
“Crie uma vez, publique em qualquer lugar” com WordPress
Publicados: 2022-03-10COPE é uma estratégia para reduzir o trabalho necessário para publicar nosso conteúdo em diferentes mídias, como site, e-mail, aplicativos e outros. Iniciado pela NPR, ele atinge seu objetivo ao estabelecer uma única fonte de verdade para o conteúdo que pode ser usado para todas as diferentes mídias.
Ter conteúdo que funcione em todos os lugares não é uma tarefa trivial, pois cada meio terá seus próprios requisitos. Por exemplo, enquanto o HTML é válido para imprimir conteúdo para a web, esse idioma não é válido para um aplicativo iOS/Android. Da mesma forma, podemos adicionar classes ao nosso HTML para a web, mas elas devem ser convertidas em estilos para email.
A solução para este enigma é separar a forma do conteúdo: a apresentação e o significado do conteúdo devem ser desacoplados, e apenas o significado é usado como a única fonte de verdade. A apresentação pode então ser adicionada em outra camada (específica para a mídia selecionada).
Por exemplo, dado o seguinte trecho de código HTML, o <p> é uma tag HTML que se aplica principalmente à web, e o atributo class="align-center" é a apresentação (colocar um elemento “no centro” faz sentido para um mídia baseada em tela, mas não para uma mídia baseada em áudio, como Amazon Alexa):
<p class="align-center">Hello world!</p>Portanto, esse conteúdo não pode ser usado como uma única fonte de verdade e deve ser convertido em um formato que separe o significado da apresentação, como o seguinte trecho de código JSON:
{ content: "Hello world!", placement: "center", type: "paragraph" }Este pedaço de código pode ser usado como uma única fonte de verdade para o conteúdo, pois a partir dele podemos recriar novamente o código HTML para usar na web e obter um formato apropriado para outros meios.
Por que WordPress
O WordPress é ideal para implementar a estratégia COPE por vários motivos:
- É versátil.
O modelo de banco de dados do WordPress não define um modelo de conteúdo fixo e rígido; pelo contrário, foi criado para a versatilidade, permitindo criar modelos de conteúdo variados através do uso de metacampo, que permite o armazenamento de dados adicionais para quatro entidades diferentes: postagens e tipos de postagem personalizados, usuários, comentários e taxonomias ( tags e categorias). - É poderoso.
O WordPress brilha como um CMS (Content Management System), e seu ecossistema de plugins permite adicionar facilmente novas funcionalidades. - É generalizado.
Estima-se que 1/3 dos sites sejam executados no WordPress. Então, uma quantidade considerável de pessoas que trabalham na web conhecem e são capazes de usar, ou seja, o WordPress. Não apenas desenvolvedores, mas também blogueiros, vendedores, equipe de marketing e assim por diante. Então, muitos interessados diferentes, independentemente de sua formação técnica, poderão produzir o conteúdo que atua como a única fonte de verdade. - É sem cabeça.
Headless é a capacidade de desacoplar o conteúdo da camada de apresentação, e é um recurso fundamental para implementar o COPE (para poder alimentar dados em mídias diferentes).
Desde que incorporou a API REST WP no núcleo a partir da versão 4.7, e mais marcadamente desde o lançamento do Gutenberg na versão 5.0 (para a qual muitos endpoints da API REST tiveram que ser implementados), o WordPress pode ser considerado um CMS headless, já que a maioria do conteúdo do WordPress pode ser acessado por meio de uma API REST por qualquer aplicativo construído em qualquer pilha.
Além disso, o recém-criado WPGraphQL integra WordPress e GraphQL, permitindo alimentar conteúdo do WordPress em qualquer aplicativo usando essa API cada vez mais popular. Finalmente, meu próprio projeto PoP adicionou recentemente uma implementação de uma API para WordPress que permite exportar os dados do WordPress como formatos nativos REST, GraphQL ou PoP. - Possui Gutenberg , um editor baseado em blocos que auxilia bastante na implementação do COPE porque é baseado no conceito de blocos (conforme explicado nas seções abaixo).
