
Construindo um detector de ambiente para dispositivos IoT no Mac OS
Publicados: 2022-03-10Saber em qual sala você está permite vários aplicativos de IoT — desde acender a luz até mudar os canais de TV. Então, como podemos detectar o momento em que você e seu telefone estão na cozinha, no quarto ou na sala de estar? Com o hardware de commodities de hoje, há uma infinidade de possibilidades:
Uma solução é equipar cada quarto com um dispositivo bluetooth . Quando seu telefone estiver dentro do alcance de um dispositivo bluetooth, seu telefone saberá qual é a sala, com base no dispositivo bluetooth. No entanto, manter uma variedade de dispositivos Bluetooth é uma sobrecarga significativa – desde a substituição de baterias até a substituição de dispositivos disfuncionais. Além disso, a proximidade com o dispositivo Bluetooth nem sempre é a resposta: se você estiver na sala, perto da parede compartilhada com a cozinha, seus utensílios de cozinha não devem começar a despejar comida.
Outra solução, embora impraticável, é usar o GPS . No entanto, tenha em mente que o GPS funciona mal em ambientes fechados em que a multidão de paredes, outros sinais e outros obstáculos causam estragos na precisão do GPS.
Nossa abordagem é aproveitar todas as redes WiFi dentro do alcance - mesmo aquelas às quais seu telefone não está conectado. Veja como: considere a força do WiFi A na cozinha; digamos que seja 5. Como há uma parede entre a cozinha e o quarto, podemos razoavelmente esperar que a força do WiFi A no quarto seja diferente; digamos que é 2. Podemos explorar essa diferença para prever em qual sala estamos. Além do mais: a rede WiFi B do nosso vizinho só pode ser detectada da sala de estar, mas é efetivamente invisível da cozinha. Isso torna a previsão ainda mais fácil. Em suma, a lista de todos os WiFi dentro do alcance nos fornece informações abundantes.
Este método tem as vantagens distintas de:
- não requerendo mais hardware;
- contando com sinais mais estáveis como WiFi;
- funcionando bem onde outras técnicas como GPS são fracas.
Quanto mais paredes, melhor, pois quanto mais díspares forem as forças da rede WiFi, mais fácil será a classificação das salas. Você criará um aplicativo de desktop simples que coleta dados, aprende com os dados e prevê em qual sala você está a qualquer momento.
Leitura adicional no SmashingMag:
- A ascensão da interface do usuário de conversação inteligente
- Aplicações de aprendizado de máquina para designers
- Como prototipar experiências de IoT: construindo o hardware
- Projetando para a Internet das Coisas Emocionais
Pré-requisitos
Para este tutorial, você precisará de um Mac OSX. Considerando que o código pode ser aplicado a qualquer plataforma, forneceremos apenas instruções de instalação de dependência para Mac.
- Mac OS X
- Homebrew, um gerenciador de pacotes para Mac OSX. Para instalar, copie e cole o comando em brew.sh
- Instalação do NodeJS 10.8.0+ e npm
- Instalação do Python 3.6+ e pip. Veja as primeiras 3 seções de “Como instalar o virtualenv, instalando com pip e gerenciando pacotes”
Etapa 0: configurar o ambiente de trabalho
Seu aplicativo de desktop será escrito em NodeJS. No entanto, para alavancar bibliotecas computacionais mais eficientes como numpy , o código de treinamento e previsão será escrito em Python. Para começar, vamos configurar seus ambientes e instalar dependências. Crie um novo diretório para hospedar seu projeto.
mkdir ~/riotNavegue no diretório.
cd ~/riotUse pip para instalar o gerenciador de ambiente virtual padrão do Python.
sudo pip install virtualenv Crie um ambiente virtual Python3.6 chamado riot .
virtualenv riot --python=python3.6Ative o ambiente virtual.
source riot/bin/activate Seu prompt agora é precedido por (riot) . Isso indica que entramos com sucesso no ambiente virtual. Instale os seguintes pacotes usando pip :
-
numpy: Uma biblioteca de álgebra linear eficiente -
scipy: Uma biblioteca de computação científica que implementa modelos populares de aprendizado de máquina
pip install numpy==1.14.3 scipy ==1.1.0Com a configuração do diretório de trabalho, começaremos com um aplicativo de desktop que registra todas as redes WiFi dentro do alcance. Essas gravações constituirão dados de treinamento para seu modelo de aprendizado de máquina. Assim que tivermos os dados em mãos, você escreverá um classificador de mínimos quadrados, treinado nos sinais WiFi coletados anteriormente. Por fim, usaremos o modelo de mínimos quadrados para prever a sala em que você está, com base nas redes WiFi ao alcance.
