
O guia para raspagem ética de sites dinâmicos com Node.js e marionetista
Publicados: 2022-03-10Vamos começar com uma pequena seção sobre o que realmente significa web scraping. Todos nós usamos web scraping em nossas vidas cotidianas. Ele apenas descreve o processo de extração de informações de um site. Portanto, se você copiar e colar uma receita de seu prato de macarrão favorito da internet em seu caderno pessoal, estará realizando a raspagem da web .
Ao usar esse termo na indústria de software, geralmente nos referimos à automação dessa tarefa manual usando um software. Aderindo ao nosso exemplo anterior de “prato de macarrão”, esse processo geralmente envolve duas etapas:
- Buscando a página
Primeiro temos que baixar a página como um todo. Esta etapa é como abrir a página em seu navegador da Web ao raspar manualmente. - Analisando os dados
Agora, temos que extrair a receita no HTML do site e convertê-la em um formato legível por máquina como JSON ou XML.
No passado, trabalhei para muitas empresas como consultor de dados. Fiquei surpreso ao ver quantas tarefas de extração, agregação e enriquecimento de dados ainda são feitas manualmente, embora possam ser facilmente automatizadas com apenas algumas linhas de código. Isso é exatamente o que o web scraping significa para mim: extrair e normalizar informações valiosas de um site para alimentar outro processo de negócios de geração de valor.
Durante esse tempo, vi empresas usarem web scraping para todos os tipos de casos de uso. As empresas de investimento se concentraram principalmente na coleta de dados alternativos, como análises de produtos , informações sobre preços ou postagens em mídias sociais para sustentar seus investimentos financeiros.
Aqui está um exemplo. Um cliente me procurou para obter dados de avaliação de produtos para uma extensa lista de produtos de vários sites de comércio eletrônico, incluindo a classificação, a localização do avaliador e o texto da avaliação para cada avaliação enviada. Os dados do resultado permitiram ao cliente identificar tendências sobre a popularidade do produto em diferentes mercados. Este é um excelente exemplo de como uma única informação aparentemente “inútil” pode se tornar valiosa quando comparada a uma quantidade maior.
Outras empresas aceleram seu processo de vendas usando web scraping para geração de leads . Esse processo geralmente envolve a extração de informações de contato, como número de telefone, endereço de e-mail e nome de contato para uma determinada lista de sites. Automatizar essa tarefa dá às equipes de vendas mais tempo para abordar os clientes em potencial. Assim, a eficiência do processo de vendas aumenta.
Atenha-se às regras
Em geral, a extração de dados publicamente disponíveis é legal, conforme confirmado pela jurisdição do caso Linkedin vs. HiQ. No entanto, estabeleci um conjunto de regras éticas que gosto de seguir ao iniciar um novo projeto de web scraping. Isso inclui:
- Verificando o arquivo robots.txt.
Geralmente contém informações claras sobre quais partes do site o proprietário da página pode acessar por robôs e raspadores e destaca as seções que não devem ser acessadas. - Lendo os termos e condições.
Em comparação com o robots.txt, essa informação não está disponível com menos frequência, mas geralmente informa como eles tratam os raspadores de dados. - Raspagem com velocidade moderada.
A raspagem cria carga do servidor na infraestrutura do site de destino. Dependendo do que você raspa e em qual nível de simultaneidade seu raspador está operando, o tráfego pode causar problemas para a infraestrutura do servidor do site de destino. Obviamente, a capacidade do servidor desempenha um grande papel nessa equação. Portanto, a velocidade do meu scraper é sempre um equilíbrio entre a quantidade de dados que pretendo extrair e a popularidade do site de destino. Encontrar esse equilíbrio pode ser alcançado respondendo a uma única pergunta: “A velocidade planejada vai mudar significativamente o tráfego orgânico do site?”. Nos casos em que não tenho certeza sobre a quantidade de tráfego natural de um site, uso ferramentas como o ahrefs para ter uma ideia aproximada.
Selecionando a tecnologia certa
Na verdade, a raspagem com um navegador headless é uma das tecnologias de menor desempenho que você pode usar, pois afeta fortemente sua infraestrutura. Um núcleo do processador da sua máquina pode manipular aproximadamente uma instância do Chrome.
