
Desenvolvendo para a Web Semântica
Publicados: 2022-03-10Em julho, a Wikimedia Foundation anunciou a Wikipédia Abstrata, uma tentativa de marcar conhecimento independente do idioma. Em muitos aspectos, este é o culminar de décadas de construção, durante as quais o sonho de uma Web Semântica nunca decolou, mas também nunca desapareceu completamente.
Na verdade, a Web Semântica está crescendo e, à medida que renova sua missão, todos temos a ganhar com a incorporação de marcação semântica em nossos sites, sejam eles blogs pessoais ou gigantes de mídia social. Se você se preocupa com experiências sofisticadas na web, SEO ou se defende da tirania dos monopólios da web, a Web Semântica merece nossa atenção.
Os benefícios do desenvolvimento para a Web Semântica nem sempre são imediatos ou visíveis, mas todo site que o faz fortalece as bases de uma internet aberta, transparente e descentralizada.
A Web Semântica
O que exatamente é a Web Semântica? É uma web legível por máquina, fornecendo por meio de metadados “uma estrutura comum que permite que os dados sejam compartilhados e reutilizados entre os limites do aplicativo, da empresa e da comunidade”.
A ideia é tão antiga quanto a própria World Wide Web. Mais velho, na verdade. Foi um ponto focal da proposta de 1989 de Tim Berners-Lee. Como ele destacou, não apenas os documentos devem formar teias, mas os dados dentro deles também devem:
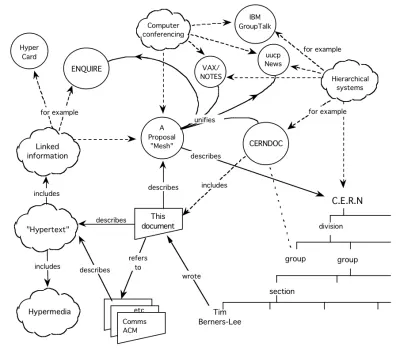
A Web Semântica trilha uma estrada pedregosa nas décadas seguintes. Desde a virada do milênio, ele se transformou em vários conceitos – dados abertos, gráficos de conhecimento – todos efetivamente significando a mesma coisa: teias de dados.
Como resume o W3C, é “uma extensão da web atual em que a informação recebe um significado bem definido, permitindo que computadores e pessoas trabalhem em cooperação”.

A ideia teve seu quinhão de defensores. O hacktivista da Internet Aaron Swartz escreveu um manuscrito de livro sobre a Web Semântica chamado A Programmable Web . Nele escreveu:
“Os documentos não podem realmente ser mesclados, integrados e consultados; eles servem principalmente como instâncias isoladas a serem vistas e revisadas. Mas os dados são multiformes, capazes de mudar para qualquer formato que melhor se adapte às suas necessidades.”
Por várias razões, a Web Semântica não decolou da mesma forma que a Web, embora esteja se recuperando. Várias marcações tentaram dominar o manto ao longo dos anos - RDFa, OWL e Schema, para citar alguns - embora nenhuma tenha se tornado padrão da maneira que, digamos, HTML ou CSS. A barreira de entrada era muito alta.
No entanto, o sonho da Web Semântica perdurou e, à medida que mais e mais sites a incorporam em seus projetos, há mais motivos para se juntar à festa. Quanto mais sites aderirem, mais forte a Web Semântica se tornará.
Leitura adicional
- Inteligência de dados
- A Web Semântica, um artigo de 2001 de Tim Berners-Lee, James Hensley e Ora Lassila
- Credible Web Community Group no W3C
Conhecimento sem fronteiras
Antes de entrar nas ervas daninhas de como projetar para a Web Semântica, vale a pena se aprofundar um pouco mais no porquê . O que importa se os dados estão conectados? Os documentos conectados não são suficientes?
