
Construindo um Serviço de Logging Central Interno
Publicados: 2022-03-10Todos sabemos como a depuração é importante para melhorar o desempenho e os recursos do aplicativo. O BrowserStack executa um milhão de sessões por dia em uma pilha de aplicativos altamente distribuída! Cada um envolve várias partes móveis, pois a única sessão de um cliente pode abranger vários componentes em várias regiões geográficas.
Sem a estrutura e as ferramentas corretas, o processo de depuração pode ser um pesadelo. No nosso caso, precisávamos de uma maneira de coletar os eventos que aconteciam durante as diferentes etapas de cada processo para obter uma compreensão profunda de tudo o que ocorre durante uma sessão. Com nossa infraestrutura, resolver esse problema ficou complicado, pois cada componente pode ter vários eventos de seu ciclo de vida de processamento de uma solicitação.
É por isso que desenvolvemos nossa própria ferramenta de Central Logging Service (CLS) interna para registrar todos os eventos importantes registrados durante uma sessão. Esses eventos ajudam nossos desenvolvedores a identificar as condições em que algo dá errado em uma sessão e ajudam a acompanhar certas métricas-chave do produto.
Os dados de depuração variam de coisas simples, como latência de resposta da API, até o monitoramento da integridade da rede de um usuário. Neste artigo, compartilhamos nossa história de construção de nossa ferramenta CLS que coleta 70G de dados cronológicos relevantes por dia de mais de 100 componentes de forma confiável, em escala e com duas instâncias M3.large EC2.
A decisão de construir internamente
Primeiro, vamos considerar por que construímos nossa ferramenta CLS internamente em vez de usar uma solução existente. Cada uma de nossas sessões envia em média 15 eventos, de múltiplos componentes ao serviço - traduzindo em aproximadamente 15 milhões de eventos totais por dia.
Nosso serviço precisava da capacidade de armazenar todos esses dados. Buscamos uma solução completa para suportar o armazenamento, envio e consulta de eventos entre eventos. Como consideramos soluções de terceiros, como Amplitude e Keen, nossas métricas de avaliação incluíram custo, desempenho no tratamento de altas solicitações paralelas e facilidade de adoção. Infelizmente, não conseguimos encontrar um ajuste que atendesse a todos os nossos requisitos dentro do orçamento - embora os benefícios incluíssem economia de tempo e redução de alertas. Embora exigisse um esforço adicional, decidimos desenvolver uma solução interna.

Detalhes técnicos
Em termos de arquitetura para nosso componente, descrevemos os seguintes requisitos básicos:
- Desempenho do cliente
Não afeta o desempenho do cliente/componente que envia os eventos. - Régua
Capaz de lidar com um grande número de solicitações em paralelo. - Desempenho do serviço
Rápido para processar todos os eventos que estão sendo enviados para ele. - Insights de dados
Cada evento registrado precisa ter algumas informações meta para poder identificar exclusivamente o componente ou usuário, conta ou mensagem e fornecer mais informações para ajudar o desenvolvedor a depurar mais rapidamente. - Interface consultável
Os desenvolvedores podem consultar todos os eventos de uma sessão específica, ajudando a depurar uma sessão específica, criar relatórios de integridade de componentes ou gerar estatísticas de desempenho significativas de nossos sistemas. - Adoção mais rápida e fácil
Fácil integração com um componente existente ou novo sem sobrecarregar as equipes e consumir seus recursos. - Baixa manutenção
Somos uma pequena equipe de engenharia, por isso buscamos uma solução para minimizar os alertas!
Construindo nossa solução CLS
Decisão 1: Escolhendo uma interface para expor
Ao desenvolver o CLS, obviamente não queríamos perder nenhum de nossos dados, mas também não queríamos que o desempenho do componente fosse afetado. Sem mencionar o fator adicional de impedir que os componentes existentes se tornem mais complicados, pois isso atrasaria a adoção e o lançamento geral. Ao determinar nossa interface, consideramos as seguintes opções:
- Armazenar eventos no Redis local em cada componente, à medida que um processador em segundo plano o envia para o CLS. No entanto, isso requer uma alteração em todos os componentes, juntamente com a introdução do Redis para componentes que ainda não o continham.
- Um modelo de Publicador - Assinante, em que o Redis está mais próximo do CLS. Como todos publicam eventos, novamente temos o fator de componentes rodando em todo o mundo. Durante o período de tráfego intenso, isso atrasaria os componentes. Além disso, essa gravação pode saltar intermitentemente até cinco segundos (devido apenas à Internet).
- Envio de eventos por UDP, que oferece menor impacto no desempenho do aplicativo. Nesse caso os dados seriam enviados e esquecidos, porém, a desvantagem aqui seria a perda de dados.
Curiosamente, nossa perda de dados em relação ao UDP foi inferior a 0,1%, o que era um valor aceitável para considerarmos a construção de tal serviço. Conseguimos convencer todas as equipes de que essa quantidade de perda valia o desempenho e seguimos em frente para alavancar uma interface UDP que ouvia todos os eventos enviados.
