
Pré-processamento de dados em aprendizado de máquina: 7 etapas fáceis a seguir
Publicados: 2021-07-15O pré-processamento de dados no Machine Learning é uma etapa crucial que ajuda a melhorar a qualidade dos dados para promover a extração de insights significativos dos dados. O pré-processamento de dados em Machine Learning refere-se à técnica de preparação (limpeza e organização) dos dados brutos para torná-los adequados para a construção e treinamento de modelos de Machine Learning. Em palavras simples, o pré-processamento de dados em Machine Learning é uma técnica de mineração de dados que transforma dados brutos em um formato compreensível e legível.
Índice
Por que o pré-processamento de dados em aprendizado de máquina?
Quando se trata de criar um modelo de Machine Learning, o pré-processamento de dados é o primeiro passo que marca o início do processo. Normalmente, os dados do mundo real são incompletos, inconsistentes, imprecisos (contêm erros ou discrepâncias) e muitas vezes carecem de valores/tendências de atributos específicos. É aqui que o pré-processamento de dados entra no cenário – ele ajuda a limpar, formatar e organizar os dados brutos, tornando-os prontos para uso em modelos de Machine Learning. Vamos explorar várias etapas do pré-processamento de dados no aprendizado de máquina.
Participe do Curso de Inteligência Artificial on-line das principais universidades do mundo - Mestrados, Programas de Pós-Graduação Executiva e Programa de Certificado Avançado em ML e IA para acelerar sua carreira.
Etapas no pré-processamento de dados no aprendizado de máquina
Existem sete etapas significativas no pré-processamento de dados em Machine Learning:
1. Adquira o conjunto de dados
Adquirir o conjunto de dados é o primeiro passo no pré-processamento de dados no aprendizado de máquina. Para construir e desenvolver modelos de Machine Learning, você deve primeiro adquirir o conjunto de dados relevante. Esse conjunto de dados será composto por dados coletados de fontes múltiplas e díspares que são então combinados em um formato adequado para formar um conjunto de dados. Os formatos do conjunto de dados diferem de acordo com os casos de uso. Por exemplo, um conjunto de dados de negócios será totalmente diferente de um conjunto de dados médicos. Enquanto um conjunto de dados de negócios conterá dados relevantes do setor e de negócios, um conjunto de dados médicos incluirá dados relacionados à saúde.
Existem várias fontes online de onde você pode baixar conjuntos de dados como https://www.kaggle.com/uciml/datasets e https://archive.ics.uci.edu/ml/index.php . Você também pode criar um conjunto de dados coletando dados por meio de diferentes APIs do Python. Quando o conjunto de dados estiver pronto, você deve colocá-lo nos formatos de arquivo CSV, HTML ou XLSX.

2. Importe todas as bibliotecas cruciais
Como o Python é a biblioteca mais usada e também a preferida pelos cientistas de dados em todo o mundo, mostraremos como importar bibliotecas Python para pré-processamento de dados em Machine Learning. Leia mais sobre bibliotecas Python para Data Science aqui. As bibliotecas Python predefinidas podem realizar trabalhos específicos de pré-processamento de dados. A importação de todas as bibliotecas cruciais é a segunda etapa do pré-processamento de dados no aprendizado de máquina. As três principais bibliotecas Python usadas para esse pré-processamento de dados no Machine Learning são:
- NumPy – NumPy é o pacote fundamental para cálculo científico em Python. Por isso, é usado para inserir qualquer tipo de operação matemática no código. Usando o NumPy, você também pode adicionar grandes arrays e matrizes multidimensionais em seu código.
- Pandas – Pandas é uma excelente biblioteca Python de código aberto para manipulação e análise de dados. É amplamente utilizado para importar e gerenciar os conjuntos de dados. Ele inclui estruturas de dados fáceis de usar e de alto desempenho e ferramentas de análise de dados para Python.
