
O que é Análise Exploratória de Dados em Python? Aprenda do zero
Publicados: 2021-03-04A Análise Exploratória de Dados ou EDA, em suma, compreende quase 70% do Projeto de Ciência de Dados. EDA é o processo de explorar os dados usando várias ferramentas de análise para obter as estatísticas inferenciais dos dados. Essas explorações são feitas vendo números simples ou traçando gráficos e tabelas de diferentes tipos.
Cada gráfico ou tabela descreve uma história diferente e um ângulo para os mesmos dados. Para a maior parte da parte de análise e limpeza de dados, o Pandas é a ferramenta mais utilizada. Para as visualizações e plotagem de gráficos/gráficos, são usadas bibliotecas de plotagem como Matplotlib, Seaborn e Plotly.
A EDA é extremamente necessária para ser realizada, pois faz com que os dados confessem a você. Um Cientista de Dados que faz um EDA muito bom sabe muito sobre os dados e, portanto, o modelo que ele construirá será automaticamente melhor do que o Cientista de Dados que não fizer um bom EDA.
Ao final deste tutorial, você saberá o seguinte:
- Verificando a visão geral básica dos dados
- Verificando a estatística descritiva dos dados
- Manipulando nomes de colunas e tipos de dados
- Manipulando valores ausentes e linhas duplicadas
- Análise bivariada
Índice
Visão geral básica dos dados
Usaremos o Cars Dataset para este tutorial, que pode ser baixado do Kaggle. A primeira etapa para quase qualquer conjunto de dados é importá-lo e verificar sua visão geral básica – sua forma, colunas, tipos de coluna, 5 principais linhas, etc. Esta etapa fornece um resumo rápido dos dados com os quais você trabalhará. Vamos ver como fazer isso em Python.
| # Importando as bibliotecas necessárias importar pandas como pd importar numpy como np import seaborn as sns #visualização importe matplotlib.pyplot como plt #visualização %matplotlib em linha sns.set(color_codes= True ) |
Dados de cabeça e cauda
| dados = pd.read_csv( “caminho/conjunto de dados.csv” ) # Verifica as 5 primeiras linhas do dataframe data.head() |
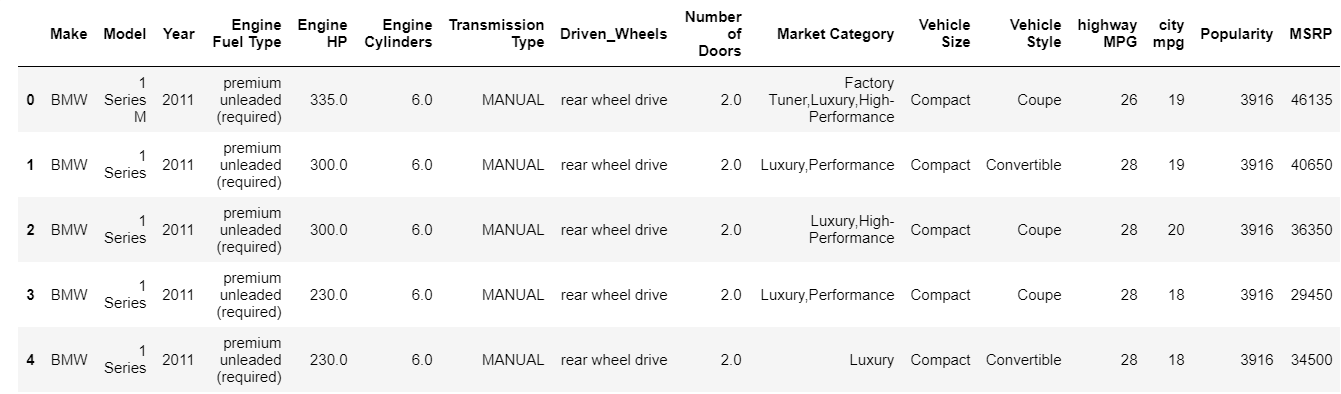
A função head imprime os 5 principais índices do quadro de dados por padrão. Você também pode especificar quantos índices principais você precisa ver ignorando esse valor na cabeça. Imprimir a cabeça instantaneamente nos dá uma visão rápida do tipo de dados que temos, que tipo de recursos estão presentes e quais valores eles contêm. Claro, isso não conta toda a história sobre os dados, mas dá uma olhada rápida nos dados. Da mesma forma, você pode imprimir a parte inferior do quadro de dados usando a função tail.