Existem várias razões pelas quais a Web Semântica continua sendo impulsionada por aqueles que se preocupam com uma internet livre e aberta. Compreender essas razões é essencial para o processo de implementação. Não deveria ser um caso de 'coma seus vegetais, use marcação semântica'. A Web Semântica é algo para se acreditar e fazer parte.
Os benefícios da Web Semântica incluem:
- Experiências web mais ricas e sofisticadas
- Ignorando silos de conteúdo e monopólios da internet
- Melhor legibilidade e classificações do mecanismo de pesquisa
- Democratização da informação
A maioria deles pode ser rastreada até um princípio central da Web Semântica: uma linguagem universal para dados. Embora a internet já tenha feito maravilhas para a comunicação internacional, não há como escapar do fato de que alguns países a têm muito melhor do que outros. Veja os idiomas usados na web versus os idiomas usados no mundo real, por exemplo. Os olhos de águia entre vocês podem detectar um leve desequilíbrio nos dados abaixo…
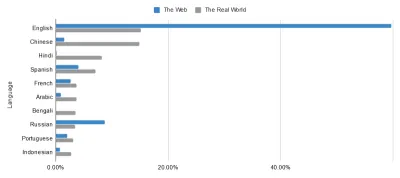
A utopia sem fronteiras da web não é tão próxima quanto parece para aqueles de nós dentro da bolha anglófona. Isso é algo para castigar alguém? Não necessariamente, mas é algo para enfrentar. Isso destaca a importância da marcação que preenche essas lacunas. Ao enriquecer os dados da web, tiramos a tensão de suas linguagens.
Este é o cerne da recém-anunciada Wikipédia Abstrata, que tentará separar os artigos do idioma em que foram escritos. A Diretora Executiva da Wikimedia, Katherine Maher, escreve: “Usando código, os voluntários poderão traduzir esses 'artigos' suas próprias línguas. Se for bem-sucedido, isso poderá permitir que todos leiam sobre qualquer tópico no Wikidata em seu próprio idioma.”
Resumo O criador da Wikipédia Denny Vrandecic tem sido um defensor da Web Semântica há anos, reconhecendo seu potencial para desbloquear um potencial inexplorado online. Quebrar as barreiras nacionais é essencial para esse processo.
“Não importa em que idioma você publica seu conteúdo, você vai perder a oportunidade de incluir a grande maioria das pessoas no mundo. A Web nos deu essa oportunidade maravilhosa de ter alcance global — mas ao confiar em um único idioma, ou em um pequeno conjunto de idiomas, estamos desperdiçando essa oportunidade. Embora o objetivo mais importante seja criar um bom conteúdo em primeiro lugar, você convida mais pessoas a participar do desenvolvimento de um conteúdo melhor sendo independente do idioma. Isso ajuda a reduzir as barreiras à contribuição e ao consumo e permite que muito mais pessoas se beneficiem desse esforço.”
— Denny Vrandecic, criador da Wikipédia abstrata
Um exemplo oportuno disso foi a visualização de dados durante a pandemia de COVID-19. O vírus causou estragos indescritíveis em todo o mundo, mas também foi um momento brilhante para redes de dados abertas, permitindo que aplicativos da Web excelentes, relatórios e muito mais sejam comuns em toda a Web.
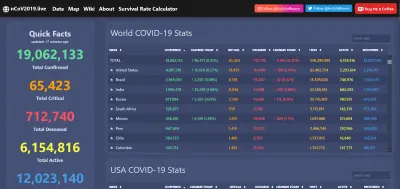
E, claro, quando os dados são transparentes e facilmente acessíveis, fica mais fácil identificar anomalias... ou enganos diretos. O acesso público generalizado ao tipo de informação acima seria impensável há 20 anos. Agora esperamos e cheiramos um rato quando nos é negado. Os dados são poderosos e, se quisermos, podem ser usados para sempre.