- Matplotlib – Matplotlib é uma biblioteca de plotagem 2D Python que é usada para plotar qualquer tipo de gráfico em Python. Ele pode fornecer números com qualidade de publicação em vários formatos de cópia impressa e ambientes interativos entre plataformas (shells IPython, notebook Jupyter, servidores de aplicativos da Web etc.).
Leia : Ideias de projetos de aprendizado de máquina para iniciantes
3. Importe o conjunto de dados
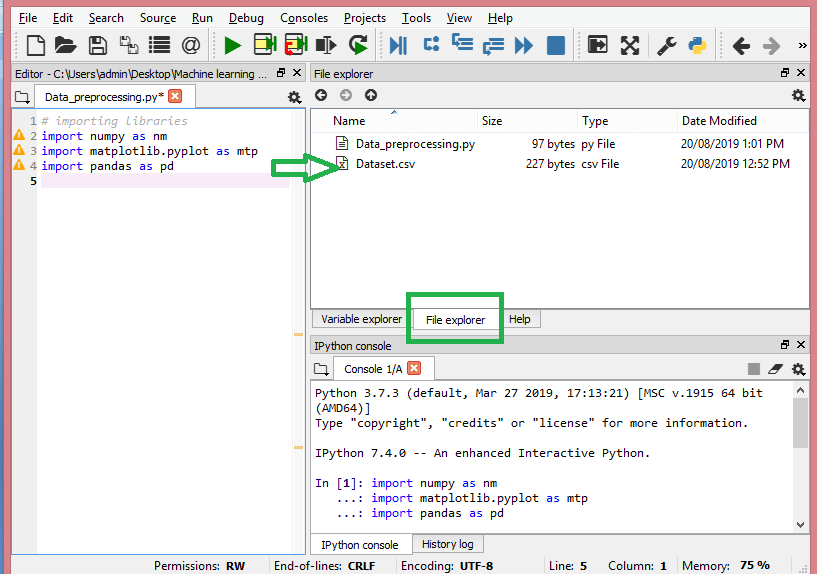
Nesta etapa, você precisa importar o(s) conjunto(s) de dados que reuniu para o projeto de ML em questão. A importação do conjunto de dados é uma das etapas importantes no pré-processamento de dados no aprendizado de máquina. No entanto, antes de importar o(s) conjunto(s) de dados, você deve definir o diretório atual como o diretório de trabalho. Você pode definir o diretório de trabalho no Spyder IDE em três etapas simples:
- Salve seu arquivo Python no diretório que contém o conjunto de dados.
- Vá para a opção File Explorer no Spyder IDE e escolha o diretório necessário.
- Agora, clique no botão F5 ou na opção Executar para executar o arquivo.
Fonte
É assim que o diretório de trabalho deve ficar.
Depois de definir o diretório de trabalho contendo o conjunto de dados relevante, você pode importar o conjunto de dados usando a função “read_csv()” da biblioteca Pandas. Essa função pode ler um arquivo CSV (localmente ou por meio de uma URL) e também realizar várias operações nele. O read_csv() é escrito como:
data_set= pd.read_csv('Dataset.csv')
Nesta linha de código, “data_set” denota o nome da variável em que você armazenou o conjunto de dados. A função também contém o nome do conjunto de dados. Depois de executar este código, o conjunto de dados será importado com sucesso.
Durante o processo de importação do conjunto de dados, há outra coisa essencial que você deve fazer – extrair variáveis dependentes e independentes. Para cada modelo de Machine Learning, é necessário separar as variáveis independentes (matriz de recursos) e variáveis dependentes em um conjunto de dados.