| # Imprime as últimas 10 linhas do dataframe data.tail( 10 ) |
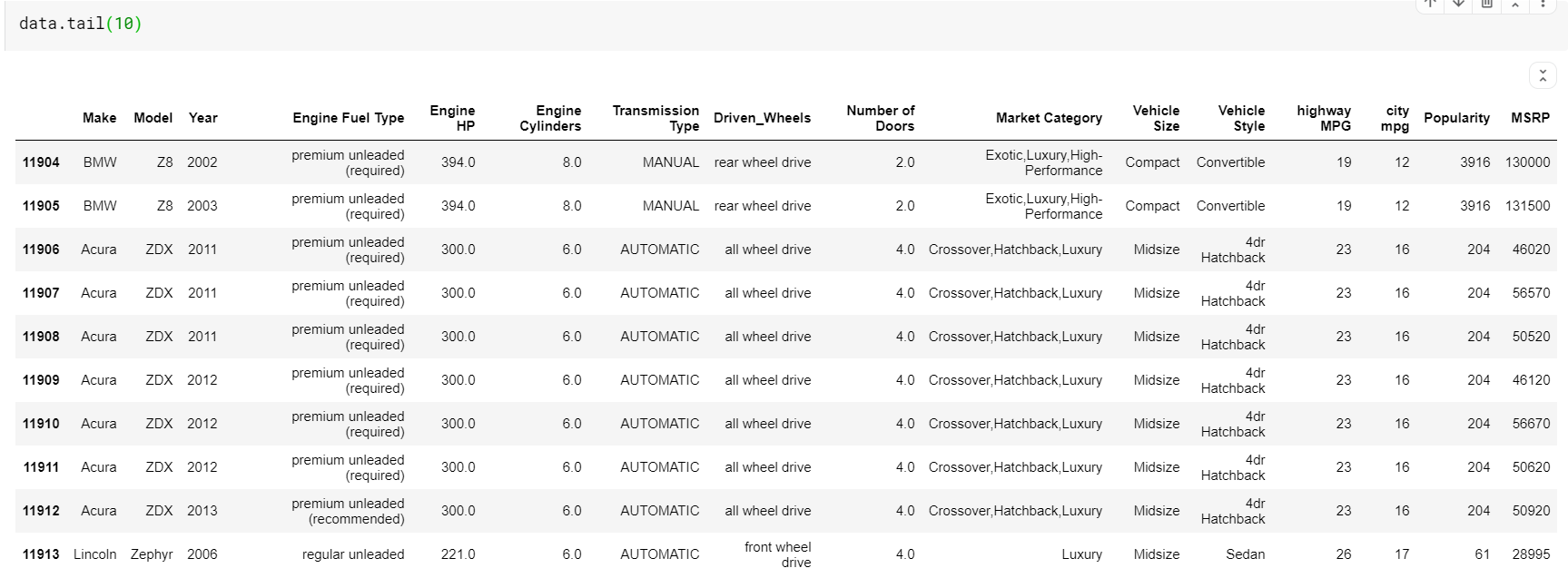
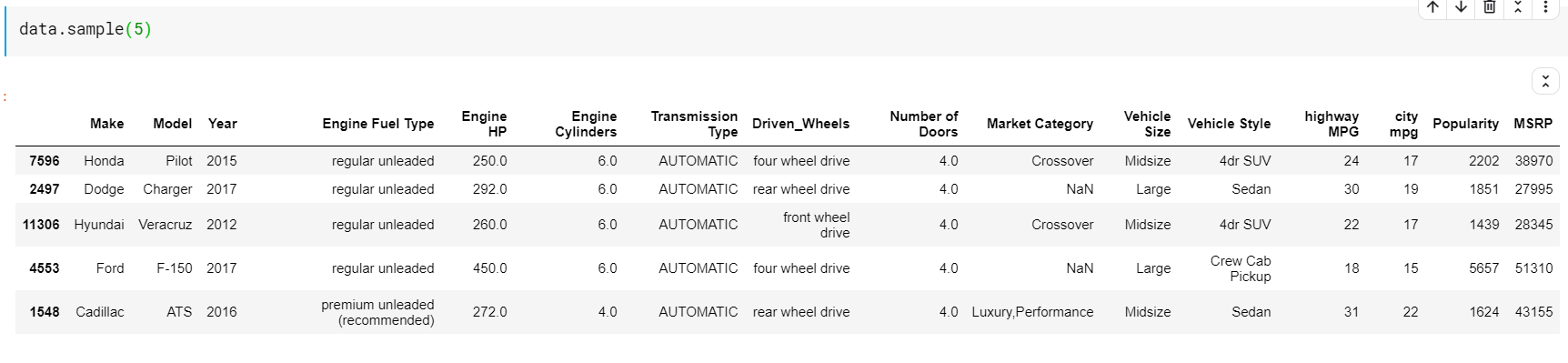
Uma coisa a notar aqui é que ambas as funções-head e tail nos dão os índices superiores ou inferiores. Mas as linhas superiores ou inferiores nem sempre são uma boa visualização dos dados. Portanto, você também pode imprimir qualquer número de linhas amostradas aleatoriamente do conjunto de dados usando a função sample().
