
Criando um fluxo de trabalho de teste de integração contínua usando o GitHub Actions
Publicados: 2022-03-10Ao contribuir com projetos em plataformas de controle de versão como GitHub e Bitbucket, a convenção é que existe o branch principal contendo a base de código funcional. Depois, existem outras ramificações nas quais vários desenvolvedores podem trabalhar em cópias da principal para adicionar um novo recurso, corrigir um bug e assim por diante. Faz muito sentido porque fica mais fácil monitorar o tipo de efeito que as alterações recebidas terão no código existente. Se houver algum erro, ele pode ser facilmente rastreado e corrigido antes de integrar as alterações na ramificação principal. Pode ser demorado passar por cada linha de código manualmente procurando por erros ou bugs – mesmo para um projeto pequeno. É aí que entra a integração contínua.
O que é Integração Contínua (CI)?
“A integração contínua (CI) é a prática de automatizar a integração de alterações de código de vários colaboradores em um único projeto de software.”
— Atlassian. com
A ideia geral por trás da integração contínua (CI) é garantir que as alterações feitas no projeto não “quebrem a compilação”, ou seja, arruinem a base de código existente. Implementar a integração contínua em seu projeto, dependendo de como você configurou seu fluxo de trabalho, criaria uma compilação sempre que alguém fizesse alterações no repositório.
Então, o que é uma construção?
Uma compilação — neste contexto — é a compilação do código-fonte em um formato executável. Se for bem-sucedido, significa que as alterações recebidas não afetarão negativamente a base de código e estão prontas. No entanto, se a compilação falhar, as alterações terão que ser reavaliadas. É por isso que é aconselhável fazer alterações em um projeto trabalhando em uma cópia do projeto em um branch diferente antes de incorporá-lo à base de código principal. Dessa forma, se a compilação for interrompida, será mais fácil descobrir de onde vem o erro e também não afetará seu código-fonte principal.
“Quanto mais cedo você detectar defeitos, mais barato eles serão para consertar.”
— David Farley, Continuous Delivery: Reliable Software Releases through Build, Test and Deployment Automation
Existem várias ferramentas disponíveis para ajudar na criação de integração contínua para o seu projeto. Estes incluem Jenkins, TravisCI, CircleCI, GitLab CI, GitHub Actions, etc. Para este tutorial, usarei GitHub Actions.
Ações do GitHub para integração contínua
CI Actions é um recurso relativamente novo no GitHub e permite a criação de fluxos de trabalho que executam automaticamente a compilação e os testes do seu projeto. Um fluxo de trabalho contém um ou mais trabalhos que podem ser ativados quando ocorre um evento. Esse evento pode ser um push para qualquer uma das ramificações do repositório ou a criação de uma solicitação pull. Explicarei esses termos em detalhes à medida que prosseguirmos.
Vamos começar!
Pré-requisitos
Este é um tutorial para iniciantes, então falarei principalmente sobre o GitHub Actions CI em um nível superficial. Os leitores já devem estar familiarizados com a criação de uma API REST Node JS usando o banco de dados PostgreSQL, Sequelize ORM e escrevendo testes com Mocha e Chai.
Você também deve ter o seguinte instalado em sua máquina:
- NodeJS,
- PostgreSQL,
- NPM,
- VSCode (ou qualquer editor e terminal de sua escolha).
Vou fazer uso de uma API REST que já criei chamada countries-info-api . É uma API simples sem autorizações baseadas em função (como no momento em que escrevo este tutorial). Isso significa que qualquer pessoa pode adicionar, excluir e/ou atualizar os detalhes de um país. Cada país terá um id (UUID gerado automaticamente), nome, capital e população. Para isso, usei Node js, express js framework e Postgresql para o banco de dados.
Explicarei brevemente como configuro o servidor, o banco de dados antes de começar a escrever os testes para cobertura de teste e o arquivo de fluxo de trabalho para integração contínua.
Você pode clonar o repositório countries-info-api para acompanhar ou criar sua própria API.
Tecnologia utilizada : Node Js, NPM (um gerenciador de pacotes para Javascript), banco de dados Postgresql, sequelize ORM, Babel.
