
Data Frames em Python: Tutorial detalhado de Python 2022
Publicados: 2021-01-09Se você é um desenvolvedor ou codificador que trabalha na linguagem de programação Python, deve estar familiarizado com uma das bibliotecas de gerenciamento de dados mais incríveis do mercado – Pandas, uma das principais bibliotecas python existentes. Ao longo dos anos, o Pandas emergiu como uma ferramenta padrão para análise e gerenciamento de dados usando Python. Leia sobre outras ferramentas importantes do Python.
O Pandas é, sem dúvida, o pacote Python mais versátil para ciência de dados e com razão. Ele fornece estruturas de dados poderosas, expressivas e flexíveis para fácil manipulação e análise de dados, e Data Frames em Python é uma dessas estruturas.
Este é precisamente o nosso tópico de discussão neste post – apresentaremos o formato de dados básico para Pandas, ou seja, o Pandas Data Frame.
Índice
O que é um Data Frame?
De acordo com a documentação da biblioteca Pandas , um Data Frame é uma “estrutura de dados tabular bidimensional, mutável em tamanho e potencialmente heterogênea com eixos rotulados (linhas e colunas)”. Em palavras simples, um Data Frame é uma estrutura de dados em que os dados são alinhados de forma tabular, ou seja, em linhas e colunas.
Um Data Frame geralmente tem as seguintes características:
- Pode ter várias linhas e colunas.
- Enquanto cada linha representa uma amostra de dados, cada coluna compreende uma variável diferente que descreve as amostras (linhas).
- Os dados em cada coluna geralmente são do mesmo tipo de dados (por exemplo, números, strings, datas, etc.).
- Ao contrário dos conjuntos de dados do Excel, ele evita ter valores ausentes, portanto, não há lacunas ou valores vazios entre linhas ou colunas.
Em um Data Frame do Pandas, você também pode especificar os nomes de índice e coluna para seu Data Frame. Enquanto o índice indica a diferença nas linhas, os nomes das colunas mostram a diferença nas colunas.
Como criar um quadro de dados em Python (usando Pandas)
Criar um Data Frame é o primeiro passo para o processamento de dados em Python. Você pode criar um Pandas Data Frame usando entradas como:
- Dito
- Listas
- Series
- Numpy “ndarray”
- Outro quadro de dados
- Arquivos externos, como CS
- Criando um Data Frame Vazio
É muito fácil criar um Data Frame básico, também conhecido como Empty Data Frame. Aqui está um exemplo:
Entrada -

Saída -

- Criando um Data Frame a partir de Listas
Você pode criar um Data Frame usando uma única lista ou várias listas.
Entrada -

Saída -

- Criando um Data Frame a partir de Dict de “ndarrays” ou Listas
Para criar um Data Frame a partir de um dict de ndarrays, todos os ndarrays devem ter o mesmo comprimento. Além disso, se for indexado, o comprimento do índice deve ser igual ao comprimento das matrizes. No entanto, se não estiver indexado, o índice será range(n) por padrão, onde 'n' denota o comprimento do array.
Entrada -

Saída -

Aqui os valores 0,1,2,3 são o índice padrão atribuído a cada linha usando a função range(n).
Quais são as operações fundamentais do data frame?
Agora que vimos três maneiras de criar Data Frames em Python, é hora de aprender sobre as diferentes operações dentro de um Data Frame.
- Selecionando um índice ou coluna de um Pandas Data Frame
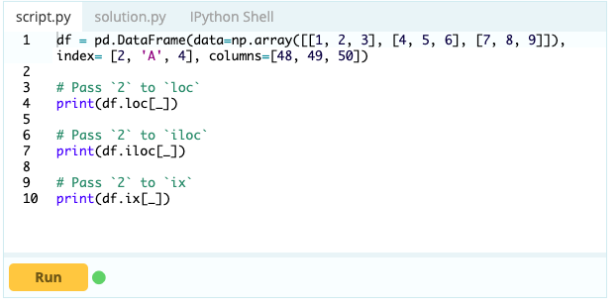
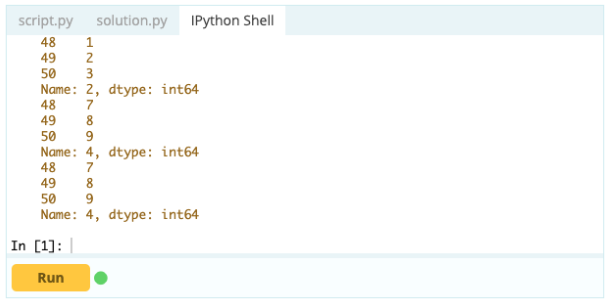
É importante saber como selecionar um índice ou coluna antes de começar a adicionar, excluir e renomear os componentes em um DataFrame. Suponha que este seja seu Data Frame:

Você deseja acessar o valor sob o índice 0 na coluna 'A' – o valor é 1. Há muitas maneiras de acessar esse valor, mas duas das mais importantes são – .loc[] e .iloc[].
Entrada -
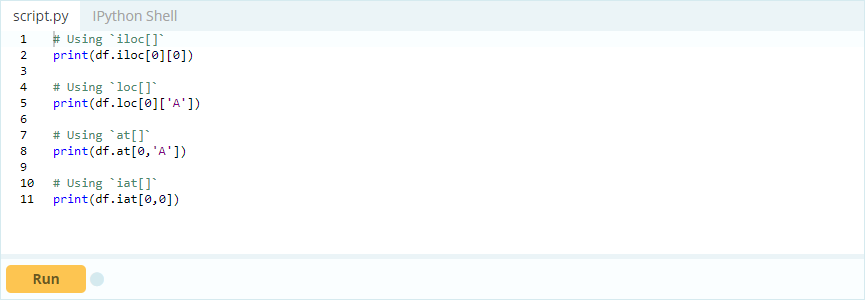
Saída -
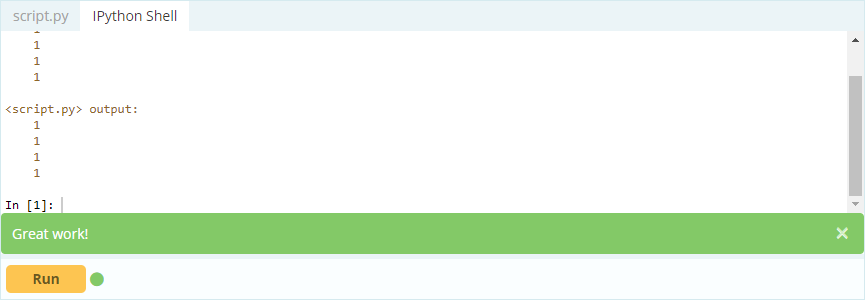
Assim, como você pode ver, você pode acessar os valores chamando-os pelo rótulo ou declarando sua posição no índice ou na coluna. Enquanto isso estava selecionando um valor de um Data Frame, como você pode selecionar linhas e colunas do mesmo?
É assim:
Entrada -
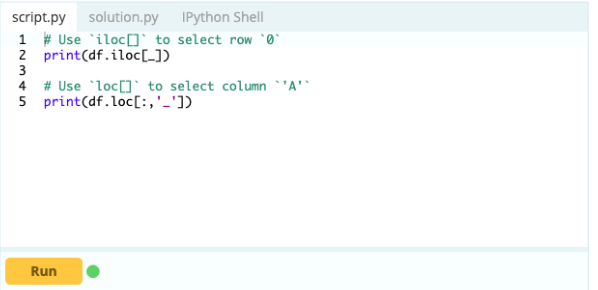
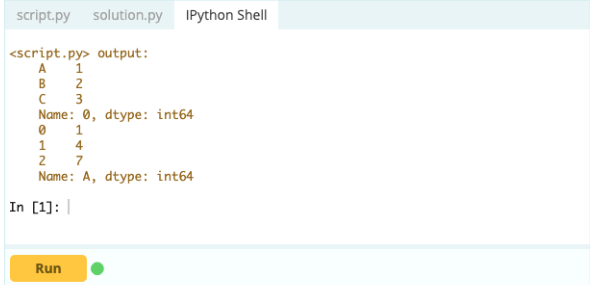
Saída-
- Como adicionar um índice, linha ou coluna a um DataFrame do Pandas
Depois de aprender a acessar valores e selecionar colunas de um Data Frame, você pode aprender a adicionar índice, linha ou coluna em um Pandas Data Frame.
Adicionando um índice:
Ao criar um Data Frame, você pode optar por adicionar uma entrada ao argumento 'index'. Isso garante que você possa acessar facilmente o índice desejado. Se você não especificar o índice, por padrão, um índice com valor numérico que começa com 0 e continua até a última linha do DataFrame será adicionado a ele. Embora, mesmo após o índice ser especificado por padrão, você pode usar uma coluna e convertê-la em um índice chamando a função set_index() no Data Frame.