Etapa 1: aplicativo de desktop inicial
Nesta etapa, criaremos um novo aplicativo de desktop usando o Electron JS. Para começar, usaremos o gerenciador de pacotes Node npm e um utilitário de download wget .
brew install npm wgetPara começar, vamos criar um novo projeto Node.
npm init Isso solicita o nome do pacote e, em seguida, o número da versão. Pressione ENTER para aceitar o nome padrão de riot e a versão padrão de 1.0.0 .
package name: (riot) version: (1.0.0) Isso solicita uma descrição do projeto. Adicione qualquer descrição não vazia que desejar. Abaixo, a descrição é room detector
description: room detector Isso solicita o ponto de entrada ou o arquivo principal do qual executar o projeto. Digite app.js .
entry point: (index.js) app.js Isso solicita o test command e o git repository . Pressione ENTER para pular esses campos por enquanto.
test command: git repository: Isso solicita palavras- keywords e author . Preencha os valores que desejar. Abaixo, usamos iot , wifi para palavras-chave e usamos John Doe para o autor.
keywords: iot,wifi author: John Doe Isso solicita a licença. Pressione ENTER para aceitar o valor padrão de ISC .
license: (ISC) Neste ponto, o npm solicitará um resumo das informações até o momento. Sua saída deve ser semelhante à seguinte.
{ "name": "riot", "version": "1.0.0", "description": "room detector", "main": "app.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [ "iot", "wifi" ], "author": "John Doe", "license": "ISC" } Pressione ENTER para aceitar. npm então produz um package.json . Liste todos os arquivos para verificar novamente.
lsIsso produzirá o único arquivo neste diretório, juntamente com a pasta do ambiente virtual.
package.json riotInstale as dependências do NodeJS para nosso projeto.
npm install electron --global # makes electron binary accessible globally npm install node-wifi --save Comece com main.js do Electron Quick Start, baixando o arquivo, usando o abaixo. O argumento -O a seguir renomeia main.js para app.js .
wget https://raw.githubusercontent.com/electron/electron-quick-start/master/main.js -O app.js Abra app.js no nano ou no seu editor de texto favorito.
nano app.js Na linha 12, altere index.html para static/index.html , pois criaremos um diretório static para conter todos os templates HTML.
function createWindow () { // Create the browser window. win = new BrowserWindow({width: 1200, height: 800}) // and load the index.html of the app. win.loadFile('static/index.html') // Open the DevTools. Salve suas alterações e saia do editor. Seu arquivo deve corresponder ao código-fonte do arquivo app.js Agora crie um novo diretório para hospedar nossos templates HTML.
mkdir staticBaixe uma folha de estilo criada para este projeto.
wget https://raw.githubusercontent.com/alvinwan/riot/master/static/style.css?token=AB-ObfDtD46ANlqrObDanckTQJ2Q1Pyuks5bf79PwA%3D%3D -O static/style.css Abra static/index.html no nano ou no seu editor de texto favorito. Comece com a estrutura HTML padrão.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> </head> <body> <main> </main> </body> </html>Logo após o título, vincule a fonte Montserrat vinculada pelo Google Fonts e folha de estilo.
<title>Riot | Room Detector</title> <!-- start new code --> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> <!-- end new code --> </head> Entre as tags main , adicione um slot para o nome da sala prevista.
<main> <!-- start new code --> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> <!-- end new code --> </main>Seu script agora deve corresponder exatamente ao seguinte. Saia do editor.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> </main> </body> </html>Agora, altere o arquivo do pacote para conter um comando de início.
nano package.json Logo após a linha 7, adicione um comando start com o alias de electron . . Certifique-se de adicionar uma vírgula ao final da linha anterior.
