
Como construir um raspador de produto da Amazon com Node.js
Publicados: 2022-03-10Você já esteve em uma posição em que precisa conhecer intimamente o mercado de um determinado produto? Talvez você esteja lançando algum software e precise saber como precificá-lo. Ou talvez você já tenha seu próprio produto no mercado e queira ver quais recursos adicionar para obter uma vantagem competitiva. Ou talvez você só queira comprar algo para si mesmo e tenha certeza de obter o melhor retorno possível.
Todas essas situações têm uma coisa em comum: você precisa de dados precisos para tomar a decisão correta . Na verdade, há outra coisa que eles compartilham. Todos os cenários podem se beneficiar do uso de um web scraper.
Web scraping é a prática de extrair grandes quantidades de dados da web através do uso de software. Então, em essência, é uma maneira de automatizar o tedioso processo de clicar em 'copiar' e depois 'colar' 200 vezes. Claro, um bot pode fazer isso no tempo que você levou para ler esta frase, então não é apenas menos chato, mas muito mais rápido também.
Mas a pergunta principal é: por que alguém iria querer raspar as páginas da Amazon?
Você está prestes a descobrir! Mas antes de tudo, gostaria de deixar algo claro agora – embora o ato de raspar dados disponíveis publicamente seja legal, a Amazon tem algumas medidas para impedir isso em suas páginas. Como tal, peço que você sempre esteja atento ao site durante a raspagem, tome cuidado para não danificá-lo e siga as diretrizes éticas.
Leitura recomendada : “O guia para raspagem ética de sites dinâmicos com Node.js e marionetista” por Andreas Altheimer
Por que você deve extrair dados de produtos da Amazon
Sendo o maior varejista online do planeta, é seguro dizer que, se você quiser comprar algo, provavelmente poderá obtê-lo na Amazon. Portanto, não é preciso dizer o quão grande é o tesouro de dados do site.
Ao raspar a web, sua principal pergunta deve ser o que fazer com todos esses dados. Embora existam muitas razões individuais, tudo se resume a dois casos de uso proeminentes: otimizar seus produtos e encontrar as melhores ofertas.
“
Vamos começar com o primeiro cenário. A menos que você tenha projetado um novo produto verdadeiramente inovador, as chances são de que você já possa encontrar algo pelo menos semelhante na Amazon. Raspar essas páginas de produtos pode gerar dados inestimáveis, como:
- A estratégia de preços dos concorrentes
Assim, você pode ajustar seus preços para ser competitivo e entender como os outros lidam com promoções; - Opiniões dos clientes
Para ver com o que sua futura base de clientes mais se importa e como melhorar sua experiência; - Características mais comuns
Para ver o que sua concorrência oferece, saiba quais funcionalidades são cruciais e quais podem ser deixadas para depois.
Em essência, a Amazon tem tudo o que você precisa para uma análise profunda do mercado e do produto. Você estará mais bem preparado para projetar, lançar e expandir sua linha de produtos com esses dados.
O segundo cenário pode se aplicar tanto a empresas quanto a pessoas comuns. A ideia é bem parecida com a que mencionei anteriormente. Você pode raspar os preços, recursos e avaliações de todos os produtos que você pode escolher e, assim, poderá escolher aquele que oferece mais benefícios pelo menor preço. Afinal, quem não gosta de um bom negócio?
Nem todos os produtos merecem esse nível de atenção aos detalhes, mas isso pode fazer uma enorme diferença em compras caras. Infelizmente, embora os benefícios sejam claros, muitas dificuldades acompanham a raspagem da Amazon.
Os desafios de extrair dados de produtos da Amazon
Nem todos os sites são iguais. Como regra geral, quanto mais complexo e difundido for um site, mais difícil será raspá-lo. Lembra quando eu disse que a Amazon era o site de comércio eletrônico mais proeminente? Bem, isso o torna extremamente popular e razoavelmente complexo.
Em primeiro lugar, a Amazon sabe como os bots de raspagem agem, então o site tem contramedidas em vigor. Ou seja, se o scraper seguir um padrão previsível, enviando solicitações em intervalos fixos, mais rápidos do que um humano ou com parâmetros quase idênticos, a Amazon notará e bloqueará o IP. Os proxies podem resolver esse problema, mas eu não precisei deles, pois não vamos extrair muitas páginas no exemplo.
