
Adicionando recursos de divisão de código a um site WordPress por meio de PoP
Publicados: 2022-03-10A velocidade está entre as principais prioridades de qualquer site hoje em dia. Uma maneira de fazer um site carregar mais rápido é dividir o código: dividir um aplicativo em partes que podem ser carregadas sob demanda - carregando apenas o JavaScript necessário e nada mais. Sites baseados em estruturas JavaScript podem implementar imediatamente a divisão de código por meio do Webpack, o popular empacotador de JavaScript. Para sites WordPress, porém, não é tão fácil. Primeiro, o Webpack não foi construído intencionalmente para funcionar com o WordPress, portanto, configurá-lo exigirá algumas soluções alternativas; em segundo lugar, nenhuma ferramenta parece estar disponível que forneça recursos nativos de carregamento de ativos sob demanda para o WordPress.
Dada a falta de uma solução adequada para WordPress, decidi implementar minha própria versão de code-splitting para PoP, um framework de código aberto para construção de sites WordPress que criei. Um site WordPress com PoP instalado terá recursos de divisão de código nativamente, portanto, não precisará depender do Webpack ou de qualquer outro empacotador. Neste artigo, mostrarei como isso é feito, explicando quais decisões foram tomadas com base em aspectos da arquitetura do framework. No final, analisarei o desempenho de um site com e sem divisão de código e os benefícios e desvantagens de usar uma implementação personalizada em um empacotador externo. Espero que você aproveite o passeio!
Definindo a Estratégia
A divisão de código pode ser amplamente dividida nestas duas etapas:
- Calculando quais ativos devem ser carregados para cada rota,
- Carregar dinamicamente esses ativos sob demanda.
Para enfrentar a primeira etapa, precisaremos produzir um mapa de dependência de ativos, incluindo todos os ativos em nosso aplicativo. Os ativos devem ser adicionados recursivamente a este mapa — dependências de dependências também devem ser adicionadas, até que nenhum ativo adicional seja necessário. Podemos então calcular todas as dependências necessárias para uma rota específica percorrendo o mapa de dependência de ativos, começando do ponto de entrada da rota (ou seja, o arquivo ou pedaço de código a partir do qual ela inicia a execução) até o último nível.
Para lidar com a segunda etapa, poderíamos calcular quais ativos são necessários para a URL solicitada no lado do servidor e, em seguida, enviar a lista de ativos necessários na resposta, sobre os quais o aplicativo precisaria carregá-los, ou diretamente HTTP/ 2 empurre os recursos ao lado da resposta.
Essas soluções, no entanto, não são ótimas. No primeiro caso, o aplicativo deve solicitar todos os ativos após a resposta ser retornada, de modo que haveria uma série adicional de solicitações de ida e volta para buscar os ativos e a visualização não poderia ser gerada antes que todos eles fossem carregados, resultando em o usuário ter que esperar (esse problema é facilitado tendo todos os ativos pré-cache por meio de service workers, então o tempo de espera é reduzido, mas não podemos evitar a análise dos ativos que acontece somente depois que a resposta está de volta). No segundo caso, podemos enviar os mesmos ativos repetidamente (a menos que adicionemos alguma lógica extra, como indicar quais recursos já carregamos por meio de cookies, mas isso realmente adiciona complexidade indesejada e impede que a resposta seja armazenada em cache) e não pode servir os ativos de uma CDN.
Por causa disso, decidi tratar essa lógica no lado do cliente. Uma lista de quais ativos são necessários para cada rota é disponibilizada para o aplicativo no cliente, para que ele já saiba quais ativos são necessários para a URL solicitada. Isso resolve os problemas mencionados acima:
- Os ativos podem ser carregados imediatamente, não sendo necessário aguardar a resposta do servidor. (Quando combinamos isso com os service workers, podemos ter certeza de que, quando a resposta estiver de volta, todos os recursos terão sido carregados e analisados, portanto, não há tempo de espera adicional.)
- O aplicativo sabe quais ativos já foram carregados; portanto, ele não solicitará todos os ativos necessários para essa rota, mas apenas os ativos que ainda não foram carregados.
O aspecto negativo de entregar essa lista para o front end é que ela pode ficar pesada, dependendo do tamanho do site (como quantas rotas ele disponibiliza). Precisamos encontrar uma maneira de carregá-lo sem aumentar o tempo de carregamento percebido do aplicativo. Mais sobre isso mais tarde.
Tendo tomado essas decisões, podemos prosseguir com o design e, em seguida, implementar a divisão de código no aplicativo. Para facilitar o entendimento, o processo foi dividido nas seguintes etapas:
- Entendendo a arquitetura do aplicativo,
- Mapeamento de dependências de ativos,
- Listando todas as rotas de aplicativos,
- Gerando uma lista que define quais ativos são necessários para cada rota,
- Carregando ativos dinamicamente,
- Aplicando otimizações.
Vamos direto ao assunto!
0. Entendendo a Arquitetura do Aplicativo
Precisaremos mapear a relação de todos os ativos entre si. Vamos analisar as particularidades da arquitetura do PoP para projetar a solução mais adequada para atingir esse objetivo.
