
Adicionando funcionalidades dinâmicas e assíncronas aos sites JAMstack
Publicados: 2022-03-10Isso significa que os sites JAMstack não podem lidar com interações dinâmicas? Definitivamente não!
Os sites JAMstack são ótimos para criar interações assíncronas e altamente dinâmicas. Com alguns pequenos ajustes em como pensamos sobre nosso código, podemos criar interações divertidas e imersivas usando apenas ativos estáticos!
É cada vez mais comum ver sites criados usando o JAMstack — ou seja, sites que podem ser servidos como arquivos HTML estáticos criados a partir de JavaScript, Markup e APIs. As empresas adoram o JAMstack porque ele reduz os custos de infraestrutura, acelera a entrega e reduz as barreiras para melhorias de desempenho e segurança, pois o envio de ativos estáticos elimina a necessidade de dimensionar servidores ou manter bancos de dados altamente disponíveis (o que também significa que não há servidores ou bancos de dados que possam ser hackeado). Os desenvolvedores gostam do JAMstack porque reduz a complexidade de colocar um site ao vivo na internet: não há servidores para gerenciar ou implantar; podemos escrever código de front-end e ele simplesmente vai ao ar , como mágica .
(“Magic” neste caso são implantações estáticas automatizadas, que estão disponíveis gratuitamente em várias empresas, incluindo a Netlify, onde trabalho.)
Mas se você gastar muito tempo conversando com desenvolvedores sobre o JAMstack, surgirá a questão se o JAMstack pode ou não lidar com Serious Web Applications. Afinal, sites JAMstack são sites estáticos, certo? E os sites estáticos não são super limitados no que podem fazer?
Esse é um equívoco muito comum e, neste artigo, vamos nos aprofundar na origem do equívoco, examinar os recursos do JAMstack e percorrer vários exemplos de uso do JAMstack para criar aplicativos da Web sérios.
Fundamentos do JAMstack
Phil Hawksworth explica o que JAMStack realmente significa e quando faz sentido usá-lo em seus projetos, bem como como isso afeta as ferramentas e a arquitetura de front-end. Leia um artigo relacionado →
O que torna um site JAMstack “estático”?
Os navegadores da Web hoje carregam arquivos HTML, CSS e JavaScript, exatamente como nos anos 90.
Um site JAMstack, em sua essência, é uma pasta cheia de arquivos HTML, CSS e JavaScript.
Esses são “ativos estáticos”, o que significa que não precisamos de uma etapa intermediária para gerá-los (por exemplo, projetos PHP como WordPress precisam de um servidor para gerar o HTML em cada solicitação).
Esse é o verdadeiro poder do JAMstack: ele não requer nenhuma infraestrutura especializada para funcionar. Você pode executar um site JAMstack em seu computador local, colocando-o em sua rede de entrega de conteúdo (CDN) preferida, hospedando-o com serviços como GitHub Pages - você pode até arrastar e soltar a pasta em seu cliente FTP favorito para carregá-la para hospedagem compartilhada.
Ativos estáticos não significam necessariamente experiências estáticas
Como os sites JAMstack são feitos de arquivos estáticos, é fácil supor que a experiência nesses sites é, você sabe, estática . Mas esse não é o caso!
JavaScript é capaz de fazer um monte de coisas dinâmicas. Afinal, os frameworks JavaScript modernos são arquivos estáticos depois que passamos pela etapa de construção – e há centenas de exemplos de experiências de sites incrivelmente dinâmicas alimentadas por eles.
Existe um equívoco comum de que “estático” significa inflexível ou fixo. Mas tudo o que “estático” realmente significa no contexto de “sites estáticos” é que os navegadores não precisam de ajuda para entregar seu conteúdo – eles podem usá-los nativamente sem um servidor manipulando uma etapa de processamento primeiro.
Ou, colocando de outra forma:
“Ativos estáticos” não significa aplicativos estáticos; significa que nenhum servidor é necessário.