Blobs versus blocos para representar informações
Um blob é uma única unidade de informações armazenadas todas juntas no banco de dados. Por exemplo, escrever a postagem do blog abaixo em um CMS que depende de blobs para armazenar informações armazenará o conteúdo da postagem do blog em uma única entrada de banco de dados — contendo o mesmo conteúdo:
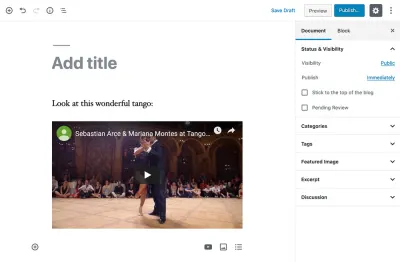
<p>Look at this wonderful tango:</p> <figure> <iframe width="951" height="535" src="https://www.youtube.com/embed/sxm3Xyutc1s" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe> <figcaption>An exquisite tango performance</figcaption> </figure>Como pode ser apreciado, as informações importantes desta postagem do blog (como o conteúdo do parágrafo e a URL, as dimensões e os atributos do vídeo do Youtube) não são facilmente acessíveis: Se quisermos recuperar alguma delas por conta própria, precisamos analisar o código HTML para extraí-los — o que está longe de ser uma solução ideal.
Os blocos agem de forma diferente. Ao representar a informação como uma lista de blocos, podemos armazenar o conteúdo de forma mais semântica e acessível. Cada bloco transmite seu próprio conteúdo e suas próprias propriedades que podem depender de seu tipo (por exemplo, talvez um parágrafo ou um vídeo?).
Por exemplo, o código HTML acima pode ser representado como uma lista de blocos como esta:
{ [ type: "paragraph", content: "Look at this wonderful tango:" ], [ type: "embed", provider: "Youtube", url: "https://www.youtube.com/embed/sxm3Xyutc1s", width: 951, height: 535, frameborder: 0, allowfullscreen: true, allow: "accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture", caption: "An exquisite tango performance" ] } Através desta forma de representação da informação, podemos facilmente usar qualquer dado por conta própria e adaptá-lo para o meio específico onde deve ser exibido. Por exemplo, se quisermos extrair todos os vídeos da postagem do blog para exibir em um sistema de entretenimento automotivo, podemos simplesmente iterar todos os blocos de informações, selecionar aqueles com type="embed" e provider="Youtube" e extrair o URL deles. Da mesma forma, se quisermos exibir o vídeo em um Apple Watch, não precisamos nos preocupar com as dimensões do vídeo, para que possamos ignorar os atributos width e height de maneira direta.
Como Gutenberg implementa blocos
Antes do WordPress versão 5.0, o WordPress usava blobs para armazenar conteúdo de postagem no banco de dados. A partir da versão 5.0, o WordPress vem com o Gutenberg, um editor baseado em blocos, permitindo a maneira aprimorada de processar o conteúdo mencionado acima, o que representa um avanço na implementação do COPE. Infelizmente, Gutenberg não foi projetado para este caso de uso específico, e sua representação das informações é diferente daquela descrita para blocos, resultando em vários inconvenientes com os quais precisaremos lidar.
Vamos primeiro dar uma olhada em como a postagem do blog descrita acima é salva por meio do Gutenberg:
<!-- wp:paragraph --> <p>Look at this wonderful tango:</p> <!-- /wp:paragraph --> <!-- wp:core-embed/youtube {"url":"https://www.youtube.com/embed/sxm3Xyutc1s","type":"rich","providerNameSlug":"embed-handler","className":"wp-embed-aspect-16-9 wp-has-aspect-ratio"} --> <figure class="wp-block-embed-youtube wp-block-embed is-type-rich is-provider-embed-handler wp-embed-aspect-16-9 wp-has-aspect-ratio"> <div class="wp-block-embed__wrapper"> https://www.youtube.com/embed/sxm3Xyutc1s </div> <figcaption>An exquisite tango performance</figcaption> </figure> <!-- /wp:core-embed/youtube -->A partir deste trecho de código, podemos fazer as seguintes observações:
Os blocos são salvos todos juntos na mesma entrada do banco de dados
Existem dois blocos no código acima:
<!-- wp:paragraph --> <p>Look at this wonderful tango:</p> <!-- /wp:paragraph --> <!-- wp:core-embed/youtube {"url":"https://www.youtube.com/embed/sxm3Xyutc1s","type":"rich","providerNameSlug":"embed-handler","className":"wp-embed-aspect-16-9 wp-has-aspect-ratio"} --> <figure class="wp-block-embed-youtube wp-block-embed is-type-rich is-provider-embed-handler wp-embed-aspect-16-9 wp-has-aspect-ratio"> <div class="wp-block-embed__wrapper"> https://www.youtube.com/embed/sxm3Xyutc1s </div> <figcaption>An exquisite tango performance</figcaption> </figure> <!-- /wp:core-embed/youtube --> Com exceção dos blocos globais (também chamados de “reutilizáveis”), que possuem uma entrada própria no banco de dados e podem ser referenciados diretamente por meio de seus IDs, todos os blocos são salvos juntos na entrada da postagem do blog na tabela wp_posts .
