
Análise exploratória de dados em Python: o que você precisa saber?
Publicados: 2021-03-12A Análise Exploratória de Dados (EDA) é uma prática muito comum e importante seguida por todos os cientistas de dados. É o processo de olhar para tabelas e tabelas de dados de diferentes ângulos para entendê-los completamente. Obter uma boa compreensão dos dados nos ajuda a limpá-los e resumi-los, o que traz os insights e tendências que de outra forma não eram claros.
A EDA não tem um conjunto rígido de regras que devem ser seguidas como na 'análise de dados', por exemplo. As pessoas que são novas no campo sempre tendem a confundir os dois termos, que são em sua maioria semelhantes, mas diferentes em seu propósito. Ao contrário da EDA, a análise de dados está mais inclinada à implementação de probabilidades e métodos estatísticos para revelar fatos e relações entre diferentes variantes.
Voltando, não há maneira certa ou errada de realizar EDA. Isso varia de pessoa para pessoa, no entanto, existem algumas diretrizes principais comumente seguidas que estão listadas abaixo.
- Manipulação de valores ausentes: Valores nulos podem ser vistos quando todos os dados podem não estar disponíveis ou registrados durante a coleta.
- Remoção de dados duplicados: é importante evitar qualquer overfitting ou viés criado durante o treinamento do algoritmo de aprendizado de máquina usando registros de dados repetidos
- Manipulação de valores atípicos: Os valores atípicos são registros que diferem drasticamente do restante dos dados e não seguem a tendência. Pode surgir devido a certas exceções ou imprecisões durante a coleta de dados
- Dimensionamento e normalização: Isso é feito apenas para variáveis de dados numéricos. Na maioria das vezes, as variáveis diferem muito em seu alcance e escala, o que torna difícil compará-las e encontrar correlações.
- Análise univariada e bivariada: A análise univariada geralmente é feita vendo como uma variável está afetando a variável de destino. A análise bivariada é realizada entre quaisquer 2 variáveis, pode ser numérica ou categórica ou ambas.
Veremos como alguns deles são implementados usando um conjunto de dados muito famoso de 'Risco de inadimplência de crédito residencial' disponível no Kaggle aqui . Os dados contêm informações sobre o solicitante do empréstimo no momento da solicitação do empréstimo. Ele contém dois tipos de cenários:
- O cliente com dificuldades de pagamento : atrasou mais de X dias
em pelo menos uma das primeiras Y parcelas do empréstimo em nossa amostra,
- Todos os outros casos : Todos os outros casos em que o pagamento é pago a tempo.
Trabalharemos apenas nos arquivos de dados do aplicativo para este artigo.
Relacionado: Ideias e tópicos de projetos Python para iniciantes
Índice
Olhando para os dados
app_data = pd.read_csv('application_data.csv')
app_data.info()
Depois de ler os dados do aplicativo, usamos a função info() para obter uma breve visão geral dos dados com os quais estaremos lidando. A saída abaixo nos informa que temos cerca de 300.000 registros de empréstimos com 122 variáveis. Destas, existem 16 variáveis categóricas e as restantes numéricas.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entradas, 0 a 307510
Colunas: 122 entradas, SK_ID_CURR a AMT_REQ_CREDIT_BUREAU_YEAR
dtypes: float64(65), int64(41), object(16)
uso de memória: 286,2+ MB
É sempre uma boa prática manipular e analisar dados numéricos e categóricos separadamente.
categórico = app_data.select_dtypes(include = objeto).columns
app_data[categorical].apply(pd.Series.nunique, axis = 0)
Observando apenas os recursos categóricos abaixo, vemos que a maioria deles possui apenas algumas categorias que os tornam mais fáceis de analisar usando gráficos simples.