| # Imprime 5 linhas aleatórias data.sample( 5 ) |
Estatísticas descritivas
Em seguida, vamos verificar as estatísticas descritivas do conjunto de dados. As estatísticas descritivas consistem em tudo o que “descreve” o conjunto de dados. Verificamos a forma do quadro de dados, o que todas as colunas estão presentes, quais são todos os recursos numéricos e categóricos. Veremos também como fazer tudo isso em funções simples.
Forma
| # Verificando a forma do dataframe (mxn) #m=número de linhas #n=número de colunas data.shape |

Como vemos, esse quadro de dados contém 11.914 linhas e 16 colunas.
Colunas
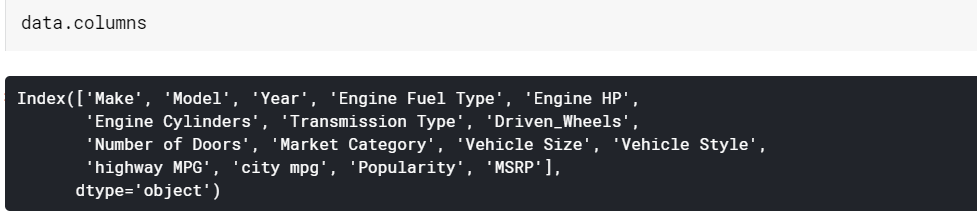
| # Imprime os nomes das colunas dados.colunas |
Informações do dataframe
| # Imprime os tipos de dados da coluna e o número de valores não omissos data.info() |
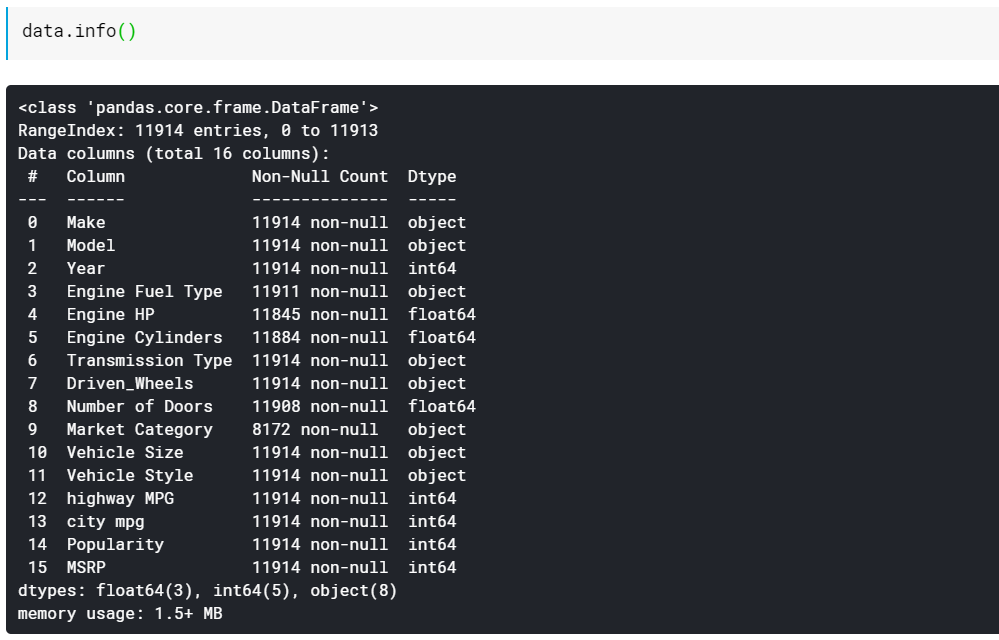
Como você vê, a função info() nos fornece todas as colunas, quantos valores não nulos ou não ausentes existem nessas colunas e, por último, o tipo de dados dessas colunas. Esta é uma boa maneira rápida de ver o que todos os recursos são numéricos e o que todos são categóricos/baseados em texto. Além disso, agora temos informações sobre o que todas as colunas têm valores ausentes. Veremos como trabalhar com valores ausentes mais tarde.
