
Deve ler 24 perguntas e respostas da entrevista do Datastage [Guia definitivo 2022]
Publicados: 2021-01-08Datastage é uma ferramenta ETL, ou seja, Extrair, Transformar e Carregar fornecida pela IBM em seu conjunto InfoSphere e conjunto de Plataformas de Soluções de Informação. É uma ferramenta ETL popular e é usada para trabalhar com grandes conjuntos de dados e armazéns para criar e manter os repositórios de dados. Neste artigo, veremos as perguntas mais frequentes da entrevista do DataStage e também forneceremos as respostas para essas perguntas. Se você é iniciante e está interessado em aprender mais sobre ciência de dados, confira nosso treinamento em ciência de dados das melhores universidades.
As perguntas e respostas mais comuns da entrevista do DataStage são as seguintes:
Índice
Perguntas e respostas da entrevista do DataStage
1. O que é o IBM DataStage e por que ele é usado?
DataStage é uma ferramenta fornecida pela IBM e usada para projetar, desenvolver e executar os aplicativos para preencher os dados em data warehouses, extraindo os dados de bancos de dados de servidores Windows. Ele contém o recurso de visualizações gráficas para integrações de dados e também pode extrair dados de várias fontes. É, portanto, considerada uma das ferramentas ETL mais potentes. O DataStage possui várias versões que as empresas podem usar com base em seus requisitos. As versões são Server Edition, MVS Edition e Enterprise Edition.
2. Quais são as características do DataStage?
As características do IBM DataStage são as seguintes:
- Ele pode ser implantado em servidores locais, bem como na nuvem, conforme a necessidade e o requisito.
- É fácil de usar e pode aumentar a velocidade e a flexibilidade da integração de dados com eficiência.
- Ele suporta big data e pode acessar big data de várias maneiras, como integrador JDBC, suporte JSON e sistemas de arquivos distribuídos.
3. Descreva brevemente a arquitetura do DataStage.
O IBM DataStage segue um modelo cliente-servidor como sua arquitetura e possui diferentes tipos de arquitetura para suas diversas versões. Os componentes da arquitetura cliente-servidor são:
- Componentes do cliente
- Servidores
- Estágios
- Definições de tabela
- Containers
- Projetos
- Empregos
4. Como podemos executar um trabalho usando a linha de comando no DataStage?
O comando é: dsjob -run -jobstatus <projectname> <jobname>
5. Liste algumas funções que podemos executar usando o comando 'dsjob'.
As diferentes funções que podemos realizar usando o comando $dsjob são:
- $dsjob -run: é usado para executar o trabalho do DataStage
- $dsjob -stop: É usado para parar o trabalho que está presente no processo
- $dsjob -jobid: É usado para fornecer as informações do trabalho
- $dsjob -report: É usado para exibir o relatório completo do trabalho
- $dsjob -lprojects: É usado para listar todos os projetos que estão presentes
- $dsjob -ljobs: É usado para listar todos os trabalhos que estão presentes no projeto
- $dsjob -lstages: É usado para listar todos os estágios do trabalho atual
- $dsjob -llinks: É usado para listar todos os links
- $dsjobs -lparams: É usado para listar todos os parâmetros do trabalho
- $dsjob -projectinfo: É usado para recuperar as informações sobre o projeto
- $dsjob -jobinfo: É usado para a recuperação de informações do trabalho
- $dsjob -stageinfo: É usado para a recuperação de informações desse estágio desse trabalho
- $dsjob -linkinfo: É usado para obter as informações desse link
- $dsjob -paraminfo: Fornece as informações de todos os parâmetros
- $dsjob -loginfo: É usado para obter as informações sobre o log
- $dsjob -log: É usado para adicionar uma mensagem de texto no log
- $dsjob -logsum: É usado para exibir os dados de log
- $dsjob -logdetail: É usado para exibir todos os detalhes do log
- $dsjob -lognewest: É usado para recuperar o id do log mais recente
6. O que é um designer de fluxo no IBM DataStage?
O designer de fluxo é a interface do usuário baseada na Web do DataStage e é usado para criar, editar, carregar e executar os trabalhos no DataStage.