Vamos fazer um cálculo de exemplo rápido para ver o que isso significa para um projeto de web scraping do mundo real.
Cenário
- Você quer raspar 20.000 URLs.
- O tempo médio de resposta do site de destino é de 6 segundos.
- Seu servidor tem 2 núcleos de CPU.
O projeto levará 16 horas para ser concluído.
Por isso, sempre tento evitar o uso de um navegador ao realizar um teste de viabilidade de raspagem para um site dinâmico.
Aqui está uma pequena lista de verificação que eu sempre passo:
- Posso forçar o estado de página necessário por meio de parâmetros GET na URL? Se sim, podemos simplesmente executar uma solicitação HTTP com os parâmetros anexados.
- As informações dinâmicas fazem parte da fonte da página e estão disponíveis por meio de um objeto JavaScript em algum lugar no DOM? Se sim, podemos usar novamente uma solicitação HTTP normal e analisar os dados do objeto stringificado.
- Os dados são buscados por meio de uma solicitação XHR? Em caso afirmativo, posso acessar diretamente o endpoint com um cliente HTTP? Se sim, podemos enviar uma solicitação HTTP para o endpoint diretamente. Muitas vezes, a resposta é até formatada em JSON, o que facilita muito a nossa vida.
Se todas as perguntas forem respondidas com um “não” definitivo, ficaremos oficialmente sem opções viáveis para usar um cliente HTTP. Claro, pode haver mais ajustes específicos do site que poderíamos tentar, mas geralmente, o tempo necessário para descobri-los é muito alto, comparado ao desempenho mais lento de um navegador headless. A beleza de raspar com um navegador é que você pode raspar qualquer coisa que esteja sujeita à seguinte regra básica:
Se você puder acessá-lo com um navegador, poderá raspá-lo.
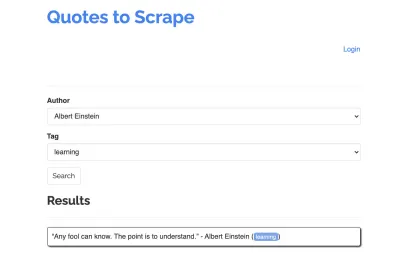
Vamos usar o seguinte site como exemplo para nosso scraper: https://quotes.toscrape.com/search.aspx. Ele apresenta citações de uma lista de determinados autores para uma lista de tópicos. Todos os dados são buscados via XHR.
Quem deu uma olhada de perto no funcionamento do site e passou pela lista de verificação acima provavelmente percebeu que as cotações poderiam realmente ser raspadas usando um cliente HTTP, pois elas podem ser recuperadas fazendo uma solicitação POST diretamente no endpoint de cotações. Mas como este tutorial deve cobrir como raspar um site usando o Puppeteer, vamos fingir que isso é impossível.
Pré-requisitos de instalação
Como vamos construir tudo usando o Node.js, vamos primeiro criar e abrir uma nova pasta e criar um novo projeto Node dentro dela, executando o seguinte comando:
mkdir js-webscraper cd js-webscraper npm initVerifique se você já instalou o npm. O instalador nos fará algumas perguntas sobre meta-informações sobre este projeto, que todos podemos pular, pressionando Enter .
Instalando o Marionetista
Já falamos sobre raspagem com um navegador antes. Puppeteer é uma API Node.js que nos permite conversar com uma instância do Chrome sem comando de forma programática.
Vamos instalá-lo usando npm:
npm install puppeteerConstruindo nosso raspador
Agora, vamos começar a construir nosso scraper criando um novo arquivo, chamado scraper.js .
Primeiro, importamos a biblioteca instalada anteriormente, Puppeteer:
const puppeteer = require('puppeteer');Como próximo passo, dizemos ao Puppeteer para abrir uma nova instância do navegador dentro de uma função assíncrona e auto-executável:
(async function scrape() { const browser = await puppeteer.launch({ headless: false }); // scraping logic comes here… })();Nota : Por padrão, o modo sem cabeça está desligado, pois isso aumenta o desempenho. No entanto, ao construir um novo raspador, gosto de desativar o modo sem cabeça. Isso nos permite acompanhar o processo pelo qual o navegador está passando e ver todo o conteúdo renderizado. Isso nos ajudará a depurar nosso script mais tarde.