“
O JAMstack pode fazer isso?
Se alguém perguntar sobre a criação de um novo aplicativo, é comum ver sugestões de abordagens do JAMstack, como Gatsby, Eleventy, Nuxt e outras ferramentas semelhantes. É igualmente comum ver surgirem objeções: “geradores de sites estáticos não podem fazer _______”, onde _______ é algo dinâmico.
Mas – como abordamos na seção anterior – os sites JAMstack podem lidar com conteúdo e interações dinâmicas!
Aqui está uma lista incompleta de coisas que eu ouvi repetidamente as pessoas afirmarem que o JAMstack não pode lidar com o que definitivamente pode:
- Carregar dados de forma assíncrona
- Lidar com arquivos de processamento, como manipulação de imagens
- Ler e gravar em um banco de dados
- Lidar com a autenticação do usuário e proteger o conteúdo por trás de um login
Nas seções a seguir, veremos como implementar cada um desses fluxos de trabalho em um site JAMstack.
Se você não pode esperar para ver o JAMstack dinâmico em ação, você pode conferir as demos primeiro, depois voltar e aprender como elas funcionam.
Uma nota sobre as demos :
Essas demos são escritas sem nenhum framework. Eles são apenas HTML, CSS e JavaScript padrão. Eles foram construídos com navegadores modernos (por exemplo, Chrome, Firefox, Safari, Edge) em mente e aproveitam os recursos mais recentes, como módulos JavaScript, modelos HTML e a API Fetch. Nenhum polyfill foi adicionado, portanto, se você estiver usando um navegador sem suporte, as demonstrações provavelmente falharão.
Carregar dados de uma API de terceiros de forma assíncrona
“E se eu precisar obter novos dados depois que meus arquivos estáticos forem criados?”
No JAMstack, podemos tirar proveito de várias bibliotecas de solicitações assíncronas, incluindo a API Fetch integrada, para carregar dados usando JavaScript em qualquer ponto.
Demonstração: pesquise uma API de terceiros em um site JAMstack
Um cenário comum que requer carregamento assíncrono é quando o conteúdo de que precisamos depende da entrada do usuário. Por exemplo, se construirmos uma página de pesquisa para a API Rick & Morty , não saberemos qual conteúdo exibir até que alguém insira um termo de pesquisa.
Para lidar com isso, precisamos:
- Crie um formulário onde as pessoas possam digitar seu termo de pesquisa,
- Ouça o envio de um formulário,
- Obtenha o termo de pesquisa do envio do formulário,
- Envie uma solicitação assíncrona para a API Rick & Morty usando o termo de pesquisa,
- Exiba os resultados da solicitação na página.
Primeiro, precisamos criar um formulário e um elemento vazio que conterá nossos resultados de pesquisa, que se parece com isso:
<form> <label for="name">Find characters by name</label> <input type="text" name="name" required /> <button type="submit">Search</button> </form> <ul></ul>Em seguida, precisamos escrever uma função que lide com envios de formulários. Esta função irá:
- Impedir o comportamento de envio de formulário padrão
- Obter o termo de pesquisa da entrada do formulário
- Use a API Fetch para enviar uma solicitação à API Rick & Morty usando o termo de pesquisa
- Chame uma função auxiliar que exiba os resultados da pesquisa na página
Também precisamos adicionar um ouvinte de evento no formulário para o evento submit que chama nossa função de manipulador.
Veja como esse código se parece completamente:
<script type="module"> import showResults from './show-results.js'; const form = document.querySelector('form'); const handleSubmit = async event => { event.preventDefault(); // get the search term from the form input const name = form.elements['name'].value; // send a request to the Rick & Morty API based on the user input const characters = await fetch( `https://rickandmortyapi.com/api/character/?name=${name}`, ) .then(response => response.json()) .catch(error => console.error(error)); // add the search results to the DOM showResults(characters.results); }; form.addEventListener('submit', handleSubmit); </script>Observação: para manter o foco nos comportamentos dinâmicos do JAMstack, não discutiremos como as funções utilitárias como showResults são escritas. O código é completamente comentado, então confira a fonte para saber como ele funciona!