Portanto, para recuperar as informações de um bloco específico, primeiro precisamos analisar o conteúdo e isolar todos os blocos uns dos outros. Convenientemente, o WordPress fornece a função parse_blocks($content) para fazer exatamente isso. Essa função recebe uma string contendo o conteúdo da postagem do blog (em formato HTML) e retorna um objeto JSON contendo os dados de todos os blocos contidos.
Tipo de bloco e atributos são transmitidos através de comentários HTML
Cada bloco é delimitado com uma tag inicial <!-- wp:{block-type} {block-attributes-encoded-as-JSON} --> e uma tag final <!-- /wp:{block-type} --> que (sendo comentários HTML) garantem que esta informação não seja visível ao exibi-la em um site. No entanto, não podemos exibir a postagem do blog diretamente em outra mídia, pois o comentário HTML pode estar visível, aparecendo como conteúdo ilegível. Isso não é grande coisa, pois após analisar o conteúdo através da função parse_blocks($content) , os comentários HTML são removidos e podemos operar diretamente com os dados do bloco como um objeto JSON.
Blocos contêm HTML
O bloco de parágrafo tem "<p>Look at this wonderful tango:</p>" como seu conteúdo, em vez de "Look at this wonderful tango:" . Portanto, ele contém código HTML (tags <p> e </p> ) que não é útil para outras mídias e, como tal, deve ser removido, por exemplo, através da função PHP strip_tags($content) .
Ao remover as tags, podemos manter as tags HTML que transmitem explicitamente informações semânticas, como as tags <strong> e <em> (em vez de suas contrapartes <b> e <i> , que se aplicam apenas a uma mídia baseada em tela), e remova todas as outras tags. Isso ocorre porque há uma grande chance de que as tags semânticas também possam ser interpretadas adequadamente para outras mídias (por exemplo, o Amazon Alexa pode reconhecer as tags <strong> e <em> e alterar sua voz e entonação de acordo ao ler um pedaço de texto). Para fazer isso, invocamos a função strip_tags com um 2º parâmetro contendo as tags permitidas e a colocamos dentro de uma função de encapsulamento por conveniência:
function strip_html_tags($content) { return strip_tags($content, '<strong><em>'); }A legenda do vídeo é salva dentro do HTML e não como um atributo
Como pode ser visto no bloco de vídeo do Youtube, a legenda "An exquisite tango performance" é armazenada dentro do código HTML (incluído pela tag <figcaption /> ), mas não dentro do objeto de atributos codificados em JSON. Como consequência, para extrair a legenda, precisaremos analisar o conteúdo do bloco, por exemplo, por meio de uma expressão regular:
function extract_caption($content) { $matches = []; preg_match('/<figcaption>(.*?)<\/figcaption>/', $content, $matches); if ($caption = $matches[1]) { return strip_html_tags($caption); } return null; }Este é um obstáculo que devemos superar para extrair todos os metadados de um bloco Gutenberg. Isso acontece em vários blocos; como nem todos os metadados são salvos como atributos, devemos primeiro identificar quais são esses metadados e, em seguida, analisar o conteúdo HTML para extraí-los bloco a bloco e parte a parte.
Em relação ao COPE, isso representa uma chance perdida de ter uma solução realmente ótima. Pode-se argumentar que a opção alternativa também não é a ideal, pois duplicaria a informação, armazenando-a tanto dentro do HTML quanto como atributo, o que viola o princípio DRY ( D on't R epeat Y ourself). No entanto, essa violação já ocorre: Por exemplo, o atributo className contém o valor "wp-embed-aspect-16-9 wp-has-aspect-ratio" , que também é impresso dentro do conteúdo, no atributo HTML class .
Implementando o COPE
Nota: lancei esta funcionalidade, incluindo todo o código descrito abaixo, como plugin do WordPress Block Metadata. Você está convidado a instalá-lo e brincar com ele para que possa experimentar o poder do COPE. O código-fonte está disponível neste repositório do GitHub.
Agora que sabemos como é a representação interna de um bloco, vamos implementar o COPE através do Gutenberg. O procedimento envolverá as seguintes etapas:
- Como a função
parse_blocks($content)retorna um objeto JSON com níveis aninhados, devemos primeiro simplificar essa estrutura. - Iteramos todos os blocos e, para cada um, identificamos seus metadados e os extraímos, transformando-os em um formato agnóstico médio no processo. Quais atributos são adicionados à resposta podem variar dependendo do tipo de bloco.
