
CNN vs RNN: Diferença entre CNN e RNN
Publicados: 2021-02-25Índice
Introdução
No campo da Inteligência Artificial, as Redes Neurais inspiradas no cérebro humano estão sendo amplamente utilizadas na extração e processamento de informações complexas de vários dados e o uso de Redes Neurais Convolucionais (CNN) e Redes Neurais Recorrentes (RNN) em tais aplicações estão se mostrando úteis.
Neste artigo, vamos entender os conceitos por trás das Redes Neurais Convolucionais e das Redes Neurais Recorrentes, ver suas aplicações e distinguir as diferenças entre os dois tipos populares de Redes Neurais.
Aprenda o treinamento de aprendizado de máquina das melhores universidades do mundo. Ganhe Masters, Executive PGP ou Advanced Certificate Programs para acelerar sua carreira.
Redes neurais e aprendizado profundo
Antes de entrarmos nos conceitos de Redes Neurais Convolucionais e Redes Neurais Recorrentes, vamos entender os conceitos por trás das Redes Neurais e como elas estão ligadas ao Deep Learning.
Nos últimos tempos, Deep Learning já é um conceito amplamente utilizado em muitos campos e, portanto, é um tema quente nos dias de hoje. Mas qual é a razão por trás disso ser tão amplamente falado? Para responder a esta pergunta, vamos aprender sobre o conceito de Redes Neurais.
Em suma, as redes neurais são a espinha dorsal do Deep Learning. Eles são um conjunto de camadas compostas por elementos altamente interconectados conhecidos como neurônios que realizam uma série de transformações nos dados que geram seu próprio entendimento desses dados que nos referimos ao termo, características.

O que são Redes Neurais?
O primeiro conceito que precisamos entender é o de Redes Neurais. Sabemos que o Cérebro Humano é uma das estruturas complexas já estudadas. Devido à sua complexidade tem havido uma enorme dificuldade em desvendar seu funcionamento interno, mas no presente, vários tipos de pesquisas estão sendo realizados para desvendar seus segredos. Este Cérebro Humano serve de inspiração por trás dos modelos de Rede Neural.
Por definição, as Redes Neurais são as unidades funcionais do Deep Learning que utilizam essas Redes Neurais para imitar a atividade cerebral e resolver problemas complexos. Quando os dados de entrada são alimentados na Rede Neural, eles são processados através das camadas do perceptron e, finalmente, fornecem a saída.
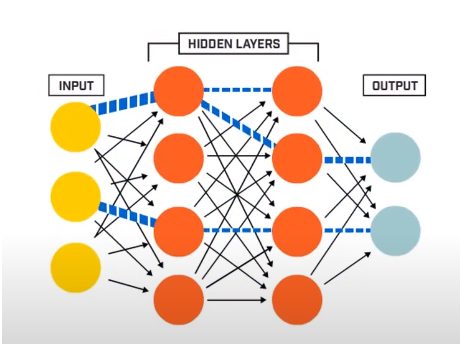
Uma Rede Neural consiste basicamente em 3 camadas –
- Camada de entrada
- Camadas ocultas
- Camada de saída
A camada de entrada lê os dados de entrada que são alimentados no sistema de rede neural para posterior pré-processamento pelas camadas subsequentes de neurônios artificiais. Todas as camadas que existem entre a camada de entrada e a camada de saída são chamadas de camadas ocultas.
É nessas Camadas Ocultas que os neurônios presentes nelas fazem uso de entradas e vieses ponderados e produzem uma saída utilizando as funções de ativação. A camada de saída é a última camada de neurônios que nos dá a saída para um determinado programa.
Fonte
Como funcionam as redes neurais?
Agora que temos uma ideia da estrutura básica das Redes Neurais, vamos avançar e entender como elas funcionam. Para entender seu funcionamento, primeiro temos que aprender sobre uma das estruturas básicas das Redes Neurais, conhecida como Perceptron.