Configurando o Servidor
Antes de configurar o servidor, instalei algumas dependências do npm.
npm install express dotenv cors npm install --save-dev @babel/core @babel/cli @babel/preset-env nodemonEstou usando o framework express e escrevendo no formato ES6, então vou precisar do Babeljs para compilar meu código. Você pode ler a documentação oficial para saber mais sobre como funciona e como configurá-lo para o seu projeto. O Nodemon detectará quaisquer alterações feitas no código e reiniciará automaticamente o servidor.
Nota : Os pacotes Npm instalados usando o --save-dev são necessários apenas durante os estágios de desenvolvimento e são vistos em devDependencies no arquivo package.json .
Adicionei o seguinte ao meu arquivo index.js :
import express from "express"; import bodyParser from "body-parser"; import cors from "cors"; import "dotenv/config"; const app = express(); const port = process.env.PORT; app.use(bodyParser.json()); app.use(bodyParser.urlencoded({ extended: true })); app.use(cors()); app.get("/", (req, res) => { res.send({message: "Welcome to the homepage!"}) }) app.listen(port, () => { console.log(`Server is running on ${port}...`) }) Isso configura nossa API para ser executada no que for atribuído à variável PORT no arquivo .env . É também aqui que declararemos variáveis às quais não queremos que outros tenham acesso fácil. O pacote dotenv npm carrega nossas variáveis de ambiente de .env .
Agora, quando executo npm run start no meu terminal, recebo isso:
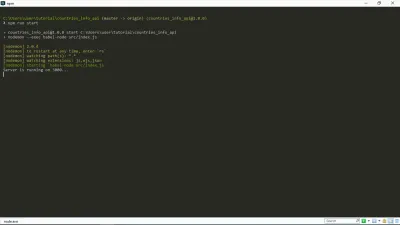
Como você pode ver, nosso servidor está funcionando. Yay!
Este link https://127.0.0.1:your_port_number/ em seu navegador da web deve retornar a mensagem de boas-vindas. Ou seja, enquanto o servidor estiver em execução.
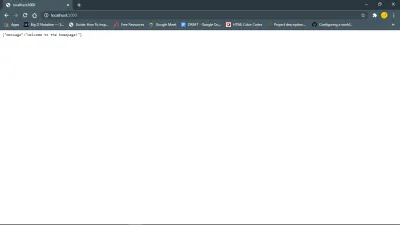
Em seguida, Banco de Dados e Modelos.
Criei o modelo de país usando o Sequelize e conectei ao meu banco de dados Postgres. Sequelize é um ORM para Nodejs. Uma grande vantagem é que nos poupa o tempo de escrever consultas SQL brutas.
Como estamos usando o Postgresql, o banco de dados pode ser criado através da linha de comando psql usando o CREATE DATABASE database_name . Isso também pode ser feito no seu terminal, mas prefiro o PSQL Shell.
No arquivo env, vamos configurar a string de conexão do nosso banco de dados, seguindo este formato abaixo.
TEST_DATABASE_URL = postgres://<db_username>:<db_password>@127.0.0.1:5432/<database_name>Para o meu modelo, segui este tutorial de sequela. É fácil de seguir e explica tudo sobre como configurar o Sequelize.
Em seguida, escreverei testes para o modelo que acabei de criar e configurarei a cobertura no Coverall.
Escrita de testes e cobertura de relatórios
Por que escrever testes? Pessoalmente, acredito que escrever testes ajuda você como desenvolvedor a entender melhor como se espera que seu software funcione nas mãos de seu usuário porque é um processo de brainstorming. Também ajuda a descobrir bugs a tempo.
Testes:
Existem diferentes métodos de teste de software, no entanto, para este tutorial, usei testes unitários e de ponta a ponta.
Eu escrevi meus testes usando o framework de teste Mocha e a biblioteca de asserções Chai. Também instalei sequelize-test-helpers para ajudar a testar o modelo que criei usando sequelize.define .
Cobertura de teste:
É aconselhável verificar sua cobertura de teste porque o resultado mostra se nossos casos de teste estão realmente cobrindo o código e também quanto código é usado quando executamos nossos casos de teste.

Eu usei Istanbul (uma ferramenta de cobertura de testes), nyc (cliente CLI da Instabul) e Coveralls.