- Finalmente disponibilizamos os dados através de uma API (REST/GraphQL/PoP).
Vamos implementar esses passos um por um.
1. Simplificando a estrutura do objeto JSON
O objeto JSON retornado da função parse_blocks($content) tem uma arquitetura aninhada, na qual os dados de blocos normais aparecem no primeiro nível, mas os dados de um bloco reutilizável referenciado estão ausentes (somente os dados do bloco de referência são adicionados), e os dados para blocos aninhados (que são adicionados dentro de outros blocos) e para blocos agrupados (onde vários blocos podem ser agrupados) aparecem em 1 ou mais subníveis. Essa arquitetura dificulta o processamento dos dados do bloco de todos os blocos do conteúdo do post, pois de um lado faltam alguns dados e do outro não sabemos a priori em quantos níveis os dados estão localizados. Além disso, há um divisor de blocos colocado a cada par de blocos, sem conteúdo, que pode ser ignorado com segurança.
Por exemplo, a resposta obtida de um post contendo um bloco simples, um bloco global, um bloco aninhado contendo um bloco simples e um grupo de blocos simples, nessa ordem, é o seguinte:
[ // Simple block { "blockName": "core/image", "attrs": { "id": 70, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n" ] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Reference to reusable block { "blockName": "core/block", "attrs": { "ref": 218 }, "innerBlocks": [], "innerHTML": "", "innerContent": [] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Nested block { "blockName": "core/columns", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/column", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/image", "attrs": { "id": 69, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/column", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/paragraph", "attrs": [], "innerBlocks": [], "innerHTML": "\n<p>This is how I wake up every morning</p>\n", "innerContent": [ "\n<p>This is how I wake up every morning</p>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-columns\">\n\n</div>\n", "innerContent": [ "\n<div class=\"wp-block-columns\">", null, "\n\n", null, "</div>\n" ] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Block group { "blockName": "core/group", "attrs": [], // Contained grouped blocks "innerBlocks": [ { "blockName": "core/image", "attrs": { "id": 71, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerBlocks": [], "innerHTML": "\n<p>Second element of the group</p>\n", "innerContent": [ "\n<p>Second element of the group</p>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">\n\n</div></div>\n", "innerContent": [ "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">", null, "\n\n", null, "</div></div>\n" ] } ]Uma solução melhor é ter todos os dados no primeiro nível, então a lógica para iterar por todos os dados do bloco é bastante simplificada. Portanto, devemos buscar os dados para esses blocos reutilizáveis/aninhados/agrupados e adicioná-los também no primeiro nível. Como pode ser visto no código JSON acima:
- O bloco divisor vazio tem o atributo
"blockName"com valorNULL - A referência a um bloco reutilizável é definida por meio
$block["attrs"]["ref"] - Blocos aninhados e de grupo definem seus blocos contidos em
$block["innerBlocks"]
Portanto, o código PHP a seguir remove os blocos divisores vazios, identifica os blocos reutilizáveis/aninhados/agrupados e adiciona seus dados ao primeiro nível e remove todos os dados de todos os subníveis:
/** * Export all (Gutenberg) blocks' data from a WordPress post */ function get_block_data($content, $remove_divider_block = true) { // Parse the blocks, and convert them into a single-level array $ret = []; $blocks = parse_blocks($content); recursively_add_blocks($ret, $blocks); // Maybe remove blocks without name if ($remove_divider_block) { $ret = remove_blocks_without_name($ret); } // Remove 'innerBlocks' property if it exists (since that code was copied to the first level, it is currently duplicated) foreach ($ret as &$block) { unset($block['innerBlocks']); } return $ret; } /** * Remove the blocks without name, such as the empty block divider */ function remove_blocks_without_name($blocks) { return array_values(array_filter( $blocks, function($block) { return $block['blockName']; } )); } /** * Add block data (including global and nested blocks) into the first level of the array */ function recursively_add_blocks(&$ret, $blocks) { foreach ($blocks as $block) { // Global block: add the referenced block instead of this one if ($block['attrs']['ref']) { $ret = array_merge( $ret, recursively_render_block_core_block($block['attrs']) ); } // Normal block: add it directly else { $ret[] = $block; } // If it contains nested or grouped blocks, add them too if ($block['innerBlocks']) { recursively_add_blocks($ret, $block['innerBlocks']); } } } /** * Function based on `render_block_core_block` */ function recursively_render_block_core_block($attributes) { if (empty($attributes['ref'])) { return []; } $reusable_block = get_post($attributes['ref']); if (!$reusable_block || 'wp_block' !== $reusable_block->post_type) { return []; } if ('publish' !== $reusable_block->post_status || ! empty($reusable_block->post_password)) { return []; } return get_block_data($reusable_block->post_content); } Chamando a função get_block_data($content) passando o conteúdo do post ( $post->post_content ) como parâmetro, agora obtemos a seguinte resposta:
[[ { "blockName": "core/image", "attrs": { "id": 70, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>\n", "innerContent": [ "\n<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>\n" ] }, { "blockName": "core/columns", "attrs": [], "innerHTML": "\n<div class=\"wp-block-columns\">\n\n</div>\n", "innerContent": [ "\n<div class=\"wp-block-columns\">", null, "\n\n", null, "</div>\n" ] }, { "blockName": "core/column", "attrs": [], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/image", "attrs": { "id": 69, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n" ] }, { "blockName": "core/column", "attrs": [], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>This is how I wake up every morning</p>\n", "innerContent": [ "\n<p>This is how I wake up every morning</p>\n" ] }, { "blockName": "core/group", "attrs": [], "innerHTML": "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">\n\n</div></div>\n", "innerContent": [ "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">", null, "\n\n", null, "</div></div>\n" ] }, { "blockName": "core/image", "attrs": { "id": 71, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>Second element of the group</p>\n", "innerContent": [ "\n<p>Second element of the group</p>\n" ] } ] Embora não seja estritamente necessário, é muito útil criar um endpoint da API REST para gerar o resultado de nossa nova função get_block_data($content) , que nos permitirá entender facilmente quais blocos estão contidos em um post específico e como eles são estruturada. O código abaixo adiciona esse endpoint em /wp-json/block-metadata/v1/data/{POST_ID} :

/** * Define REST endpoint to visualize a post's block data */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'data/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_blocks' ]); }); function get_post_blocks($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $response = new WP_REST_Response($block_data); $response->set_status(200); return $response; }/** * Define REST endpoint to visualize a post's block data */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'data/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_blocks' ]); }); function get_post_blocks($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $response = new WP_REST_Response($block_data); $response->set_status(200); return $response; }
Para vê-lo em ação, confira este link que exporta os dados para este post.
2. Extraindo todos os metadados de bloco em um formato agnóstico médio
Nesta fase, temos dados de bloco contendo código HTML que não é apropriado para COPE. Portanto, devemos remover as tags HTML não semânticas de cada bloco para convertê-lo em um formato agnóstico de meio.
Podemos decidir quais são os atributos que devem ser extraídos por tipo de bloco (por exemplo, extrair a propriedade de alinhamento de texto para blocos de "paragraph" , a propriedade de URL de vídeo para o bloco "youtube embed" e assim por diante) .
Como vimos anteriormente, nem todos os atributos são realmente salvos como atributos de bloco, mas dentro do conteúdo interno do bloco, portanto, para essas situações, precisaremos analisar o conteúdo HTML usando expressões regulares para extrair esses pedaços de metadados.
Depois de inspecionar todos os blocos enviados pelo núcleo do WordPress, decidi não extrair metadados para os seguintes:
"core/columns""core/column""core/cover" | Eles se aplicam apenas a mídias baseadas em tela e (sendo blocos aninhados) são difíceis de lidar. |
"core/html" | Este só faz sentido para a web. |
"core/table""core/button""core/media-text" | Eu não tinha ideia de como representar seus dados de maneira meio agnóstica ou se isso faz sentido. |
Isso me deixa com os seguintes blocos, para os quais vou extrair seus metadados:
-
'core/paragraph' -
'core/image' -
'core-embed/youtube'(como representante de todos os blocos'core-embed') -
'core/heading' -
'core/gallery' -
'core/list' -
'core/audio' -
'core/file' -
'core/video' -
'core/code' -
'core/preformatted' -
'core/quote'e'core/pullquote' -
'core/verse'
Para extrair os metadados, criamos a função get_block_metadata($block_data) que recebe um array com os dados do bloco para cada bloco (ou seja, a saída da nossa função get_block_data implementada anteriormente) e, dependendo do tipo de bloco (fornecido na propriedade "blockName" ), decide quais atributos são necessários e como extraí-los:
/** * Process all (Gutenberg) blocks' metadata into a medium-agnostic format from a WordPress post */ function get_block_metadata($block_data) { $ret = []; foreach ($block_data as $block) { $blockMeta = null; switch ($block['blockName']) { case ...: $blockMeta = ... break; case ...: $blockMeta = ... break; ... } if ($blockMeta) { $ret[] = [ 'blockName' => $block['blockName'], 'meta' => $blockMeta, ]; } } return $ret; }Vamos extrair os metadados para cada tipo de bloco, um por um:
“core/paragraph”
Simplesmente remova as tags HTML do conteúdo e remova as linhas de quebra à direita.