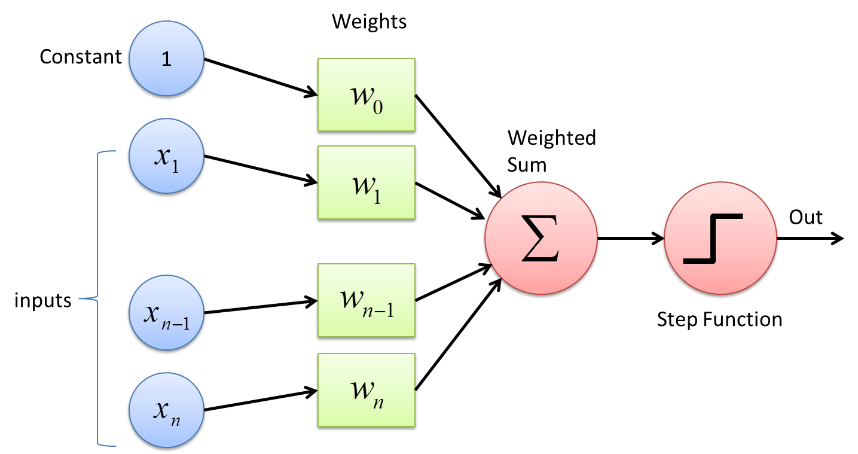
Perceptron é um tipo de rede neural que é a forma mais básica. É uma rede neural artificial simples de alimentação direta com apenas uma camada oculta. Na rede Perceptron, cada neurônio está conectado a todos os outros neurônios na direção direta.
As conexões entre esses neurônios são ponderadas, pelo que a informação que é transferida entre os dois neurônios é reforçada ou atenuada por esses pesos. No processo de treinamento das Redes Neurais, são esses pesos que são ajustados para obter o valor correto.
O Perceptron faz uso de uma função classificadora binária na qual mapeia um vetor de variáveis que são de natureza binária para uma única saída binária. Isso também pode ser usado no Aprendizado Supervisionado. As etapas do Algoritmo de Aprendizagem Perceptron são:
- Multiplique todas as entradas com seus pesos w, onde w são números reais que podem ser inicialmente fixos ou aleatórios.
- Adicione o produto para obter a soma ponderada, ∑ wj xj
- Uma vez que a soma ponderada das entradas é obtida, a Função de Ativação é aplicada para determinar se a soma ponderada é maior que um determinado valor limite ou não, dependendo da função de ativação aplicada. A saída é atribuída como 1 ou 0 dependendo da condição de limite. Aqui o valor “-threshold” também se refere ao termo viés, b.
Desta forma, o algoritmo de Aprendizagem Perceptron pode ser usado para acionar (valor =1) os neurônios presentes nas Redes Neurais que são projetadas e desenvolvidas hoje. Outra representação do Algoritmo de Aprendizagem Perceptron é –
f(x) = 1, se ∑ wj xj + b ≥ 0
0, se ∑ wj xj + b < 0
Embora os Perceptrons não sejam amplamente utilizados hoje em dia, ainda permanecem como um dos conceitos centrais em Redes Neurais. Em pesquisas posteriores, entendeu-se que pequenas mudanças nos pesos ou no viés em até mesmo um perceptron poderiam alterar muito a saída de 1 para 0 ou vice-versa. Esta foi uma grande desvantagem do Perceptron. Assim, foram desenvolvidas funções de ativação mais complexas, como as funções ReLU e Sigmoid, que introduzem apenas mudanças moderadas nos pesos e viés dos neurônios artificiais.
Fonte
Redes Neurais Convolucionais
Uma Rede Neural Convolucional é um Algoritmo de Aprendizado Profundo que toma uma imagem como entrada, atribui vários pesos e vieses a várias partes da imagem, de modo que sejam diferenciáveis umas das outras. Uma vez que eles se tornem diferenciáveis, usando várias funções de ativação, o Modelo de Rede Neural Convolucional pode executar várias tarefas no domínio do Processamento de Imagens, incluindo Reconhecimento de Imagens, Classificação de Imagens, Detecção de Objetos e Faces, etc.