Com este código em vigor, podemos carregar nosso site em um navegador e veremos o formulário vazio sem resultados:
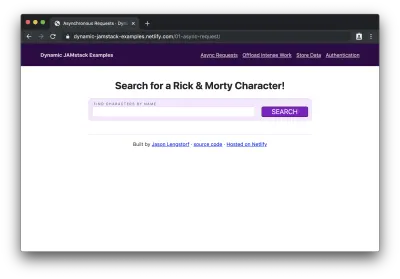
Se inserirmos um nome de personagem (por exemplo, “rick”) e clicarmos em “pesquisar”, veremos uma lista de personagens cujos nomes contêm “rick” exibida:
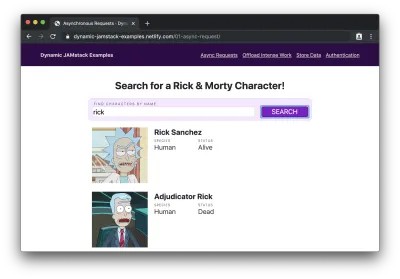
Ei! Esse site estático apenas carregou dados dinamicamente? Santos baldes!
Você pode experimentar isso por si mesmo na demonstração ao vivo ou confira o código-fonte completo para obter mais detalhes.
Lidar com tarefas de computação caras fora do dispositivo do usuário
Em muitos aplicativos, precisamos fazer coisas que consomem muitos recursos, como processar uma imagem. Embora alguns desses tipos de operações sejam possíveis usando apenas JavaScript do lado do cliente, não é necessariamente uma boa ideia fazer com que os dispositivos de seus usuários façam todo esse trabalho. Se eles estiverem em um dispositivo de baixa potência ou tentando estender os últimos 5% da vida útil da bateria, fazer com que o dispositivo faça muito trabalho provavelmente será uma experiência frustrante para eles.
Então isso significa que os aplicativos JAMstack estão sem sorte? De jeito nenhum!
O “A” no JAMstack significa APIs. Isso significa que podemos enviar esse trabalho para uma API e evitar girar os fãs do computador de nossos usuários para a configuração “hover”.
“Mas espere”, você pode dizer. “Se nosso aplicativo precisa fazer um trabalho personalizado e esse trabalho requer uma API, isso não significa apenas que estamos construindo um servidor?”
Graças ao poder das funções sem servidor, não precisamos!
As funções sem servidor (também chamadas de “funções lambda”) são uma espécie de API sem a necessidade de nenhum padrão de servidor. Podemos escrever uma função JavaScript simples e antiga, e todo o trabalho de implantação, dimensionamento, roteamento e assim por diante é transferido para nosso provedor sem servidor de escolha.
Usar funções sem servidor não significa que não haja um servidor; significa apenas que não precisamos pensar em um servidor.
“
As funções sem servidor são a manteiga de amendoim do nosso JAMstack: elas desbloqueiam um mundo inteiro de funcionalidades dinâmicas e de alta potência sem nunca nos pedir para lidar com código de servidor ou devops.
Demonstração: converter uma imagem em escala de cinza
Vamos supor que temos um aplicativo que precisa:
- Baixar uma imagem de um URL
- Converta essa imagem para tons de cinza
- Faça upload da imagem convertida para um repositório do GitHub
Até onde eu sei, não há como fazer conversões de imagem como essa inteiramente no navegador - e mesmo que houvesse, é uma coisa bastante intensiva de recursos, então provavelmente não queremos sobrecarregar nossos usuários ' dispositivos.
Em vez disso, podemos enviar a URL para ser convertida em uma função sem servidor, que fará o trabalho pesado para nós e enviará de volta uma URL para uma imagem convertida.
