
A melhor folha de dicas de ciência de dados que todos os cientistas de dados deveriam ter
Publicados: 2021-01-29Para todos os profissionais iniciantes e novatos que estão pensando em mergulhar no mundo em expansão da ciência de dados, compilamos uma folha de dicas rápida para você se atualizar com os conceitos básicos e as metodologias que destacam esse campo.
Índice
Ciência de dados - o básico
Os dados que são gerados em nosso mundo estão em uma forma bruta, ou seja, números, códigos, palavras, frases, etc. A Ciência de Dados usa esses dados brutos para processá-los usando métodos científicos para transformá-los em formas significativas para obter conhecimento e insights .
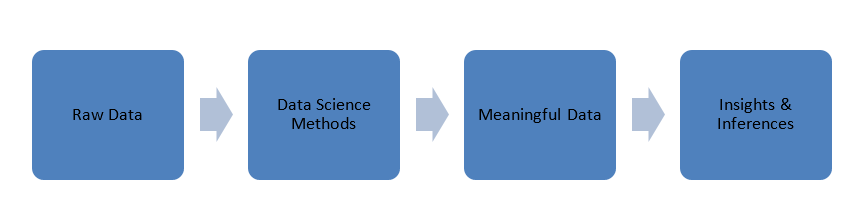
Dados
Antes de mergulharmos nos princípios da ciência de dados, vamos falar um pouco sobre dados, seus tipos e processamento de dados.
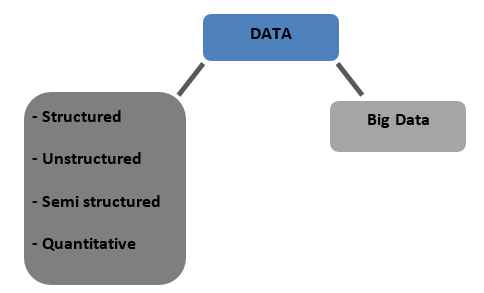
Tipos de dados
Estruturado – Dados que são armazenados em formato tabulado em bancos de dados. Pode ser numérico ou texto
Não estruturados – Dados que não podem ser tabulados com qualquer estrutura definitiva são chamados de dados não estruturados
Semiestruturado – Dados mistos com características de dados estruturados e não estruturados
Quantitativo – Dados com valores numéricos definidos que podem ser quantificados
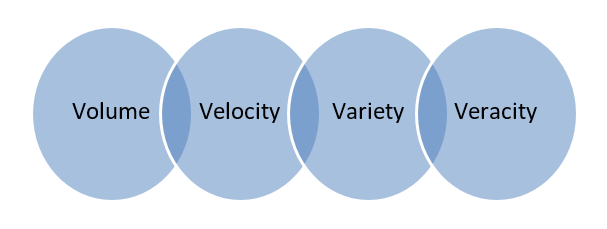
Big Data – Dados armazenados em enormes bancos de dados que abrangem vários computadores ou farms de servidores são chamados de Big Data. Dados biométricos, dados de mídia social etc. são considerados Big Data. Big data é caracterizado por 4 V's
Pré-processamento de dados
Classificação de dados – É o processo de categorizar ou rotular dados em classes como numérica, textual ou imagem, texto, vídeo, etc.
Limpeza de dados – Consiste em eliminar dados ausentes/inconsistentes/incompatíveis ou substituir dados usando um dos seguintes métodos.
- Interpolação
- Heurística
- Tarefa aleatória
- Vizinho mais próximo
Mascaramento de dados – Ocultar ou mascarar dados confidenciais para manter a privacidade de informações confidenciais enquanto ainda é possível processá-las.
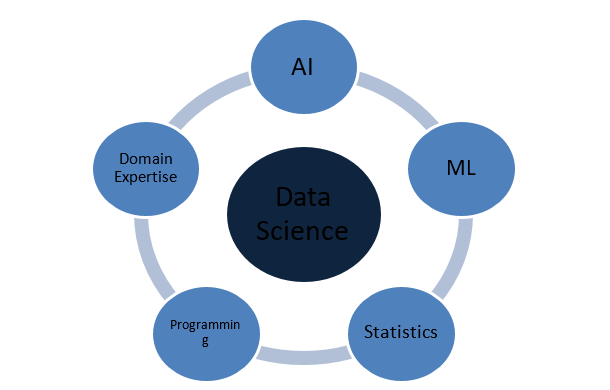
Do que é feita a Ciência de Dados?