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZAÇÃO_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype: int64
Agora para os recursos numéricos, o método describe() nos fornece as estatísticas de nossos dados:
numer= app_data.describe()
numeric= numer.columns
número
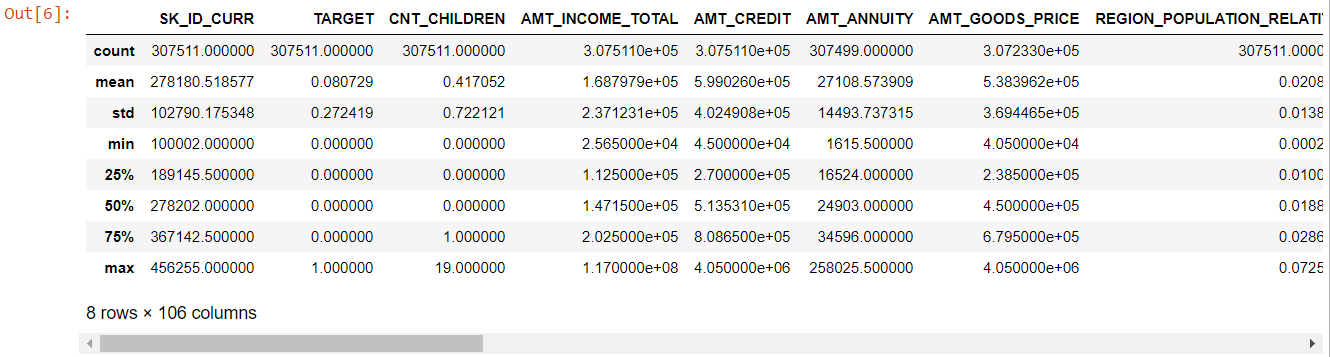
Olhando para a tabela inteira é evidente que:
- days_birth é negativo: idade do requerente (em dias) em relação ao dia da aplicação
- days_employed tem valores atípicos (o valor máximo é de cerca de 100 anos) (635243)
- amt_annuity- significa muito menor que o valor máximo
Portanto, agora sabemos quais recursos terão que ser analisados mais a fundo.
Dados ausentes
Podemos fazer um gráfico de pontos de todos os recursos com valores ausentes plotando a % de dados ausentes ao longo do eixo Y.
ausente = pd.DataFrame( (app_data.isnull().sum()) * 100 / app_data.shape[0]).reset_index()
plt.figure(figsize = (16,5))
ax = sns.pointplot('index', 0, data = missing)

plt.xticks(rotação = 90, tamanho da fonte = 7)
plt.title(“Porcentagem de valores ausentes”)
plt.ylabel(“PERCENTAGEM”)
plt.show()
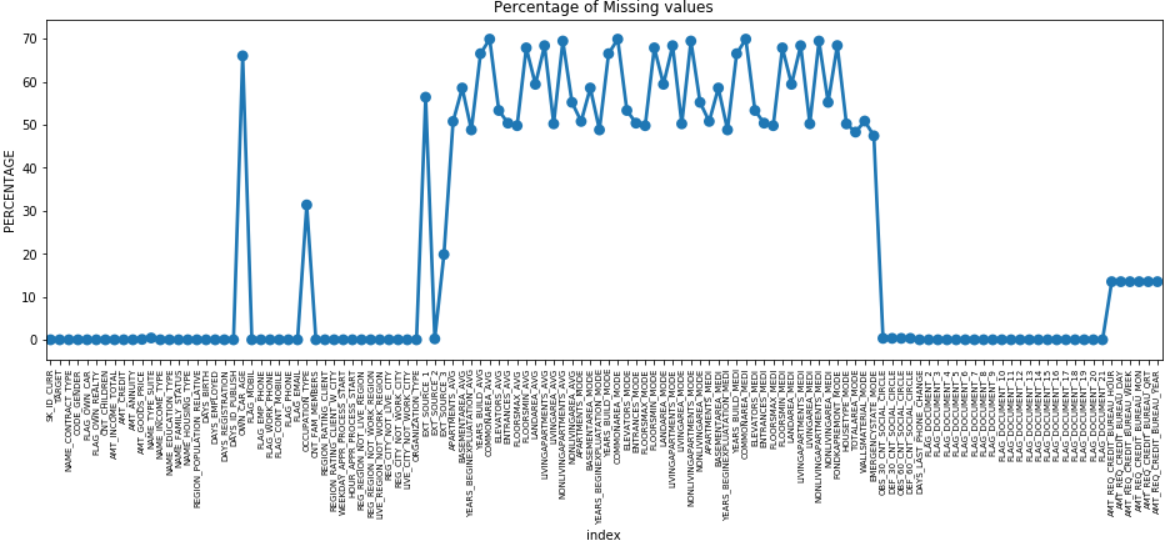
Muitas colunas têm muitos dados ausentes (30-70%), algumas têm poucos dados ausentes (13-19%) e muitas colunas também não têm dados ausentes. Não é realmente necessário modificar o conjunto de dados quando você só precisa executar o EDA. No entanto, avançando com o pré-processamento de dados, devemos saber como lidar com valores ausentes.