"scripts": { "test": "echo \"Error: no test specified\" && exit 1", "start": "electron ." }, Salvar e sair. Agora você está pronto para iniciar seu aplicativo de desktop no Electron JS. Use npm para iniciar seu aplicativo.
npm startSeu aplicativo de desktop deve corresponder ao seguinte.

Isso conclui seu aplicativo de desktop inicial. Para sair, navegue de volta ao seu terminal e CTRL+C. Na próxima etapa, gravaremos redes wifi e tornaremos o utilitário de gravação acessível por meio da interface do usuário do aplicativo de desktop.
Etapa 2: gravar redes WiFi
Nesta etapa, você escreverá um script NodeJS que registra a força e a frequência de todas as redes wifi dentro do alcance. Crie um diretório para seus scripts.
mkdir scripts Abra scripts/observe.js no nano ou no seu editor de texto favorito.
nano scripts/observe.jsImporte um utilitário wifi NodeJS e o objeto do sistema de arquivos.
var wifi = require('node-wifi'); var fs = require('fs'); Defina uma função de record que aceite um manipulador de conclusão.
/** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { } Dentro da nova função, inicialize o utilitário wifi. Defina iface como null para inicializar em uma interface wifi aleatória, pois esse valor é atualmente irrelevante.
function record(n, completion, hook) { wifi.init({ iface : null }); }Defina uma matriz para conter suas amostras. Amostras são dados de treinamento que usaremos para nosso modelo. As amostras neste tutorial em particular são listas de redes wifi dentro do alcance e suas forças, frequências, nomes etc.
function record(n, completion, hook) { ... samples = [] } Defina uma função recursiva startScan , que iniciará as varreduras de wifi de forma assíncrona. Após a conclusão, a varredura assíncrona de wifi invocará recursivamente startScan .
function record(n, completion, hook) { ... function startScan(i) { wifi.scan(function(err, networks) { }); } startScan(n); } No retorno de chamada wifi.scan , verifique se há erros ou listas vazias de redes e reinicie a verificação, se for o caso.
wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } });Adicione o caso base da função recursiva, que invoca o manipulador de conclusão.
wifi.scan(function(err, networks) { ... if (i <= 0) { return completion({samples: samples}); } });Emita uma atualização de progresso, anexe à lista de amostras e faça a chamada recursiva.
wifi.scan(function(err, networks) { ... hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); No final do arquivo, invoque a função de record com um retorno de chamada que salva amostras em um arquivo no disco.
function record(completion) { ... } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + (21-i) + " with " + networks.length + " networks"); }) } cli();Verifique se seu arquivo corresponde ao seguinte:
var wifi = require('node-wifi'); var fs = require('fs'); /** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { wifi.init({ iface : null // network interface, choose a random wifi interface if set to null }); samples = [] function startScan(i) { wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } if (i <= 0) { return completion({samples: samples}); } hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); } startScan(n); } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks"); }) } cli();Salvar e sair. Execute o script.
node scripts/observe.jsSua saída corresponderá ao seguinte, com números variáveis de redes.
* [INFO] Collected sample 1 with 39 networks Examine as amostras que acabaram de ser coletadas. Pipe to json_pp para imprimir o JSON e pipe to head para ver as primeiras 16 linhas.
cat samples.json | json_pp | head -16O abaixo é um exemplo de saída para uma rede de 2,4 GHz.
{ "samples": [ [ { "mac": "64:0f:28:79:9a:29", "bssid": "64:0f:28:79:9a:29", "ssid": "SMASHINGMAGAZINEROCKS", "channel": 4, "frequency": 2427, "signal_level": "-91", "security": "WPA WPA2", "security_flags": [ "(PSK/AES,TKIP/TKIP)", "(PSK/AES,TKIP/TKIP)" ] },Isso conclui seu script de verificação de wifi NodeJS. Isso nos permite visualizar todas as redes WiFi dentro do alcance. Na próxima etapa, você tornará esse script acessível no aplicativo de desktop.
Etapa 3: conectar o script de digitalização ao aplicativo da área de trabalho
Nesta etapa, você primeiro adicionará um botão ao aplicativo de desktop para acionar o script. Em seguida, você atualizará a interface do usuário do aplicativo de desktop com o progresso do script.
