
Escolhendo uma nova tecnologia de banco de dados sem servidor em uma agência (estudo de caso)
Publicados: 2022-03-10Este artigo foi gentilmente apoiado por nossos queridos amigos da Fauna, que tornam o trabalho com dados operacionais produtivo, escalável e seguro para todas as equipes de desenvolvimento de software. Obrigado!

Adotar uma nova tecnologia é uma das decisões mais difíceis para um tecnólogo em uma função de liderança. Geralmente, essa é uma área de risco grande e desconfortável, quer você esteja criando software para outra organização ou dentro da sua própria.
Nos últimos doze anos como engenheiro de software, encontrei-me na posição de ter que avaliar uma nova tecnologia com frequência cada vez maior. Este pode ser o próximo framework frontend, uma nova linguagem ou até mesmo arquiteturas totalmente novas, como serverless.
A fase de experimentação é muitas vezes divertida e emocionante. É onde os engenheiros de software estão mais à vontade, abraçando a novidade e a euforia dos momentos “aha” enquanto grokking novos conceitos. Como engenheiros, gostamos de pensar e mexer, mas com experiência suficiente, todo engenheiro aprende que mesmo a tecnologia mais incrível tem seus defeitos. Você só não os encontrou ainda.
Agora, como cofundador de uma agência criativa, minha equipe e eu geralmente estamos em uma posição única para usar novas tecnologias. Vemos muitos projetos greenfield, que se tornam a oportunidade perfeita para introduzir algo novo. Esses projetos também apresentam um nível de isolamento técnico da organização maior e geralmente são menos sobrecarregados por decisões anteriores.
Dito isto, um bom líder de agência é encarregado de cuidar da grande ideia de outra pessoa e entregá-la ao mundo. Temos que tratá-lo com ainda mais cuidado do que com nossos próprios projetos. Sempre que estou prestes a dar a última palavra em uma nova tecnologia, costumo ponderar sobre essa sabedoria do cofundador do Stack Overflow, Joel Spolski:
“Você tem que suar e sangrar com a coisa por um ano ou dois antes de realmente saber que é bom o suficiente ou perceber que não importa o quanto você tente, você não pode...”
Este é o medo, este é o lugar em que nenhum líder de tecnologia quer se encontrar. Escolher uma nova tecnologia para um projeto do mundo real é difícil o suficiente, mas como agência, você precisa tomar essas decisões com o projeto de outra pessoa, alguém o sonho de outra pessoa, o dinheiro de outra pessoa. Em uma agência, a última coisa que você quer é encontrar uma dessas manchas perto do prazo de um projeto. Cronogramas e orçamentos apertados tornam quase impossível reverter o curso depois que um certo limite é ultrapassado, portanto, descobrir que uma tecnologia não pode fazer algo crítico ou não é confiável tarde demais em um projeto pode ser catastrófico.
Ao longo da minha carreira como engenheiro de software, trabalhei em empresas SaaS e agências criativas. Quando se trata de adotar uma nova tecnologia para um projeto esses dois ambientes possuem critérios bem diferentes. Há sobreposição de critérios, mas, em geral, o ambiente da agência precisa trabalhar com orçamentos rígidos e restrições de tempo rigorosas . Embora queiramos que os produtos que construímos envelheçam bem ao longo do tempo, muitas vezes é mais difícil fazer investimentos em algo menos comprovado ou adotar tecnologia com curvas de aprendizado mais acentuadas e arestas.
Dito isto, as agências também têm algumas restrições únicas que uma única organização pode não ter. Temos de influenciar a eficiência e a estabilidade. A hora faturável geralmente é a unidade de medida final quando um projeto é concluído. Estive em empresas de SaaS onde gastar um ou dois dias na configuração ou em um pipeline de construção não é grande coisa.
Em uma agência, esse tipo de custo de tempo sobrecarrega os relacionamentos, pois as equipes financeiras veem margens de lucro estreitas para resultados pouco visíveis. Também temos que considerar a manutenção a longo prazo de um projeto e, inversamente, o que acontece se um projeto precisar ser devolvido ao cliente. Portanto, devemos buscar eficiência, curva de aprendizado e estabilidade na tecnologia que escolhemos.