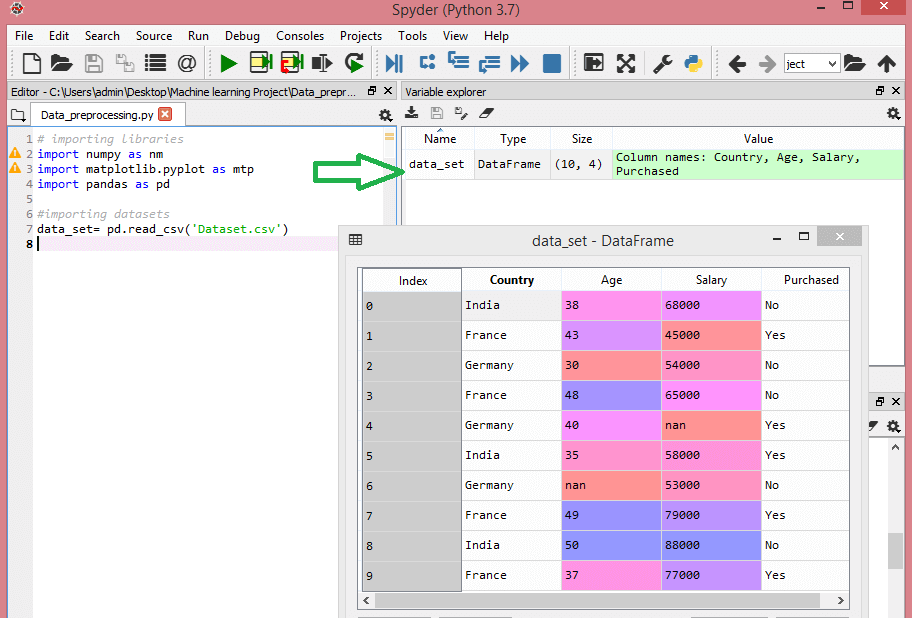
Considere este conjunto de dados:
Fonte
Este conjunto de dados contém três variáveis independentes – país, idade e salário, e uma variável dependente – adquirida.
Como extrair as variáveis independentes?
Para extrair as variáveis independentes, você pode usar a função “iloc[ ]” da biblioteca Pandas. Essa função pode extrair linhas e colunas selecionadas do conjunto de dados.
x= data_set.iloc[:,:-1].values
Na linha de código acima, o primeiro dois pontos(:) considera todas as linhas e o segundo dois pontos(:) considera todas as colunas. O código contém “:-1”, pois você deve deixar de fora a última coluna que contém a variável dependente. Ao executar este código, você obterá a matriz de recursos, assim –
[['Índia' 38,0 68.000,0]
['França' 43,0 45000,0]
['Alemanha' 30,0 54000,0]
['França' 48,0 65000,0]
['Alemanha' 40,0 nan]
['Índia' 35,0 58000,0]
['Alemanha' nan 53000.0]
['França' 49,0 79000,0]
['Índia' 50,0 88000,0]
['França' 37,0 77000,0]]
Como extrair a variável dependente?
Você pode usar a função “iloc[ ]” para extrair a variável dependente também. Veja como você escreve:
y= data_set.iloc[:,3].values
Esta linha de código considera todas as linhas apenas com a última coluna. Ao executar o código acima, você obterá o array de variáveis dependentes, assim –
array(['Não', 'Sim', 'Não', 'Não', 'Sim', 'Sim', 'Não', 'Sim', 'Não', 'Sim'],
dtype=objeto)
4. Identificando e lidando com os valores ausentes
No pré-processamento de dados, é fundamental identificar e manipular corretamente os valores ausentes, caso contrário, você poderá tirar conclusões e inferências imprecisas e incorretas dos dados. Escusado será dizer que isso prejudicará seu projeto de ML.
Basicamente, existem duas maneiras de lidar com dados ausentes:
- Excluindo uma linha específica – nesse método, você remove uma linha específica que possui um valor nulo para um recurso ou uma coluna específica em que mais de 75% dos valores estão ausentes. No entanto, esse método não é 100% eficiente e é recomendável usá-lo apenas quando o conjunto de dados tiver amostras adequadas. Você deve garantir que, após a exclusão dos dados, não haja adição de viés.