Abra static/index.html .
nano static/index.htmlInsira o botão “Adicionar”, conforme mostrado abaixo.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <div class="buttons"> <a href="add.html" class="button">Add new room</a> </div> <!-- end new code --> </main> Salvar e sair. Abra static/add.html .
nano static/add.htmlCole o seguinte conteúdo.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Add New Room</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <h1 class="title">0</h1> <p class="subtitle">of <span>20</span> samples needed. Feel free to move around the room.</p> <input type="text" class="text-field" placeholder="(room name)"> <div class="buttons"> <a href="#" class="button">Start recording</a> <a href="index.html" class="button light">Cancel</a> </div> <p class="text"></p> </main> <script> require('../scripts/observe.js') </script> </body> </html> Salvar e sair. Reabra scripts/observe.js .
nano scripts/observe.js Abaixo da função cli , defina uma nova função ui .
function cli() { ... } // start new code function ui() { } // end new code cli();Atualize o status do aplicativo de desktop para indicar que a função começou a ser executada.
function ui() { var room_name = document.querySelector('#add-room-name').value; var status = document.querySelector('#add-status'); var number = document.querySelector('#add-title'); status.style.display = "block" status.innerHTML = "Listening for wifi..." }Particione os dados em conjuntos de dados de treinamento e validação.
function ui() { ... function completion(data) { train_data = {samples: data['samples'].slice(0, 15)} test_data = {samples: data['samples'].slice(15)} var train_json = JSON.stringify(train_data); var test_json = JSON.stringify(test_data); } } Ainda dentro do retorno de chamada de completion , grave os dois conjuntos de dados no disco.
function ui() { ... function completion(data) { ... fs.writeFile('data/' + room_name + '_train.json', train_json, 'utf8', function() {}); fs.writeFile('data/' + room_name + '_test.json', test_json, 'utf8', function() {}); console.log(" * [INFO] Done") status.innerHTML = "Done." } } Invoque record com os retornos de chamada apropriados para gravar 20 amostras e salve as amostras em disco.
function ui() { ... function completion(data) { ... } record(20, completion, function(i, networks) { number.innerHTML = i console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks") }) } Por fim, invoque as funções cli e ui quando apropriado. Comece excluindo o cli(); chamada na parte inferior do arquivo.
function ui() { ... } cli(); // remove me Verifique se o objeto de documento é globalmente acessível. Caso contrário, o script está sendo executado a partir da linha de comando. Nesse caso, invoque a função cli . Se for, o script é carregado de dentro do aplicativo de desktop. Nesse caso, vincule o ouvinte de clique à função ui .
if (typeof document == 'undefined') { cli(); } else { document.querySelector('#start-recording').addEventListener('click', ui) }Salvar e sair. Crie um diretório para armazenar nossos dados.
mkdir dataInicie o aplicativo de desktop.
npm startVocê verá a seguinte página inicial. Clique em “Adicionar sala”.
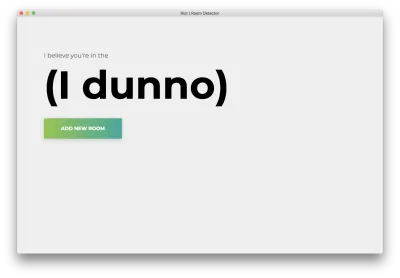
Você verá o seguinte formulário. Digite um nome para a sala. Lembre-se desse nome, pois usaremos isso mais tarde. Nosso exemplo será bedroom .
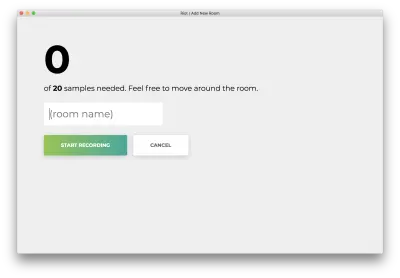
Clique em “Iniciar gravação” e você verá o seguinte status “Ouvindo wifi…”.
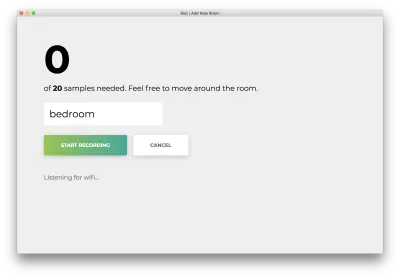
Depois que todas as 20 amostras forem gravadas, seu aplicativo corresponderá ao seguinte. O status será "Concluído".