PoP é uma camada que envolve o WordPress, permitindo-nos usar o WordPress como o CMS que alimenta o aplicativo, mas fornecendo uma estrutura JavaScript personalizada para renderizar conteúdo no lado do cliente para criar sites dinâmicos. Ele redefine os componentes de construção da página web: enquanto o WordPress atualmente é baseado no conceito de templates hierárquicos que produzem HTML (como single.php , home.php e archive.php ), o PoP é baseado no conceito de “modules, ” que são uma funcionalidade atômica ou uma composição de outros módulos. Construir um aplicativo PoP é semelhante a brincar com LEGO – empilhar módulos uns sobre os outros ou embrulhar uns aos outros, criando uma estrutura mais complexa. Também pode ser pensado como uma implementação do design atômico de Brad Frost, e se parece com isso:
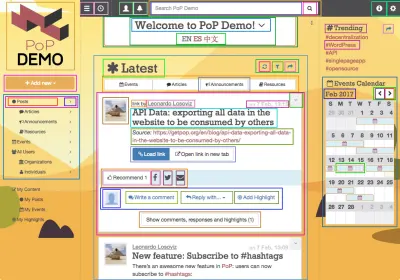
Os módulos podem ser agrupados em entidades de ordem superior, a saber: blocks, blockGroups, pageSections e topLevels. Essas entidades também são módulos, apenas com propriedades e responsabilidades adicionais, e contêm umas às outras seguindo uma arquitetura estritamente top-down na qual cada módulo pode ver e alterar as propriedades de todos os seus módulos internos. A relação entre os módulos é assim:
- 1 topLevel contém N pageSections,
- 1 pageSection contém N blocos ou blockGroups,
- 1 blockGroup contém N blocos ou blockGroups,
- 1 bloco contém N módulos,
- 1 módulo contém N módulos, ad infinitum.
Executando código JavaScript no PoP
O PoP cria HTML dinamicamente, começando no nível pageSection, iterando por todos os módulos abaixo da linha, renderizando cada um deles por meio do modelo Handlebars predefinido do módulo e, finalmente, adicionando os elementos recém-criados correspondentes do módulo no DOM. Feito isso, ele executa funções JavaScript neles, que são predefinidas módulo a módulo.
PoP difere de frameworks JavaScript (como React e AngularJS) em que o fluxo da aplicação não se origina no cliente, mas ainda é configurado no back-end, dentro da configuração do módulo (que é codificado em um objeto PHP). Influenciado pelos ganchos de ação do WordPress, o PoP implementa um padrão de publicação-assinatura:
- Cada módulo define quais funções JavaScript devem ser executadas em seus elementos DOM recém-criados correspondentes, não necessariamente sabendo de antemão o que executará esse código ou de onde ele virá.
- Objetos JavaScript devem registrar quais funções JavaScript eles implementam.
- Finalmente, em tempo de execução, o PoP calcula quais objetos JavaScript devem executar quais funções JavaScript e os invoca apropriadamente.
Por exemplo, por meio de seu objeto PHP correspondente, um módulo de calendário indica que ele precisa que a função de calendar seja executada em seus elementos DOM assim:
class CalendarModule { function get_jsmethods() { $methods = parent::get_jsmethods(); $this->add_jsmethod($methods, 'calendar'); return $methods; } ... } Em seguida, um objeto JavaScript — neste caso, popFullCalendar — anuncia que implementou a função de calendar . Isso é feito chamando popJSLibraryManager.register :
window.popFullCalendar = { calendar : function(elements) { ... } }; popJSLibraryManager.register(popFullCalendar, ['calendar', ...]); Finalmente, popJSLibraryManager faz a correspondência sobre o que executa qual código. Ele permite que objetos JavaScript registrem quais funções eles implementam e fornece um método para executar uma função específica de todos os objetos JavaScript inscritos:
window.popJSLibraryManager = { libraries: [], methods: {}, register : function(library, methods) { this.libraries.push(library); for (var i = 0; i < methods.length; i++) { var method = methods[i]; this.methods[method] = this.methods[method] || []; this.methods[method].push(library); } }, execute : function(method, elements) { var libraries = this.methods[method] || []; for (var i = 0; i < libraries.length; i++) { var library = libraries[i]; library[method](elements); } } } Depois que um novo elemento de calendário for adicionado ao DOM, que possui um ID de calendar-293 , o PoP simplesmente executará a seguinte função:
popJSLibraryManager.execute("calendar", document.getElementById("calendar-293"));Ponto de entrada
Para PoP, o ponto de entrada para executar o código JavaScript é esta linha no final da saída HTML:
<script type="text/javascript">popManager.init();</script> popManager.init() primeiro inicializa o framework front-end e, em seguida, executa as funções JavaScript definidas por todos os módulos renderizados, conforme explicado acima. Abaixo está uma forma bem simplificada desta função (o código original está no GitHub). Ao invocar popJSLibraryManager.execute('pageSectionInitialized', pageSection) e popJSLibraryManager.execute('documentInitialized') , todos os objetos JavaScript que implementam essas funções ( pageSectionInitialized e documentInitialized ) as executarão.