Para feições com menos valores omissos, podemos usar a regressão para prever os valores omissos ou preencher com a média dos valores presentes, dependendo da feição. E para recursos com um número muito alto de valores ausentes, é melhor descartar essas colunas, pois elas fornecem muito menos informações sobre a análise.
Desequilíbrio de dados
Neste conjunto de dados, os inadimplentes são identificados usando a variável binária 'TARGET'.
100 * app_data['TARGET'].value_counts() / len(app_data['TARGET'])
0 91.927118
1 8.072882
Nome: TARGET, dtype: float64
Vemos que os dados estão altamente desequilibrados com uma proporção de 92:8. A maioria dos empréstimos foi paga no prazo (meta = 0). Portanto, sempre que houver um desequilíbrio tão grande, é melhor pegar os recursos e compará-los com a variável de destino (análise direcionada) para determinar quais categorias nesses recursos tendem a inadimplir nos empréstimos mais do que outras.
Abaixo estão apenas alguns exemplos de gráficos que podem ser feitos usando a biblioteca seaborn de python e funções simples definidas pelo usuário.
Gênero
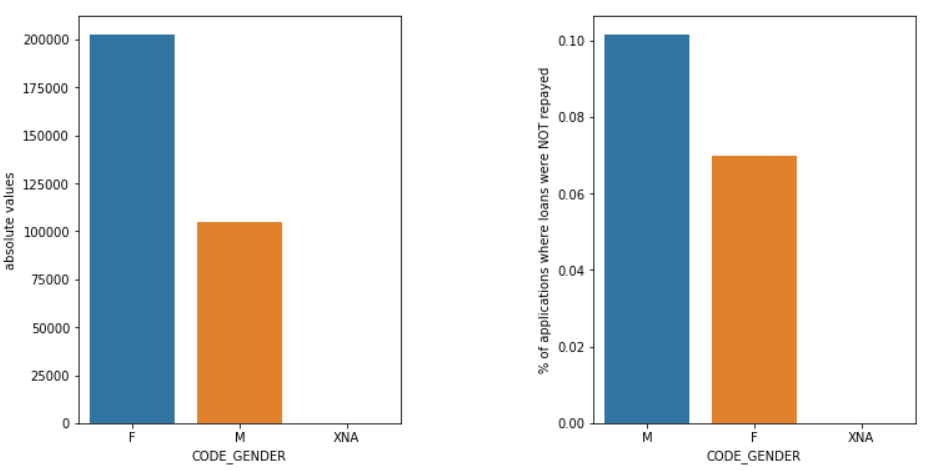
Os homens (M) têm uma chance maior de inadimplência em comparação com as mulheres (F), embora o número de solicitantes do sexo feminino seja quase o dobro. Assim, as mulheres são mais confiáveis do que os homens para pagar seus empréstimos.
Tipo de educação
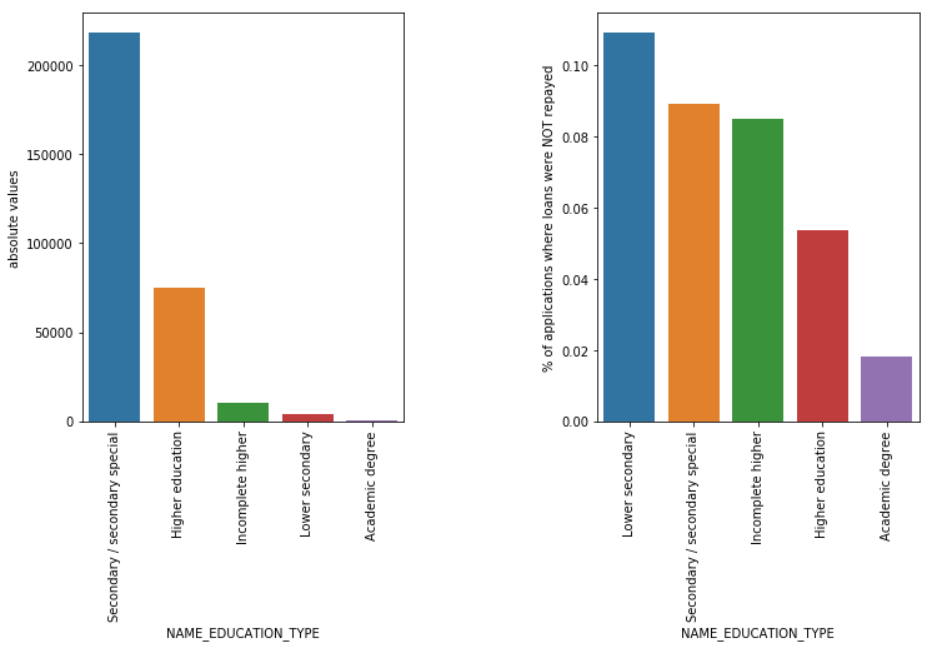
Embora a maioria dos empréstimos estudantis seja para o ensino secundário ou superior, são os empréstimos para o ensino secundário inferior que são mais arriscados para a empresa, seguidos pelos secundários.