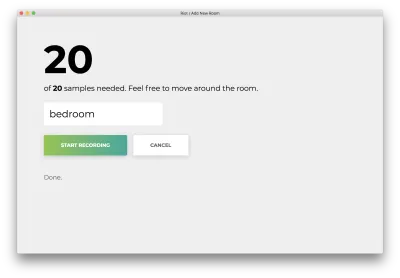
Clique no nome errado "Cancelar" para retornar à página inicial, que corresponde ao seguinte.
Agora podemos escanear redes wifi a partir da interface do usuário da área de trabalho, que salvará todas as amostras gravadas em arquivos no disco. Em seguida, treinaremos um algoritmo de aprendizado de máquina pronto para uso - mínimos quadrados nos dados que você coletou.
Etapa 4: escrever o script de treinamento do Python
Nesta etapa, escreveremos um script de treinamento em Python. Crie um diretório para seus utilitários de treinamento.
mkdir model Abra model/train.py
nano model/train.py No topo do seu arquivo, importe a biblioteca computacional numpy e scipy para seu modelo de mínimos quadrados.
import numpy as np from scipy.linalg import lstsq import json import sysOs próximos três utilitários tratarão do carregamento e da configuração dos dados dos arquivos no disco. Comece adicionando uma função de utilitário que nivela listas aninhadas. Você usará isso para achatar uma lista de listas de amostras.
import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) Adicione um segundo utilitário que carrega amostras dos arquivos especificados. Esse método abstrai o fato de que as amostras estão espalhadas por vários arquivos, retornando apenas um único gerador para todas as amostras. Para cada uma das amostras, o rótulo é o índice do arquivo. Por exemplo, se você chamar get_all_samples('a.json', 'b.json') , todas as amostras em a.json terão rótulo 0 e todas as amostras em b.json terão rótulo 1.
def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, labelEm seguida, adicione um utilitário que codifique as amostras usando um modelo de saco de palavras. Aqui está um exemplo: Suponha que coletamos duas amostras.
- rede wifi A na força 10 e rede wifi B na força 15
- rede wifi B na força 20 e rede wifi C na força 25.
Esta função produzirá uma lista de três números para cada uma das amostras: o primeiro valor é a força da rede wifi A, o segundo para a rede B e o terceiro para C. Na verdade, o formato é [A, B, C ].
- [10, 15, 0]
- [0, 20, 25]
def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [strengths[networks.index(network)] if network in networks else 0 for network in ordering] Usando todos os três utilitários acima, sintetizamos uma coleção de amostras e seus rótulos. Reúna todas as amostras e rótulos usando get_all_samples . Defina uma ordering de formato consistente para codificar one-hot todas as amostras e, em seguida, aplique a codificação one_hot às amostras. Finalmente, construa os dados e rotule as matrizes X e Y , respectivamente.
def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, orderingEssas funções completam o pipeline de dados. Em seguida, abstraímos a previsão e avaliação do modelo. Comece definindo o método de previsão. A primeira função normaliza as saídas do nosso modelo, de modo que a soma de todos os valores totalize 1 e que todos os valores sejam não negativos; isso garante que a saída seja uma distribuição de probabilidade válida. A segunda avalia o modelo.
def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1)Em seguida, avalie a precisão do modelo. A primeira linha executa a previsão usando o modelo. O segundo conta o número de vezes que os valores previstos e verdadeiros concordam e, em seguida, normaliza pelo número total de amostras.
def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy Isso conclui nossas utilidades de previsão e avaliação. Após esses utilitários, defina uma função main que coletará o conjunto de dados, treinará e avaliará. Comece lendo a lista de argumentos da linha de comando sys.argv ; estas são as salas a incluir na formação. Em seguida, crie um grande conjunto de dados de todas as salas especificadas.
def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering)Aplique a codificação one-hot aos rótulos. Uma codificação one-hot é semelhante ao modelo de saco de palavras acima; usamos essa codificação para lidar com variáveis categóricas. Digamos que temos 3 rótulos possíveis. Em vez de rotular 1, 2 ou 3, rotulamos os dados com [1, 0, 0], [0, 1, 0] ou [0, 0, 1]. Para este tutorial, pouparemos a explicação de por que a codificação one-hot é importante. Treine o modelo e avalie nos conjuntos de treinamento e validação.