Da mesma forma, sair de silos de conteúdo – uma marca registrada da experiência moderna na web – tira o poder de monopólios da web como Google, Facebook e Twitter. Estamos tão acostumados a plataformas de terceiros decifrando e apresentando informações que esquecemos que elas não são estritamente necessárias.
“Se tivéssemos formatos compartilhados, protocolos compartilhados, ainda poderíamos acabar com certos provedores desempenhando um papel importante em certos mercados – pense no Gmail para e-mail – mas todos são livres para migrar para outro provedor e o mercado permanece competitivo.”
— Denny Vrandecic, criador da Wikipédia abstrata
A Web Semântica não possui silos; é gratuito, aberto e abstrato, permitindo a comunicação entre diferentes linguagens e plataformas que seriam muito mais difíceis de outra forma.
Conteúdo on-line de atualização de dados
Projetar para a Web Semântica se resume a conteúdo on-line de atualização de dados — examinar seu conteúdo e ver o que pode (e deve) ser abstraído. O que isso significa em termos práticos, além de concordar vagamente que vale a pena fazer? Depende:
- Se estiver começando um projeto do zero, incorpore as considerações da Web Semântica ao que você faz. À medida que um site toma forma, insira marcação semântica em seu DNA.
- Se estiver atualizando ou reconstruindo um projeto, avalie o que poderia ser integrado à Web Semântica que atualmente não está e, em seguida, implemente.
Ambos os casos basicamente equivalem a conteúdo de manipulação de dados. Nesta seção, veremos alguns exemplos de abstração de dados e como ela pode tornar o conteúdo melhor, mais inteligente e mais amplamente disponível.
Informações de abstração
Projetar e desenvolver para a Web Semântica significa olhar para o conteúdo online com seu chapéu de dados. A maioria de nós experimenta a web como uma série de documentos ou páginas de conexão; o que você quer fazer com a Web Semântica é conectar informações. Isso significa avaliar seu conteúdo para pontos de dados e ajustar o design com base no que você encontrar.
O defensor da Web Semântica, James Hendler, descreve esse processo particularmente bem com seu ethos DIVE. ( MERGULHE nos dados, hein? Hein?). Ele se decompõe da seguinte forma:
- Descobrir
Encontre conjuntos de dados e/ou conteúdo (inclusive fora de sua própria organização). - Integrar
Vincule as relações usando rótulos significativos. - Validar
Fornecer entradas para sistemas de modelagem e simulação. - Explorar
Desenvolva abordagens para transformar dados em conhecimento acionável.
Desenvolver para a Web Semântica é, em grande parte, ter essa visão panorâmica das coisas que você faz e como isso potencialmente alimenta experiências na Web infinitamente mais ricas. Como diz Hendler, o conhecimento acionável é o objetivo.
Isso realmente pode ser aplicado a quase qualquer tipo de conteúdo da web, mas vamos começar com um exemplo comum: receitas . Digamos que você tenha um blog de culinária, com novas receitas toda quinta-feira. Se você é francês e publica uma receita de suflê sensacional em seu blog pessoal em texto simples, é útil apenas para aqueles que sabem ler francês.
No entanto, ao implementar a marcação semântica, o blog pode ser transformado em um conjunto de dados de receita legível por máquina. A sintaxe existe para que os termos de culinária sejam abstraídos. Schema, por exemplo, que pode funcionar junto com Microdata, RDFa ou JSON-LD, tem marcação incluindo:
- tempo de preparação
- hora de cozinhar
- receitaRendimento
- receitaIngrediente
- custo estimado
- nutrição, quebrando em calorias e gorduraConteúdo
- adequadoParaDieta.
Eu poderia continuar. A gama completa de opções, com exemplos, pode ser lida em Schema.org. Ao adicioná-los ao formato do post, o formato da receita não precisa ser alterado - você está simplesmente colocando as informações em termos que os computadores possam entender.