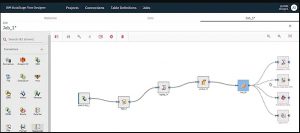
Fonte
7. Quais são as principais características do designer de fluxo?
As principais características do designer de fluxo são:
- É muito útil para realizar trabalhos com um grande número de estágios.
- Não há necessidade de migrar os trabalhos para usar o designer de fluxo.
- Podemos usar a paleta fornecida para adicionar e remover conectores e operadores na tela do designer usando o recurso de arrastar e soltar.
Saiba mais sobre: Data Science vs Data Mining: Diferença entre Data Science e Data Mining
8. Como converter um trabalho de servidor em um trabalho paralelo no DataStage?
Um trabalho do servidor pode ser convertido em um trabalho paralelo usando um coletor de link e um coletor de IPC.
9 . O que é um conector HBase?
Um conector HBase no DataStage é uma ferramenta usada para conectar bancos de dados e tabelas presentes no banco de dados HBase. É usado principalmente para executar as seguintes tarefas:
- Ler e gravar dados de e para o banco de dados HBase.
- Lendo dados no modo paralelo.
- Usando o HBase como uma tabela de visualização
10. O que é um conector Hive?
O conector Hive é uma ferramenta usada para dar suporte aos modos de partição durante a leitura dos dados. Pode ser feito de duas maneiras:
- modo de partição módulo
- modo de partição mínimo-máximo
11. O que é Infosphere no DataStage?
O servidor de informações infosphere é capaz de gerenciar os requisitos de alto volume das empresas e entrega resultados de alta qualidade e mais rápidos. Ele fornece às empresas uma plataforma única para gerenciar os dados onde elas podem entender, limpar, transformar e fornecer enormes quantidades de informações.


Fonte
12. Listar todas as diferentes camadas do InfoSphere Information Server?
As diferentes camadas do InfoSphere Information Server são:
- Nível do cliente
- Nível de serviços
- Nível do mecanismo
- Camada do repositório de metadados
13. Descreva brevemente a camada Cliente do Infosphere Information Server.
A camada cliente do Infosphere Information Server é usada para o desenvolvimento e a administração completa dos computadores usando os programas cliente e consoles.
14. Descreva brevemente a camada de Serviços do Infosphere Information Server.
A camada de serviços do Infosphere Information Server é usada para fornecer serviços padrão como metadados e log e alguns outros serviços específicos do módulo. Ele contém um servidor de aplicativos, vários módulos de produtos e outros serviços de produtos.
15. Descreva brevemente a camada de mecanismo do Infosphere Information Server.
A camada de mecanismo do Infosphere Information Server é um conjunto de componentes lógicos usados para executar as tarefas e outras tarefas para os módulos do produto.
16. Descreva brevemente a camada do Repositório de Metadados do Infosphere Information Server.
A camada do repositório de metadados do Infosphere Information Server inclui o repositório de metadados, o banco de dados de análise e o computador. Ele é usado para compartilhar os metadados, dados compartilhados e informações de configuração.
17. Quais são os tipos de processamento paralelo no DataStage?
Existem dois tipos diferentes de processamento paralelo, que são:
- Particionamento de dados
- Pipeline de dados
18 . O que é particionamento de dados?
O particionamento de dados é um tipo de abordagem paralela para processamento de dados. Envolve o processo de dividir os registros em partições para o processamento. Aumenta a eficiência do processamento em um modelo linear.
Leia mais: Pré-processamento de dados em aprendizado de máquina: 7 etapas fáceis a seguir
19. O que é Pipeline de Dados?
O Data Pipelining é um tipo de abordagem paralela para processamento de dados onde realizamos a extração de dados da fonte e depois os fazemos passar por uma sequência de funções de processamento para obter a saída necessária.
20. O que é SST no DataStage?
OSH é uma abreviação de Orchestrate Shell e é uma linguagem de script usada no DataStage internamente pelo mecanismo paralelo.
21. O que são Jogadores?
Os players no DataStage são os processos de trabalho pesado. Eles nos ajudam a realizar o processamento paralelo e são atribuídos aos operadores em cada nó.