def main(): ... X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) test_accuracy = evaluate(X_test, Y_test, w)Imprima ambas as precisões e salve o modelo em disco.
def main(): ... print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, test_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() No final do arquivo, execute a função main .
if __name__ == '__main__': main()Salvar e sair. Verifique se seu arquivo corresponde ao seguinte:
import numpy as np from scipy.linalg import lstsq import json import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, label def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [int(strengths[networks.index(network)]) if network in networks else 0 for network in ordering] def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, ordering def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1) def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) validation_accuracy = evaluate(X_test, Y_test, w) print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, validation_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() if __name__ == '__main__': main() Salvar e sair. Lembre-se do nome da sala usado acima ao gravar as 20 amostras. Use esse nome em vez do bedroom abaixo. Nosso exemplo é bedroom . Usamos -W ignore para ignorar avisos de um bug LAPACK.
python -W ignore model/train.py bedroomComo coletamos apenas amostras de treinamento para uma sala, você deve ver 100% de precisão de treinamento e validação.
Train accuracy (100.0%), Validation accuracy (100.0%)Em seguida, vincularemos esse script de treinamento ao aplicativo de desktop.
Etapa 5: script de treinamento de links
Nesta etapa, retreinaremos automaticamente o modelo sempre que o usuário coletar um novo lote de amostras. Abra scripts/observe.js .
nano scripts/observe.js Logo após a importação do fs , importe o gerador e os utilitários do processo filho.
var fs = require('fs'); // start new code const spawn = require("child_process").spawn; var utils = require('./utils.js'); Na função ui , adicione a seguinte chamada para retrain no final do manipulador de conclusão.
function ui() { ... function completion() { ... retrain((data) => { var status = document.querySelector('#add-status'); accuracies = data.toString().split('\n')[0]; status.innerHTML = "Retraining succeeded: " + accuracies }); } ... } Após a função ui , adicione a seguinte função de retrain . Isso gera um processo filho que executará o script python. Após a conclusão, o processo chama um manipulador de conclusão. Em caso de falha, ele registrará a mensagem de erro.
function ui() { .. } function retrain(completion) { var filenames = utils.get_filenames() const pythonProcess = spawn('python', ["./model/train.py"].concat(filenames)); pythonProcess.stdout.on('data', completion); pythonProcess.stderr.on('data', (data) => { console.log(" * [ERROR] " + data.toString()) }) } Salvar e sair. Abra scripts/utils.js .
nano scripts/utils.js Adicione o seguinte utilitário para buscar todos os conjuntos de dados em data/ .
var fs = require('fs'); module.exports = { get_filenames: get_filenames } function get_filenames() { filenames = new Set([]); fs.readdirSync("data/").forEach(function(filename) { filenames.add(filename.replace('_train', '').replace('_test', '').replace('.json', '' )) }); filenames = Array.from(filenames.values()) filenames.sort(); filenames.splice(filenames.indexOf('.DS_Store'), 1) return filenames }Salvar e sair. Para a conclusão desta etapa, mova-se fisicamente para um novo local. Idealmente, deve haver uma parede entre sua localização original e sua nova localização. Quanto mais barreiras, melhor o seu aplicativo de desktop funcionará.
Mais uma vez, execute seu aplicativo de desktop.
npm startAssim como antes, execute o script de treinamento. Clique em “Adicionar sala”.
Digite um nome de quarto diferente do seu primeiro quarto. Usaremos a living room .
Clique em “Iniciar gravação” e você verá o seguinte status “Ouvindo wifi…”.