Ao avaliar uma nova tecnologia, observo três áreas abrangentes:
- A tecnologia
- A experiência do desenvolvedor
- O negócio
Cada uma dessas áreas tem um conjunto de critérios que eu gosto de atender antes de realmente começar a mergulhar no código e experimentar. Neste artigo, examinaremos esses critérios e usaremos o exemplo de considerar um novo banco de dados para um projeto e revisá-lo em alto nível sob cada lente. Tomar uma decisão tangível como essa ajudará a demonstrar como podemos aplicar essa estrutura no mundo real.
A tecnologia
A primeira coisa a ser observada ao avaliar uma nova tecnologia é se essa solução pode resolver os problemas que ela afirma resolver. Antes de mergulhar em como uma tecnologia pode ajudar nossos processos e operações comerciais, é importante primeiro estabelecer que ela está atendendo aos nossos requisitos funcionais . Também é aqui que gosto de dar uma olhada nas soluções existentes que estamos usando e como essa nova se compara a elas.
Vou me fazer perguntas como:
- No mínimo, resolve o problema que minha solução existente resolve?
- De que forma esta solução é melhor?
- Em que aspectos é pior?
- Para as áreas em que é pior, o que será necessário para superar essas deficiências?
- Será que vai tomar o lugar de várias ferramentas?
- Quão estável é a tecnologia?
Nosso Por quê?
Neste ponto, também quero rever por que estamos buscando outra solução. Uma resposta simples é que estamos enfrentando um problema que as soluções existentes não resolvem . No entanto, isso raramente é o caso. Resolvemos muitos problemas de software ao longo dos anos com toda a tecnologia que temos hoje. O que normalmente acontece é que nos transformamos em uma nova tecnologia que torna algo que estamos fazendo atualmente mais fácil, mais estável, mais rápido ou mais barato.
Vamos usar o React como exemplo. Por que decidimos adotar o React quando jQuery ou Vanilla JavaScript estavam fazendo o trabalho? Nesse caso, o uso do framework destacou como essa era uma maneira muito melhor de lidar com frontends com estado. Tornou-se mais rápido para nós construir coisas como filtragem e classificação de recursos trabalhando com estruturas de dados em vez de manipulação direta do DOM. Esta foi uma economia de tempo e maior estabilidade de nossas soluções.
O Typescript é outro exemplo em que decidimos adotá-lo porque encontramos aumentos na estabilidade e manutenção do nosso código. Com a adoção de novas tecnologias, muitas vezes não há um problema claro que estamos procurando resolver, mas apenas procurando permanecer atualizados e descobrir soluções mais eficientes e estáveis do que estamos usando atualmente.
No caso de um banco de dados, estávamos pensando especificamente em mudar para uma opção sem servidor . Tivemos muito sucesso com aplicativos e implantações sem servidor, reduzindo nossa sobrecarga como organização. Uma área em que sentimos que isso estava faltando era nossa camada de dados. Vimos serviços como Amazon Aurora, Fauna, Cosmos e Firebase que estavam aplicando princípios serverless a bancos de dados e queríamos ver se era hora de darmos o salto nós mesmos. Nesse caso, estávamos procurando reduzir nossa sobrecarga operacional e aumentar nossa velocidade e eficiência de desenvolvimento.
Nesse nível, é importante entender o porquê antes de começar a mergulhar em novas ofertas. Isso pode ser porque você está resolvendo um problema novo, mas com muito mais frequência você está procurando melhorar sua capacidade de resolver um tipo de problema que já está resolvendo. Nesse caso, você precisa fazer um inventário de onde esteve para descobrir o que proporcionaria uma melhoria significativa ao seu fluxo de trabalho. Com base em nosso exemplo de análise de bancos de dados sem servidor, precisaremos dar uma olhada em como estamos resolvendo problemas atualmente e onde essas soluções são insuficientes.
Onde estivemos…
Como agência, usamos anteriormente uma ampla variedade de bancos de dados, incluindo, entre outros, MySQL, PostgreSQL, MongoDB, DynamoDB, BigQuery e Firebase Cloud Storage. A grande maioria do nosso trabalho se concentrou em três bancos de dados principais: PostgreSQL, MongoDB e Firebase Realtime Database. Cada um deles, de fato, tem ofertas semi-servidor, mas alguns recursos-chave de ofertas mais recentes nos fizeram reavaliar nossas suposições anteriores. Vamos dar uma olhada em nossa experiência histórica com cada um deles primeiro e por que ficamos considerando alternativas em primeiro lugar.