Em seguida, a Amazon usa deliberadamente estruturas de página variadas para seus produtos. Ou seja, se você inspecionar as páginas em busca de produtos diferentes, há uma boa chance de encontrar diferenças significativas em sua estrutura e atributos. A razão por trás disso é bastante simples. Você precisa adaptar o código do seu scraper para um sistema específico e, se usar o mesmo script em um novo tipo de página, precisará reescrever partes dele. Então, eles estão essencialmente fazendo você trabalhar mais pelos dados.
Por fim, a Amazon é um site vasto. Se você deseja coletar grandes quantidades de dados, executar o software de raspagem em seu computador pode levar muito tempo para suas necessidades. Esse problema é ainda mais consolidado pelo fato de que ir muito rápido bloqueará seu raspador. Portanto, se você deseja um carregamento de dados rapidamente, precisará de um raspador realmente poderoso.
Bom, chega de falar de problemas, vamos focar nas soluções!
Como construir um Web Scraper para a Amazon
Para manter as coisas simples, adotaremos uma abordagem passo a passo para escrever o código. Sinta-se à vontade para trabalhar em paralelo com o guia.
Procure os dados que precisamos
Então, aqui está um cenário: estou me mudando em alguns meses para um novo lugar, e precisarei de algumas prateleiras novas para guardar livros e revistas. Quero conhecer todas as minhas opções e fazer o melhor negócio possível. Então, vamos ao mercado da Amazônia, procurar por “prateleiras” e ver o que conseguimos.
O URL para esta pesquisa e a página que vamos extrair estão aqui.
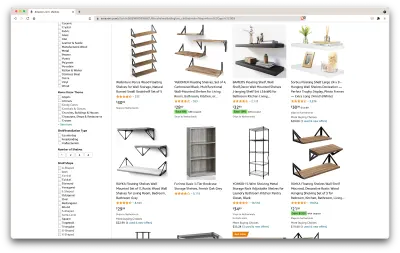
Ok, vamos fazer um balanço do que temos aqui. Apenas olhando para a página, podemos obter uma boa imagem sobre:
- como as prateleiras parecem;
- o que o pacote inclui;
- como os clientes os avaliam;
- seu preço;
- o link para o produto;
- uma sugestão de alternativa mais barata para alguns dos itens.
Isso é mais do que poderíamos pedir!
Obtenha as ferramentas necessárias
Vamos garantir que todas as ferramentas a seguir estejam instaladas e configuradas antes de prosseguir para a próxima etapa.
- cromada
Podemos baixá-lo daqui. - Código VS
Siga as instruções nesta página para instalá-lo em seu dispositivo específico. - Node.js
Antes de começar a usar o Axios ou o Cheerio, precisamos instalar o Node.js e o Node Package Manager. A maneira mais fácil de instalar o Node.js e o NPM é obter um dos instaladores da fonte oficial do Node.Js e executá-lo.
Agora, vamos criar um novo projeto NPM. Crie uma nova pasta para o projeto e execute o seguinte comando:
npm init -yPara criar o web scraper, precisamos instalar algumas dependências em nosso projeto:
- Cheerio
Uma biblioteca de código aberto que nos ajuda a extrair informações úteis analisando a marcação e fornecendo uma API para manipular os dados resultantes. Cheerio nos permite selecionar tags de um documento HTML usando seletores:$("div"). Esse seletor específico nos ajuda a escolher todos os elementos<div>em uma página. Para instalar o Cheerio, execute o seguinte comando na pasta dos projetos:
npm install cheerio- Axios
Uma biblioteca JavaScript usada para fazer solicitações HTTP do Node.js.
npm install axiosInspecione a origem da página
Nas etapas a seguir, aprenderemos mais sobre como as informações são organizadas na página. A ideia é entender melhor o que podemos extrair de nossa fonte.
As ferramentas do desenvolvedor nos ajudam a explorar interativamente o Document Object Model (DOM) do site. Usaremos as ferramentas do desenvolvedor no Chrome, mas você pode usar qualquer navegador da Web com o qual se sinta confortável.
Vamos abri-lo clicando com o botão direito do mouse em qualquer lugar da página e selecionando a opção “Inspecionar”:
Isso abrirá uma nova janela contendo o código-fonte da página. Como dissemos antes, estamos procurando raspar as informações de todas as prateleiras.
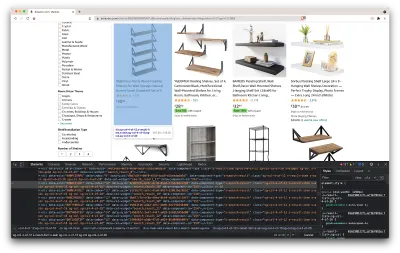
Como podemos ver na captura de tela acima, os contêineres que contêm todos os dados têm as seguintes classes:
sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20Na próxima etapa, usaremos o Cheerio para selecionar todos os elementos que contêm os dados que precisamos.