Para nossa função serverless, usaremos as funções Netlify. No código do nosso site, adicionamos uma pasta no nível raiz chamada “functions” e criamos um novo arquivo chamado “convert-image.js” dentro. Em seguida, escrevemos o que chamamos de manipulador, que é o que recebe e - como você deve ter adivinhado - trata das solicitações para nossa função sem servidor.
Para converter uma imagem, fica assim:
exports.handler = async event => { // only try to handle POST requests if (event.httpMethod !== 'POST') { return { statusCode: 404, body: '404 Not Found' }; } try { // get the image URL from the POST submission const { imageURL } = JSON.parse(event.body); // use a temporary directory to avoid intermediate file cruft // see https://www.npmjs.com/package/tmp const tmpDir = tmp.dirSync(); const convertedPath = await convertToGrayscale(imageURL, tmpDir); // upload the processed image to GitHub const response = await uploadToGitHub(convertedPath, tmpDir.name); return { statusCode: 200, body: JSON.stringify({ url: response.data.content.download_url, }), }; } catch (error) { return { statusCode: 500, body: JSON.stringify(error.message), }; } };Esta função faz o seguinte:
- Verifica se a solicitação foi enviada usando o método HTTP POST
- Pega o URL da imagem do corpo do POST
- Cria um diretório temporário para armazenar os arquivos que serão limpos assim que a função terminar de ser executada
- Chama uma função auxiliar que converte a imagem em tons de cinza
- Chama uma função auxiliar que carrega a imagem convertida no GitHub
- Retorna um objeto de resposta com um código de status HTTP 200 e o URL da imagem recém-carregada
Nota : Não vamos falar sobre como funciona o helper para conversão de imagem ou upload para o GitHub, mas o código fonte está bem comentado para que você possa ver como funciona.
Em seguida, precisamos adicionar um formulário que será usado para enviar as URLs para processamento e um local para mostrar o antes e o depois:
<form action="/.netlify/functions/convert-image" method="POST" > <label for="imageURL">URL of an image to convert</label> <input type="url" name="imageURL" required /> <button type="submit">Convert</button> </form> <div></div>Por fim, precisamos adicionar um ouvinte de evento ao formulário para que possamos enviar as URLs para nossa função sem servidor para processamento:
<script type="module"> import showResults from './show-results.js'; const form = document.querySelector('form'); form.addEventListener('submit', event => { event.preventDefault(); // get the image URL from the form const imageURL = form.elements['imageURL'].value; // send the image off for processing const promise = fetch('/.netlify/functions/convert-image', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ imageURL }), }) .then(result => result.json()) .catch(error => console.error(error)); // do the work to show the result on the page showResults(imageURL, promise); }); </script>Após implantar o site (junto com sua nova pasta “functions”) no Netlify e/ou iniciar o Netlify Dev em nossa CLI, podemos ver o formulário em nosso navegador:
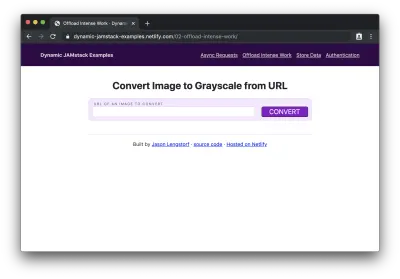
Se adicionarmos um URL de imagem ao formulário e clicarmos em “converter”, veremos “processando…” por um momento enquanto a conversão está acontecendo, então veremos a imagem original e sua contraparte em escala de cinza recém-criada:

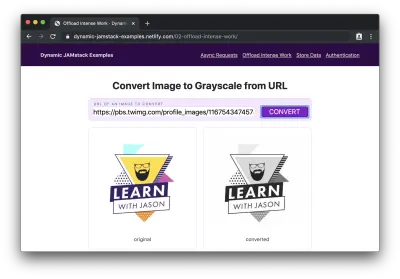
Oh droga! Nosso site JAMstack acabou de lidar com alguns negócios muito sérios e não tivemos que pensar em servidores uma vez ou esgotar as baterias de nossos usuários!