Normalmente, escolhemos o PostgreSQL para projetos maiores e de longo prazo, pois esse é o padrão ouro testado em batalha para quase tudo. Ele suporta transações clássicas, dados normalizados e é compatível com ACID. Há uma variedade de ferramentas e ORMs disponíveis em quase todos os idiomas e pode até ser usado como um banco de dados NoSQL ad-hoc com suporte a colunas JSON. Ele se integra bem com muitas estruturas, bibliotecas e linguagens de programação existentes, tornando-o um verdadeiro cavalo de batalha para qualquer lugar. Também é de código aberto e, portanto, não nos prende a nenhum fornecedor. Como se costuma dizer, ninguém nunca foi demitido por escolher o Postgres.
Dito isto, gradualmente nos encontramos usando o PostgreSQL cada vez menos à medida que nos tornamos mais uma loja orientada a Node. Descobrimos que os ORMs para Node são medíocres e exigem mais consultas personalizadas (embora isso tenha se tornado menos problemático agora) e o NoSQL parece ser um ajuste mais natural ao trabalhar em um tempo de execução JavaScript ou TypeScript. Dito isso, muitas vezes tínhamos projetos que podiam ser feitos rapidamente com modelagem relacional clássica, como fluxos de trabalho de comércio eletrônico. No entanto, lidar com a configuração local do banco de dados, unificar o fluxo de testes entre as equipes e lidar com migrações locais eram coisas que não amávamos e ficamos felizes em deixar para trás, pois os bancos de dados baseados em nuvem NoSQL se tornaram mais populares.
O MongoDB foi cada vez mais nosso banco de dados preferido, pois adotamos o Node.js como nosso back-end preferido. Trabalhar com o MongoDB Atlas facilitou o desenvolvimento rápido e bancos de dados de teste que nossa equipe poderia usar. Por um tempo, o MongoDB não era compatível com ACID, não suportava transações e desencorajava muitas operações do tipo junção interna, portanto, para aplicativos de comércio eletrônico ainda usávamos o Postgres com mais frequência. Dito isto, há uma variedade de bibliotecas que o acompanham e a linguagem de consulta do Mongo e o suporte JSON de primeira classe nos deram velocidade e eficiência que não tínhamos experimentado com bancos de dados relacionais. O MongoDB adicionou suporte para transações ACID recentemente, mas por muito tempo, essa foi a principal razão pela qual optamos pelo Postgres.
O MongoDB também nos apresentou um novo nível de flexibilidade. No meio de um projeto de agência, os requisitos são obrigados a mudar. Não importa o quanto você se defenda, sempre há um requisito de dados de última hora . Com bancos de dados NoSQL, em geral, a flexibilidade da estrutura de dados tornou esses tipos de mudanças menos severas. Não acabamos com uma pasta cheia de arquivos de migração para gerenciar as colunas adicionadas, removidas e adicionadas novamente antes que um projeto sequer visse a luz do dia.
Como serviço, o Mongo Atlas também estava bem próximo do que desejávamos em um serviço de banco de dados em nuvem. Eu gosto de pensar no Atlas como uma oferta semi -servidor, já que você ainda tem alguma sobrecarga operacional ao gerenciá-lo. Você precisa provisionar um banco de dados de determinado tamanho e selecionar uma quantidade de memória antecipadamente. Essas coisas não serão dimensionadas automaticamente para você, portanto, você precisará monitorá-las para quando for a hora de fornecer mais espaço ou memória. Em um banco de dados verdadeiramente sem servidor, tudo isso aconteceria automaticamente e sob demanda.
Também utilizamos o Firebase Realtime Database para alguns projetos. De fato, essa era uma oferta sem servidor em que o banco de dados aumenta e diminui sob demanda e, com preços pagos conforme o uso , fazia sentido para aplicativos em que a escala não era conhecida antecipadamente e o orçamento era limitado. Usamos isso em vez do MongoDB para projetos de curta duração que tinham requisitos de dados simples.