case 'core/paragraph': $blockMeta = [ 'content' => trim(strip_html_tags($block['innerHTML'])), ]; break; 'core/image'
O bloco tem um ID referente a um arquivo de mídia carregado ou, se não, a fonte da imagem deve ser extraída de <img src="..."> . Vários atributos (caption, linkDestination, link, alinhamento) são opcionais.
case 'core/image': $blockMeta = []; // If inserting the image from the Media Manager, it has an ID if ($block['attrs']['id'] && $img = wp_get_attachment_image_src($block['attrs']['id'], $block['attrs']['sizeSlug'])) { $blockMeta['img'] = [ 'src' => $img[0], 'width' => $img[1], 'height' => $img[2], ]; } elseif ($src = extract_image_src($block['innerHTML'])) { $blockMeta['src'] = $src; } if ($caption = extract_caption($block['innerHTML'])) { $blockMeta['caption'] = $caption; } if ($linkDestination = $block['attrs']['linkDestination']) { $blockMeta['linkDestination'] = $linkDestination; if ($link = extract_link($block['innerHTML'])) { $blockMeta['link'] = $link; } } if ($align = $block['attrs']['align']) { $blockMeta['align'] = $align; } break; Faz sentido criar as funções extract_image_src , extract_caption e extract_link já que suas expressões regulares serão usadas repetidamente por vários blocos. Observe que uma legenda em Gutenberg pode conter links ( <a href="..."> ), no entanto, ao chamar strip_html_tags , eles são removidos da legenda.
Apesar de lamentável, considero esta prática inevitável, pois não podemos garantir um link para funcionar em plataformas não web. Assim, embora o conteúdo esteja ganhando universalidade, pois pode ser usado para diferentes mídias, também está perdendo especificidade, portanto, sua qualidade é inferior em relação ao conteúdo que foi criado e customizado para a plataforma específica.
function extract_caption($innerHTML) { $matches = []; preg_match('/<figcaption>(.*?)<\/figcaption>/', $innerHTML, $matches); if ($caption = $matches[1]) { return strip_html_tags($caption); } return null; } function extract_link($innerHTML) { $matches = []; preg_match('/<a href="(.*?)">(.*?)<\/a>>', $innerHTML, $matches); if ($link = $matches[1]) { return $link; } return null; } function extract_image_src($innerHTML) { $matches = []; preg_match('/<img src="(.*?)"/', $innerHTML, $matches); if ($src = $matches[1]) { return $src; } return null; } 'core-embed/youtube'
Simplesmente recupere o URL do vídeo dos atributos do bloco e extraia sua legenda do conteúdo HTML, se existir.
case 'core-embed/youtube': $blockMeta = [ 'url' => $block['attrs']['url'], ]; if ($caption = extract_caption($block['innerHTML'])) { $blockMeta['caption'] = $caption; } break; 'core/heading'
Tanto o tamanho do cabeçalho (h1, h2, …, h6) quanto o texto do cabeçalho não são atributos, portanto devem ser obtidos do conteúdo HTML. Observe que, em vez de retornar a tag HTML para o cabeçalho, o atributo size é simplesmente uma representação equivalente, que é mais agnóstica e faz mais sentido para plataformas não web.
case 'core/heading': $matches = []; preg_match('/<h[1-6])>(.*?)<\/h([1-6])>/', $block['innerHTML'], $matches); $sizes = [ null, 'xxl', 'xl', 'l', 'm', 'sm', 'xs', ]; $blockMeta = [ 'size' => $sizes[$matches[1]], 'heading' => $matches[2], ]; break; 'core/gallery'
Infelizmente, para a galeria de imagens não consegui extrair as legendas de cada imagem, pois não são atributos, e extraí-las através de uma simples expressão regular pode falhar: Se houver uma legenda para o primeiro e terceiro elementos, mas nenhuma para a segunda, então eu não saberia qual legenda corresponde a qual imagem (e não dediquei tempo para criar um regex complexo). Da mesma forma, na lógica abaixo, estou sempre recuperando o tamanho "full" da imagem, no entanto, isso não precisa ser o caso e desconheço como o tamanho mais apropriado pode ser inferido.
case 'core/gallery': $imgs = []; foreach ($block['attrs']['ids'] as $img_id) { $img = wp_get_attachment_image_src($img_id, 'full'); $imgs[] = [ 'src' => $img[0], 'width' => $img[1], 'height' => $img[2], ]; } $blockMeta = [ 'imgs' => $imgs, ]; break; 'core/list'
Simplesmente transforme os elementos <li> em uma matriz de itens.