Busque os dados
Após instalarmos todas as dependências apresentadas acima, vamos criar um novo arquivo index.js e digitar as seguintes linhas de código:
const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { try { const response = await axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = response.data; const $ = cheerio.load(html); const shelves = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20').each((_idx, el) => { const shelf = $(el) const title = shelf.find('span.a-size-base-plus.a-color-base.a-text-normal').text() shelves.push(title) }); return shelves; } catch (error) { throw error; } }; fetchShelves().then((shelves) => console.log(shelves)); Como podemos ver, importamos as dependências que precisamos nas duas primeiras linhas e, em seguida, criamos uma função fetchShelves() que, usando Cheerio, obtém todos os elementos que contêm informações de nossos produtos da página.
Ele itera sobre cada um deles e o envia para um array vazio para obter um resultado melhor formatado.
A função fetchShelves() retornará apenas o título do produto no momento, então vamos pegar o restante das informações que precisamos. Por favor, adicione as seguintes linhas de código após a linha onde definimos a variável title .
const image = shelf.find('img.s-image').attr('src') const link = shelf.find('aa-link-normal.a-text-normal').attr('href') const reviews = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last().attr('aria-label') const stars = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') const price = shelf.find('span.a-price > span.a-offscreen').text() let element = { title, image, link: `https://amazon.com${link}`, price, } if (reviews) { element.reviews = reviews } if (stars) { element.stars = stars } E substitua shelves.push(title) por shelves.push(element) .
Agora estamos selecionando todas as informações de que precisamos e adicionando-as a um novo objeto chamado element . Cada elemento é então enviado para a matriz de shelves para obter uma lista de objetos contendo apenas os dados que estamos procurando.
É assim que um objeto de shelf deve se parecer antes de ser adicionado à nossa lista:
{ title: 'SUPERJARE Wall Mounted Shelves, Set of 2, Display Ledge, Storage Rack for Room/Kitchen/Office - White', image: 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', link: 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating-Shelves-Display%2Fdp%2FB07H4NRT36%2Fref%3Dsr_1_59_sspa%3Fcrid%3D36QNR0DBY6M7J%26dchild%3D1%26keywords%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26psc%3D1&qualifier=1627970918&id=3373422987100422&widgetName=sp_btf', price: '$32.99', reviews: '6,171', stars: '4.7 out of 5 stars' }Formate os dados
Agora que conseguimos buscar os dados de que precisamos, é uma boa ideia salvá-los como um arquivo .CSV para melhorar a legibilidade. Após obter todos os dados, usaremos o módulo fs fornecido pelo Node.js e salvaremos um novo arquivo chamado saved-shelves.csv na pasta do projeto. Importe o módulo fs na parte superior do arquivo e copie ou escreva nas seguintes linhas de código:
let csvContent = shelves.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("\n") fs.writeFile('saved-shelves.csv', "Title, Image, Link, Price, Reviews, Stars" + '\n' + csvContent, 'utf8', function (err) { if (err) { console.log('Some error occurred - file either not saved or corrupted.') } else{ console.log('File has been saved!') } }) Como podemos ver, nas três primeiras linhas, formatamos os dados que reunimos anteriormente juntando todos os valores de um objeto shelve usando uma vírgula. Em seguida, usando o módulo fs , criamos um arquivo chamado saved-shelves.csv , adicionamos uma nova linha que contém os cabeçalhos das colunas, adicionamos os dados que acabamos de formatar e criamos uma função de retorno de chamada que trata os erros.
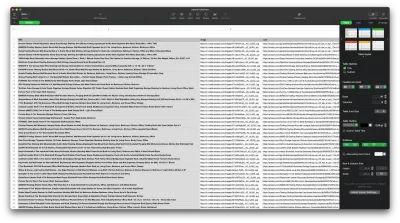
O resultado deve ser algo assim:
Dicas de bônus!
Raspagem de aplicativos de página única
O conteúdo dinâmico está se tornando o padrão hoje em dia, pois os sites estão mais complexos do que nunca. Para fornecer a melhor experiência possível ao usuário, os desenvolvedores devem adotar diferentes mecanismos de carregamento de conteúdo dinâmico , tornando nosso trabalho um pouco mais complicado. Se você não sabe o que isso significa, imagine um navegador sem uma interface gráfica de usuário. Felizmente, existe o Puppeteer — a biblioteca mágica do Node que fornece uma API de alto nível para controlar uma instância do Chrome pelo protocolo DevTools. Ainda assim, ele oferece a mesma funcionalidade de um navegador, mas deve ser controlado programaticamente digitando algumas linhas de código. Vamos ver como isso funciona.