De acordo com os documentos, Istanbul instrumenta seu código JavaScript ES5 e ES2015+ com contadores de linha, para que você possa acompanhar o quão bem seus testes de unidade exercitam sua base de código.
No meu arquivo package.json , o script de teste executa os testes e gera um relatório.
{ "scripts": { "test": "nyc --reporter=lcov --reporter=text mocha -r @babel/register ./src/test/index.js" } } No processo, ele criará uma pasta .nyc_output contendo as informações de cobertura bruta e uma pasta de coverage contendo os arquivos de relatório de cobertura. Ambos os arquivos não são necessários no meu repositório, então eu os coloquei no arquivo .gitignore .
Agora que geramos um relatório, temos que enviá-lo para o Coveralls. Uma coisa legal sobre o Coveralls (e outras ferramentas de cobertura, suponho) é como ele relata sua cobertura de teste. A cobertura é dividida arquivo por arquivo e você pode ver a cobertura relevante, linhas cobertas e perdidas e o que mudou na cobertura de construção.
Para começar, instale o pacote npm do macacão. Você também precisa fazer login no macacão e adicionar o repositório a ele.
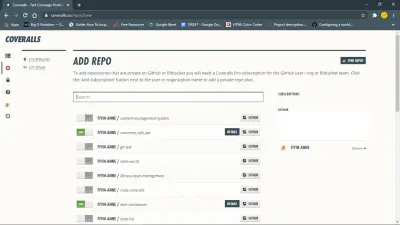
Em seguida, configure macacões para seu projeto javascript criando um arquivo coveralls.yml em seu diretório raiz. Este arquivo conterá seu repo-token obtido na seção de configurações do seu repositório em macacões.
Outro script necessário no arquivo package.json são os scripts de cobertura. Este script será útil quando estivermos criando uma compilação via Actions.
{ "scripts": { "coverage": "nyc npm run test && nyc report --reporter=text-lcov --reporter=lcov | node ./node_modules/coveralls/bin/coveralls.js --verbose" } }Basicamente, ele executará os testes, obterá o relatório e o enviará para o macacão para análise.
Agora vamos ao ponto principal deste tutorial.
Criar arquivo de fluxo de trabalho JS do nó
Neste ponto, configuramos os trabalhos necessários que executaremos em nossa ação do GitHub. (Quer saber o que significa “empregos”? Continue lendo.)
O GitHub facilitou a criação do arquivo de fluxo de trabalho fornecendo um modelo inicial. Conforme visto na página Ações, existem vários modelos de fluxo de trabalho que atendem a diferentes propósitos. Para este tutorial, usaremos o fluxo de trabalho Node.js (que o GitHub já sugeriu gentilmente).
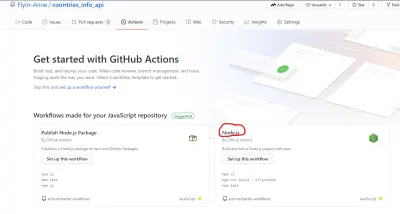
Você pode editar o arquivo diretamente no GitHub, mas vou criar manualmente o arquivo no meu repositório local. A pasta .github/workflows que contém o arquivo node.js.yml estará no diretório raiz.
Este arquivo já contém alguns comandos básicos e o primeiro comentário explica o que eles fazem.
# This workflow will do a clean install of node dependencies, build the source code and run tests across different versions of nodeFarei algumas alterações para que, além do comentário acima, também faça cobertura.
Meu arquivo .node.js.yml :
name: NodeJS CI on: ["push"] jobs: build: name: Build runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build --if-present - run: npm run coverage - name: Coveralls uses: coverallsapp/github-action@master env: COVERALLS_REPO_TOKEN: ${{ secrets.COVERALLS_REPO_TOKEN }} COVERALLS_GIT_BRANCH: ${{ github.ref }} with: github-token: ${{ secrets.GITHUB_TOKEN }}O que isto significa?
Vamos decompô-lo.