Leia também: Carreira em Ciência de Dados
Conclusão
Esse tipo de análise visto acima é feito amplamente na análise de risco em serviços bancários e financeiros. Dessa forma, os arquivos de dados podem ser usados para minimizar o risco de perder dinheiro ao emprestar aos clientes. O escopo da AED em todos os outros setores é infinito e deve ser amplamente utilizado.
Se você está curioso para aprender sobre ciência de dados, confira o Executive PG in Data Science do IIIT-B & upGrad, que é criado para profissionais que trabalham e oferece mais de 10 estudos de caso e projetos, workshops práticos práticos, orientação com especialistas do setor, 1- on-1 com mentores do setor, mais de 400 horas de aprendizado e assistência de trabalho com as principais empresas.
A Análise Exploratória de Dados é considerada o nível inicial quando você começa a modelar seus dados. Esta é uma técnica bastante perspicaz para analisar as melhores práticas para modelar seus dados. Você poderá extrair gráficos visuais, gráficos e relatórios dos dados para obter uma compreensão completa deles. Os outliers referem-se a anomalias ou pequenas variações em seus dados. Isso pode acontecer durante a coleta de dados. Existem 4 maneiras pelas quais podemos detectar um outlier no conjunto de dados. Esses métodos são os seguintes: Ao contrário da análise de dados, não há regras e regulamentos rígidos e rápidos a serem seguidos para a EDA. Não se pode dizer que este é o método correto ou que é o método errado para realizar a EDA. Os iniciantes são muitas vezes incompreendidos e ficam confusos entre EDA e análise de dados.Por que a Análise Exploratória de Dados (EDA) é necessária?
A EDA envolve certas etapas para analisar completamente os dados, incluindo derivar os resultados estatísticos, encontrar valores de dados ausentes, manipular as entradas de dados defeituosas e, finalmente, deduzir vários gráficos e gráficos.
O objetivo principal dessa análise é garantir que o conjunto de dados que você está usando seja adequado para começar a aplicar algoritmos de modelagem. Essa é a razão pela qual esta é a primeira etapa que você deve executar em seus dados antes de passar para o estágio de modelagem. O que são outliers e como lidar com eles?
1. Boxplot - Boxplot é um método de detecção de um outlier onde segregamos os dados através de seus quartis.
2. Gráfico de dispersão - Um gráfico de dispersão exibe os dados de 2 variáveis na forma de uma coleção de pontos marcados no plano cartesiano. O valor de uma variável representa o eixo horizontal (x-ais) e o valor da outra variável representa o eixo vertical (eixo y).
3. Z-score - Ao calcular o Z-score, procuramos os pontos que estão distantes do centro e os consideramos como discrepantes.
4. Intervalo Interquartil (IQR) - O Intervalo Interquartil ou IQR é a diferença entre os quartis superior e inferior ou 75º e 25º quartil, muitas vezes referido como dispersão estatística. Quais são as diretrizes para realizar a EDA?
No entanto, existem algumas diretrizes que são comumente praticadas:
1. Lidando com valores ausentes
2. Removendo dados duplicados
3. Lidando com valores discrepantes
4. Dimensionamento e normalização
5. Análise univariada e bivariada