Dentro de nossa instância de navegador aberta, agora abrimos uma nova página e direcionamos para nosso URL de destino:
const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); Como parte da função assíncrona, usaremos a instrução await para aguardar a execução do seguinte comando antes de prosseguir com a próxima linha de código.
Agora que abrimos com sucesso uma janela do navegador e navegamos até a página, temos que criar o estado do site , para que as informações desejadas fiquem visíveis para raspagem.
Os tópicos disponíveis são gerados dinamicamente para um autor selecionado. Assim, primeiro selecionaremos 'Albert Einstein' e aguardaremos a lista de tópicos gerada. Uma vez que a lista foi totalmente gerada, selecionamos 'aprendizagem' como um tópico e o selecionamos como um segundo parâmetro de formulário. Em seguida, clicamos em enviar e extraímos as cotações recuperadas do contêiner que contém os resultados.

Como agora vamos converter isso em lógica JavaScript, vamos primeiro fazer uma lista de todos os seletores de elementos sobre os quais falamos no parágrafo anterior:
| Campo de seleção do autor | #author |
| Campo de seleção de tags | #tag |
| Botão de envio | input[type="submit"] |
| Contêiner de cotação | .quote |
Antes de começarmos a interagir com a página, garantiremos que todos os elementos que acessaremos estejam visíveis, adicionando as seguintes linhas ao nosso script:
await page.waitForSelector('#author'); await page.waitForSelector('#tag');Em seguida, selecionaremos valores para nossos dois campos de seleção:
await page.select('select#author', 'Albert Einstein'); await page.select('select#tag', 'learning');Agora estamos prontos para realizar nossa pesquisa clicando no botão "Pesquisar" na página e aguardando as citações aparecerem:
await page.click('.btn'); await page.waitForSelector('.quote'); Como agora vamos acessar a estrutura HTML DOM da página, estamos chamando a função page.evaluate() fornecida, selecionando o contêiner que contém as aspas (é apenas um neste caso). Em seguida, construímos um objeto e definimos null como o valor de fallback para cada parâmetro de object :
let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, }; }); return quotes; });Podemos tornar todos os resultados visíveis em nosso console registrando-os:
console.log(quotes);Por fim, vamos fechar nosso navegador e adicionar uma instrução catch:
await browser.close();O raspador completo se parece com o seguinte:
const puppeteer = require('puppeteer'); (async function scrape() { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('#author'); await page.select('#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); // logging results console.log(quotes); await browser.close(); })();Vamos tentar executar nosso scraper com:
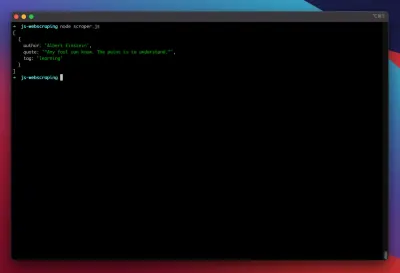
node scraper.jsE lá vamos nós! O raspador retorna nosso objeto de cotação exatamente como esperado:
Otimizações avançadas
Nosso raspador básico está funcionando agora. Vamos adicionar algumas melhorias para prepará-lo para algumas tarefas de raspagem mais sérias.
Configurando um User-Agent
Por padrão, o Puppeteer usa um agente de usuário que contém a string HeadlessChrome . Alguns sites procuram esse tipo de assinatura e bloqueiam solicitações recebidas com uma assinatura como essa. Para evitar que isso seja um possível motivo para a falha do scraper, sempre defino um agente de usuário personalizado adicionando a seguinte linha ao nosso código:
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');Isso pode ser melhorado ainda mais escolhendo um agente de usuário aleatório com cada solicitação de uma matriz dos 5 principais agentes de usuário mais comuns. Uma lista dos agentes de usuário mais comuns pode ser encontrada em um artigo sobre Agentes de usuário mais comuns.