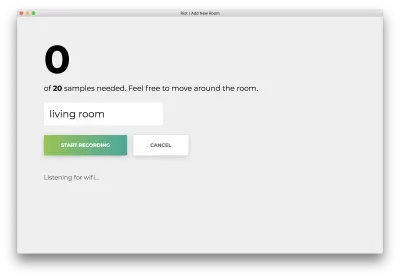
Depois que todas as 20 amostras forem gravadas, seu aplicativo corresponderá ao seguinte. O status será “Concluído. Modelo de reciclagem…”
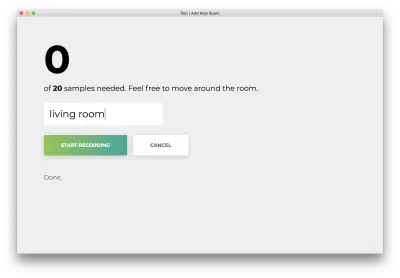
Na próxima etapa, usaremos esse modelo retreinado para prever em tempo real a sala em que você está.
Etapa 6: escrever o script de avaliação do Python
Nesta etapa, carregaremos os parâmetros do modelo pré-treinados, verificaremos as redes wifi e preveremos a sala com base na verificação.
Abra model/eval.py .
nano model/eval.pyImportar bibliotecas usadas e definidas em nosso último script.
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate Defina um utilitário para extrair os nomes de todos os conjuntos de dados. Esta função assume que todos os conjuntos de dados são armazenados em data/ como <dataset>_train.json e <dataset>_test.json .
from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) Defina a função main e comece carregando os parâmetros salvos do script de treinamento.
def get_datasets(): ... def main(): w = np.load('w.npy') ordering = np.load('ordering.npy')Crie o conjunto de dados e preveja.
def main(): ... classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w))Calcule uma pontuação de confiança com base na diferença entre as duas principais probabilidades.
def main(): ... sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) Por fim, extraia a categoria e imprima o resultado. Para concluir o script, invoque a função main .
def main() ... category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()Salvar e sair. Verifique se seu código corresponde ao seguinte (código-fonte):
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) def main(): w = np.load('w.npy') ordering = np.load('ordering.npy') classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w)) sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()Em seguida, conectaremos esse script de avaliação ao aplicativo de desktop. O aplicativo de desktop executará continuamente verificações de Wi-Fi e atualizará a interface do usuário com a sala prevista.
Etapa 7: conectar a avaliação ao aplicativo para desktop
Nesta etapa, atualizaremos a interface do usuário com uma exibição de “confiança”. Em seguida, o script NodeJS associado executará continuamente verificações e previsões, atualizando a interface do usuário de acordo.
Abra static/index.html .
nano static/index.htmlAdicione uma linha de confiança logo após o título e antes dos botões.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <p class="subtitle">with <span>0%</span> confidence</p> <!-- end new code --> <div class="buttons"> Logo após main , mas antes do final do body , adicione um novo script predict.js .
</main> <!-- start new code --> <script> require('../scripts/predict.js') </script> <!-- end new code --> </body> Salvar e sair. Abra scripts/predict.js .
nano scripts/predict.jsImporte os utilitários NodeJS necessários para o sistema de arquivos, utilitários e gerador de processo filho.
var fs = require('fs'); var utils = require('./utils'); const spawn = require("child_process").spawn; Defina uma função de predict que invoca um processo de nó separado para detectar redes Wi-Fi e um processo Python separado para prever a sala.
function predict(completion) { const nodeProcess = spawn('node', ["scripts/observe.js"]); const pythonProcess = spawn('python', ["-W", "ignore", "./model/eval.py", "samples.json"]); }Após a geração de ambos os processos, adicione retornos de chamada ao processo Python para sucessos e erros. O retorno de chamada de sucesso registra informações, invoca o retorno de chamada de conclusão e atualiza a interface do usuário com a previsão e a confiança. O retorno de chamada de erro registra o erro.
function predict(completion) { ... pythonProcess.stdout.on('data', (data) => { information = JSON.parse(data.toString()); console.log(" * [INFO] Room '" + information.category + "' with confidence '" + information.confidence + "'") completion() if (typeof document != "undefined") { document.querySelector('#predicted-room-name').innerHTML = information.category document.querySelector('#predicted-confidence').innerHTML = information.confidence } }); pythonProcess.stderr.on('data', (data) => { console.log(data.toString()); }) } Defina uma função principal para invocar a função de predict recursivamente, para sempre.
function main() { f = function() { predict(f) } predict(f) } main();Uma última vez, abra o aplicativo de desktop para ver a previsão ao vivo.
npm startAproximadamente a cada segundo, uma varredura será concluída e a interface será atualizada com a mais recente confiança e espaço previsto. Parabéns; você concluiu um detector de ambiente simples baseado em todas as redes WiFi dentro do alcance.