Adicionando uma linha:
Você pode adicionar linhas a um DataFrame usando a função append.
Entrada -

Saída -

Você também pode usar .loc para inserir linhas em seu DataFrame assim:
Entrada -
Saída -
Adicionando uma coluna
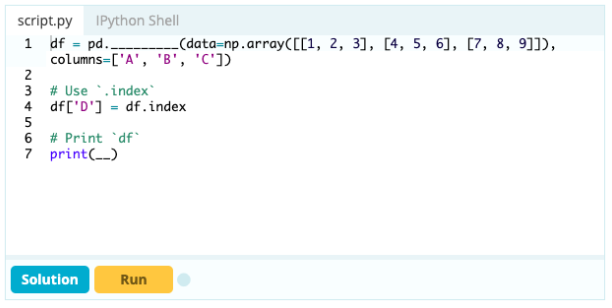
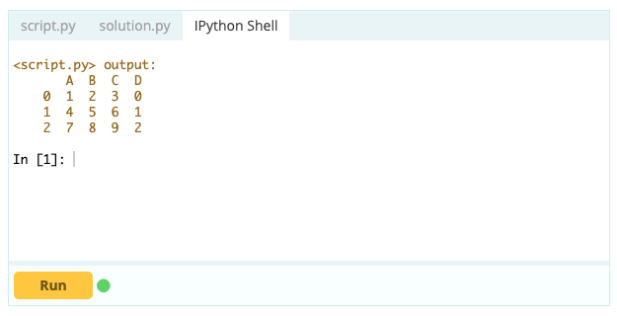
Se você quiser que um índice faça parte de um Data Frame, você pode pegar uma coluna do Data Frame ou fazer referência a uma coluna que ainda não foi criada e atribuí-la à propriedade .index assim:
Entrada -
Saída -
Para adicionar colunas a um Data Frame, você também pode usar a mesma abordagem que usaria para adicionar um índice ao Data Frame, ou seja, você pode usar a função .loc[ ] ou .iloc[ ]. Por exemplo:
Entrada -
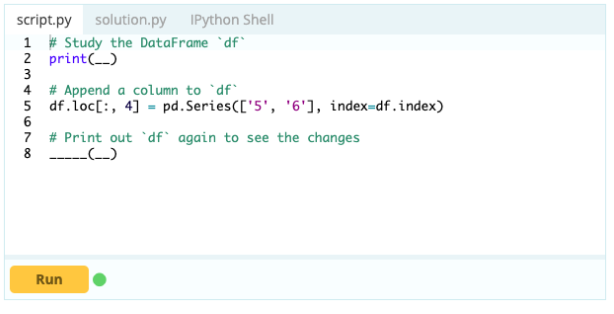
Saída
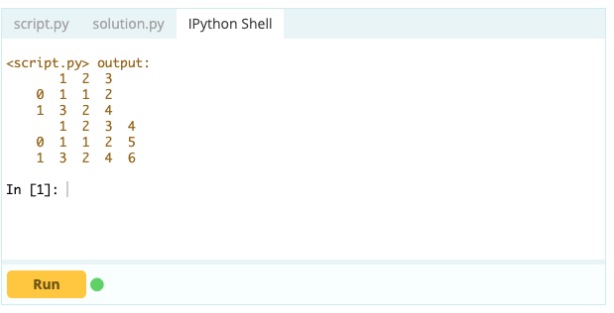
Com .loc[ ], você pode adicionar uma série a um DataFrame existente. Como um objeto Series é bastante semelhante a uma coluna de um Data Frame, é muito fácil adicionar um Series a um Data Frame existente.
- Como redefinir o índice de um quadro de dados?
Você pode redefinir o índice de um Data Frame se ele não ficar como você deseja. Você pode usar a função .reset_index() para fazer isso.
Entrada -
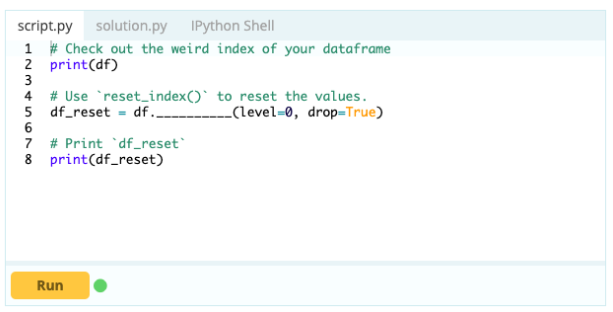
Saída -
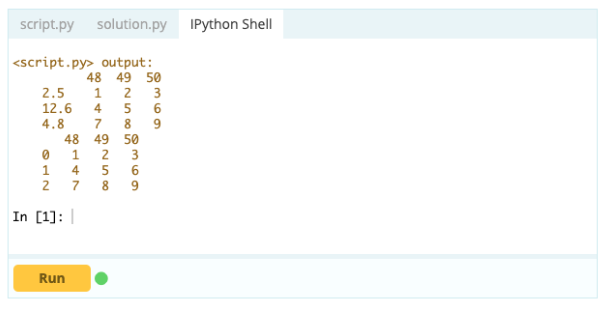
- Como excluir um índice, linha ou coluna para um DataFrame do Pandas
Excluindo um índice
- Redefinindo o índice do Data Frame.
- Remova o nome do índice (se houver) usando a função del df.index.name.
- Remova um índice junto com uma linha.
- Remova todos os valores de índice duplicados redefinindo o índice, descartando as duplicatas da coluna de índice que foi adicionada ao Data Frame e restabelecendo a nova coluna (sem índice duplicado) novamente como o índice.