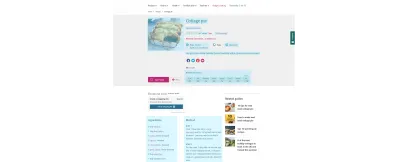
Por exemplo, tudo destacado em azul na receita da BBC acima também recebeu marcação semântica – desde o tempo de cozimento até o conteúdo nutricional. Você pode ver o que está acontecendo nos bastidores inserindo o URL da receita no Teste de pesquisa aprimorada do Google. Observe a funcionalidade 'Adicionar à lista de compras', um exemplo de conexão possibilitada pela implementação da Web Semântica. Um bom conteúdo se torna um dado utilizável.
A maioria de nós cruzou caminhos com esse tipo de sofisticação por meio de resultados de pesquisa, mas os aplicativos são muito mais amplos do que isso. A marcação semântica de receitas facilita a localização e o uso de sites por assistentes domésticos. Os ingredientes listados podem ser encomendados no supermercado local. As receitas podem ser filtradas de várias maneiras – para dietas, alergias, religião, custo, o que você quiser. Ou digamos que você tenha um número limitado de ingredientes em casa. Com um banco de dados, você pode inserir esses ingredientes e ver quais receitas se encaixam na conta.
A gama de possibilidades realmente beira o ilimitado. Como disse Swartz, os dados são multiformes. Depois de tê-lo, você pode usá-lo de todas as maneiras estranhas e maravilhosas. Esta peça não é sobre essas maneiras estranhas e maravilhosas, mas sim sobre torná-las possíveis. Projetar para a Web Semântica torna o projeto subsequente infinitamente mais rico.
Aqui está um exemplo mais pessoal para mostrar o que quero dizer. Alguns amigos e eu administramos um pequeno webzine de música como hobby. Embora publiquemos um artigo ou entrevista ímpar, o 'evento principal' são nossas resenhas semanais de álbuns, nas quais nós três atribuímos uma partitura, escolhemos as faixas favoritas e escrevemos resumos. Estamos trabalhando há mais de cinco anos, o que significa que temos cerca de 250 avaliações, o que significa uma quantidade enorme de dados em potencial. Nós não percebemos o quanto até que começamos a redesenhar o site.
Eu mencionei isso em um artigo sobre inserir dados estruturados no processo de design. Ao dissecar nossos comentários, percebemos que eles estavam repletos de informações que poderiam receber marcação semântica. Artistas, nomes de álbuns, arte, data de lançamento, pontuações individuais, pontuações gerais, tipo de lançamento e muito mais. Além do mais - e é aí que fica realmente empolgante - percebemos que poderíamos nos conectar a um banco de dados existente: MusicBrainz.
Essa abordagem de mão dupla é o cerne da Web Semântica. Quando nosso site de música for relançado, ele será sua própria fonte de dados aberta com milhares de pontos de dados exclusivos. Conectar-se a um banco de dados de música existente dará aos nossos próprios dados mais contexto – e potencial. Milhares de pontos de dados tornam-se dezenas de milhares de pontos de dados, talvez mais.
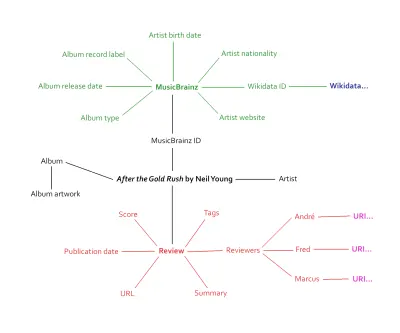
O gráfico acima apenas arranha a superfície de quanta informação será conectada às páginas de resenhas. O conteúdo é o mesmo de antes, só que agora está conectado a um ecossistema de metadados – o Giant Global Graph, como Berners-Lee o chamou.