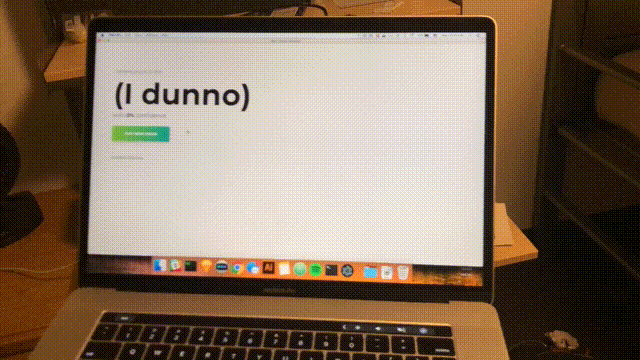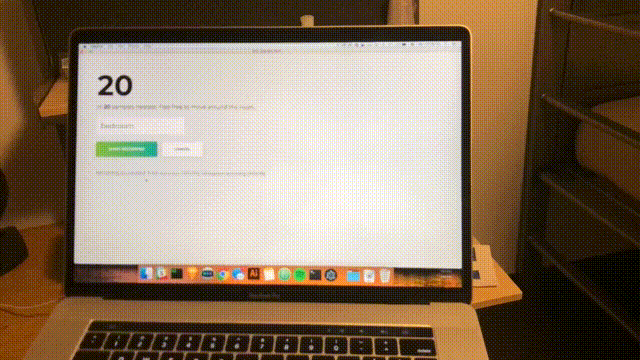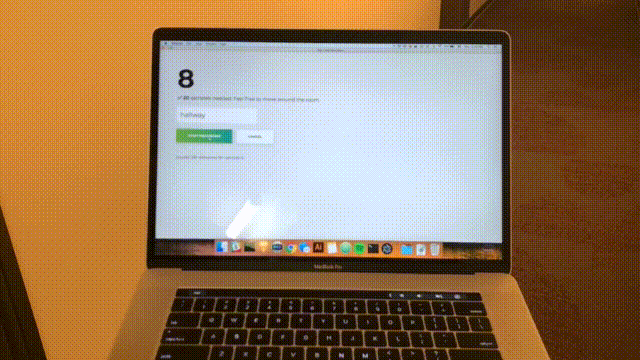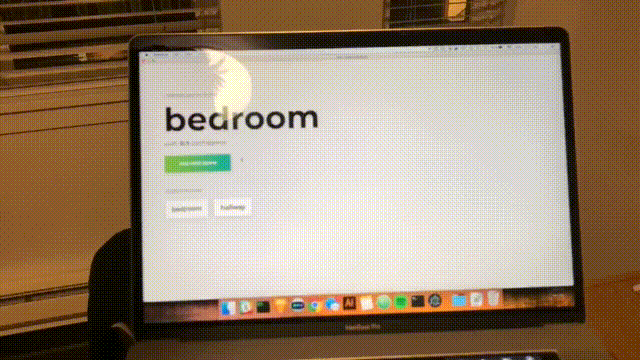
Conclusão
Neste tutorial, criamos uma solução usando apenas sua área de trabalho para detectar sua localização em um prédio. Construímos um aplicativo de desktop simples usando o Electron JS e aplicamos um método simples de aprendizado de máquina em todas as redes WiFi dentro do alcance. Isso abre caminho para aplicativos de Internet das coisas sem a necessidade de conjuntos de dispositivos cuja manutenção é cara (custo não em termos de dinheiro, mas em termos de tempo e desenvolvimento).
Nota : Você pode ver o código-fonte na íntegra no Github.
Com o tempo, você pode descobrir que esses mínimos quadrados não funcionam espetacularmente de fato. Tente encontrar dois locais dentro de uma única sala ou fique nas portas. Os mínimos quadrados serão grandes incapazes de distinguir entre casos de borda. Podemos fazer melhor? Acontece que podemos, e em lições futuras, vamos alavancar outras técnicas e os fundamentos do aprendizado de máquina para um melhor desempenho. Este tutorial serve como um teste rápido para experimentos futuros.