-
name
Esse seria o nome do seu fluxo de trabalho (NodeJS CI) ou trabalho (build) e o GitHub o exibirá na página de ações do seu repositório. -
on
Este é o evento que aciona o fluxo de trabalho. Essa linha no meu arquivo está basicamente dizendo ao GitHub para acionar o fluxo de trabalho sempre que um push for feito para meu repositório. -
jobs
Um fluxo de trabalho pode conter pelo menos um ou mais trabalhos e cada trabalho é executado em um ambiente especificado porruns-on. No exemplo de arquivo acima, há apenas um trabalho que executa a compilação e também executa a cobertura e é executado em um ambiente Windows. Eu também posso separá-lo em dois trabalhos diferentes como este:
Arquivo Node.yml atualizado
name: NodeJS CI on: [push] jobs: build: name: Build runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build --if-present - run: npm run test coverage: name: Coveralls runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: coverallsapp/github-action@master env: COVERALLS_REPO_TOKEN: ${{ secrets.COVERALLS_REPO_TOKEN }} with: github-token: ${{ secrets.GITHUB_TOKEN }}-
env
Ele contém as variáveis de ambiente que estão disponíveis para todos ou tarefas e etapas específicas no fluxo de trabalho. No trabalho de cobertura, você pode ver que as variáveis de ambiente foram “ocultas”. Eles podem ser encontrados na página de segredos do seu repositório em configurações. -
steps
Isso basicamente é uma lista das etapas a serem seguidas ao executar esse trabalho. - O trabalho de
buildfaz várias coisas:- Ele usa uma ação de check-out (v2 significa a versão) que literalmente faz o check-out do seu repositório para que seja acessível pelo seu fluxo de trabalho;
- Ele usa uma ação setup-node que configura o ambiente do nó a ser usado;
- Ele executa scripts de instalação, construção e teste encontrados em nosso arquivo package.json.
-
coverage
Isso usa uma ação coverallsapp que publica os dados de cobertura LCOV do seu conjunto de testes para coveralls.io para análise.
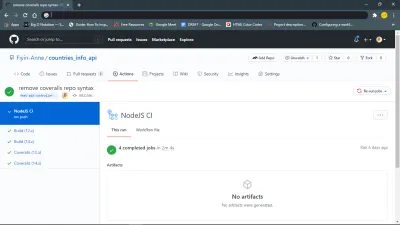
Inicialmente, fiz um push para meu branch feat-add-controllers-and-route e esqueci de adicionar o repo_token de Coveralls ao meu arquivo .coveralls.yml , então recebi o erro que você pode ver na linha 132.
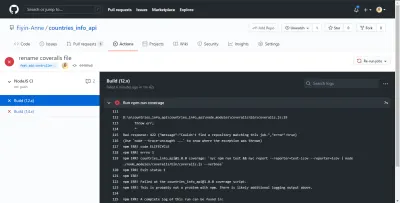
Bad response: 422 {"message":"Couldn't find a repository matching this job.","error":true} Depois de adicionar o repo_token , minha compilação pôde ser executada com êxito. Sem esse token, os macacões não seriam capazes de relatar adequadamente minha análise de cobertura de teste. Ainda bem que nosso GitHub Actions CI apontou o erro antes de ser enviado para o branch principal.
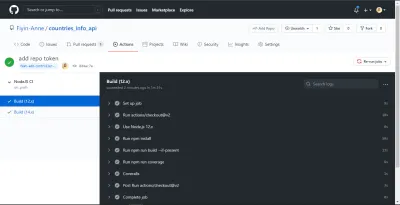
NB: Estas foram tiradas antes de eu separar o trabalho em dois trabalhos. Além disso, consegui ver o resumo da cobertura - e a mensagem de erro - no meu terminal porque adicionei o sinalizador --verbose no final do meu script de cobertura
Conclusão
Podemos ver como configurar a integração contínua para nossos projetos e também integrar a cobertura de testes usando as Actions disponibilizadas pelo GitHub. Existem muitas outras maneiras de ajustar isso para atender às necessidades do seu projeto. Embora o repositório de amostra usado neste tutorial seja um projeto realmente menor, você pode ver como a integração contínua é essencial mesmo em um projeto maior. Agora que meus trabalhos foram executados com sucesso, estou confiante em mesclar a ramificação com minha ramificação principal. Eu ainda aconselharia que você também leia os resultados das etapas após cada execução para ver se é completamente bem-sucedido.