Uma coisa que não gostamos no Firebase foi que ele parecia estar mais longe do modelo relacional típico construído em torno de dados normalizados aos quais estávamos acostumados. Manter as estruturas de dados planas significava que muitas vezes tínhamos mais duplicações, o que poderia se tornar um pouco feio à medida que um projeto cresce. Você acaba tendo que atualizar os mesmos dados em vários lugares ou tentar juntar diferentes referências, resultando em várias consultas que podem se tornar difíceis de raciocinar no código. Embora gostássemos do Firebase, nunca nos apaixonamos pela linguagem de consulta e, às vezes, achamos a documentação medíocre.
Em geral, tanto o MongoDB quanto o Firebase tinham um foco semelhante em dados desnormalizados e, sem acesso a transações eficientes, muitas vezes encontramos muitos dos fluxos de trabalho fáceis de modelar em bancos de dados relacionais, o que levou a códigos mais complexos na camada do aplicativo com suas Contrapartes NoSQL. Se pudéssemos obter a flexibilidade e a facilidade dessas ofertas NoSQL com a robustez e a modelagem relacional de um banco de dados SQL tradicional, teríamos encontrado uma ótima combinação. Sentimos que o MongoDB tinha a melhor API e recursos, mas o Firebase tinha o modelo verdadeiramente sem servidor operacionalmente.
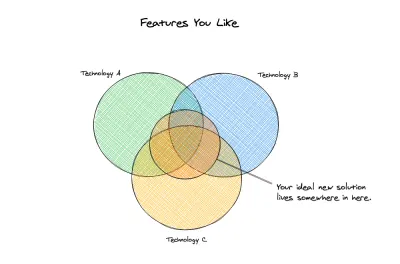
Nosso Ideal
Neste ponto, podemos começar a analisar quais novas opções consideraremos. Definimos claramente nossas soluções anteriores e identificamos as coisas que são importantes para nós termos no mínimo em nossa nova solução. Não temos apenas uma linha de base ou um conjunto mínimo de requisitos, mas também um conjunto de problemas que gostaríamos que a nova solução aliviasse para nós. Aqui estão os requisitos técnicos que temos:
- Sem servidor operacionalmente com escala sob demanda
- Modelagem flexível (sem esquema)
- Sem dependência de migrações ou ORMs
- Transações compatíveis com ACID
- Suporta relacionamentos e dados normalizados
- Funciona com back-ends sem servidor e tradicionais
Então, agora que temos uma lista de itens obrigatórios, podemos avaliar algumas opções. Pode não ser importante que a nova solução prenda todos os alvos aqui. Pode ser que ele atinja a combinação certa de recursos onde as soluções existentes não estão se sobrepondo. Por exemplo, se você quisesse flexibilidade sem esquema , teria que desistir das transações ACID. (Este foi o caso por muito tempo com bancos de dados.)
Um exemplo de outro domínio é se você quiser ter validação de typescript em sua renderização de modelo, você precisa usar TSX e React. Se você optar por opções como Svelte ou Vue, poderá ter isso - parcialmente, mas não completamente - por meio da renderização do modelo . Portanto, uma solução que forneceu o tamanho reduzido e a velocidade do Svelte com a verificação de tipo de nível de modelo de React e TypeScript pode ser suficiente para adoção, mesmo que esteja faltando outro recurso. O equilíbrio entre desejos e necessidades vai mudar de projeto para projeto. Cabe a você descobrir onde será o valor e decidir como marcar os pontos mais importantes em sua análise.
Agora podemos dar uma olhada em uma solução e ver como ela é avaliada em relação à nossa solução desejada. Fauna é uma solução de banco de dados sem servidor que possui uma escala sob demanda com distribuição global. É um banco de dados sem esquema, que fornece transações compatíveis com ACID e suporta consultas relacionais e dados normalizados como um recurso. O Fauna pode ser usado tanto em aplicativos serverless quanto em backends mais tradicionais e fornece bibliotecas para trabalhar com as linguagens mais populares. Além disso, o Fauna fornece fluxos de trabalho para autenticação, bem como multilocação fácil e eficiente. Esses são recursos adicionais sólidos a serem observados, pois podem ser os fatores de oscilação quando duas tecnologias estão frente a frente em nossa avaliação.