Conceitos de Estatística
Regressão
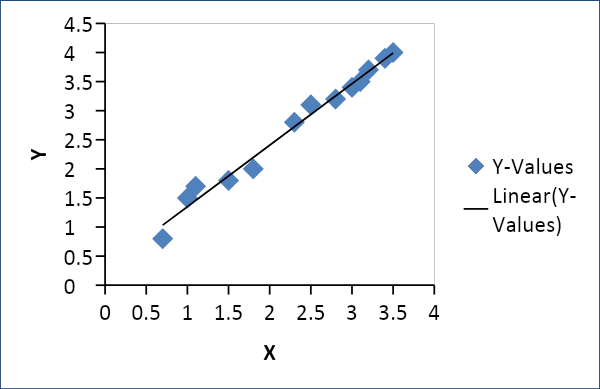
Regressão linear
A Regressão Linear é usada para estabelecer uma relação entre duas variáveis, como oferta e demanda, preço e consumo, etc. Ela relaciona uma variável x como uma função linear de outra variável y da seguinte forma
Y = f(x) ou Y = mx + c, onde m = coeficiente
Regressão logística
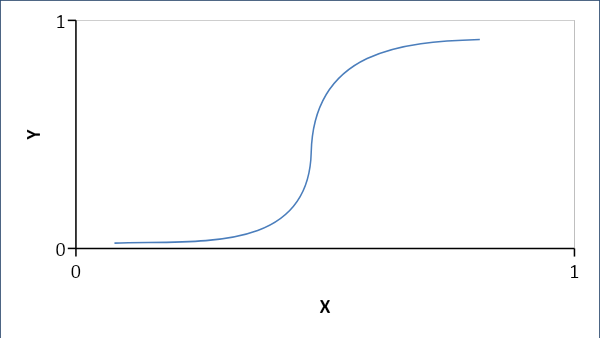
A regressão logística estabelece uma relação probabilística e não linear entre as variáveis. A resposta resultante é 0 ou 1 e procuramos probabilidades e a curva é em forma de S.
Se p < 0,5, então é 0 senão 1
Fórmula:
Y = e^ (b0 + b1x) / (1 + e^ (b0 +b1x))
onde b0 = viés e b1 = coeficiente
Probabilidade
A probabilidade ajuda a prever a probabilidade de ocorrência de um evento. Algumas terminologias:
Amostra: O conjunto de resultados prováveis
Evento: É um subconjunto do espaço amostral
Variável Aleatória: Variáveis aleatórias ajudam a mapear ou quantificar resultados prováveis para números ou uma linha em um espaço amostral
Distribuições de probabilidade
Distribuições Discretas: Dá a probabilidade como um conjunto de valores discretos (inteiro)
P[X=x] = p(x)
 Fonte da imagem
Fonte da imagem
Distribuições Contínuas: Dá a probabilidade sobre um número de pontos ou intervalos contínuos em vez de valores discretos. Fórmula:
P[a ≤ x ≤ b] = a∫bf(x) dx, onde a, b são os pontos
Origem da imagem
Correlação e Covariância
Desvio Padrão: A variação ou desvio de um determinado conjunto de dados de seu valor médio
σ = √ {(Σi=1N ( xi – x ) ) / (N -1)}
Covariância
Ele define a extensão do desvio das variáveis aleatórias X e Y com a média do conjunto de dados.
Cov(X,Y) = σ2XY= E[(X−μX)(Y−μY)] = E[XY]−μXμY
Correlação
Correlação define a extensão de uma relação linear entre variáveis juntamente com sua direção, +ve ou -ve
ρXY= σ2XY/ σX * *σY
Inteligência artificial
A capacidade das máquinas de adquirir conhecimento e tomar decisões com base em insumos é chamada de Inteligência Artificial ou simplesmente IA.