Manipulando nomes de colunas e tipos de dados
Verificar e manipular cuidadosamente cada coluna é extremamente crucial na EDA. Precisamos ver que tipo de conteúdo uma coluna/recurso contém e o que os pandas leram seu tipo de dados. Os tipos de dados numéricos são principalmente int64 ou float64. Os recursos baseados em texto ou categóricos são atribuídos ao tipo de dados 'objeto'.
Os recursos baseados em data e hora são atribuídos Há momentos em que o Pandas não entende o tipo de dados de um recurso. Nesses casos, ele apenas atribui preguiçosamente o tipo de dados 'objeto'. Podemos especificar os tipos de dados da coluna explicitamente ao ler os dados com read_csv.
Selecionando Colunas Categóricas e Numéricas
| # Adicione todas as colunas categóricas e numéricas a listas separadas categórico = data.select_dtypes( 'objeto' ).columns numeric = data.select_dtypes( 'number' ).columns |

Aqui o tipo que passamos como 'number' seleciona todas as colunas com tipos de dados que possuem qualquer tipo de número - seja int64 ou float64.

Renomeando as colunas
| # Renomeando os nomes das colunas data = data.rename(columns={ “Motor HP” : “HP” , “Cilindros do motor” : “Cilindros” , “Tipo de transmissão” : “Transmissão” , “Driven_Wheels” : “Modo de condução” , “rodovia MPG” : “MPG-H” , “MSRP” : “Preço” }) data.head( 5 ) |

A função renomear apenas recebe um dicionário com os nomes das colunas a serem renomeadas e seus novos nomes.
Lidando com valores ausentes e linhas duplicadas
Valores ausentes são um dos problemas/discrepâncias mais comuns em qualquer conjunto de dados da vida real. O tratamento de valores ausentes é em si um tópico vasto, pois existem várias maneiras de fazê-lo. Algumas maneiras são mais genéricas e outras são mais específicas para o conjunto de dados com o qual se está lidando.
Verificando valores ausentes
| # Verificando valores ausentes data.isnull().sum() |
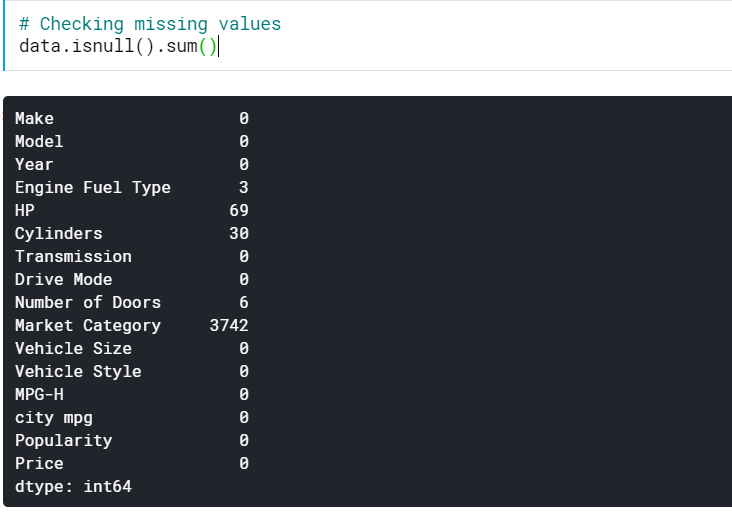
Isso nos dá o número de valores ausentes em todas as colunas. Também podemos ver a porcentagem de valores ausentes.