(function($){ window.popManager = { // The configuration for all the modules (including pageSections and blocks) in the application configuration : {...}, init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { // Obtain the pageSection element in the DOM from the ID var pageSection = $('#'+pageSectionId); // Run all required JavaScript methods on it this.runJSMethods(pageSection, configuration); // Trigger an event marking the block as initialized popJSLibraryManager.execute('pageSectionInitialized', pageSection); }); // Trigger an event marking the document as initialized popJSLibraryManager.execute('documentInitialized'); }, ... }; })(jQuery); A função runJSMethods executa os métodos JavaScript definidos para cada módulo, começando pelo pageSection, que é o módulo mais alto, e depois descendo a linha para todos os seus blocos internos e seus módulos internos:
(function($){ window.popManager = { ... runJSMethods : function(pageSection, configuration) { // Initialize the heap with "modules", starting from the top one, and recursively iterate over its inner modules var heap = [pageSection.data('module')], i; while (heap.length > 0) { // Get the first element of the heap var module = heap.pop(); // The configuration for that module contains which JavaScript methods to execute, and which are the module's inner modules var moduleConfiguration = configuration[module]; // The list of all JavaScript functions that must be executed on the module's newly created DOM elements var jsMethods = moduleConfiguration['js-methods']; // Get all of the elements added to the DOM for that module, which have been stored in JavaScript object `popJSRuntimeManager` upon creation var elements = popJSRuntimeManager.getDOMElements(module); // Iterate through all of the JavaScript methods and execute them, passing the elements as argument for (i = 0; i < jsMethods.length; i++) { popJSLibraryManager.execute(jsMethods[i], elements); } // Finally, add the inner-modules to the heap heap = heap.concat(moduleConfiguration['inner-modules']); } }, }; })(jQuery);Em resumo, a execução de JavaScript no PoP é fracamente acoplada: em vez de ter dependências fixas, executamos funções JavaScript por meio de ganchos que qualquer objeto JavaScript pode assinar.
Páginas da Web e APIs
Um site PoP é uma API autoconsumida. No PoP, não há distinção entre uma página da Web e uma API: cada URL retorna a página da Web por padrão e, apenas adicionando o parâmetro output=json , ele retorna sua API (por exemplo, getpop.org/en/ é um página da web e getpop.org/en/?output=json é sua API). A API é usada para renderizar conteúdo dinamicamente no PoP; então, ao clicar em um link para outra página, a API é o que é solicitado, pois até lá o frame do site já estará carregado (como a navegação superior e lateral) — então o conjunto de recursos necessários para o modo API será ser um subconjunto daquele da página da web. Precisamos levar isso em consideração ao calcular as dependências de uma rota: Carregar a rota ao carregar o site pela primeira vez ou carregá-la dinamicamente clicando em algum link produzirá diferentes conjuntos de ativos necessários.
Esses são os aspectos mais importantes do PoP que definirão o design e a implementação da divisão de código. Vamos prosseguir com o próximo passo.
1. Mapeamento de Dependências de Ativos
Poderíamos adicionar um arquivo de configuração para cada arquivo JavaScript, detalhando suas dependências explícitas. No entanto, isso duplicaria o código e seria difícil manter a consistência. Uma solução mais limpa seria manter os arquivos JavaScript como a única fonte de verdade, extraindo o código de dentro deles e analisando esse código para recriar as dependências.
Os metadados que procuramos nos arquivos de origem JavaScript, para poder recriar o mapeamento, são os seguintes:
- chamadas de métodos internos, como
this.runJSMethods(...); - chamadas de métodos externos, como
popJSRuntimeManager.getDOMElements(...); - todas as ocorrências de
popJSLibraryManager.execute(...), que executa uma função JavaScript em todos os objetos que a implementam; - todas as ocorrências de
popJSLibraryManager.register(...), para obter quais objetos JavaScript implementam quais métodos JavaScript.
Usaremos jParser e jTokenizer para tokenizar nossos arquivos de origem JavaScript em PHP e extrair os metadados, da seguinte forma:
- Chamadas de métodos internos (como
this.runJSMethods) são deduzidas ao encontrar a seguinte sequência: tokenthisouthat+.+ algum outro token, que é o nome do método interno (runJSMethods). - Chamadas de métodos externos (como
popJSRuntimeManager.getDOMElements) são deduzidas ao encontrar a seguinte sequência: um token incluído na lista de todos os objetos JavaScript em nosso aplicativo (precisaremos dessa lista antecipadamente; neste caso, ela conterá o objetopopJSRuntimeManager) +.+ algum outro token, que é o nome do método externo (getDOMElements). - Sempre que encontramos
popJSLibraryManager.execute("someFunctionName"), deduzimos que o método Javascript ésomeFunctionName. - Sempre que encontramos
popJSLibraryManager.register(someJSObject, ["someFunctionName1", "someFunctionName2"])deduzimos o objeto JavascriptsomeJSObjectpara implementar os métodossomeFunctionName1,someFunctionName2.
Eu implementei o script, mas não vou descrevê-lo aqui. (É muito longo não agrega muito valor, mas pode ser encontrado no repositório do PoP). O script, que é executado ao solicitar uma página interna no servidor de desenvolvimento do site (cuja metodologia escrevi em um artigo anterior sobre service workers), irá gerar o arquivo de mapeamento e armazená-lo no servidor. Eu preparei um exemplo do arquivo de mapeamento gerado. É um arquivo JSON simples, contendo os seguintes atributos:
-
internalMethodCalls
Para cada objeto JavaScript, liste as dependências das funções internas entre si. -
externalMethodCalls
Para cada objeto JavaScript, liste as dependências de funções internas para funções de outros objetos JavaScript. -
publicMethods
Liste todos os métodos registrados e, para cada método, quais objetos JavaScript o implementam. -
methodExecutions
Para cada objeto JavaScript e cada função interna, liste todos os métodos executados por meiopopJSLibraryManager.execute('someMethodName').