- Calculando a média – Este método é útil para feições com dados numéricos como idade, salário, ano, etc. Aqui, você pode calcular a média, mediana ou moda de uma feição específica ou coluna ou linha que contém um valor ausente e substituir o resultado para o valor ausente. Esse método pode adicionar variação ao conjunto de dados e qualquer perda de dados pode ser negada com eficiência. Portanto, ele produz melhores resultados em comparação com o primeiro método (omissão de linhas/colunas). Outra forma de aproximação é através do desvio de valores vizinhos. No entanto, isso funciona melhor para dados lineares.
Leia: Aplicativos de aplicativos de aprendizado de máquina usando a nuvem
5. Codificação dos dados categóricos
Dados categóricos referem-se às informações que possuem categorias específicas dentro do conjunto de dados. No conjunto de dados citado acima, existem duas variáveis categóricas – país e comprado.
Os modelos de Machine Learning são baseados principalmente em equações matemáticas. Assim, você pode entender intuitivamente que manter os dados categóricos na equação causará certos problemas, pois você só precisaria de números nas equações.
Como codificar a variável país?
Conforme visto em nosso exemplo de conjunto de dados, a coluna do país causará problemas, portanto, você deve convertê-la em valores numéricos. Para fazer isso, você pode usar a classe LabelEncoder() da biblioteca sci-kit learn. O código será o seguinte –
#Dados categóricos
#para variável de país
de sklearn.preprocessing import LabelEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
E a saída será –
Fora[15]:
array([[2, 38,0, 68000,0],
[0, 43,0, 45000,0],
[1, 30,0, 54000,0],
[0, 48,0, 65.000,0],
[1, 40.0, 65222.222222222222],
[2, 35,0, 58000,0],
[1, 41.111111111111114, 53000.0],
[0, 49,0, 79.000,0],
[2, 50,0, 88000,0],
[0, 37,0, 77000,0]], dtype=objeto)
Aqui podemos ver que a classe LabelEncoder codificou com sucesso as variáveis em dígitos. No entanto, existem variáveis de país codificadas como 0, 1 e 2 na saída mostrada acima. Assim, o modelo de ML pode assumir que existe alguma correlação entre as três variáveis, produzindo assim uma saída defeituosa. Para eliminar esse problema, agora usaremos a codificação fictícia.
Variáveis dummy são aquelas que assumem os valores 0 ou 1 para indicar a ausência ou a presença de um efeito categórico específico que pode alterar o resultado. Nesse caso, o valor 1 indica a presença dessa variável em uma determinada coluna enquanto as demais variáveis passam a ter valor 0. Na codificação fictícia, o número de colunas é igual ao número de categorias.
Como nosso conjunto de dados tem três categorias, ele produzirá três colunas com os valores 0 e 1. Para Dummy Encoding, usaremos a classe OneHotEncoder da biblioteca scikit-learn. O código de entrada será o seguinte –
#para variável de país
de sklearn.preprocessing importação LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#Codificação para variáveis fictícias

onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
Na execução deste código, você obterá a seguinte saída –
array([[0,00000000e+00, 0,00000000e+00, 1,00000000e+00, 3,80000000e+01,
6.80000000e+04],
[1,00000000e+00, 0,00000000e+00, 0,00000000e+00, 4,30000000e+01,
4.50000000e+04],
[0,00000000e+00, 1,00000000e+00, 0,00000000e+00, 3,00000000e+01,
5.40000000e+04],
[1,00000000e+00, 0,00000000e+00, 0,00000000e+00, 4,80000000e+01,
6.50000000e+04],
[0,00000000e+00, 1,00000000e+00, 0,00000000e+00, 4,00000000e+01,
6.52222222e+04],
[0,00000000e+00, 0,00000000e+00, 1,00000000e+00, 3,50000000e+01,
5.80000000e+04],
[0,00000000e+00, 1,00000000e+00, 0,00000000e+00, 4,11111111e+01,
5.30000000e+04],
[1,00000000e+00, 0,00000000e+00, 0,00000000e+00, 4,90000000e+01,
7.90000000e+04],
[0,00000000e+00, 0,00000000e+00, 1,00000000e+00, 5,00000000e+01,
8.80000000e+04],
[1,00000000e+00, 0,00000000e+00, 0,00000000e+00, 3,70000000e+01,
7.70000000e+04]])
Na saída mostrada acima, todas as variáveis são divididas em três colunas e codificadas nos valores 0 e 1.