| # Porcentagem de valores ausentes data.isnull().mean()* 100 |
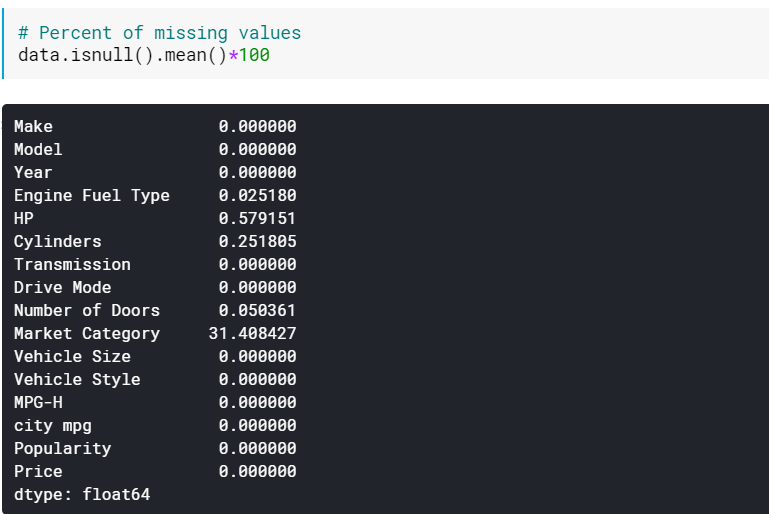
A verificação das porcentagens pode ser útil quando houver muitas colunas com valores ausentes. Nesses casos, as colunas com muitos valores ausentes (por exemplo, >60% ausentes) podem ser simplesmente descartadas.
Como imputar valores ausentes
| #Imputando valores ausentes de colunas numéricas por média dados[numérico] = dados[numérico].fillna(dados[numérico].média().iloc[ 0 ]) #Imputando valores ausentes de colunas categóricas por modo data[categorical] = data[categorical].fillna(data[categorical].mode().iloc[ 0 ]) |
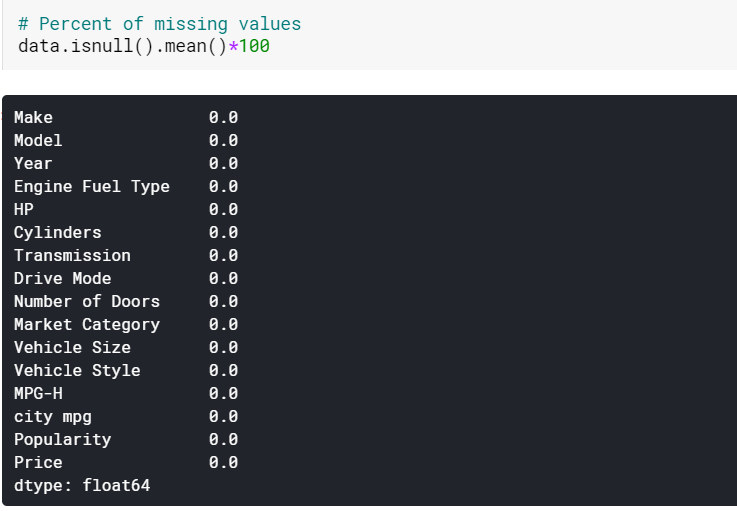
Aqui simplesmente imputamos os valores ausentes nas colunas numéricas por seus respectivos meios e os das colunas categóricas por seus modos. E como podemos ver, não há valores ausentes agora.
Observe que esta é a maneira mais primitiva de imputar os valores e não funciona em casos da vida real onde formas mais sofisticadas são desenvolvidas, por exemplo, interpolação, KNN, etc.
Manipulando Linhas Duplicadas
| # Soltar linhas duplicadas data.drop_duplicates(inplace= True ) |
Isso apenas descarta as linhas duplicadas.
Checkout: ideias e tópicos de projetos Python
Análise bivariada
Agora vamos ver como obter mais insights fazendo análises bivariadas. Bivariada significa uma análise que consiste em 2 variáveis ou características. Existem diferentes tipos de gráficos disponíveis para diferentes tipos de recursos.