Excluindo uma coluna
Para remover colunas de um Data Frame, você pode usar a função drop().
Entrada -
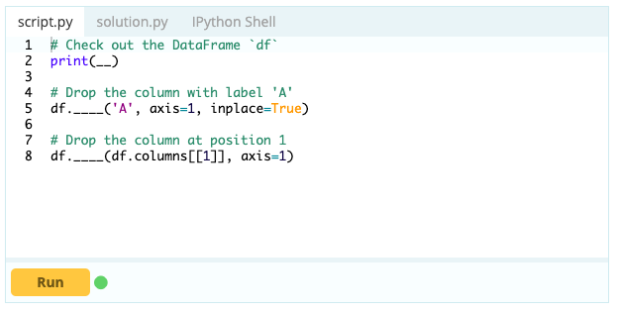
Saída -
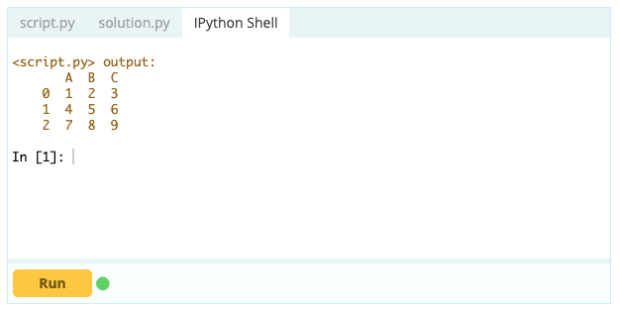
Excluindo uma linha
Para excluir uma linha de um Data Frame, você pode usar a função drop() usando a propriedade index para especificar o índice das linhas que deseja excluir do DataFrame.
Entrada -
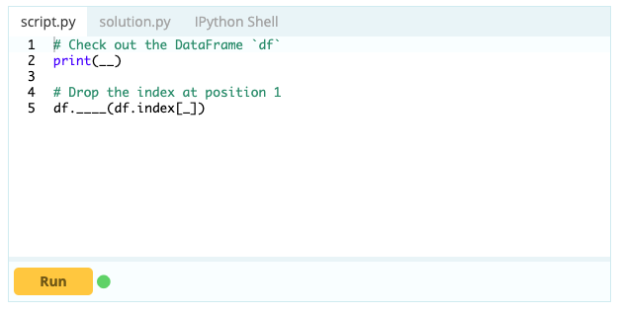
Saída -
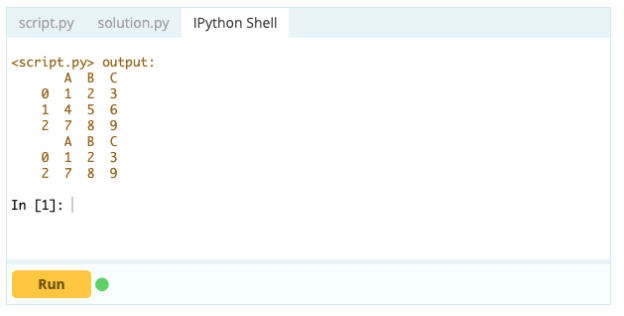
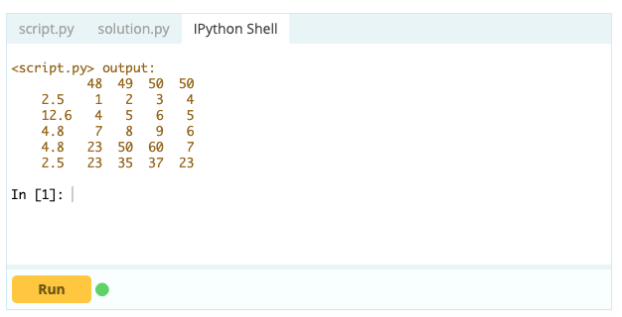
No entanto, para excluir linhas duplicadas, você pode usar a função df.drop_duplicates().
Entrada -
Saída -
Fontes: Tutorialspoint Datacamp
Conclusão
Então, aqui está o seu tutorial básico para Data Frame em Python usando Pandas.
Se você estiver interessado em aprender Python, ciência de dados, confira o PG Diploma in Data Science do IIIT-B & upGrad, criado para profissionais que trabalham e oferece mais de 10 estudos de caso e projetos, workshops práticos práticos, orientação com especialistas do setor, 1-on-1 com mentores do setor, mais de 400 horas de aprendizado e assistência de trabalho com as principais empresas.
Por que o Pandas é uma das bibliotecas mais preferidas para criar quadros de dados em Python?
A biblioteca Pandas é considerada a mais adequada para a criação de quadros de dados, pois fornece vários recursos que tornam a criação de um quadro de dados eficiente. Alguns desses recursos são os seguintes: Pandas nos fornece vários quadros de dados que não apenas permitem uma representação de dados eficiente, mas também nos permitem manipulá-los. Ele