Embora um resultado tenha sido um impacto menor no desempenho de um aplicativo, enfrentamos um problema, pois o tráfego UDP não era permitido de todas as redes, principalmente de nossos usuários - fazendo com que, em alguns casos, não recebêssemos nenhum dado. Como solução alternativa, oferecemos suporte ao registro de eventos usando solicitações HTTP. Todos os eventos vindos do lado do usuário seriam enviados via HTTP, enquanto todos os eventos sendo gravados de nossos componentes seriam via UDP.
Decisão 2: Tech Stack (Idioma, Estrutura e Armazenamento)
Somos uma loja Ruby. No entanto, não tínhamos certeza se Ruby seria uma escolha melhor para nosso problema específico. Nosso serviço teria que lidar com muitas solicitações recebidas, além de processar muitas gravações. Com o bloqueio Global Interpreter, alcançar multithreading ou simultaneidade seria difícil em Ruby (por favor, não se ofenda - nós amamos Ruby!). Então precisávamos de uma solução que nos ajudasse a alcançar esse tipo de simultaneidade.
Também estávamos ansiosos para avaliar uma nova linguagem em nossa pilha de tecnologia, e esse projeto parecia perfeito para experimentar coisas novas. Foi quando decidimos dar uma chance ao Golang, já que ele oferecia suporte embutido para simultaneidade e threads e rotinas leves. Cada ponto de dados registrado se assemelha a um par chave-valor em que 'chave' é o evento e 'valor' serve como seu valor associado.
Mas ter uma chave e um valor simples não é suficiente para recuperar dados relacionados a uma sessão - há mais metadados para isso. Para resolver isso, decidimos que qualquer evento que precisasse ser registrado teria um ID de sessão junto com sua chave e valor. Também adicionamos campos extras como carimbo de data/hora, ID do usuário e o componente que registra os dados, para que fique mais fácil buscar e analisar os dados.

Agora que decidimos sobre nossa estrutura de carga útil, tivemos que escolher nosso armazenamento de dados. Consideramos o Elastic Search, mas também queríamos oferecer suporte a solicitações de atualização de chaves. Isso faria com que todo o documento fosse reindexado, o que poderia afetar o desempenho de nossas gravações. O MongoDB fazia mais sentido como um armazenamento de dados, pois seria mais fácil consultar todos os eventos com base em qualquer um dos campos de dados que seriam adicionados. Isso foi fácil!
Decisão 3: O tamanho do banco de dados é enorme e a consulta e o arquivamento são uma merda!
Para reduzir a manutenção, nosso serviço teria que lidar com o maior número possível de eventos. Dada a taxa que o BrowserStack lança recursos e produtos, tínhamos certeza de que o número de nossos eventos aumentaria a taxas mais altas ao longo do tempo, o que significa que nosso serviço teria que continuar a ter um bom desempenho. À medida que o espaço aumenta, as leituras e gravações demoram mais – o que pode prejudicar muito o desempenho do serviço.
A primeira solução que exploramos foi mover os logs de um determinado período para fora do banco de dados (no nosso caso, optamos por 15 dias). Para isso, criamos um banco de dados diferente para cada dia, permitindo encontrar logs anteriores a um determinado período sem precisar digitalizar todos os documentos escritos. Agora, removemos continuamente os bancos de dados com mais de 15 dias do Mongo, enquanto, é claro, mantemos os backups por precaução.
A única parte restante foi uma interface de desenvolvedor para consultar dados relacionados à sessão. Honestamente, este foi o problema mais fácil de resolver. Fornecemos uma interface HTTP, onde as pessoas podem consultar eventos relacionados à sessão no banco de dados correspondente no MongoDB, para quaisquer dados que tenham um ID de sessão específico.
Arquitetura
Vamos falar sobre os componentes internos do serviço, considerando os seguintes pontos:
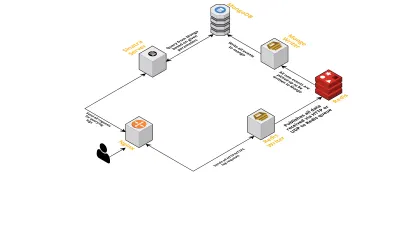
- Conforme discutido anteriormente, precisávamos de duas interfaces - uma escutando por UDP e outra escutando por HTTP. Então construímos dois servidores, novamente um para cada interface, para escutar eventos. Assim que um evento chega, nós o analisamos para verificar se ele possui os campos obrigatórios - estes são ID de sessão, chave e valor. Se isso não acontecer, os dados são descartados. Caso contrário, os dados são passados por um canal Go para outra goroutine, cuja única responsabilidade é gravar no MongoDB.
- Uma possível preocupação aqui é escrever para o MongoDB. Se as gravações no MongoDB forem mais lentas do que a taxa de recebimento dos dados, isso cria um gargalo. Isso, por sua vez, priva outros eventos de entrada e significa perda de dados. O servidor, portanto, deve ser rápido no processamento de logs de entrada e estar pronto para processar os próximos. Para resolver o problema, dividimos o servidor em duas partes: a primeira recebe todos os eventos e os enfileira para a segunda, que os processa e os grava no MongoDB.
