
Crie um aplicativo de bookmarking com FaunaDB, Netlify e 11ty
Publicados: 2022-03-10A revolução do JAMstack (JavaScript, APIs e Markup) está a todo vapor. Sites estáticos são seguros, rápidos, confiáveis e divertidos de trabalhar. No centro do JAMstack estão os geradores de sites estáticos (SSGs) que armazenam seus dados como arquivos simples: Markdown, YAML, JSON, HTML e assim por diante. Às vezes, gerenciar dados dessa maneira pode ser excessivamente complicado. Às vezes, ainda precisamos de um banco de dados.
Com isso em mente, o Netlify — um host de site estático e o FaunaDB — um banco de dados em nuvem sem servidor — colaboraram para facilitar a combinação de ambos os sistemas.
Por que um site de favoritos?
O JAMstack é ótimo para muitos usos profissionais, mas um dos meus aspectos favoritos desse conjunto de tecnologia é sua baixa barreira de entrada para ferramentas e projetos pessoais.
Existem muitos produtos bons no mercado para a maioria das aplicações que eu poderia criar, mas nenhum seria exatamente configurado para mim. Nenhum me daria controle total sobre meu conteúdo. Nenhum viria sem um custo (monetário ou informativo).
Com isso em mente, podemos criar nossos próprios mini-serviços usando métodos JAMstack. Nesse caso, criaremos um site para armazenar e publicar quaisquer artigos interessantes que encontrar em minhas leituras diárias de tecnologia.
Passo muito tempo lendo artigos que foram compartilhados no Twitter. Quando gosto de um, clico no ícone "coração". Então, dentro de alguns dias, é quase impossível encontrar com o influxo de novos favoritos. Eu quero construir algo tão próximo da facilidade do “coração”, mas que eu possuo e controle.
Como vamos fazer isso? Estou feliz que você perguntou.
Interessado em obter o código? Você pode pegá-lo no Github ou simplesmente implantar diretamente no Netlify desse repositório! Veja aqui o produto final.
Nossas tecnologias
Funções de hospedagem e sem servidor: Netlify
Para funções de hospedagem e sem servidor, usaremos o Netlify. Como um bônus adicional, com a nova colaboração mencionada acima, a CLI da Netlify — “Netlify Dev” — se conectará automaticamente ao FaunaDB e armazenará nossas chaves de API como variáveis de ambiente.
Banco de dados: FaunaDB
O FaunaDB é um banco de dados NoSQL “sem servidor”. Nós o usaremos para armazenar nossos dados de favoritos.
Gerador de Site Estático: 11ty
Eu sou um grande crente em HTML. Por causa disso, o tutorial não usará JavaScript de front-end para renderizar nossos favoritos. Em vez disso, usaremos o 11ty como um gerador de site estático. O 11ty possui uma funcionalidade de dados integrada que torna a busca de dados de uma API tão fácil quanto escrever algumas funções JavaScript curtas.
Atalhos do iOS
Precisaremos de uma maneira fácil de postar dados em nosso banco de dados. Nesse caso, usaremos o aplicativo Atalhos do iOS. Isso também pode ser convertido em um bookmarklet JavaScript para Android ou desktop.
Configurando o FaunaDB via Netlify Dev
Se você já se inscreveu no FaunaDB ou precisa criar uma nova conta, a maneira mais fácil de configurar um link entre o FaunaDB e o Netlify é através da CLI do Netlify: Netlify Dev. Você pode encontrar instruções completas do FaunaDB aqui ou seguir abaixo.
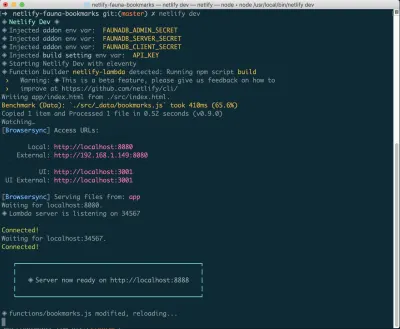
Se você ainda não tem isso instalado, você pode executar o seguinte comando no Terminal:
npm install netlify-cli -gDe dentro do diretório do seu projeto, execute os seguintes comandos:
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account Quando tudo estiver conectado, você poderá executar netlify dev em seu projeto. Isso executará todos os scripts de compilação que configurarmos, mas também se conectará aos serviços Netlify e FaunaDB e obterá todas as variáveis de ambiente necessárias. Prático!