22. O que é uma biblioteca de coleções no DataStage?
As bibliotecas de coleção são o conjunto de operadores e são usadas para coletar os dados particionados.
23. Quais são os tipos de coletores disponíveis na biblioteca de coleções do DataStage?
Os tipos de colecionadores disponíveis na biblioteca de coleções são:
- Coletor de classificação
- Coletor de rodízios
- Coletor encomendado
24. Como o arquivo de origem é preenchido no DataStage?
O arquivo de origem pode ser preenchido usando consultas SQL e também usando a ferramenta de extração do gerador de linhas.
Resultado final
Esperamos que nosso artigo contendo todas as perguntas e respostas da entrevista do DataStage tenha ajudado você a se preparar para a entrevista do DataStage. Você pode dar uma olhada nestes cursos oferecidos pelo upGrad para aumentar seu conhecimento sobre estes tópicos:
- PG Diploma em Desenvolvimento de Software Especialização em Big Data : Este curso é criado pelo upGrad em associação com o IIIT-B para fornecer aos indivíduos o conhecimento necessário para o desenvolvimento de software e abranger o conhecimento sobre o gerenciamento de Big Data.
- PGC em Desenvolvimento Full Stack : Este curso sobre desenvolvimento full-stack é criado por upGrad e profissionais da indústria da Tech Mahindra para tornar os indivíduos capazes de resolver desafios no nível da indústria e obter todas as habilidades necessárias para entrar e trabalhar nas indústrias.
Nós da upGrad estamos sempre lá para ajudá-lo com sua preparação. Você também pode ver nossos cursos que podem ajudá-lo a aprender todas as habilidades e técnicas exigidas pelo setor para se preparar bem para suas entrevistas e futuras ambições de trabalho, como sempre dizemos 'Raho Ambicioso'. Esses cursos foram feitos por especialistas do setor e acadêmicos experientes para torná-lo capaz de se tornar proficiente em qualquer tecnologia e habilidades que deseja aprender.
Se você estiver interessado em aprender python e quiser colocar a mão na massa em várias ferramentas e bibliotecas, confira Programa PG Executivo em Ciência de Dados.
Quais são os quatro estágios principais do Datastage?
O IBM Datastage é uma ferramenta poderosa para projetar, desenvolver e executar os aplicativos para preencher os dados em data warehouses, extraindo os dados dos bancos de dados. Abaixo estão as quatro principais etapas do Datastage. Administrador é usado para tarefas de administração que incluem a configuração de usuários do DataStage e critérios de eliminação, mobilização e desmobilização de projetos, etc. O designer ou interface de design desenvolve os aplicativos OU trabalhos do Datastage que são regulados pelo diretor e executados pelo servidor. Como o nome sugere, o gerenciador mantém e gerencia os repositórios e permite que os usuários modifiquem os dados armazenados por meio dele. O diretor executa várias funções, incluindo validar os trabalhos, escaloná-los e executá-los juntamente com o monitoramento dos trabalhos paralelos.
Para quais propósitos, o comando “dsjob” é usado?
O comando dsjob é usado para várias funções, incluindo recuperação e exibição de dados sobre projetos ou trabalhos. Aqui estão algumas das funções que podem ser executadas usando o comando dsjob. $dsjob -run usado para executar o trabalho do DataStage, $dsjob -stop usado para parar o trabalho que está atualmente presente no processo, $dsjob -jobid usado para fornecer as informações do trabalho, $dsjob -report usado para exibir o relatório completo do trabalho , etc
Quais são as características do DataStage?
O Datastage é uma poderosa ferramenta de arquitetura de dados e possui várias características. Algumas das características do Datastage são as seguintes: O Datastage pode ser implantado nos servidores locais e nos servidores em nuvem, dependendo dos requisitos do usuário. A velocidade e a flexibilidade da integração de dados podem ser aumentadas a qualquer momento e podem ser usadas com eficiência. Ele suporta big data e pode acessar big data de várias maneiras, como integrador JDBC, suporte JSON e sistemas de arquivos distribuídos.