O fundamental de um Modelo de Rede Neural Convolucional é que ele recebe uma imagem de entrada. A imagem de entrada pode ser rotulada (como gato, cachorro, leão, etc.) ou não rotulada. Dependendo disso, os algoritmos de Deep Learning são classificados em dois tipos, a saber, os algoritmos supervisionados, onde as imagens são rotuladas e os algoritmos não supervisionados, onde as imagens não recebem nenhum rótulo específico.
Para a máquina do computador, a imagem de entrada é vista como uma matriz de pixels, mais frequentemente na forma de uma matriz. As imagens são principalmente da forma hxwxd (onde h = Altura, w = Largura, d = Dimensão). Por exemplo, uma imagem de matriz de tamanho 16 x 16 x 3 denota uma imagem RGB (3 representa os valores RGB). Por outro lado, uma imagem de matriz 14 x 14 x 1 representa uma imagem em tons de cinza.
Fonte
Camadas de Rede Neural Convolucional
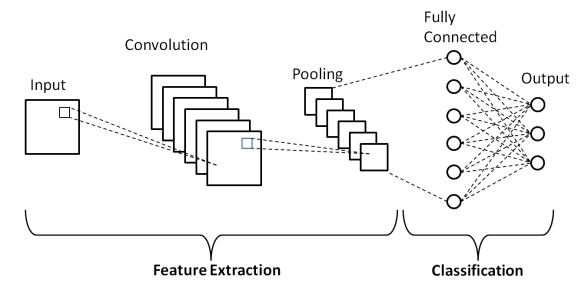
Conforme mostrado na Arquitetura básica acima de uma Rede Neural Convolucional, um Modelo CNN consiste em várias camadas através das quais as imagens de entrada passam por um pré-processamento para obter a saída. Basicamente, essas camadas são diferenciadas em duas partes –

- As três primeiras camadas, incluindo a camada de entrada, a camada de convolução e a camada de pooling, que atua como a ferramenta de extração de recursos para derivar os recursos de nível básico das imagens alimentadas no modelo.
- A camada totalmente conectada final e a camada de saída usam a saída das camadas de extração de recursos e prevê uma classe para a imagem dependendo dos recursos extraídos.
A primeira camada é a Camada de Entrada onde a imagem é alimentada no Modelo de Rede Neural Convolucional na forma de uma matriz de matriz, ou seja, 32 x 32 x 3, onde 3 denota que a imagem é uma imagem RGB com altura e largura iguais de 32 pixels. Em seguida, essas imagens de entrada passam pela Camada Convolucional onde é realizada a operação matemática de Convolução.
A imagem de entrada é convoluída com outra matriz quadrada conhecida como kernel ou filtro. Ao deslizar o kernel um a um sobre os pixels da imagem de entrada, obtemos a imagem de saída conhecida como mapa de recursos, que fornece informações sobre os recursos de nível básico da imagem, como bordas e linhas.
A Camada Convolucional é seguida pela camada Pooling cujo objetivo é reduzir o tamanho do mapa de características para reduzir o custo computacional. Isso é feito por vários tipos de pooling, como Max Pooling, Average Pooling e Sum Pooling.
A Camada Totalmente Conectada (FC) é a penúltima camada do Modelo de Rede Neural Convolucional onde as camadas são achatadas e alimentadas à camada FC. Aqui, usando funções de ativação como as funções Sigmoid, ReLU e tanH, a previsão do rótulo ocorre e é fornecida na camada de saída final .
Onde as CNNs ficam aquém
Com tantas aplicações úteis da Rede Neural Convolucional em dados de imagens visuais, as CNNs têm uma pequena desvantagem, pois não funcionam bem com uma sequência de imagens (vídeos) e falham na interpretação das informações temporais e blocos de texto.
Para lidar com dados temporais ou sequenciais, como as sentenças, precisamos de algoritmos que aprendam com os dados passados e também com os dados futuros na sequência. Felizmente, as Redes Neurais Recorrentes fazem exatamente isso.