Use um banco de dados para armazenar e recuperar entradas
Em muitos aplicativos, inevitavelmente precisaremos da capacidade de salvar a entrada do usuário. E isso significa que precisamos de um banco de dados.
Você pode estar pensando: “Então é isso, certo? O gabarito está em alta? Certamente um site JAMstack – que você nos disse que é apenas uma coleção de arquivos em uma pasta – não pode ser conectado a um banco de dados!”
Au contraire.
Como vimos na seção anterior, as funções sem servidor nos dão a capacidade de fazer todo tipo de coisas poderosas sem precisar criar nossos próprios servidores.
Da mesma forma, podemos usar ferramentas de banco de dados como serviço (DBaaS) (como Fauna) para ler e gravar em um banco de dados sem precisar configurá-lo ou hospedá-lo.
As ferramentas DBaaS simplificam enormemente o processo de configuração de bancos de dados para sites: criar um novo banco de dados é tão simples quanto definir os tipos de dados que queremos armazenar. As ferramentas geram automaticamente todo o código para gerenciar as operações de criação, leitura, atualização e exclusão (CRUD) e o disponibilizam para uso via API, para que não precisemos realmente gerenciar um banco de dados; nós apenas começamos a usá -lo.
Demonstração: criar uma página de petição
Se quisermos criar um pequeno aplicativo para coletar assinaturas digitais para uma petição, precisamos configurar um banco de dados para armazenar essas assinaturas e permitir que a página as leia para exibição.
Para esta demonstração, usaremos o Fauna como nosso provedor de DBaaS. Não nos aprofundaremos em como o Fauna funciona, mas no interesse de demonstrar o pequeno esforço necessário para configurar um banco de dados, vamos listar cada etapa e clicar para obter um banco de dados pronto para uso:
- Crie uma conta Fauna em https://fauna.com
- Clique em “criar um novo banco de dados”
- Dê um nome ao banco de dados (por exemplo, “dynamic-jamstack-demos”)
- Clique em “criar”
- Clique em “segurança” no menu à esquerda na próxima página
- Clique em “nova chave”
- Altere a lista suspensa de funções para "Servidor"
- Adicione um nome para a chave (por exemplo, “Dynamic JAMstack Demos”)
- Armazene a chave em algum lugar seguro para uso com o aplicativo
- Clique em “salvar”
- Clique em “GraphQL” no menu à esquerda
- Clique em "importar esquema"
- Faça upload de um arquivo chamado
db-schema.gqlque contém o seguinte código:
type Signature { name: String! } type Query { signatures: [Signature!]! }Depois de fazer o upload do esquema, nosso banco de dados está pronto para uso. (A sério.)
Treze etapas é muito, mas com essas treze etapas, acabamos de obter um banco de dados, uma API GraphQL, gerenciamento automático de capacidade, dimensionamento, implantação, segurança e muito mais - tudo tratado por especialistas em banco de dados. De graça. Que tempo para estar vivo!
Para experimentá-lo, a opção “GraphQL” no menu à esquerda nos dá um explorador GraphQL com documentação sobre as consultas e mutações disponíveis que nos permitem realizar operações CRUD.
Nota : Não entraremos em detalhes sobre as consultas e mutações do GraphQL neste post, mas Eve Porcello escreveu uma excelente introdução ao envio de consultas e mutações do GraphQL se você quiser uma cartilha sobre como ele funciona.