Observe que o resultado ainda não é um mapa de dependência de ativo, mas sim um mapa de dependência de objeto JavaScript. A partir desse mapa, podemos estabelecer, sempre que uma função de algum objeto for executada, quais outros objetos também serão necessários. Ainda precisamos configurar quais objetos JavaScript estão contidos em cada ativo, para todos os ativos (no script jTokenizer, os objetos JavaScript são os tokens que procuramos para identificar as chamadas de métodos externos, então essa informação é uma entrada para o script e pode não pode ser obtido dos próprios arquivos de origem). Isso é feito por meio de objetos PHP ResourceLoaderProcessor , como resourceloader-processor.php.
Finalmente, combinando o mapa e a configuração, poderemos calcular todos os ativos necessários para cada rota no aplicativo.
2. Listando todas as rotas de aplicativos
Precisamos identificar todas as rotas disponíveis em nosso aplicativo. Para um site WordPress, esta lista começará com o URL de cada uma das hierarquias de modelos. Os implementados para PoP são estes:
- página inicial: https://getpop.org/en/
- autor: https://getpop.org/en/u/leo/
- único: https://getpop.org/en/blog/new-feature-code-splitting/
- etiqueta: https://getpop.org/en/tags/internet/
- página: https://getpop.org/en/philosophy/
- categoria: https://getpop.org/en/blog/ (a categoria é realmente implementada como uma página, para remover a
category/do caminho da URL) - 404: https://getpop.org/en/this-page-does-not-exist/
Para cada uma dessas hierarquias, devemos obter todas as rotas que produzem uma configuração única (ou seja, que exigirá um conjunto único de ativos). No caso do PoP, temos o seguinte:
- home page e 404 são únicos.
- As páginas de tags sempre têm a mesma configuração para qualquer tag. Assim, um único URL para qualquer tag será suficiente.
- A postagem única depende da combinação do tipo de postagem (como "evento" ou "postagem") e a categoria principal da postagem (como "blog" ou "artigo"). Então, precisamos de um URL para cada uma dessas combinações.
- A configuração de uma página de categoria depende da categoria. Então, precisaremos do URL de cada categoria de postagem.
- Uma página de autor depende do papel do autor (“indivíduo”, “organização” ou “comunidade”). Portanto, precisaremos de URLs para três autores, cada um deles com uma dessas funções.
- Cada página pode ter sua própria configuração (“log in”, “fale conosco”, “nossa missão”, etc.). Portanto, todos os URLs de página devem ser adicionados à lista.
Como podemos ver, a lista já é bastante longa. Além disso, nosso aplicativo pode adicionar parâmetros ao URL que alteram a configuração, possivelmente alterando também quais ativos são necessários. O PoP, por exemplo, oferece a adição dos seguintes parâmetros de URL:
- tab (
?tab=…), para mostrar uma informação relacionada: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors; - format (
?format=…), para alterar como os dados são exibidos: https://getpop.org/en/blog/?format=list; - target (
?target=…), para abrir a página em uma página diferenteSeção: https://getpop.org/en/add-post/?target=addons.
Algumas das rotas iniciais podem ter um, dois ou até três dos parâmetros acima, criando uma ampla gama de combinações:
- postagem única: https://getpop.org/en/blog/new-feature-code-splitting/
- autores de postagem única: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors
- autores de um único post como uma lista: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list
- autores de um único post como uma lista em uma janela modal: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list&target=modals
Em resumo, para PoP, todas as rotas possíveis são uma combinação dos seguintes itens:
- todas as rotas iniciais da hierarquia de templates;
- todos os diferentes valores para os quais a hierarquia produzirá uma configuração diferente;
- todas as abas possíveis para cada hierarquia (hierarquias diferentes podem ter valores de tabulação diferentes: um único post pode ter as abas “autores” e “respostas”, enquanto um autor pode ter as abas “postagens” e “seguidores”);
- todos os formatos possíveis para cada aba (abas diferentes podem ser aplicadas em formatos diferentes: a aba “autores” pode ter o formato “mapa”, mas a aba “respostas” não);
- todos os alvos possíveis indicando as seções da página onde cada rota pode ser exibida (enquanto uma postagem pode ser criada na seção principal ou em uma janela flutuante, a página “Compartilhar com seus amigos” pode ser configurada para abrir em uma janela modal).
Portanto, para uma aplicação um pouco complexa, a produção da lista com todas as rotas não pode ser feita manualmente. Devemos, então, criar um script para extrair essas informações do banco de dados, manipulá-las e, por fim, emiti-las no formato que for necessário. Este script obterá todas as categorias de postagem, a partir das quais podemos produzir a lista de todas as URLs de páginas de categorias diferentes e, em seguida, para cada categoria, consultará o banco de dados para qualquer postagem sob a mesma, o que produzirá a URL de uma única postar em cada categoria, e assim por diante. O script completo está disponível, começando pela function get_resources() , que expõe ganchos a serem implementados por cada um dos casos de hierarquia.
3. Gerando a lista que define quais ativos são necessários para cada rota
Até agora, temos o mapa de dependência de ativos e a lista de todas as rotas no aplicativo. Agora é hora de combinar esses dois e produzir uma lista que indica, para cada rota, quais ativos são necessários.
Para criar esta lista, aplicamos o seguinte procedimento:
- Produza uma lista contendo todos os métodos JavaScript a serem executados para cada rota:
Calcule os módulos da rota, obtenha a configuração para cada módulo, extraia da configuração quais funções JavaScript o módulo precisa executar e adicione todas elas. - Em seguida, percorra o mapa de dependência de ativos para cada função JavaScript, reúna a lista de todas as dependências necessárias e adicione-as todas.