Agora, depois de analisar todos esses pontos fortes, temos que avaliar os pontos fracos . Um dos quais é Fauna não é de código aberto. Isso significa que há riscos de aprisionamento do fornecedor ou alterações de negócios e preços que estão fora de seu controle. O código aberto pode ser bom porque muitas vezes você pode levar a tecnologia para outro fornecedor, se quiser ou contribuir potencialmente para o projeto.
No mundo das agências, o aprisionamento do fornecedor é algo que devemos observar de perto, não tanto por causa do preço, mas a viabilidade do negócio subjacente é importante. Ter que mudar bancos de dados em um projeto que está no meio do desenvolvimento ou há alguns anos é desastroso para uma agência. Muitas vezes um cliente terá que pagar a conta por isso, o que não é uma conversa agradável de se ter.
Uma outra fraqueza com a qual estávamos preocupados é o foco no JAMstack . Embora gostemos do JAMstack, nos encontramos construindo uma ampla variedade de aplicativos da Web tradicionais com mais frequência. Queremos ter certeza de que a Fauna continua a dar suporte a esses casos de uso. Tivemos uma experiência ruim no passado com um provedor de hospedagem que foi all-in no JAMstack e acabamos tendo que migrar uma faixa bastante grande de sites do serviço, então queremos ter certeza de que todos os casos de uso continuarão a ver suporte sólido. No momento, esse parece ser o caso, e os fluxos de trabalho sem servidor fornecidos pela Fauna podem complementar um aplicativo mais tradicional muito bem.

Neste ponto, fizemos nossa pesquisa funcional e a única maneira de saber se essa solução é viável é descer e escrever algum código. Em um ambiente de agência, não podemos simplesmente tirar semanas do cronograma para que as pessoas avaliem várias soluções. Essa é a natureza de trabalhar em uma agência versus um ambiente SaaS . Neste último, você pode construir alguns protótipos para tentar chegar à solução certa. Em uma agência, você terá alguns dias para experimentar, ou talvez a oportunidade de fazer um projeto paralelo, mas em geral temos que reduzir isso a uma ou duas tecnologias neste estágio e depois colocar os dedos no teclado.
A experiência do desenvolvedor
Julgar o lado da experiência de uma nova tecnologia é talvez a mais difícil das três áreas, pois é por natureza subjetiva. Também terá variabilidade de equipe para equipe. Por exemplo, se você perguntar a um programador Ruby, um programador Python e um programador Rust sobre suas opiniões sobre diferentes recursos de linguagem, você obterá uma grande variedade de respostas. Portanto, antes de começar a julgar uma experiência, você deve primeiro decidir quais características são mais importantes para sua equipe em geral.

Para as agências, acho que existem dois grandes gargalos que surgem em relação à experiência do desenvolvedor:
- Tempo de instalação e configuração
- Aprendizagem
Ambos afetam a viabilidade a longo prazo de uma nova tecnologia de maneiras diferentes. Manter equipes temporárias de desenvolvedores sincronizadas em uma agência pode ser uma dor de cabeça. Ferramentas que têm muitos custos iniciais de configuração e configurações são notoriamente difíceis para as agências trabalharem. A outra é a capacidade de aprendizado e como é fácil para os desenvolvedores desenvolverem a nova tecnologia. Abordaremos isso com mais detalhes e por que eles são minha base ao começar a avaliar a experiência do desenvolvedor.
Tempo de instalação e configuração
As agências tendem a ter pouca paciência e tempo para configuração. Para mim, adoro ferramentas afiadas, com designs ergonômicos, que me permitem trabalhar rapidamente no problema de negócios em questão. Alguns anos atrás, trabalhei para uma empresa de SaaS que tinha uma configuração local complexa que envolvia muitas configurações e muitas vezes falhava em pontos aleatórios no processo de configuração. Uma vez configurado, a sabedoria convencional era não tocar em nada e esperar que você não estivesse na empresa tempo suficiente para ter que configurá-lo novamente em outra máquina. Eu conheci desenvolvedores que gostaram muito de configurar cada pedacinho de sua configuração do emacs e não pensaram em perder algumas horas para um ambiente local quebrado.
Em geral, descobri que os engenheiros de agência desprezam esse tipo de coisa em seu trabalho diário. Enquanto estão em casa, eles podem mexer com esses tipos de ferramentas, mas quando há um prazo não há nada como ferramentas que simplesmente funcionam. Nas agências, normalmente preferimos aprender algumas coisas novas que funcionam bem, de forma consistente, em vez de poder configurar cada peça de tecnologia de acordo com o gosto pessoal de cada indivíduo.