Com o banco de dados pronto, podemos criar uma função serverless que armazena novas assinaturas no banco de dados:
const qs = require('querystring'); const graphql = require('./util/graphql'); exports.handler = async event => { try { // get the signature from the POST data const { signature } = qs.parse(event.body); const ADD_SIGNATURE = ` mutation($signature: String!) { createSignature(data: { name: $signature }) { _id } } `; // store the signature in the database await graphql(ADD_SIGNATURE, { signature }); // send people back to the petition page return { statusCode: 302, headers: { Location: '/03-store-data/', }, // body is unused in 3xx codes, but required in all function responses body: 'redirecting...', }; } catch (error) { return { statusCode: 500, body: JSON.stringify(error.message), }; } };Esta função faz o seguinte:
- Pega o valor da assinatura dos dados
POSTdo formulário - Chama uma função auxiliar que armazena a assinatura no banco de dados
- Define uma mutação do GraphQL para gravar no banco de dados
- Envia a mutação usando uma função auxiliar do GraphQL
- Redireciona de volta para a página que enviou os dados
Em seguida, precisamos de uma função serverless para ler todas as assinaturas do banco de dados para que possamos mostrar quantas pessoas apoiam nossa petição:
const graphql = require('./util/graphql'); exports.handler = async () => { const { signatures } = await graphql(` query { signatures { data { name } } } `); return { statusCode: 200, body: JSON.stringify(signatures.data), }; };Esta função envia uma consulta e a retorna.
Uma observação importante sobre chaves confidenciais e aplicativos JAMstack :
Uma coisa a notar sobre este aplicativo é que estamos usando funções sem servidor para fazer essas chamadas porque precisamos passar uma chave de servidor privada para Fauna que prova que temos acesso de leitura e gravação a esse banco de dados. Não podemos colocar essa chave no código do lado do cliente, porque isso significaria que qualquer pessoa poderia encontrá-la no código-fonte e usá-la para executar operações CRUD em nosso banco de dados. As funções sem servidor são essenciais para manter as chaves privadas em aplicativos JAMstack.
Assim que tivermos nossas funções serverless configuradas, podemos adicionar um formulário que envia à função para adicionar uma assinatura, um elemento para mostrar assinaturas existentes e um pouco de JS para chamar a função para obter assinaturas e colocá-las em nossa exibição elemento:
<form action="/.netlify/functions/add-signature" method="POST"> <label for="signature">Your name</label> <input type="text" name="signature" required /> <button type="submit">Sign</button> </form> <ul class="signatures"></ul> <script> fetch('/.netlify/functions/get-signatures') .then(res => res.json()) .then(names => { const signatures = document.querySelector('.signatures'); names.forEach(({ name }) => { const li = document.createElement('li'); li.innerText = name; signatures.appendChild(li); }); }); </script>Se carregarmos isso no navegador, veremos nosso formulário de petição com assinaturas abaixo:
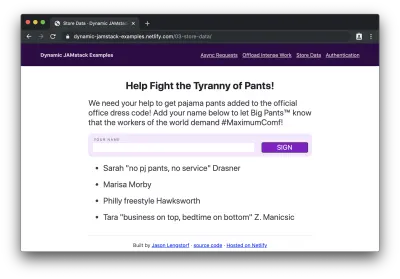
Então, se adicionarmos nossa assinatura…
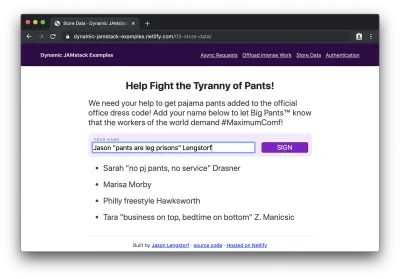
…e submetê-lo, veremos nosso nome anexado ao final da lista:
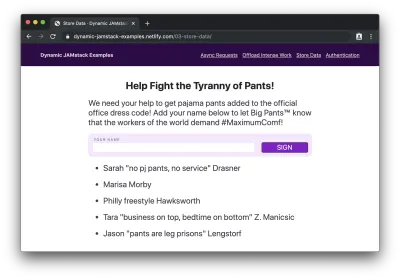
Cachorro gostoso! Acabamos de escrever um aplicativo JAMstack completo com banco de dados com cerca de 75 linhas de código e 7 linhas de esquema de banco de dados!