Redes Neurais Recorrentes
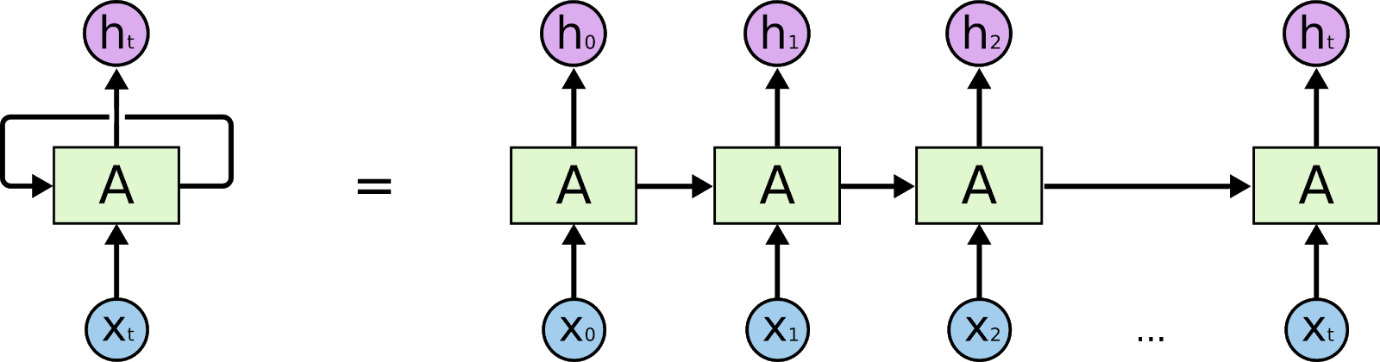
Redes Neurais Recorrentes são redes projetadas para interpretar informações temporais ou sequenciais. As RNNs usam outros pontos de dados em uma sequência para fazer melhores previsões. Eles fazem isso recebendo entrada e reutilizando as ativações de nós anteriores ou nós posteriores na sequência para influenciar a saída.
Fonte
Como resultado de sua memória interna, as redes neurais recorrentes podem lembrar detalhes vitais, como a entrada que receberam, o que as torna muito precisas na previsão do que está por vir. Portanto, eles são o algoritmo mais preferido para dados sequenciais, como séries temporais, fala, texto, áudio, vídeo e muito mais. Redes neurais recorrentes podem formar uma compreensão muito mais profunda de uma sequência e seu contexto em comparação com outros algoritmos.
Como funcionam as redes neurais recorrentes?
A base para entender o funcionamento das redes neurais recorrentes é a mesma das redes neurais convolucionais, as redes neurais simples feed-forward, também conhecidas como Perceptron. Além disso, em redes neurais recorrentes, a saída da etapa anterior é alimentada como uma entrada para a etapa atual. Na maioria das Redes Neurais, a saída geralmente é independente das entradas e vice-versa, essa é a diferença básica entre a RNN e outras Redes Neurais.
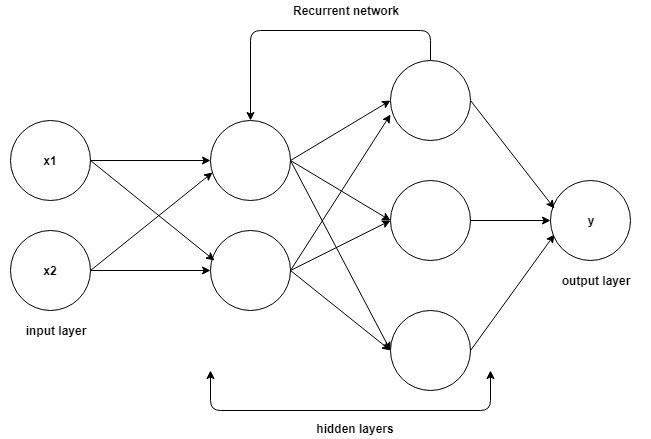
Fonte
Portanto, uma RNN tem duas entradas: o presente e o passado recente. Isso é importante porque a sequência de dados contém informações cruciais sobre o que está por vir, e é por isso que uma RNN pode fazer coisas que outros algoritmos não podem. A principal e mais importante característica das Redes Neurais Recorrentes é o estado Oculto, que lembra algumas informações sobre uma sequência.
As Redes Neurais Recorrentes possuem uma memória que armazena todas as informações sobre o que foi calculado. Usando os mesmos parâmetros para cada entrada e executando a mesma tarefa em todas as entradas ou camadas ocultas, a complexidade dos parâmetros é reduzida.