Tipos
- Máquinas reativas: a IA de máquina reativa funciona aprendendo a reagir a cenários predefinidos, limitando-se às opções mais rápidas e melhores. Eles não têm memória e são melhores para tarefas com um conjunto definido de parâmetros. Altamente confiável e consistente.
- Memória limitada: esta IA tem alguns dados observacionais e legados do mundo real alimentados a ela. Ele pode aprender e tomar decisões com base nos dados fornecidos, mas não pode obter novas experiências.
- Teoria da Mente: É uma IA interativa que pode tomar decisões com base no comportamento das entidades circundantes.
- Autoconsciência: Esta IA está ciente de sua existência e funcionamento independentemente do ambiente. Ele pode desenvolver habilidades cognitivas e entender e avaliar os impactos de suas próprias ações no ambiente.
Termos de IA
Redes neurais
Redes neurais são um grupo ou rede de nós interconectados que retransmitem dados e informações em um sistema. NNs são modelados para imitar neurônios em nossos cérebros e podem tomar decisões aprendendo e prevendo.
Heurística
Heurística é a capacidade de prever com base em aproximações e estimativas rapidamente usando experiência anterior em situações em que as informações disponíveis são irregulares. É rápido, mas não preciso ou preciso.
Raciocínio baseado em Casos
A capacidade de aprender com casos anteriores de resolução de problemas e aplicá-los em situações atuais para chegar a uma solução aceitável
Processamento de linguagem natural
É simplesmente a capacidade de uma máquina de entender e interagir diretamente na fala ou texto humano. Por exemplo, comandos de voz em um carro
Aprendizado de máquina
Machine Learning é simplesmente uma aplicação de IA usando vários modelos e algoritmos para prever e resolver problemas.
Tipos

Supervisionado
Esse método depende de dados de entrada que são associativos aos dados de saída. A máquina é fornecida com um conjunto de variáveis alvo Y e deve chegar à variável alvo através de um conjunto de variáveis de entrada X sob a supervisão de um algoritmo de otimização. Exemplos de aprendizado supervisionado são Redes Neurais, Floresta Aleatória, Aprendizado Profundo, Máquinas de Vetor de Suporte, etc.
Sem supervisão
Nesse método, as variáveis de entrada não têm rotulagem ou associação, e os algoritmos trabalham para encontrar padrões e clusters, resultando em novos conhecimentos e insights.
Reforçado
A aprendizagem reforçada concentra-se em técnicas de improvisação para aprimorar ou polir o comportamento de aprendizagem. É um método baseado em recompensas onde a máquina melhora gradualmente suas técnicas para ganhar uma recompensa alvo.
Métodos de modelagem
Regressão
Os modelos de regressão sempre fornecem números como saída por meio de interpolação ou extrapolação de dados contínuos.
Classificação
Os modelos de classificação apresentam resultados como uma classe ou rótulo e são melhores em prever resultados discretos como 'que tipo'
Tanto a regressão quanto a classificação são modelos supervisionados.
Agrupamento
Clustering é um modelo não supervisionado que identifica clusters com base em características, atributos, recursos, etc.
Algoritmos de ML
Árvores de decisão
As árvores de decisão usam uma abordagem binária para chegar a uma solução baseada em perguntas sucessivas em cada estágio, de modo que o resultado seja um dos dois possíveis, como 'Sim' ou 'Não'. As árvores de decisão são simples de implementar e interpretar.
Floresta aleatória ou ensacamento
Random Forest é um algoritmo avançado de árvores de decisão. Ele usa um grande número de árvores de decisão o que torna a estrutura densa e complexa como uma floresta. Ele gera vários resultados e, portanto, leva a resultados e desempenho mais precisos.
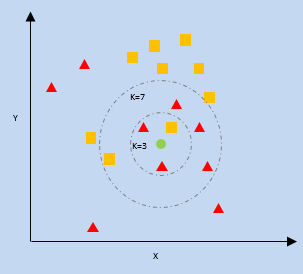
K- Vizinho mais próximo (KNN)
O kNN usa a proximidade dos pontos de dados mais próximos em um gráfico em relação a um novo ponto de dados para prever em qual categoria ele se enquadra. O novo ponto de dados é atribuído à categoria com maior número de vizinhos.
k = número de vizinhos mais próximos
Baías ingénuas
Naive Bayes trabalha em dois pilares, primeiro que todas as características dos pontos de dados são independentes, não relacionadas entre si, ou seja, únicas, e segundo no teorema de Bayes que prevê resultados com base em uma condição ou hipótese.