Uma coisa boa de trabalhar com uma plataforma de nuvem que não é de código aberto é que eles possuem a configuração e a configuração inteiramente. Embora uma desvantagem disso seja o aprisionamento do fornecedor, a vantagem é que esses tipos de ferramentas geralmente fazem o que são configurados para fazer bem. Não há ajustes nos ambientes, configurações locais e pipelines de implantação. Também temos menos decisões a tomar.
Isso é inerentemente o apelo do serverless . Serverless em geral tem uma maior dependência de serviços e ferramentas proprietárias. Trocamos a flexibilidade de hospedagem e código fonte para que possamos ganhar maior estabilidade e focar nos problemas do domínio do negócio que estamos tentando resolver. Também observarei que quando estou avaliando uma tecnologia e tenho a sensação de que a migração de uma plataforma pode ser necessária, isso geralmente é um mau sinal no início.
No caso de bancos de dados, a configuração configurar e esquecer é ideal ao trabalhar com clientes em que as necessidades do banco de dados podem ser ambíguas. Tivemos clientes que não tinham certeza de quão popular seria um programa ou aplicativo. Tivemos clientes que tecnicamente não fomos contratados para oferecer suporte dessa maneira, mas mesmo assim nos ligaram em pânico quando precisavam de nós para dimensionar seu banco de dados ou aplicativo.
No passado, sempre tínhamos que levar em consideração coisas como redundância, replicação de dados e fragmentação para dimensionar quando criamos nossas SOWs. Tentar cobrir cada cenário e ao mesmo tempo estar preparado para mover um livro completo de negócios no caso de um banco de dados não ser dimensionado é uma situação impossível de se preparar. No final, um banco de dados sem servidor facilita essas coisas.
Você nunca perde dados , não precisa se preocupar em replicar dados em uma rede, nem provisionar um banco de dados e uma máquina maiores para executá-los – tudo simplesmente funciona. Nós nos concentramos apenas no problema de negócios em questão, a arquitetura técnica e a escala sempre serão gerenciadas. Para nossa equipe de desenvolvimento, esta é uma grande vitória; temos menos simulações de incêndio, monitoramento e troca de contexto.
Aprendizagem
Existe uma medida clássica de experiência do usuário, que acho aplicável à experiência do desenvolvedor, que é a capacidade de aprendizado . Ao projetar para uma determinada experiência do usuário, não olhamos apenas se algo é aparente ou fácil na primeira tentativa. A tecnologia só tem mais complexidade do que isso na maioria das vezes. O importante é a facilidade com que um novo usuário pode aprender e dominar o sistema.
Quando se trata de ferramentas técnicas, especialmente as poderosas, seria pedir muito que houvesse zero curva de aprendizado . Normalmente, o que procuramos é que haja uma ótima documentação para os casos de uso mais comuns e que esse conhecimento seja fácil e rapidamente construído em um projeto. Perder um pouco de tempo para aprender no primeiro projeto com uma tecnologia é normal. Depois disso, devemos ver a eficiência melhorar a cada projeto sucessivo.
O que procuro especificamente aqui é como podemos aproveitar o conhecimento e os padrões que já conhecemos para ajudar a encurtar a curva de aprendizado. Por exemplo, com bancos de dados sem servidor, haverá praticamente zero curva de aprendizado para configurá-los na nuvem e implantá-los. Quando se trata de usar o banco de dados, uma das coisas que eu gosto é quando ainda podemos aproveitar todos os anos de domínio de bancos de dados relacionais e aplicar esses aprendizados à nossa nova configuração. Nesse caso, estamos aprendendo a usar uma nova ferramenta, mas isso não está nos forçando a repensar nossa modelagem de dados desde o início.

Como exemplo disso, ao usar Firebase, MongoDB e DynamoDB, descobrimos que ele encorajou dados desnormalizados em vez de tentar juntar documentos diferentes. Isso criou muito atrito cognitivo ao modelar nossos dados, pois precisávamos pensar em termos de padrões de acesso em vez de entidades de negócios. Do outro lado dessa Fauna nos permitiu alavancar nossos anos de conhecimento relacional, bem como nossa preferência por dados normalizados quando se trata de modelagem de dados.