Como codificar a variável comprada?
Para a segunda variável categórica, ou seja, comprada, pode-se utilizar o objeto “labelencoder” da classe LableEncoder. Não estamos usando a classe OneHotEncoder, pois a variável comprada possui apenas duas categorias sim ou não, ambas codificadas em 0 e 1.
O código de entrada para esta variável será –
labelEncoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
A saída será –
Out[17]: array([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
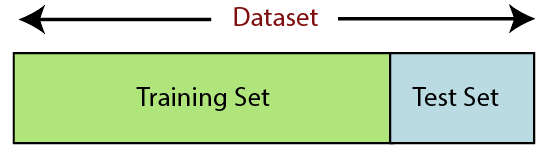
6. Dividindo o conjunto de dados
A divisão do conjunto de dados é a próxima etapa no pré-processamento de dados no aprendizado de máquina. Cada conjunto de dados para o modelo de Machine Learning deve ser dividido em dois conjuntos separados – conjunto de treinamento e conjunto de teste.
Fonte
Conjunto de treinamento denota o subconjunto de um conjunto de dados que é usado para treinar o modelo de aprendizado de máquina. Aqui, você já está ciente da saída. Um conjunto de teste, por outro lado, é o subconjunto do conjunto de dados usado para testar o modelo de aprendizado de máquina. O modelo de ML usa o conjunto de testes para prever resultados.
Normalmente, o conjunto de dados é dividido em proporção 70:30 ou proporção 80:20. Isso significa que você pega 70% ou 80% dos dados para treinar o modelo, deixando de fora os 30% ou 20% restantes. O processo de divisão varia de acordo com a forma e o tamanho do conjunto de dados em questão.
Para dividir o conjunto de dados, você deve escrever a seguinte linha de código –
de sklearn.model_selection importar train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0,2, random_state=0)
Aqui, a primeira linha divide as matrizes do conjunto de dados em subconjuntos de treinamento e teste aleatórios. A segunda linha de código inclui quatro variáveis:
- x_train – recursos para os dados de treinamento
- x_test – recursos para os dados de teste
- y_train – variáveis dependentes para dados de treinamento
- y_test – variável independente para dados de teste
Assim, a função train_test_split() inclui quatro parâmetros, os dois primeiros são para arrays de dados. A função test_size especifica o tamanho do conjunto de teste. O test_size pode ser .5, .3 ou .2 – especifica a razão de divisão entre os conjuntos de treinamento e teste. O último parâmetro, “random_state” define a semente para um gerador aleatório para que a saída seja sempre a mesma.
7. Dimensionamento de recursos
O dimensionamento de recursos marca o fim do pré-processamento de dados no Machine Learning. É um método para padronizar as variáveis independentes de um conjunto de dados dentro de um intervalo específico. Em outras palavras, o dimensionamento de recursos limita o intervalo de variáveis para que você possa compará-las em bases comuns.