Proteja o conteúdo com autenticação do usuário
“Ok, você com certeza está preso desta vez”, você pode estar pensando. “Não há como um site JAMstack lidar com a autenticação do usuário. Como diabos isso funcionaria, mesmo?!”
Eu vou te dizer como funciona, meu amigo: com nossas funções confiáveis sem servidor e OAuth.
OAuth é um padrão amplamente adotado para permitir que as pessoas concedam aos aplicativos acesso limitado às informações de suas contas em vez de compartilhar suas senhas. Se você já fez login em um serviço usando outro serviço (por exemplo, “faça login com sua conta do Google”), você já usou o OAuth antes.
Observação: não vamos aprofundar como o OAuth funciona, mas Aaron Parecki escreveu uma visão geral sólida do OAuth que abrange os detalhes e o fluxo de trabalho.
Nos aplicativos JAMstack, podemos aproveitar o OAuth e os JSON Web Tokens (JWTs) que ele nos fornece para identificar usuários, proteger o conteúdo e permitir que apenas usuários logados o visualizem.
Demonstração: Exigir login para visualizar o conteúdo protegido
Se precisarmos construir um site que mostre conteúdo apenas para usuários logados, precisamos de algumas coisas:
- Um provedor de identidade que gerencia usuários e o fluxo de entrada
- Elementos de interface do usuário para gerenciar o login e o logout
- Uma função sem servidor que verifica se há um usuário conectado usando JWTs e retorna conteúdo protegido, se fornecido
Para este exemplo, usaremos o Netlify Identity, que nos dá uma experiência de desenvolvedor muito agradável para adicionar autenticação e fornece um widget drop-in para gerenciar ações de login e logout.
Para habilitá-lo:
- Visite seu painel Netlify
- Escolha o site que precisa de autenticação na sua lista de sites
- Clique em “identidade” na navegação superior
- Clique no botão "Ativar identidade"
Podemos adicionar o Netlify Identity ao nosso site adicionando marcação que mostra o conteúdo desconectado e adiciona um elemento para mostrar o conteúdo protegido após o login:
<div class="content logged-out"> <h1>Super Secret Stuff!</h1> <p> only my bestest friends can see this content</p> <button class="login">log in / sign up to be my best friend</button> </div> <div class="content logged-in"> <div class="secret-stuff"></div> <button class="logout">log out</button> </div>Essa marcação depende do CSS para mostrar o conteúdo com base em se o usuário está logado ou não. No entanto, não podemos confiar nisso para realmente proteger o conteúdo — qualquer um pode visualizar o código-fonte e roubar nossos segredos!
Em vez disso, criamos um div vazio que conterá nosso conteúdo protegido, mas precisaremos fazer uma solicitação a uma função sem servidor para realmente obter esse conteúdo. Vamos investigar como isso funciona em breve.