A parte com a qual tivemos que nos acostumar foi usar índices e uma nova linguagem de consulta para reunir essas peças. Em geral, descobri que preservar conceitos que fazem parte de paradigmas de design de software maiores torna mais fácil para a equipe de desenvolvimento em termos de capacidade de aprendizado e adoção.
Como sabemos que uma equipe está adotando e adorando uma nova tecnologia? Acho que o melhor sinal é quando nos perguntamos se essa ferramenta se integra com a dita nova tecnologia. Quando uma nova tecnologia chega a um nível de desejo e prazer que a equipe está procurando maneiras de incorporá-la em mais projetos, isso é um bom sinal de que você tem um vencedor.
O negócio
Nesta seção, temos que ver como uma nova tecnologia atende às nossas necessidades de negócios . Estes incluem perguntas como:
- Com que facilidade pode ser precificado e integrado aos nossos planos de suporte?
- Podemos fazer a transição para os clientes facilmente?
- Os clientes podem ser integrados a essa ferramenta, se necessário?
- Quanto tempo esta ferramenta realmente economiza, se houver?
A ascensão do serverless como paradigma se encaixa bem nas agências. Quando falamos em banco de dados e DevOps, a necessidade de especialistas nessas áreas nas agências é limitada. Muitas vezes, estamos entregando um projeto quando terminamos ou apoiando-o em uma capacidade limitada a longo prazo. Nós tendemos a favorecer os engenheiros full-stack, pois essas necessidades superam as necessidades de DevOps por uma grande margem. Se contratássemos um engenheiro de DevOps, eles provavelmente passariam algumas horas implantando um projeto e muito mais horas esperando por um incêndio.
Nesse sentido, sempre temos alguns contratados de DevOps prontos, mas não temos funcionários para esses cargos em tempo integral. Isso significa que não podemos contar com um engenheiro de DevOps para estar pronto para resolver um problema inesperado. Para nós, sabemos que podemos obter melhores taxas de hospedagem indo diretamente para a AWS, mas também sabemos que, usando o Heroku, podemos contar com nossa equipe existente para depurar a maioria dos problemas. A menos que tenhamos um cliente, precisamos oferecer suporte a longo prazo com necessidades específicas de back-end, gostamos de usar como padrão as plataformas gerenciadas como serviço.
Os bancos de dados não são exceção. Adoramos contar com serviços como Mongo Atlas ou Heroku Postgres para tornar esse processo o mais fácil possível. À medida que começamos a ver cada vez mais nossa pilha em ferramentas sem servidor como Vercel, Netlify ou AWS Lambda – nossas necessidades de banco de dados tiveram que evoluir com isso. Bancos de dados sem servidor , como Firebase, DynamoDB e Fauna, são ótimos porque se integram bem a aplicativos sem servidor, mas também liberam nossos negócios completamente de provisionamento e dimensionamento.
Essas soluções também funcionam bem para aplicativos mais tradicionais, onde não temos um aplicativo sem servidor, mas ainda podemos aproveitar as eficiências sem servidor no nível do banco de dados. Como empresa, é mais produtivo aprendermos um único banco de dados que pode ser aplicado a ambos os mundos do que mudar de contexto. Isso é semelhante à nossa decisão de adotar Node e JavaScript isomórfico (e TypeScript).
Uma das desvantagens que encontramos com o serverless foi a definição de preços para os clientes para os quais gerenciamos esses serviços. Em uma arquitetura mais tradicional, os níveis de taxa fixa tornam muito fácil convertê-los em uma taxa para clientes com circunstâncias previsíveis para incorrer em aumentos e excedentes. Quando se trata de serverless, isso pode ser ambíguo. O pessoal de finanças normalmente não gosta de ouvir coisas como cobramos 1/10 de centavo por cada leitura além de 1 milhão, e assim por diante.
Isso é difícil de traduzir em um número fixo, mesmo para engenheiros, pois muitas vezes estamos construindo aplicativos que não temos certeza de qual será o uso . Muitas vezes temos que criar camadas, mas as muitas variáveis que entram no cálculo de custo de um lambda podem ser difíceis de entender. Em última análise, para um produto SaaS, esses modelos de precificação de pagamento conforme o uso são ótimos, mas para agências, os contadores gostam de números mais concretos e previsíveis.