Teorema de Bayes:
P(X|Y) = {P(Y|X) * P(X)} / P(Y)
Onde P(X|Y) = Probabilidade condicional de X dada a ocorrência de Y
P(Y|X) = Probabilidade condicional de Y dada a ocorrência de X
P(X), P(Y) = Probabilidade de X e Y individualmente
Máquinas de vetor de suporte
Este algoritmo tenta segregar dados no espaço com base em limites que podem ser uma linha ou um plano. Esse limite é chamado de 'hiperplano' e é definido pelos pontos de dados mais próximos de cada classe que, por sua vez, são chamados de 'vetores de suporte'. A distância máxima entre os vetores de suporte de cada lado é chamada de margem.
Redes neurais
Perceptron
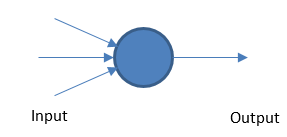
A rede neural fundamental funciona tomando entradas e saídas ponderadas com base em um valor limite.
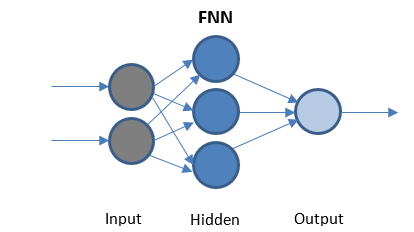
Rede Neural de Avanço
FFN é a rede mais simples que transmite dados em apenas uma direção. Pode ou não ter camadas ocultas.
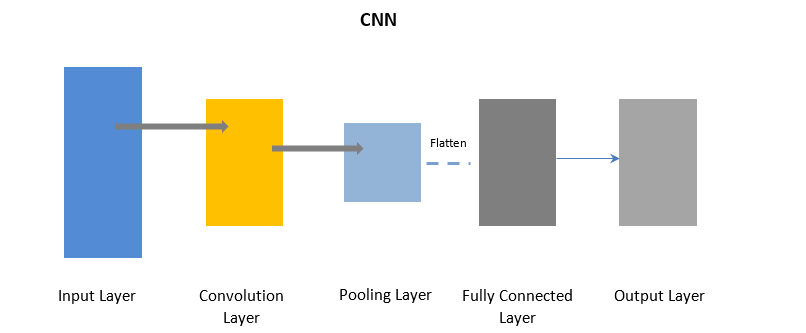
Redes Neurais Convolucionais
A CNN usa uma camada de convolução para processar certas partes dos dados de entrada em lotes, seguidas por uma camada de pooling para concluir a saída.
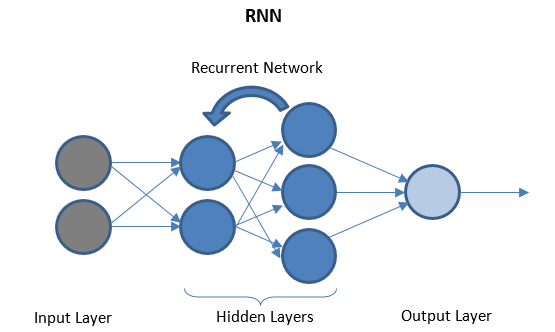
Redes Neurais Recorrentes
A RNN consiste em algumas camadas recorrentes entre camadas de E/S que podem armazenar dados 'históricos'. O fluxo de dados é bidirecional e é alimentado às camadas recorrentes para melhorar as previsões.