- Por fim, adicione os modelos Handlebars necessários para renderizar cada módulo dentro dessa rota.
Além disso, como dito anteriormente, cada URL tem uma página da web e modos de API, portanto, precisamos executar o procedimento acima duas vezes, uma para cada modo (ou seja, uma vez adicionando o parâmetro output=json ao URL, representando a rota para o modo de API, e uma vez mantendo o URL inalterado para o modo de página da web). Produziremos então duas listas, que terão usos diferentes:

- A lista de modos de página da web será usada ao carregar inicialmente o site, para que os scripts correspondentes a essa rota sejam incluídos na resposta HTML inicial. Esta lista será armazenada no servidor.
- A lista do modo API será usada ao carregar dinamicamente uma página no site. Essa lista será carregada no cliente, para permitir que o aplicativo calcule quais ativos extras devem ser carregados, sob demanda, quando um link for clicado.
A maior parte da lógica foi implementada a partir da function add_resources_from_settingsprocessors($fetching_json, ...) , (você pode encontrá-la no repositório). O parâmetro $fetching_json diferencia entre os modos de página da web ( false ) e API ( true ).
Quando o script para o modo de página da Web for executado, ele produzirá resourceloader-bundle-mapping.json, que é um objeto JSON com as seguintes propriedades:
-
bundle-ids
Esta é uma coleção de até quatro recursos (seus nomes foram desconfigurados para o ambiente de produção:eq=>handlebars,er=>handlebars-helpers, etc.), agrupados sob um ID de pacote. -
bundlegroup-ids
Esta é uma coleção debundle-ids. Cada bundleGroup representa um conjunto exclusivo de recursos. -
key-ids
Este é o mapeamento entre as rotas (representadas por seu hash, que identifica o conjunto de todos os atributos que tornam uma rota única) e seu bundleGroup correspondente.
Como pode ser observado, o mapeamento entre uma rota e seus recursos não é direto. Em vez de mapear key-ids para uma lista de recursos, ele os mapeia para um bundleGroup exclusivo, que é uma lista de bundles e apenas cada bundle é uma lista de resources (de até quatro elementos cada bundle). Por que foi feito assim? Isso serve para dois propósitos:
- Ele nos permite identificar todos os recursos em um bundleGroup exclusivo. Assim, em vez de incluir todos os recursos na resposta HTML, podemos incluir um recurso JavaScript exclusivo, que é o arquivo bundleGroup correspondente, que agrupa todos os recursos correspondentes. Isso é útil ao servir dispositivos que ainda não suportam HTTP/2, e também aumentará o tempo de carregamento, porque Gzip'ar um único arquivo agrupado é mais eficaz do que compactar seus arquivos constituintes por conta própria e depois adicioná-los. Alternativamente, também podemos carregar uma série de bundles em vez de um bundleGroup exclusivo, que é um compromisso entre recursos e bundleGroups (carregar bundles é mais lento do que bundleGroups por causa do Gzip, mas é mais eficiente se a invalidação ocorrer com frequência, para que possamos baixaria apenas o pacote atualizado e não todo o bundleGroup). Os scripts para agrupar todos os recursos em bundles e bundleGroups são encontrados em filegenerator-bundles.php e filegenerator-bundlegroups.php.
- Dividir os conjuntos de recursos em pacotes permite identificar padrões comuns (por exemplo, identificar conjuntos de quatro recursos que são compartilhados entre muitas rotas), consequentemente permitindo que diferentes rotas se conectem ao mesmo pacote. Como resultado, a lista gerada terá um tamanho menor. Isso pode não ser de grande utilidade para a lista de páginas da web, que fica no servidor, mas é ótimo para a lista de APIs, que será carregada no cliente, como veremos mais adiante.
Quando o script para o modo API for executado, ele gerará o arquivo resources.js, com as seguintes propriedades:
-
bundlesebundle-groupsservem ao mesmo propósito declarado para o modo de página da web -
keystambém servem ao mesmo propósito quekey-idspara o modo de página da web. No entanto, em vez de ter um hash como chave para representar a rota, é uma concatenação de todos aqueles atributos que tornam uma rota única — no nosso caso, format (f), tab (t) e target (r). -
sourcesé o arquivo de origem para cada recurso. -
typesé o CSS ou JavaScript para cada recurso (embora, para simplificar, não tenhamos abordado neste artigo que os recursos JavaScript também podem definir recursos CSS como dependências, e os módulos podem carregar seus próprios recursos CSS, implementando a estratégia de carregamento progressivo de CSS ). -
resourcescaptura quais bundleGroups devem ser carregados para cada hierarquia. - order
ordered-load-resourcescontém quais recursos devem ser carregados em ordem, para evitar que os scripts sejam carregados antes de seus scripts dependentes (por padrão, eles são assíncronos).
Vamos explorar como usar este arquivo na próxima seção.
4. Carregando dinamicamente os ativos
Conforme informado, a lista de APIs será carregada no cliente, para que possamos começar a carregar os ativos necessários para uma rota imediatamente após o usuário clicar em um link.