Em seguida, precisamos adicionar código para fazer nosso botão de login funcionar, carregar o conteúdo protegido e mostrá-lo na tela:
<script src="https://identity.netlify.com/v1/netlify-identity-widget.js"></script> <script> const login = document.querySelector('.login'); login.addEventListener('click', () => { netlifyIdentity.open(); }); const logout = document.querySelector('.logout'); logout.addEventListener('click', () => { netlifyIdentity.logout(); }); netlifyIdentity.on('logout', () => { document.querySelector('body').classList.remove('authenticated'); }); netlifyIdentity.on('login', async () => { document.querySelector('body').classList.add('authenticated'); const token = await netlifyIdentity.currentUser().jwt(); const response = await fetch('/.netlify/functions/get-secret-content', { headers: { Authorization: `Bearer ${token}`, }, }).then(res => res.text()); document.querySelector('.secret-stuff').innerHTML = response; }); </script>Veja o que esse código faz:
- Carrega o widget Netlify Identity, que é uma biblioteca auxiliar que cria um modal de login, lida com o fluxo de trabalho OAuth com o Netlify Identity e dá ao nosso aplicativo acesso às informações do usuário conectado
- Adiciona um ouvinte de evento ao botão de login que aciona o modal de login do Netlify Identity para abrir
- Adiciona um ouvinte de evento ao botão de logout que chama o método de logout do Netlify Identity
- Adiciona um manipulador de eventos para fazer logout para remover a classe autenticada no logout, que oculta o conteúdo conectado e mostra o conteúdo desconectado
- Adiciona um manipulador de eventos para fazer login que:
- Adiciona a classe autenticada para mostrar o conteúdo conectado e ocultar o conteúdo desconectado
- Pega o JWT do usuário conectado
- Chama uma função serverless para carregar conteúdo protegido, enviando o JWT no cabeçalho Authorization
- Coloca o conteúdo secreto na div secret-stuff para que os usuários logados possam vê-lo
No momento, a função serverless que estamos chamando nesse código não existe. Vamos criá-lo com o seguinte código:
exports.handler = async (_event, context) => { try { const { user } = context.clientContext; if (!user) throw new Error('Not Authorized'); return { statusCode: 200, headers: { 'Content-Type': 'text/html', }, body: `Você está convidado, ${user.user_metadata.full_name}!
Se você pode ler isso significa que somos melhores amigos.
Aqui estão os detalhes secretos da minha festa de aniversário:
`, }; } pegar (erro) { Retorna { código de status: 401, corpo: 'Não autorizado', }; } };
jason.af/party
Esta função faz o seguinte:
- Verifica se há um usuário no argumento de contexto da função sem servidor
- Lança um erro se nenhum usuário for encontrado
- Retorna o conteúdo secreto depois de garantir que um usuário conectado o solicitou
As funções Netlify detectarão JWTs de identidade Netlify nos cabeçalhos de autorização e colocarão automaticamente essas informações em contexto - isso significa que podemos verificar se há JWTs válidos sem precisar escrever código para validar JWTs!
Quando carregarmos esta página em nosso navegador, veremos primeiro a página desconectada:
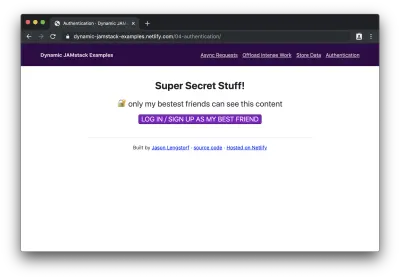
Se clicarmos no botão para fazer login, veremos o widget Netlify Identity:
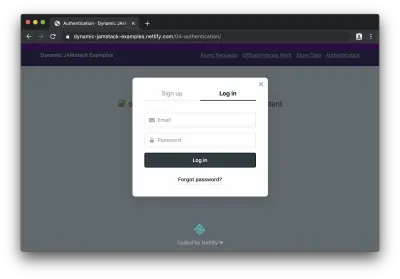
Após o login (ou inscrição), podemos ver o conteúdo protegido:
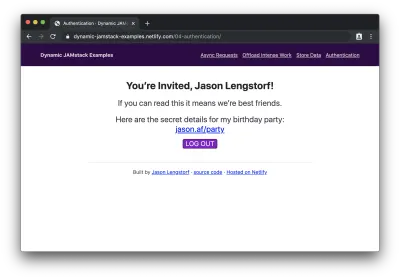
Uau! Acabamos de adicionar login de usuário e conteúdo protegido a um aplicativo JAMstack!
O que fazer a seguir
O JAMstack é muito mais do que “apenas sites estáticos” – podemos responder às interações do usuário, armazenar dados, lidar com a autenticação do usuário e praticamente qualquer outra coisa que queiramos fazer em um site moderno. E tudo sem a necessidade de provisionar, configurar ou implantar um servidor!
O que você quer construir com o JAMstack? Existe alguma coisa que você ainda não está convencido de que o JAMstack pode lidar? Eu adoraria ouvir sobre isso - me chame no Twitter ou nos comentários!