Diferença entre CNN e RNN
| Redes Neurais Convolucionais | Redes Neurais Recorrentes |
| No aprendizado profundo, uma rede neural convolucional (CNN ou ConvNet) é uma classe de redes neurais profundas, mais comumente aplicada à análise de imagens visuais. | Uma rede neural recorrente (RNN) é uma classe de redes neurais artificiais em que as conexões entre os nós formam um grafo direcionado ao longo de uma sequência temporal. |
| É adequado para dados espaciais como imagens. | RNN é usado para dados temporais, também chamados de dados sequenciais. |
| CNN é um tipo de rede neural artificial feed-forward com variações de perceptrons multicamadas projetadas para usar quantidades mínimas de pré-processamento. | A RNN, ao contrário das redes neurais feed-forward, pode usar sua memória interna para processar sequências arbitrárias de entradas. |
| A CNN é considerada mais poderosa que a RNN. | A RNN inclui menos compatibilidade de recursos quando comparada à CNN. |
| Esta CNN recebe entradas de tamanhos fixos e gera saídas de tamanho fixo. | RNN pode lidar com comprimentos de entrada/saída arbitrários. |
| As CNNs são ideais para processamento de imagens e vídeos. | RNNs são ideais para análise de texto e fala. |
| As aplicações incluem Reconhecimento de Imagens, Classificação de Imagens, Análise de Imagens Médicas, Detecção de Rosto e Visão Computacional. | As aplicações incluem Tradução de Texto, Processamento de Linguagem Natural, Tradução de Linguagem, Análise de Sentimentos e Análise de Fala. |
Conclusão
Assim, neste artigo sobre as diferenças entre os dois tipos mais populares de Redes Neurais, Redes Neurais Convolucionais e Redes Neurais Recorrentes, aprendemos a estrutura básica de uma Rede Neural, juntamente com os fundamentos de CNN e RNN e, finalmente, resumimos um breve comparação entre os dois com suas aplicações no mundo real.
Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o Programa PG Executivo do IIIT-B e do upGrad em Machine Learning e IA , projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT -B Alumni status, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Por que a CNN é mais rápida que a RNN?
As CNNs são mais rápidas que as RNNs porque são projetadas para lidar com imagens, enquanto as RNNs são projetadas para lidar com texto. Embora as RNNs possam ser treinadas para lidar com imagens, ainda é difícil para elas separar recursos contrastantes que estão mais próximos. Como, por exemplo, se você tiver uma foto de um rosto com olhos, nariz e boca, as RNNs terão dificuldade em descobrir qual recurso exibir primeiro. As CNNs usam uma grade de pontos e, usando um algoritmo, podem ser treinadas para reconhecer formas e padrões. CNNs são melhores que RNNs na classificação de imagens; eles são mais rápidos do que RNNs porque são simples de calcular e são melhores na classificação de imagens.
Para que serve o RNN?
Redes neurais recorrentes (RNNs) são uma classe de redes neurais artificiais onde as conexões entre as unidades formam um ciclo direcionado. A saída de uma unidade torna-se a entrada de outra unidade e assim por diante, assim como a saída de um neurônio torna-se a entrada de outro. As RNNs têm sido usadas com sucesso para realizar tarefas complexas, como reconhecimento de fala e tradução automática, que são difíceis de realizar com métodos padrão.
O que é RNN e como é diferente das Redes Neurais Feedforward?
As Redes Neurais Recorrentes (RNNs) são um tipo de Redes Neurais que são usadas para processar dados sequenciais. Uma rede neural recorrente consiste em uma camada de entrada, uma ou mais camadas ocultas e uma camada de saída. As camadas ocultas são projetadas para aprender representações internas dos dados de entrada, que são então apresentadas à camada de saída como uma representação externa. O RNN é treinado com a ajuda de retropropagação. As RNNs são frequentemente comparadas com as redes neurais feedforward (FNNs). Enquanto RNNs e FNNs podem aprender representações internas de dados, RNNs são capazes de aprender dependências de longo prazo, das quais FNNs não são capazes.