Carregando o script de mapeamento
O arquivo JavaScript gerado com a lista de recursos para todas as rotas no aplicativo não é leve - nesse caso, ele chegou a 85 KB (o que é otimizado, tendo desmembrado os nomes dos recursos e produzido pacotes para identificar padrões comuns entre as rotas) . O tempo de análise não deve ser um grande gargalo, porque analisar JSON é 10 vezes mais rápido do que analisar JavaScript para os mesmos dados. No entanto, o tamanho é um problema de transferência de rede, portanto, devemos carregar esse script de maneira que não afete o tempo de carregamento percebido do aplicativo ou deixe o usuário esperando.
A solução que implementei é fazer o pré-cache desse arquivo usando service workers, carregá-lo usando defer para que ele não bloqueie o thread principal durante a execução dos métodos JavaScript críticos e, em seguida, mostrar uma mensagem de notificação de fallback se o usuário clicar em um link antes que o script seja carregado: “O site ainda está carregando, aguarde alguns instantes para clicar nos links.” Isso é feito adicionando uma div fixa com uma classe de loadingscreen colocada em cima de tudo enquanto os scripts estão carregando, depois adicionando a mensagem de notificação, com uma classe de notificationmsg , dentro da div, e estas poucas linhas de CSS:
.loadingscreen > .notificationmsg { display: none; } .loadingscreen:focus > .notificationmsg, .loadingscreen:active > .notificationmsg { display: block; }Outra solução é dividir este arquivo em vários e carregá-los progressivamente conforme necessário (uma estratégia que já codifiquei). Além disso, o arquivo de 85 KB inclui todas as rotas possíveis no aplicativo, incluindo rotas como “anúncios do autor, mostrados em miniaturas, exibidos na janela de modais”, que podem ser acessados uma vez em uma lua azul, se houver. As rotas mais acessadas são poucas (home page, single, author, tag e todas as páginas, todas sem atributos extras), o que deve produzir um arquivo bem menor, em torno de 30 KB.
Obtendo a rota do URL solicitado
Devemos ser capazes de identificar a rota a partir do URL solicitado. Por exemplo:
-
https://getpop.org/en/u/leo/mapeia para a rota “autor”, -
https://getpop.org/en/u/leo/?tab=followersmapas para a rota “seguidores do autor”, -
https://getpop.org/en/tags/internet/mapeia para a rota “tag”, -
https://getpop.org/en/tags/mapeia para a rota “page/tags/”, - e assim por diante.
Para fazer isso, precisaremos avaliar a URL e deduzir dela os elementos que tornam uma rota única: a hierarquia e todos os atributos (formato, guia e destino). Identificar os atributos não é problema, pois são parâmetros na URL. O único desafio é inferir a hierarquia (home, autor, single, página ou tag) da URL, combinando a URL com vários padrões. Por exemplo,
- Qualquer coisa que comece com
https://getpop.org/en/u/é um autor. - Qualquer coisa que comece com mas não seja exatamente
https://getpop.org/en/tags/é uma tag. Se for exatamentehttps://getpop.org/en/tags/, então é uma página. - E assim por diante.
A função abaixo, implementada a partir da linha 321 do resourceloader.js, deve ser alimentada com uma configuração com os padrões para todas essas hierarquias. Ele primeiro verifica se não há subcaminho na URL — nesse caso, é “home”. Em seguida, ele verifica uma a uma para corresponder às hierarquias de “autor”, “tag” e “único”. Se não tiver sucesso com nenhum deles, então é o caso padrão, que é “page”:
window.popResourceLoader = { // The config will be populated externally, using a config.js file, generated by a script config : {}, getPath : function(url) { var parser = document.createElement('a'); parser.href = url; return parser.pathname; }, getHierarchy : function(url) { var path = this.getPath(url); if (!path) { return 'home'; } var config = this.config; if (path.startsWith(config.paths.author) && path != config.paths.author) { return 'author'; } if (path.startsWith(config.paths.tag) && path != config.paths.tag) { return 'tag'; } // We must also check that this path is, itself, not a potential page (https://getpop.org/en/posts/articles/ is "page", but https://getpop.org/en/posts/this-is-a-post/ is "single") if (config.paths.single.indexOf(path) === -1 && config.paths.single.some(function(single_path) { return path.startsWith(single_path) && path != single_path;})) { return 'single'; } return 'page'; }, ... };Como todos os dados necessários já estão no banco de dados (todas as categorias, todos os slugs de página etc.), executaremos um script para criar esse arquivo de configuração automaticamente em um ambiente de desenvolvimento ou teste. The implemented script is resourceloader-config.php, which produces config.js with the URL patterns for the hierarchies “author”, “tag” and “single”, under the key “paths”:
popResourceLoader.config = { "paths": { "author": "u/", "tag": "tags/", "single": ["posts/articles/", "posts/announcements/", ...] }, ... };Loading Resources for the Route
Once we have identified the route, we can obtain the required assets from the generated JavaScript file under the key “resources”, which looks like this:
config.resources = { "home": { "1": [1, 110, ...], "2": [2, 111, ...], ... }, "author": { "7": [6, 114, ...], "8": [7, 114, ...], ... }, "tag": { "119": [66, 127, ...], "120": [66, 127, ...], ... }, "single": { "posts/": { "7": [190, 142, ...], "3": [190, 142, ...], ... }, "events/": { "7": [213, 389, ...], "3": [213, 389, ...], ... }, ... }, "page": { "log-in/": { "3": [233, 115, ...] }, "log-out/": { "3": [234, 115, ...] }, "add-post/": { "3": [239, 398, ...] }, "posts/": { "120": [268, 127, ...], "122": [268, 127, ...], ... }, ... } };At the first level, we have the hierarchy (home, author, tag, single or page). Hierarchies are divided into two groups: those that have only one set of resources (home, author and tag), and those that have a specific subpath (page permalink for the pages, custom post type or category for the single). Finally, at the last level, for each key ID (which represents a unique combination of the possible values of “format”, “tab” and “target”, stored under “keys”), we have an array of two elements: [JS bundleGroup ID, CSS bundleGroup ID], plus additional bundleGroup IDs if executing progressive booting (JS bundleGroups to be loaded as "async" or "defer" are bundled separately; this will be explained in the optimizations section below).