- Para as filas, escolhemos o Redis. Ao dividir o componente inteiro nessas duas partes, reduzimos a carga de trabalho do servidor, dando-lhe espaço para lidar com mais logs.
- Escrevemos um pequeno serviço usando o servidor Sinatra para lidar com todo o trabalho de consultar o MongoDB com os parâmetros fornecidos. Ele retorna uma resposta HTML/JSON aos desenvolvedores quando eles precisam de informações sobre uma determinada sessão.
Todos esses processos são executados em uma única instância m3.large .
Solicitações de recursos
Como nossa ferramenta CLS teve mais uso ao longo do tempo, ela precisava de mais recursos. Abaixo, discutimos estes e como eles foram adicionados.
Metadados ausentes
Gradualmente, à medida que o número de componentes no BrowserStack aumenta, exigimos mais do CLS. Por exemplo, precisávamos da capacidade de registrar eventos de componentes sem um ID de sessão. Caso contrário, obter um sobrecarregaria nossa infraestrutura, na forma de afetar o desempenho de aplicativos e incorrer em tráfego em nossos servidores principais.
Resolvemos isso habilitando o log de eventos usando outras chaves, como IDs de terminal e usuário. Agora, sempre que uma sessão é criada ou atualizada, o CLS é informado com o ID da sessão, bem como os respectivos IDs de usuário e terminal. Ele armazena um mapa que pode ser recuperado pelo processo de gravação no MongoDB. Sempre que um evento que contém o ID do usuário ou do terminal é recuperado, o ID da sessão é adicionado.
Lidar com spam (problemas de código em outros componentes)
O CLS também enfrentou as dificuldades usuais para lidar com eventos de spam. Muitas vezes encontramos implantações em componentes que geraram um grande volume de solicitações enviadas ao CLS. Outros logs sofreriam no processo, pois o servidor ficou muito ocupado para processá-los e logs importantes foram descartados.
Na maioria das vezes, a maioria dos dados registrados eram por meio de solicitações HTTP. Para controlá-los, habilitamos a limitação de taxa no nginx (usando o módulo limit_req_zone), que bloqueia solicitações de qualquer IP que encontramos atingindo solicitações mais do que um determinado número em um pequeno período de tempo. Claro, aproveitamos os relatórios de saúde de todos os IPs bloqueados e informamos as equipes responsáveis.
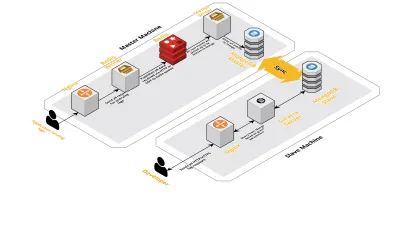
Escala v2
À medida que nossas sessões por dia aumentavam, os dados registrados no CLS também aumentavam. Isso afetou as consultas que nossos desenvolvedores estavam executando diariamente e logo o gargalo que tínhamos era com a própria máquina. Nossa configuração consistia em duas máquinas principais executando todos os componentes acima, juntamente com vários scripts para consultar o Mongo e acompanhar as principais métricas de cada produto. Com o tempo, os dados na máquina aumentaram muito e os scripts começaram a consumir muito tempo da CPU. Mesmo depois de tentar otimizar as consultas do Mongo, sempre voltamos aos mesmos problemas.
Para resolver isso, adicionamos outra máquina para executar scripts de relatórios de integridade e a interface para consultar essas sessões. O processo envolveu inicializar uma nova máquina e configurar um escravo do Mongo rodando na máquina principal. Isso ajudou a reduzir os picos de CPU que vimos todos os dias causados por esses scripts.
Conclusão
Construir um serviço para uma tarefa tão simples quanto o registro de dados pode ficar complicado, à medida que a quantidade de dados aumenta. Este artigo discute as soluções que exploramos, juntamente com os desafios enfrentados ao resolver esse problema. Experimentamos com Golang para ver como ele se encaixaria em nosso ecossistema e, até agora, ficamos satisfeitos. Nossa escolha de criar um serviço interno em vez de pagar por um externo foi maravilhosamente econômica. Também não tivemos que dimensionar nossa configuração para outra máquina até muito mais tarde - quando o volume de nossas sessões aumentou. É claro que nossas escolhas no desenvolvimento do CLS foram totalmente baseadas em nossos requisitos e prioridades.
Hoje, o CLS lida com até 15 milhões de eventos todos os dias, constituindo até 70 GB de dados. Esses dados estão sendo usados para nos ajudar a resolver quaisquer problemas que nossos clientes possam enfrentar durante qualquer sessão. Também usamos esses dados para outros fins. Considerando os insights que os dados de cada sessão fornecem sobre diferentes produtos e componentes internos, começamos a aproveitar esses dados para acompanhar cada produto. Isso é alcançado extraindo as principais métricas para todos os componentes importantes.
Em suma, obtivemos grande sucesso na construção de nossa própria ferramenta CLS. Se fizer sentido para você, recomendo que você considere fazer o mesmo!