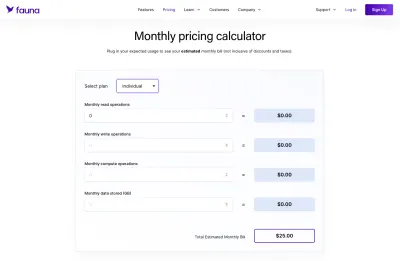
Quando se tratava de Fauna, isso era definitivamente mais ambíguo de descobrir do que dizer um banco de dados MySQL padrão que tinha hospedagem de taxa fixa por uma quantidade definida de espaço. A vantagem foi que a Fauna fornece uma boa calculadora que pudemos usar para montar nossos próprios esquemas de preços.
Outro aspecto difícil do serverless pode ser que muitos desses provedores não permitem o detalhamento fácil de cada aplicativo hospedado. Por exemplo, a plataforma Heroku facilita isso criando novos pipelines e equipes. Podemos até inserir o cartão de crédito de um cliente para eles caso não queiram usar nossos planos de hospedagem. Isso também pode ser feito no mesmo painel, para que não precisemos criar vários logins.
Quando se tratava de outras ferramentas sem servidor, isso era muito mais difícil. Ao avaliar bancos de dados sem servidor, o Firebase oferece suporte à divisão de pagamentos por projeto . No caso do Fauna ou DynamoDB, isso não é possível, então temos que fazer algum trabalho para monitorar o uso em seu painel e, se o cliente quiser sair do nosso serviço, teríamos que transferir o banco de dados para sua própria conta.
Em última análise, as ferramentas sem servidor oferecem ótimas oportunidades de negócios em termos de economia de custos, gerenciamento e eficiência de processos. No entanto, muitas vezes eles são desafiadores para as agências quando se trata de preços e gerenciamento de contas. Essa é uma área em que tivemos que aproveitar as calculadoras de custos para criar nossos próprios níveis de preços previsíveis ou configurar os clientes com suas próprias contas para que possam fazer os pagamentos diretamente.
Conclusão
Pode ser uma tarefa difícil adotar uma nova tecnologia como agência. Embora estejamos em uma posição única para trabalhar com novos projetos greenfield que tenham oportunidades para novas tecnologias, também devemos considerar o investimento de longo prazo destes. Como eles irão atuar? Nosso pessoal será produtivo e gostará de usá-los? Podemos incorporá-los à nossa oferta de negócios?
You need to have a firm grasp of where you have been before you figure out where you want to go technologically. When evaluating a new tool or platform it's important to think of what you have tried in the past and figure out what is most important to you and your team. We took a look at the concept of a serverless database and passed it through our three lenses – the technology, the experience, and the business. We were left with some pros and cons and had to strike the right balance.
After we evaluated serverless databases, we decided to adopt Fauna over the alternatives. We felt the technology was robust and ticked all of our boxes for our technology filter. When it came to the experience, virtually zero configuration and being able to leverage our existing knowledge of relational data modeling made this a winner with the development team. On the business side serverless provides clear wins to efficiency and productivity , however on the pricing side and account management there are still some difficulties. We decided the benefits in the other areas outweighed the pricing difficulties.
Overall, we highly recommend giving Fauna a shot on one of your next projects. It has become one of our favorite tools and our go-to database of choice for smaller serverless projects and even more traditional large backend applications. The community is very helpful, the learning curve is gentle, and we believe you'll find levels of productivity you hadn't realized before with existing databases.
When we first use a new technology on a project, we start with something either internal or on the smaller side. We try to mitigate the risk by wading into the water rather than leaping into the deep end by trying it on a large and complex project. As the team builds understanding of the technology, we start using it for larger projects but only after we feel comfortable that it has handled similar use cases well for us in the past.
In general, it can take up to a year for a technology to become a ubiquitous part of most projects so it is important to be patient. Agencies have a lot of flexibility but also are required to ensure stability in the products they produce, we don't get a second chance. Always be experimenting and pushing your agency to adopt new technologies, but do so carefully and you will reap the benefits.
Leitura adicional
- Serverless Database Wishlist - What's Missing Today
- Relational NoSQL: Yes, that is an option
- Concerning toolkits - A great piece about the merits of zero configuration on developer experience