Please note: For the single hierarchy, we have different configurations depending on the custom post type. This can be reflected in the subpath indicated above (for example, events and posts ) because this information is in the URL (for example, https://getpop.org/en/posts/the-winners-of-climate-change-techno-fixes/ and https://getpop.org/en/events/debate-post-fork/ ), so that, when clicking on a link, we will know the corresponding post type and can thus infer the corresponding route. However, this is not the case with the author hierarchy. As indicated earlier, an author may have three different configurations, depending on the user role ( individual , organization or community ); however, in this file, we've defined only one configuration for the author hierarchy, not three. That is because we are not able to tell from the URL what is the role of the author: user leo (under https://getpop.org/en/u/leo/ ) is an individual, whereas user pop (under https://getpop.org/en/u/pop/ ) is a community; however, their URLs have the same pattern. If we could instead have the URLs https://getpop.org/en/u/individuals/leo/ and https://getpop.org/en/u/communities/pop/ , then we could add a configuration for each user role. However, I've found no way to achieve this in WordPress. As a consequence, only for the API mode, we must merge the three routes (individuals, organizations and communities) into one, which will have all of the resources for the three cases; and clicking on the link for user leo will also load the resources for organizations and communities, even if we don't need them.
Finally, when a URL is requested, we obtain its route, from which we obtain the bundleGroup IDs (for both JavaScript and CSS assets). From each bundleGroup, we find the corresponding bundles under bundlegroups . Then, for each bundle, we obtain all resources under the key bundles . Finally, we identify which assets have not yet been loaded, and we load them by getting their source, which is stored under the key sources . The whole logic is coded starting from line 472 in resourceloader.js.
And with that, we have implemented code-splitting for our application! From now on, we can get better loading times by applying optimizations. Let's tackle that next.
5. Applying Optimizations
The objective is to load as little code as possible, as delayed as possible, and to cache as much of it as possible. Let's explore how to do this.
Splitting Up the Code Into Smaller Units
A single JavaScript asset may implement several functions (by calling popJSLibraryManager.register ), yet maybe only one of those functions is actually needed by the route. Thus, it makes sense to split up the asset into several subassets, implementing a single function on each of them, and extracting all common code from all of the functions into yet another asset, depended upon by all of them.
For instance, in the past, there was a unique file, waypoints.js , that implemented the functions waypointsFetchMore , waypointsTheater and a few more. However, in most cases, only the function waypointsFetchMore was needed, so I was loading the code for the function waypointsTheater unnecessarily. Then, I split up waypoints.js into the following assets:
- waypoints.js, with all common code and implementing no public functions;
- waypoints-fetchmore.js, which implements just the public function
waypointsFetchMore; - waypoints-theater.js, which implements just the public function
waypointsTheater.
Evaluating how to split the files is a manual job. Luckily, there is a tool that greatly eases the task: Chrome Developer Tools' “Coverage” tab, which displays in red those portions of JavaScript code that have not been invoked:
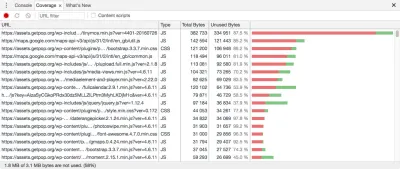
By using this tool, we can better understand how to split our JavaScript files into more granular units, thus reducing the amount of unneeded code that is loaded.
Integration With Service Workers
By precaching all of the resources using service workers, we can be pretty sure that, by the time the response is back from the server, all of the required assets will have been loaded and parsed. I wrote an article on Smashing Magazine on how to accomplish this.
Progressive Booting
PoP's architecture plays very nice with the concept of loading assets in different stages. When defining the JavaScript methods to execute on each module (by doing $this->add_jsmethod($methods, 'calendar') ), these can be set as either critical or non-critical . By default, all methods are set as non-critical, and critical methods must be explicitly defined by the developer, by adding an extra parameter: $this->add_jsmethod($methods, 'calendar', 'critical') . Then, we will be able to load scripts immediately for critical functions, and wait until the page is loaded to load non-critical functions, the JavaScript files of which are loaded using defer .
(function($){ window.popManager = { init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'critical'); ... }); window.addEventListener('load', function() { $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'non-critical'); ... }); }); ... }, ... }; })(jQuery);The gains from progressive booting are major: The JavaScript engine needs not spend time parsing non-critical JavaScript initially, when a quick response to the user is most important, and overall reduces the time to interactive.