Desenvolver para a Web Semântica significa identificar seus próprios dados, marcá-los e então descobrir como eles se conectam a outros dados. Porque ele faz. Sempre faz. E esse processo é assim…
… com o tempo se torna isso …
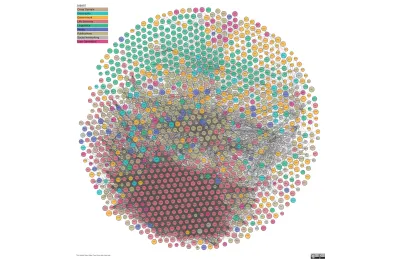
A segunda imagem é The Linked Open Data Cloud, uma visualização em constante atualização dos dados conectados da web. Essa colmeia vermelha de conexões são as ciências; o resto tem algum caminho a percorrer. É aí que entramos.
Recursos úteis da Web Semântica
- RDF em w3schools.com
- Validador de RDF do W3C
- “A Web Semântica Facilitada” por W3C
- “O que aconteceu com a Web Semântica?” por História de dois bits
- Gerador JSON-LD
- Assistente de marcação de dados estruturados do Google
Conectando
O ideal da Web Semântica é a conexão. Crie dados, compartilhe dados, exija dados. Faça parte de um ecossistema de informações. Quando você está criando dados originais, ótimo. Compartilhe. Quando os dados já existirem e você quiser usá-los, puxe-os.
Aqui estão apenas alguns dos recursos de dados disponíveis:
- DPpédia
- MusicBrainz
- WorldCat
- ISBNdb
De fato, onde existem bancos de dados como esses, eu diria que a coisa certa a fazer seria atualizá-los onde faltam informações. Por que guardá-lo para si mesmo? Torne-se um colaborador, um defensor da Web Semântica.
Implementação
No que diz respeito à construção da Semantic Webness em seus sites, certamente não estou defendendo a marcação manual, documento por documento. Quem tem tempo para isso? Na maioria das vezes, a solução é padronizar um formato e modelá-lo.
A modelagem é a grande oportunidade aqui. Quantas pessoas realmente têm tempo para marcar todas essas informações manualmente? No entanto, se você tiver entradas personalizadas, obterá o melhor dos dois mundos. O conteúdo pode ser preenchido com informações amigáveis às pessoas e as informações existem como dados prontos para servir a qualquer propósito que vier à mente.
Veja, por exemplo, um gerador de site estático como o Eleventy, que tem gostado um pouco da comunidade de desenvolvedores ultimamente. Você escreve um post, executa-o através de um modelo e você é ouro. Então, por que não incorporar a marcação semântica no próprio modelo?
Assim como o Eleventy, a nova versão do nosso site de música na web usa Markdown para seus posts. Embora tenhamos as mesmas postagens de texto antigas que sempre fizemos, cada revisão agora também inclui as seguintes entradas de metadados, que são então inseridas no modelo:
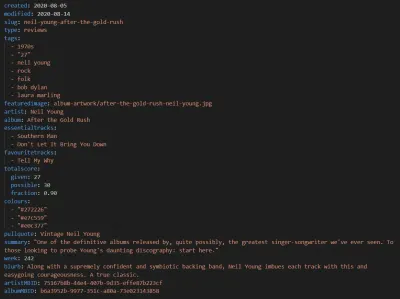
Juntamente com os detalhes do autor no corpo da postagem e algumas informações genéricas do site, isso se traduz na seguinte marcação semântica:
<script type="application/ld+json"> { "@context": "https://schema.org/", "@type": "Review", "reviewBody": "One of the definitive albums released by, quite possibly, the greatest singer-songwriter we've ever seen. To those looking to probe Young's daunting discography: start here.", "datePublished": "2020-08-14", "author": [{ "@type": "Person", "name": "Andre Dack" }, { "@type": "Person", "name": "Frederick O'Brien" }, { "@type": "Person", "name": "Marcus Lawrence" }], "itemReviewed": { "@type": "MusicAlbum", "name": "After the Gold Rush", "@id": "https://musicbrainz.org/release-group/b6a3952b-9977-351c-a80a-73e023143858", "image": "https://audioxide.com/images/album-artwork/after-the-gold-rush-neil-young.jpg", "albumProductionType": "https://schema.org/StudioAlbum", "albumReleaseType": "https://schema.org/AlbumRelease", "byArtist": { "@type": "MusicGroup", "name": "Neil