Para Numérico - Numérico
- Gráfico de dispersão
- Gráfico de linha
- Mapa de calor para correlações
Para Categórico-Numérico
- Gráfico de barras
- Trama de violino
- Enxame
Para Categórico-Categórico
- Gráfico de barras
- Gráfico de pontos
Mapa de calor para correlações
| # Verificando as correlações entre as variáveis. plt.figure(figsize=( 15 , 10 )) c= data.corr() sns.heatmap(c,cmap= “BrBG” ,annot= True ) |
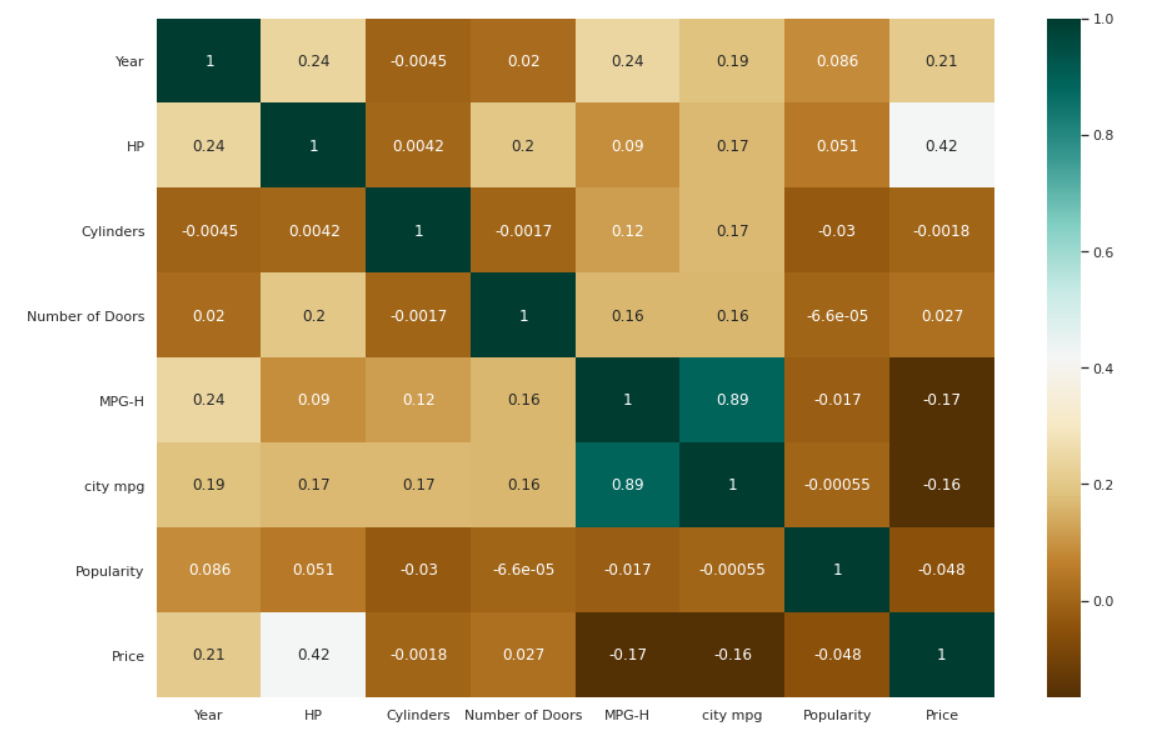
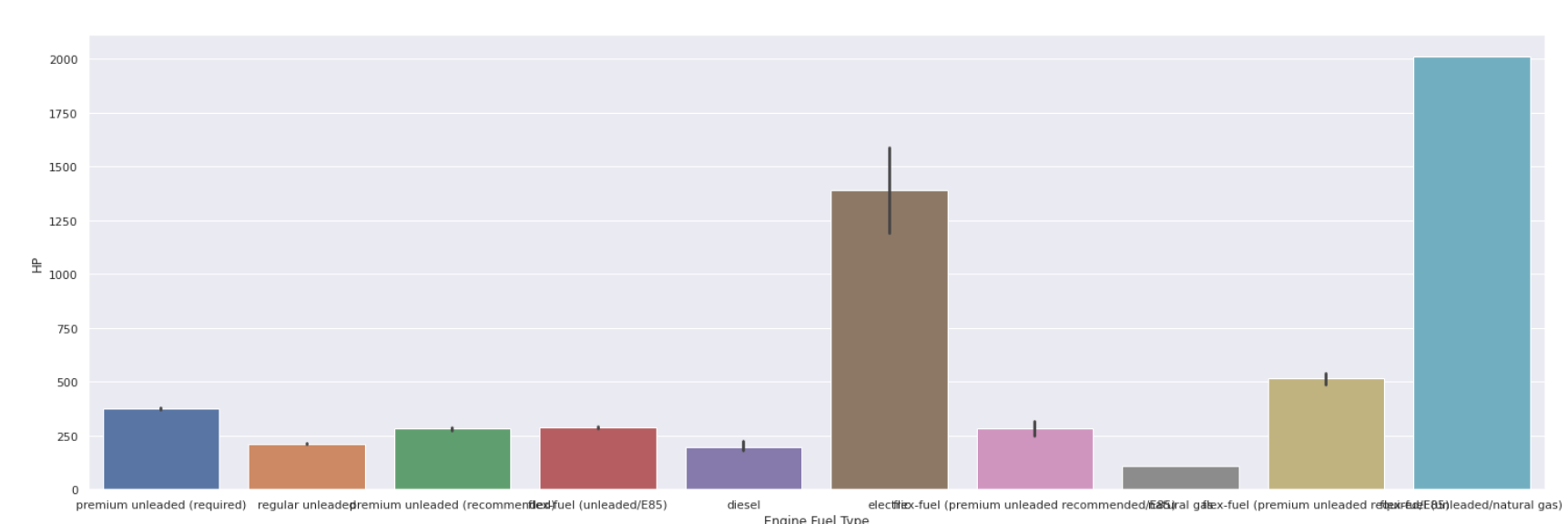
Gráfico de barras
| sns.barplot(data[ 'Tipo de combustível do motor' ], data[ 'HP' ]) |
Obtenha a certificação em ciência de dados das melhores universidades do mundo. Aprenda Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.
Conclusão
Como vimos, há muitas etapas a serem percorridas ao explorar um conjunto de dados. Nós cobrimos apenas alguns aspectos neste tutorial, mas isso lhe dará mais do que apenas conhecimento básico de um bom EDA.
Se você está curioso para aprender sobre Python, tudo sobre ciência de dados, confira o PG Diploma in Data Science do IIIT-B & upGrad, que é criado para profissionais que trabalham e oferece mais de 10 estudos de caso e projetos, workshops práticos práticos, orientação com a indústria especialistas, 1-on-1 com mentores do setor, mais de 400 horas de aprendizado e assistência de trabalho com as principais empresas.
Quais são as etapas da análise exploratória de dados?
As principais etapas que você precisa executar para fazer a análise exploratória de dados são -
Variáveis e tipos de dados devem ser identificados.
Analisando as métricas fundamentais
Análise não gráfica univariada
Análise gráfica univariada
Análise de dados bivariados
Transformações que são variáveis
Tratamento para valor perdido
Tratamento de forasteiros