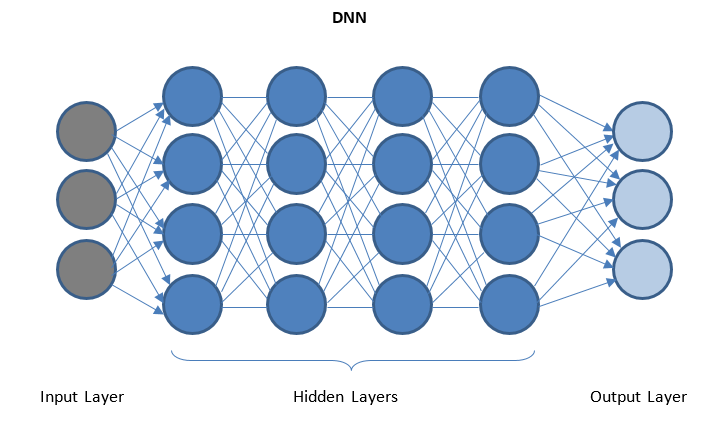
Deep Neural Networks e Deep Learning
DNN é uma rede com várias camadas ocultas entre as camadas de E/S. As camadas ocultas aplicam transformações sucessivas aos dados antes de enviá-los para a camada de saída.
O 'Deep Learning' é facilitado por meio de DNN e pode lidar com grandes quantidades de dados complexos e alcançar alta precisão devido a várias camadas ocultas
Obtenha a certificação em ciência de dados das melhores universidades do mundo. Aprenda Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.
Conclusão
A ciência de dados é um campo vasto que percorre diferentes fluxos, mas surge como uma revolução e uma revelação para nós. A ciência de dados está crescendo e mudará a forma como nossos sistemas funcionam e se sentem no futuro.
Se você está curioso para aprender sobre ciência de dados, confira o PG Diploma in Data Science do IIIT-B & upGrad, que é criado para profissionais que trabalham e oferece mais de 10 estudos de caso e projetos, workshops práticos práticos, orientação com especialistas do setor, 1- on-1 com mentores do setor, mais de 400 horas de aprendizado e assistência de trabalho com as principais empresas.
Qual linguagem de programação é mais adequada para Data Science e por quê?
Existem dezenas de linguagens de programação para ciência de dados por aí, mas a maioria da comunidade de ciência de dados acredita que, se você deseja se destacar em ciência de dados, o Python é a escolha certa. Abaixo estão algumas das razões que apoiam essa crença:
1. O Python possui uma ampla variedade de módulos e bibliotecas, como TensorFlow e PyTorch, que facilitam o manuseio de conceitos de ciência de dados.
2. Uma vasta comunidade de desenvolvedores Python ajuda constantemente os novatos a passar para a próxima fase de sua jornada de ciência de dados.
3. Esta linguagem é de longe uma das linguagens mais convenientes e fáceis de escrever com uma sintaxe limpa que melhora sua legibilidade.
Quais são os conceitos que tornam a ciência de dados completa?
Data Science é um vasto domínio que atua como um guarda-chuva para vários outros domínios cruciais. A seguir estão os conceitos mais proeminentes que constituem a ciência de dados:
Estatisticas
Estatística é um conceito importante no qual você deve se destacar para avançar na ciência de dados. Tem ainda alguns sub-tópicos:
1. Regressão Linear
2. Probabilidade
3. Distribuição de probabilidade
Inteligência artificial
A ciência para fornecer um cérebro às máquinas e deixá-las tomar suas próprias decisões com base nas entradas é conhecida como Inteligência Artificial. Máquinas reativas, memória limitada, teoria da mente e autoconsciência são alguns dos tipos de inteligência artificial.
Aprendizado de máquina
O Machine Learning é outro componente crucial da Data Science que lida com o ensino de máquinas para prever resultados futuros com base nos dados fornecidos. O aprendizado de máquina tem três métodos de modelagem proeminentes: agrupamento, regressão e classificação.
Descrever os tipos de Machine Learning?
Machine Learning ou ML simples tem três tipos principais com base em seus métodos de trabalho. Esses tipos são os seguintes:
1. Aprendizado Supervisionado
Este é o tipo mais primitivo de ML onde os dados de entrada são rotulados. A máquina é fornecida com um conjunto menor de dados que fornece à máquina uma visão do problema e é treinada sobre ele.
2. Aprendizado não supervisionado
A maior vantagem desse tipo é que os dados não são rotulados aqui e o trabalho humano é quase insignificante. Isso abre as portas para que conjuntos de dados muito maiores sejam introduzidos no modelo.
3. Aprendizado Reforçado Este é o tipo mais avançado de ML que se inspira na vida dos seres humanos. As saídas desejadas são reforçadas enquanto as saídas inúteis são desencorajadas.