case 'core/list': $matches = []; preg_match_all('/<li>(.*?)<\/li>/', $block['innerHTML'], $matches); if ($items = $matches[1]) { $blockMeta = [ 'items' => array_map('strip_html_tags', $items), ]; } break; 'core/audio'
Obtenha o URL do arquivo de mídia carregado correspondente.
case 'core/audio': $blockMeta = [ 'src' => wp_get_attachment_url($block['attrs']['id']), ]; break; 'core/file'
Considerando que a URL do arquivo é um atributo, seu texto deve ser extraído do conteúdo interno.
case 'core/file': $href = $block['attrs']['href']; $matches = []; preg_match('/<a href="'.str_replace('/', '\/', $href).'">(.*?)<\/a>/', $block['innerHTML'], $matches); $blockMeta = [ 'href' => $href, 'text' => strip_html_tags($matches[1]), ]; break; 'core/video'
Obtenha o URL do vídeo e todas as propriedades para configurar como o vídeo é reproduzido por meio de uma expressão regular. Se o Gutenberg alterar a ordem em que essas propriedades são impressas no código, essa regex deixará de funcionar, evidenciando um dos problemas de não adicionar metadados diretamente pelos atributos do bloco.
case 'core/video': $matches = []; preg_match('/ 'core/code'
Simply extract the code from within <code /> .
case 'core/code': $matches = []; preg_match('/<code>(.*?)<\/code>/is', $block['innerHTML'], $matches); $blockMeta = [ 'code' => $matches[1], ]; break; 'core/preformatted'
Similar to <code /> , but we must watch out that Gutenberg hardcodes a class too.
case 'core/preformatted': $matches = []; preg_match('/<pre class="wp-block-preformatted">(.*?)<\/pre>/is', $block['innerHTML'], $matches); $blockMeta = [ 'text' => strip_html_tags($matches[1]), ]; break; 'core/quote' and 'core/pullquote'
We must convert all inner <p /> tags to their equivalent generic "\n" character.
case 'core/quote': case 'core/pullquote': $matches = []; $regexes = [ 'core/quote' => '/<blockquote class=\"wp-block-quote\">(.*?)<\/blockquote>/', 'core/pullquote' => '/<figure class=\"wp-block-pullquote\"><blockquote>(.*?)<\/blockquote><\/figure>/', ]; preg_match($regexes[$block['blockName']], $block['innerHTML'], $matches); if ($quoteHTML = $matches[1]) { preg_match_all('/<p>(.*?)<\/p>/', $quoteHTML, $matches); $blockMeta = [ 'quote' => strip_html_tags(implode('\n', $matches[1])), ]; preg_match('/<cite>(.*?)<\/cite>/', $quoteHTML, $matches); if ($cite = $matches[1]) { $blockMeta['cite'] = strip_html_tags($cite); } } break; 'core/verse'
Similar situation to <pre /> .
case 'core/verse': $matches = []; preg_match('/<pre class="wp-block-verse">(.*?)<\/pre>/is', $block['innerHTML'], $matches); $blockMeta = [ 'text' => strip_html_tags($matches[1]), ]; break;3. Exporting Data Through An API
Now that we have extracted all block metadata, we need to make it available to our different mediums, through an API. WordPress has access to the following APIs:
- REST, through the WP REST API (integrated in WordPress core)
- GraphQL, through WPGraphQL
- PoP, through its implementation for WordPress
Let's see how to export the data through each of them.
DESCANSO
The following code creates endpoint /wp-json/block-metadata/v1/metadata/{POST_ID} which exports all block metadata for a specific post:
/** * Define REST endpoints to export the blocks' metadata for a specific post */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'metadata/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_block_meta' ]); }); function get_post_block_meta($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $block_metadata = get_block_metadata($block_data); $response = new WP_REST_Response($block_metadata); $response->set_status(200); return $response; }/** * Define REST endpoints to export the blocks' metadata for a specific post */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'metadata/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_block_meta' ]); }); function get_post_block_meta($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $block_metadata = get_block_metadata($block_data); $response = new WP_REST_Response($block_metadata); $response->set_status(200); return $response; }
To see it working, this link (corresponding to this blog post) displays the metadata for blocks of all the types analyzed earlier on.
GraphQL (Through WPGraphQL)
GraphQL works by setting-up schemas and types which define the structure of the content, from which arises this API's power to fetch exactly the required data and nothing else. Setting-up schemas works very well when the structure of the object has a unique representation.