Análise de Correlação
Redução de Dimensionalidade
Qual é o objetivo da análise exploratória de dados?
O objetivo principal da EDA é auxiliar na análise de dados antes de fazer qualquer suposição. Ele pode auxiliar na detecção de erros evidentes, bem como no melhor entendimento dos padrões de dados, na detecção de outliers ou eventos incomuns e na descoberta de relações interessantes entre variáveis.
A análise exploratória pode ser usada por cientistas de dados para garantir que os resultados que eles criam sejam precisos e apropriados para quaisquer resultados e objetivos de negócios direcionados. A EDA também auxilia as partes interessadas, garantindo que elas estejam abordando as questões apropriadas. Desvios padrão, dados categóricos e intervalos de confiança podem ser respondidos com EDA. Após a conclusão da EDA e a extração de insights, seus recursos podem ser aplicados a uma análise ou modelagem de dados mais avançada, incluindo aprendizado de máquina.
Quais são os diferentes tipos de análise exploratória de dados?
Existem dois tipos de técnicas de EDA: gráficas e quantitativas (não gráficas). A abordagem quantitativa, por outro lado, requer a compilação de estatísticas resumidas, enquanto os métodos gráficos envolvem a coleta de dados de forma diagramática ou visual. Abordagens univariadas e multivariadas são subconjuntos desses dois tipos de metodologias.
Para investigar relacionamentos, as abordagens univariadas examinam uma variável (coluna de dados) por vez, enquanto os métodos multivariados examinam duas ou mais variáveis de uma só vez. Gráficos e não gráficos univariados e multivariados são as quatro formas de EDA. Os procedimentos quantitativos são mais objetivos, enquanto os métodos pictóricos são mais subjetivos.