Implementando um proxy
O Puppeteer torna a conexão com um proxy muito fácil, pois o endereço do proxy pode ser passado para o Puppeteer na inicialização, assim:
const browser = await puppeteer.launch({ headless: false, args: [ '--proxy-server=<PROXY-ADDRESS>' ] });sslproxies fornece uma grande lista de proxies gratuitos que você pode usar. Como alternativa, os serviços de proxy rotativos podem ser usados. Como os proxies geralmente são compartilhados entre muitos clientes (ou usuários gratuitos neste caso), a conexão se torna muito menos confiável do que já é em circunstâncias normais. Este é o momento perfeito para falar sobre tratamento de erros e gerenciamento de novas tentativas.
Gerenciamento de erros e tentativas
Muitos fatores podem fazer com que seu raspador falhe. Portanto, é importante lidar com erros e decidir o que deve acontecer em caso de falha. Como conectamos nosso scraper a um proxy e esperamos que a conexão seja instável (especialmente porque estamos usando proxies gratuitos), queremos tentar novamente quatro vezes antes de desistir.
Além disso, não faz sentido tentar novamente uma solicitação com o mesmo endereço IP se ela falhou anteriormente. Assim, vamos construir um pequeno sistema rotativo de proxy .
Em primeiro lugar, criamos duas novas variáveis:
let retry = 0; let maxRetries = 5; Cada vez que estamos executando nossa função scrape() , aumentamos nossa variável retry em 1. Em seguida, envolvemos nossa lógica de raspagem completa com uma instrução try e catch para que possamos lidar com erros. O gerenciamento de novas tentativas acontece dentro de nossa função catch :
A instância anterior do navegador será fechada e, se nossa variável retry for menor que nossa variável maxRetries , a função scrape será chamada recursivamente.
Nosso raspador agora ficará assim:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); … // our scraping logic } catch(e) { console.log(e); await browser.close(); if (retry < maxRetries) { scrape(); } };Agora, vamos adicionar o rotador de proxy mencionado anteriormente.
Vamos primeiro criar um array contendo uma lista de proxies:
let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ];Agora, escolha um valor aleatório da matriz:
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];Agora podemos executar o proxy gerado dinamicamente junto com nossa instância Puppeteer:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] });É claro que esse rotador de proxy pode ser otimizado ainda mais para sinalizar proxies inativos e assim por diante, mas isso definitivamente iria além do escopo deste tutorial.
Este é o código do nosso scraper (incluindo todas as melhorias):
const puppeteer = require('puppeteer'); // starting Puppeteer let retry = 0; let maxRetries = 5; (async function scrape() { retry++; let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ]; var proxy = proxyList[Math.floor(Math.random() * proxyList.length)]; console.log('proxy: ' + proxy); const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36'); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('select#author'); await page.select('select#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('select#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); console.log(quotes); await browser.close(); } catch (e) { await browser.close(); if (retry < maxRetries) { scrape(); } } })();Voilá! Executar nosso scraper dentro de nosso terminal retornará as cotações.
Dramaturgo como alternativa ao marionetista
O Puppeteer foi desenvolvido pelo Google. No início de 2020, a Microsoft lançou uma alternativa chamada Playwright. A Microsoft caçou muitos engenheiros do Puppeteer-Team. Assim, o Playwright foi desenvolvido por muitos engenheiros que já começaram a trabalhar no Puppeteer. Além de ser a novata do blog, o maior diferencial do Playwright é o suporte cross-browser, pois suporta Chromium, Firefox e WebKit (Safari).
Testes de desempenho (como este conduzido pela Checkly) mostram que o Puppeteer geralmente oferece cerca de 30% melhor desempenho, comparado ao Playwright, o que corresponde à minha própria experiência - pelo menos no momento da redação.
Outras diferenças, como o fato de que você pode executar vários dispositivos com uma instância de navegador, não são realmente valiosas para o contexto de web scraping.
Recursos e links adicionais
- Documentação do Marionetista
- Aprendizagem de marionetista e dramaturgo
- Web Scraping com Javascript por Zenscrape
- User-Agents mais comuns
- Marionetista vs Dramaturgo