fornece recursos eficientes de alinhamento e indexação que fornecem maneiras inteligentes de rotular e organizar os dados. Alguns recursos do Pandas tornam o código limpo e aumentam sua legibilidade, tornando-o mais eficiente. Ele também pode ler vários formatos de arquivo. JSON, CSV, HDF5 e Excel são alguns dos formatos de arquivo suportados pelo Pandas. A fusão de vários conjuntos de dados tem sido um verdadeiro desafio para muitos programadores. Os pandas também superam isso e mesclam vários conjuntos de dados com muita eficiência.
Quais são as outras bibliotecas e ferramentas que complementam a biblioteca Pandas?
O Pandas não funciona apenas como uma biblioteca central para criar quadros de dados, mas também funciona com outras bibliotecas e ferramentas do Python para ser mais eficiente. Pandas é construído no pacote NumPy Python, que indica que a maior parte da estrutura da biblioteca Pandas é replicada a partir do pacote NumPy. A análise estatística dos dados na biblioteca Pandas é operada pelo SciPy, plotando funções no Matplotlib e algoritmos de aprendizado de máquina no Scikit-learn. Jupyter Notebook é um ambiente interativo baseado na web que funciona como um IDE e oferece um bom ambiente para Pandas.
Quais são as operações fundamentais do quadro de dados?
Selecionar um índice ou uma coluna antes de iniciar qualquer operação como adição ou exclusão é importante. Depois de aprender a acessar valores e selecionar colunas de um Data Frame, você pode aprender a adicionar índice, linha ou coluna em um Pandas Dataframe. Se o índice no quadro de dados não for o desejado, você poderá redefini-lo. Para redefinir o índice, você pode usar a função “reset_index()”.