Testing And Analizying Performance Gains
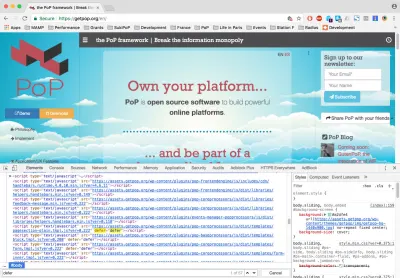
We can use https://getpop.org/en/, a PoP website, for testing purposes. When loading the home page, opening Chrome Developer Tools' “Elements” tab and searching for “defer”, it shows 4 occurrences. Thanks to progressive booting, that is 4 bundleGroup JavaScript files containing the contents of 57 Javascript files with non-critical methods that could wait until the website finished loading to be loaded:
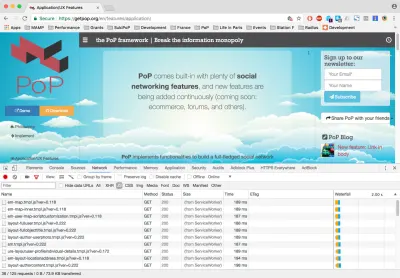
If we now switch to the “Network” tab and click on a link, we can see which assets get loaded. For instance, click on the link “Application/UX Features” on the left side. Filtering by JavaScript, we see it loaded 38 files, including JavaScript libraries and Handlebars templates. Filtering by CSS, we see it loaded 9 files. These 47 files have all been loaded on demand:
Let's check whether the loading time got boosted. We can use WebPagetest to measure the application with and without code-splitting, and calculate the difference.
- Without code-splitting: testing URL, WebPagetest results

- With code-splitting, loading resources: testing URL, WebPagetest Results

- With code-splitting, loading a bundleGroup: testing URL, WebPagetest Results

We can see that when loading the app bundle with all resources or when doing code-splitting and loading resources, there is not so much gain. However, when doing code-splitting and loading a bundleGroup, the gains are significant: 1.7 seconds in loading time, 500 milliseconds to the first meaningful paint, and 1 second to interactive.
Conclusion: Is It Worth It?
You might be thinking, Is it worth it all this trouble? Let's analyze the advantages and disadvantages of implementing our own code-splitting features.
Desvantagens
- Devemos mantê-lo.
Se usássemos apenas o Webpack, poderíamos contar com sua comunidade para manter o software atualizado e poderíamos nos beneficiar de seu ecossistema de plugins. - Os scripts levam tempo para serem executados.
O site do PoP Agenda Urbana possui 304 rotas diferentes, das quais produz 422 conjuntos de recursos exclusivos. Para este site, a execução do script que gera o mapa de dependência de ativos, usando um MacBook Pro de 2012, leva cerca de 8 minutos, e a execução do script que gera as listas com todos os recursos e cria os arquivos bundle e bundleGroup leva cerca de 15 minutos . Isso é mais do que tempo suficiente para ir para um café! - Requer um ambiente de preparação.
Se precisarmos esperar cerca de 25 minutos para executar os scripts, não poderemos executá-lo em produção. Precisaríamos ter um ambiente de teste com exatamente a mesma configuração do sistema de produção. - Código extra é adicionado ao site, apenas para gerenciamento.
Os 85 KB de código não são funcionais por si só, mas simplesmente código para gerenciar outro código. - A complexidade é adicionada.
Isso é inevitável em qualquer caso, se quisermos dividir nossos ativos em unidades menores. O Webpack também adicionaria complexidade ao aplicativo.
Vantagens
- Funciona com WordPress.
O Webpack não funciona com o WordPress pronto para uso e, para fazê-lo funcionar, precisa de algumas soluções alternativas. Esta solução funciona imediatamente para o WordPress (desde que o PoP esteja instalado). - É escalável e extensível.
O tamanho e a complexidade do aplicativo podem crescer sem limites, porque os arquivos JavaScript são carregados sob demanda. - Ele suporta Gutenberg (também conhecido como o WordPress de amanhã).
Por nos permitir carregar frameworks JavaScript sob demanda, ele suportará os blocos de Gutenberg (chamados Gutenblocks), que devem ser codificados no framework escolhido pelo desenvolvedor, com o resultado potencial de diferentes frameworks sendo necessários para a mesma aplicação. - É conveniente.
A ferramenta de construção se encarrega de gerar os arquivos de configuração. Além de esperar, nenhum esforço extra de nossa parte é necessário. - Facilita a otimização.
Atualmente, se um plugin WordPress quiser carregar seletivamente ativos JavaScript, ele usará muitas condicionais para verificar se o ID da página é o correto. Com esta ferramenta, não há necessidade disso; o processo é automático. - O aplicativo será carregado mais rapidamente.
Esta foi a razão pela qual codificamos esta ferramenta. - Requer um ambiente de preparação.
Um efeito colateral positivo é o aumento da confiabilidade: não executaremos os scripts em produção, portanto, não quebraremos nada lá; o processo de implantação não falhará devido a um comportamento inesperado; e o desenvolvedor será forçado a testar o aplicativo usando a mesma configuração da produção. - Ele é personalizado para nossa aplicação.
Não há sobrecarga ou soluções alternativas. O que obtemos é exatamente o que precisamos, com base na arquitetura com a qual estamos trabalhando.
Em conclusão: sim, vale a pena, porque agora podemos aplicar ativos de carga sob demanda em nosso site WordPress e torná-lo mais rápido.
Recursos adicionais
- Webpack, incluindo guia “”Code Splitting”
- “Better Webpack Builds” (vídeo), K. Adam White
Integração do Webpack com WordPress - “Gutenberg e o WordPress do Amanhã”, Morten Rand-Hendriksen, WP Tavern
- “WordPress explora uma abordagem agnóstica de estrutura JavaScript para construir blocos Gutenberg”, Sarah Gooding, WP Tavern