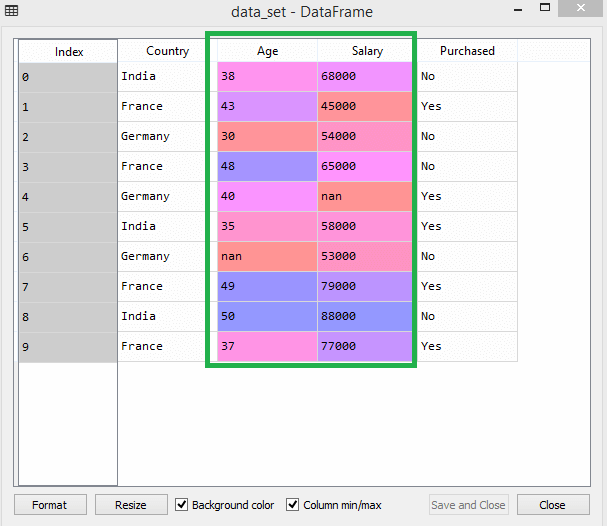
Considere este conjunto de dados, por exemplo –
Fonte
No conjunto de dados, você pode notar que as colunas idade e salário não possuem a mesma escala. Nesse cenário, se você calcular quaisquer dois valores das colunas de idade e salário, os valores de salário dominarão os valores de idade e fornecerão resultados incorretos. Portanto, você deve remover esse problema executando o dimensionamento de recursos para Machine Learning.
A maioria dos modelos de ML é baseada na Distância Euclidiana, que é representada como:
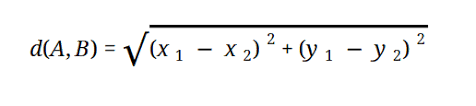
Fonte
Você pode executar o dimensionamento de recursos no Machine Learning de duas maneiras:
estandardização
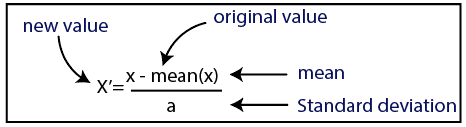
Fonte
Normalização
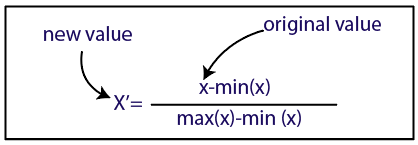
Fonte
Para nosso conjunto de dados, usaremos o método de padronização. Para isso, importaremos a classe StandardScaler da biblioteca sci-kit-learn usando a seguinte linha de código:
de sklearn.preprocessing importação StandardScaler
O próximo passo será criar o objeto da classe StandardScaler para variáveis independentes. Depois disso, você pode ajustar e transformar o conjunto de dados de treinamento usando o seguinte código:
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
Para o conjunto de dados de teste, você pode aplicar diretamente a função transform() (você não precisa usar a função fit_transform() porque ela já é feita no conjunto de treinamento). O código será o seguinte –
x_test= st_x.transform(x_test)
A saída para o conjunto de dados de teste mostrará os valores dimensionados para x_train e x_test como:
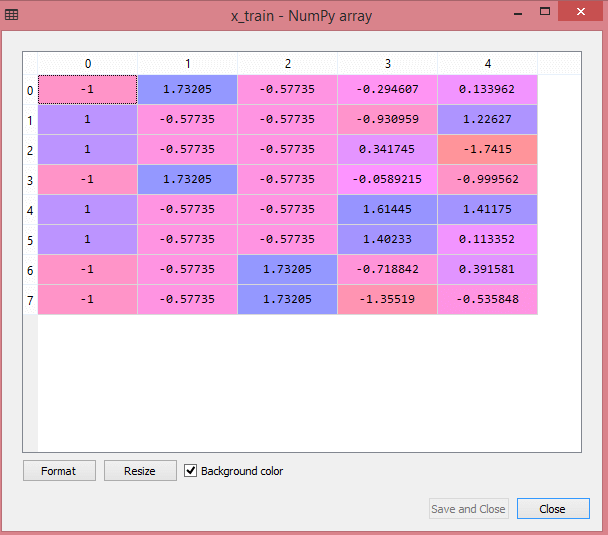
Fonte
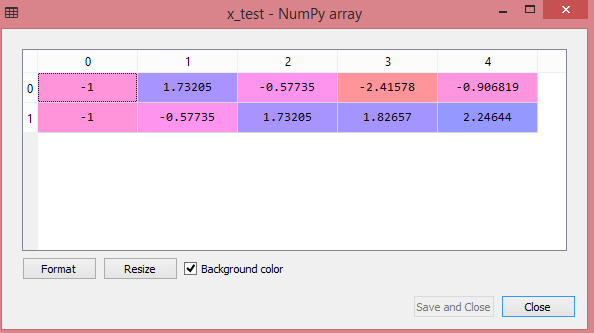
Fonte
Todas as variáveis na saída são dimensionadas entre os valores -1 e 1.