No projeto criado anteriormente, instale a biblioteca Puppeteer executando npm install puppeteer , crie um novo arquivo puppeteer.js e copie ou escreva nas seguintes linhas de código:
const puppeteer = require('puppeteer') (async () => { try { const chrome = await puppeteer.launch() const page = await chrome.newPage() await page.goto('https://www.reddit.com/r/Kanye/hot/') await page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout: 2000 }) const body = await page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(body) await chrome.close() } catch (error) { console.log(error) } })() No exemplo acima, criamos uma instância do Chrome e abrimos uma nova página do navegador que é necessária para acessar este link. Na linha a seguir, dizemos ao navegador headless para esperar até que o elemento com a classe rpBJOHq2PR60pnwJlUyP0 apareça na página. Também especificamos quanto tempo o navegador deve esperar para carregar a página (2000 milissegundos).
Usando o método de evaluate na variável de page , instruímos o Puppeteer a executar os trechos de Javascript dentro do contexto da página logo após o elemento ser finalmente carregado. Isso nos permitirá acessar o conteúdo HTML da página e retornar o corpo da página como saída. Em seguida, fechamos a instância do Chrome chamando o método close na variável chrome . O trabalho resultante deve consistir em todo o código HTML gerado dinamicamente. É assim que o Puppeteer pode nos ajudar a carregar conteúdo HTML dinâmico .
Se você não se sentir confortável usando o Puppeteer, observe que existem algumas alternativas, como NightwatchJS, NightmareJS ou CasperJS. Eles são um pouco diferentes, mas no final, o processo é bastante semelhante.
Definindo cabeçalhos user-agent
user-agent é um cabeçalho de solicitação que informa ao site que você está visitando sobre você, ou seja, seu navegador e sistema operacional. Isso é usado para otimizar o conteúdo para sua configuração, mas os sites também o usam para identificar bots enviando toneladas de solicitações - mesmo que altere o IPS.
Veja como é um cabeçalho user-agent :
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36Para não ser detectado e bloqueado, você deve alterar regularmente este cabeçalho. Tome cuidado extra para não enviar um cabeçalho vazio ou desatualizado, pois isso nunca deve acontecer para um usuário comum, e você se destacará.
Limitação de taxa
Os raspadores da Web podem coletar conteúdo extremamente rápido, mas você deve evitar ir na velocidade máxima. Há duas razões para isso:
- Muitas solicitações em pouco tempo podem tornar o servidor do site lento ou até mesmo derrubá-lo, causando problemas para o proprietário e outros visitantes. Ele pode se tornar essencialmente um ataque DoS.
- Sem proxies rotativos, é como anunciar em voz alta que você está usando um bot , já que nenhum humano enviaria centenas ou milhares de solicitações por segundo.
A solução é introduzir um atraso entre suas solicitações, uma prática chamada de “limitação de taxa”. ( É bem simples de implementar também! )
No exemplo do Puppeteer fornecido acima, antes de criar a variável body , podemos usar o método waitForTimeout fornecido pelo Puppeteer para aguardar alguns segundos antes de fazer outra solicitação:
await page.waitForTimeout(3000); Onde ms é o número de segundos que você gostaria de esperar.
Além disso, se quisermos fazer o mesmo para o exemplo axios, podemos criar uma promessa que chama o método setTimeout() , para nos ajudar a esperar o número desejado de milissegundos:
fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))Dessa forma, você pode evitar colocar muita pressão no servidor de destino e também trazer uma abordagem mais humana para a raspagem da web.
Considerações finais
E aí está, um guia passo a passo para criar seu próprio web scraper para dados de produtos da Amazon! Mas lembre-se, esta foi apenas uma situação. Se você quiser raspar um site diferente, precisará fazer alguns ajustes para obter resultados significativos.
Leitura Relacionada
Se você ainda quiser ver mais web scraping em ação, aqui está algum material de leitura útil para você:
- “O guia definitivo para Web Scraping com JavaScript e Node.Js”, Robert Sfichi
- “Raspagem avançada da Web Node.JS com marionetista”, Gabriel Cioci
- “Python Web Scraping: O melhor guia para construir seu raspador”, Raluca Penciuc