In our case, however, the metadata returned by a new field "block_metadata" (which calls our newly-created function get_block_metadata ) depends on the specific block type, so the structure of the response can vary wildly; GraphQL provides a solution to this issue through a Union type, allowing to return one among a set of different types. However, its implementation for all different variations of the metadata structure has proved to be a lot of work, and I quit along the way .
As an alternative (not ideal) solution, I decided to provide the response by simply encoding the JSON object through a new field "jsonencoded_block_metadata" :
/** * Define WPGraphQL field "jsonencoded_block_metadata" */ add_action('graphql_register_types', function() { register_graphql_field( 'Post', 'jsonencoded_block_metadata', [ 'type' => 'String', 'description' => __('Post blocks encoded as JSON', 'wp-graphql'), 'resolve' => function($post) { $post = get_post($post->ID); $block_data = get_block_data($post->post_content); $block_metadata = get_block_metadata($block_data); return json_encode($block_metadata); } ] ); });PoP
Note: This functionality is available on its own GitHub repo.
The final API is called PoP, which is a little-known project I've been working on for several years now. I have recently converted it into a full-fledged API, with the capacity to produce a response compatible with both REST and GraphQL, and which even benefits from the advantages from these 2 APIs, at the same time: no under/over-fetching of data, like in GraphQL, while being cacheable on the server-side and not susceptible to DoS attacks, like REST. It offers a mix between the two of them: REST-like endpoints with GraphQL-like queries.
The block metadata is made available through the API through the following code:
class PostFieldValueResolver extends AbstractDBDataFieldValueResolver { public static function getClassesToAttachTo(): array { return array(\PoP\Posts\FieldResolver::class); } public function resolveValue(FieldResolverInterface $fieldResolver, $resultItem, string $fieldName, array $fieldArgs = []) { $post = $resultItem; switch ($fieldName) { case 'block-metadata': $block_data = \Leoloso\BlockMetadata\Data::get_block_data($post->post_content); $block_metadata = \Leoloso\BlockMetadata\Metadata::get_block_metadata($block_data); // Filter by blockName if ($blockName = $fieldArgs['blockname']) { $block_metadata = array_filter( $block_metadata, function($block) use($blockName) { return $block['blockName'] == $blockName; } ); } return $block_metadata; } return parent::resolveValue($fieldResolver, $resultItem, $fieldName, $fieldArgs); } }To see it in action, this link displays the block metadata (+ ID, title and URL of the post, and the ID and name of its author, a la GraphQL) for a list of posts.
Além disso, assim como os argumentos do GraphQL, nossa consulta pode ser personalizada por meio de argumentos de campo, permitindo obter apenas os dados que fazem sentido para uma plataforma específica. Por exemplo, se desejarmos extrair todos os vídeos do Youtube adicionados a todas as postagens, podemos adicionar o modificador (blockname:core-embed/youtube) ao campo block-metadata no URL do endpoint, como neste link. Ou se quisermos extrair todas as imagens de um post específico, podemos adicionar modificador (blockname:core/image) como neste outro link|id|title).
Conclusão
A estratégia COPE (“Create Once, Publish Everywhere”) nos ajuda a reduzir o trabalho necessário para criar vários aplicativos que devem ser executados em diferentes mídias (web, e-mail, aplicativos, assistentes domésticos, realidade virtual etc.) criando uma única fonte de verdade para o nosso conteúdo. No que diz respeito ao WordPress, apesar de sempre ter brilhado como um Sistema de Gestão de Conteúdos, a implementação da estratégia COPE tem-se mostrado historicamente um desafio.
No entanto, alguns desenvolvimentos recentes tornaram cada vez mais viável implementar essa estratégia para o WordPress. Por um lado, desde a integração no núcleo da WP REST API, e mais marcadamente desde o lançamento do Gutenberg, a maior parte do conteúdo do WordPress é acessível por meio de APIs, tornando-o um sistema sem cabeça genuíno. Por outro lado, o Gutenberg (que é o novo editor de conteúdo padrão) é baseado em blocos, tornando todos os metadados dentro de uma postagem de blog prontamente acessíveis às APIs.
Como consequência, a implementação do COPE para WordPress é simples. Neste artigo, vimos como fazê-lo, e todo o código relevante foi disponibilizado através de vários repositórios. Mesmo que a solução não seja ótima (já que envolve muita análise de código HTML), ela ainda funciona muito bem, com a consequência de que o esforço necessário para liberar nossos aplicativos para várias plataformas pode ser bastante reduzido. Parabéns por isso!