Agora, para combinar todas as etapas que realizamos até agora, você obtém:
# importando bibliotecas
importar numpy como nm
importar matplotlib.pyplot como mtp
importar pandas como pd
#importando conjuntos de dados
data_set= pd.read_csv('Dataset.csv')
#Extraindo Variável Independente
x= data_set.iloc[:, :-1].values
#Extraindo variável dependente
y= data_set.iloc[:, 3].values
#handling missing data(Substituindo dados ausentes pelo valor médio)
de sklearn.preprocessing import Imputer
imputer= Imputer(missing_values ='NaN', strategy='mean', axis = 0)
#Ajustando o objeto imputador às variáveis independentes x.
imputerimuter= imputer.fit(x[:, 1:3])
#Substituindo dados ausentes pelo valor médio calculado
x[:, 1:3]= imputer.transform(x[:, 1:3])
#para variável de país
de sklearn.preprocessing importação LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#Codificação para variáveis fictícias
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
#codificação para variável comprada
labelEncoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
# Dividindo o conjunto de dados em conjunto de treinamento e teste.
de sklearn.model_selection importar train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0,2, random_state=0)
#Feature Scaling de conjuntos de dados
de sklearn.preprocessing importação StandardScaler
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)
Então, isso é processamento de dados em Machine Learning em poucas palavras!
Você pode verificar o Programa PG Executivo do IIT Delhi em Machine Learning & AI em associação com upGrad . IIT Delhi é uma das instituições de maior prestígio na Índia. Com mais de 500 membros do corpo docente interno que são os melhores nos assuntos.
Qual é a importância do pré-processamento de dados?
Como erros, redundâncias, valores ausentes e inconsistências comprometem a integridade do conjunto de dados, você deve abordar todos eles para obter um resultado mais preciso. Suponha que você esteja usando um conjunto de dados defeituoso para treinar um sistema de Machine Learning para lidar com as compras de seus clientes. É provável que o sistema gere vieses e desvios, resultando em uma experiência ruim para o usuário. Como resultado, antes de usar esses dados para o propósito pretendido, eles devem ser organizados e 'limpos' quanto possível. Dependendo do tipo de dificuldade com a qual você está lidando, existem inúmeras opções.
O que é limpeza de dados?
Quase certamente haverá dados ausentes e ruidosos em seus conjuntos de dados. Como o procedimento de coleta de dados não é o ideal, você terá muitas informações inúteis e ausentes. A limpeza de dados é a maneira que você deve empregar para lidar com esse problema. Isso pode ser dividido em duas categorias. O primeiro discute como lidar com dados ausentes. Você pode optar por ignorar os valores ausentes nesta seção da coleta de dados (chamada de tupla). O segundo método de limpeza de dados é para dados com ruído. É fundamental se livrar de dados inúteis que não podem ser lidos pelos sistemas se você quiser que todo o processo seja executado sem problemas.
O que você entende por transformação e redução de dados?
O pré-processamento de dados passa para o estágio de transformação depois de lidar com as preocupações. Você o usa para converter dados em conformações relevantes para análise. Normalização, seleção de atributos, discretização e geração de hierarquia de conceito são algumas das abordagens que podem ser usadas para fazer isso. Mesmo para métodos automatizados, filtrar grandes conjuntos de dados pode levar muito tempo. É por isso que o estágio de redução de dados é tão crucial: reduz o tamanho dos conjuntos de dados limitando-os às informações mais importantes, aumentando a eficiência do armazenamento e reduzindo as despesas financeiras e de tempo de trabalhar com eles.