Young", "@id": "https://musicbrainz.org/artist/75167b8b-44e4-407b-9d35-effe87b223cf" } }, "reviewRating": { "@type": "Rating", "ratingValue": 27, "worstRating": 0, "bestRating": 30 }, "publisher": { "@type": "Organization", "name": "Audioxide", "description": "Independent music webzine founded in 2015. Publishes reviews, articles, interviews, and other oddities.", "url": "https://audioxide.com", "logo": "https://audioxide.com/logo-location.jpg", "sameAs" : [ "https://facebook.com/audioxide", "https://twitter.com/audioxide", "https://instagram.com/audioxidecom" ] } } </script>Onde antes havia apenas texto, em cada página de revisão agora também haverá versões legíveis por máquina do que os leitores veem quando visitam o site. As palavras ainda estão lá, o conteúdo quase não mudou – foi apenas atualizado por dados. De resultados de pesquisa avançados a páginas de estatísticas de revisão interativas, isso aumenta enormemente o que é possível. A estrada à frente é larga e aberta. Também nos dá uma participação no futuro da MusicBrainz. Ao conectar os dados deles aos nossos próprios dados, queremos que eles funcionem bem e faremos nossa parte para garantir que isso aconteça.
A marcação semântica apropriada depende da natureza de um site, mas é provável que exista. Comece com as entradas óbvias (data, autor, tipo de conteúdo, etc.) e vá até as ervas daninhas do conteúdo. O primeiro passo pode ser tão simples quanto um hCard (uma espécie de cartão de identificação digital) para o seu site pessoal. Imprima capturas de tela das páginas e comece a anotar. Você ficará surpreso com a quantidade de conteúdo que pode ser atualizado por dados.
Além da imaginação
Projetar e desenvolver para a Web Semântica é uma prática que remonta aos ideais fundadores da Internet. Se você valoriza a visualização de dados bonita e informativa, deseja resultados de pesquisa mais sofisticados, deseja remover o poder dos monopólios da web ou simplesmente acredita em informações gratuitas e abertas, a Web Semântica é sua aliada.
Aaron Swartz encerrou seu manuscrito com um chamado à esperança:
“A Web Semântica é baseada na aposta, uma aposta de que dar ao mundo ferramentas para colaborar e se comunicar facilmente levará a possibilidades tão maravilhosas que mal podemos imaginá-las agora.”
Resumo Wikipedia Denny Vrandecic ecoa esses sentimentos hoje, dizendo:
“Há uma necessidade de uma infraestrutura da web que facilite a interoperabilidade entre os serviços, o que requer um conjunto comum de padrões para representar dados e protocolos comuns entre os provedores.”
A Web Semântica tem se arrastado por tempo suficiente para ficar claro que é improvável que uma linguagem de bala de prata apareça, mas agora há o suficiente coexistindo pacificamente para que o sonho fundador de Berners-Lee seja uma realidade para a maior parte da web. Cada um de nós pode ser defensor em nossos próprios bairros.
Seja melhor, exija melhor
Como disse Tim Berners-Lee, a Web Semântica é tanto uma cultura quanto um obstáculo técnico. Em um TED Talk de 2009, ele resumiu bem: crie dados vinculados, exija dados vinculados . Isso é mais verdadeiro agora do que nunca. A World Wide Web é tão aberta, conectada e boa quanto a forçamos a ser. Sempre que você fizer algo online, pergunte a si mesmo: “Como isso pode se conectar à Web Semântica?” As respostas adicionarão novas dimensões às coisas que criamos e criarão novas possibilidades inimaginavelmente maravilhosas nos próximos anos.