Criando nossos primeiros dados
A partir daqui, faremos login no FaunaDB e criaremos nosso primeiro conjunto de dados. Começaremos criando um novo banco de dados chamado “bookmarks”. Dentro de um Banco de Dados, temos Coleções, Documentos e Índices.
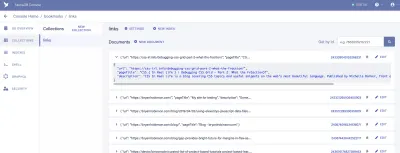
Uma coleção é um grupo categorizado de dados. Cada parte dos dados assume a forma de um Documento. Um Documento é um “registro único e mutável dentro de um banco de dados FaunaDB”, de acordo com a documentação da Fauna. Você pode pensar em Collections como uma tabela de banco de dados tradicional e em um Document como uma linha.
Para nosso aplicativo, precisamos de uma coleção, que chamaremos de “links”. Cada documento dentro da coleção “links” será um objeto JSON simples com três propriedades. Para começar, adicionaremos um novo Documento que usaremos para construir nossa primeira busca de dados.
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }Isso cria a base para as informações que precisaremos extrair de nossos favoritos, bem como nos fornece nosso primeiro conjunto de dados para extrair em nosso modelo.
Se você é como eu, você quer ver os frutos do seu trabalho imediatamente. Vamos colocar algo na página!
Instalando 11ty e puxando dados para um modelo
Como queremos que os favoritos sejam renderizados em HTML e não buscados pelo navegador, precisaremos de algo para fazer a renderização. Existem muitas maneiras excelentes de fazer isso, mas para facilidade e poder, adoro usar o gerador de site estático 11ty.
Como o 11ty é um gerador de site estático JavaScript, podemos instalá-lo via NPM.
npm install --save @11ty/eleventy A partir dessa instalação, podemos executar eleventy ou eleventy --serve em nosso projeto para começar a funcionar.
O Netlify Dev geralmente detecta o 11ty como um requisito e executa o comando para nós. Para que isso funcione - e tenha certeza de que estamos prontos para implantar, também podemos criar comandos "serve" e "build" em nosso package.json .
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }Arquivos de dados do 11ty
A maioria dos geradores de sites estáticos tem uma ideia de um “arquivo de dados” embutido. Normalmente, esses arquivos serão arquivos JSON ou YAML que permitem adicionar informações extras ao seu site.
No 11ty, você pode usar arquivos de dados JSON ou arquivos de dados JavaScript. Ao utilizar um arquivo JavaScript, podemos realmente fazer nossas chamadas de API e retornar os dados diretamente para um modelo.
Por padrão, 11ty quer arquivos de dados armazenados em um diretório _data . Você pode acessar os dados usando o nome do arquivo como uma variável em seus modelos. No nosso caso, vamos criar um arquivo em _data/bookmarks.js e acessá-lo por meio do nome da variável {{ bookmarks }} .
Se você quiser se aprofundar na configuração do arquivo de dados, leia os exemplos na documentação do 11ty ou confira este tutorial sobre como usar arquivos de dados do 11ty com a API Meetup.
O arquivo será um módulo JavaScript. Portanto, para que qualquer coisa funcione, precisamos exportar nossos dados ou uma função. No nosso caso, vamos exportar uma função.
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } Vamos quebrar isso. Temos duas funções fazendo nosso trabalho principal aqui: mapBookmarks() e getBookmarks() .
A função getBookmarks() irá buscar nossos dados do nosso banco de dados FaunaDB e mapBookmarks() irá pegar um array de marcadores e reestruturar para funcionar melhor para nosso template.
Vamos nos aprofundar em getBookmarks() .
getBookmarks()
Primeiro, precisaremos instalar e inicializar uma instância do driver JavaScript FaunaDB.
npm install --save faunadbAgora que o instalamos, vamos adicioná-lo ao topo do nosso arquivo de dados. Este código é direto dos documentos da Fauna.
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); Depois disso, podemos criar nossa função. Começaremos construindo nossa primeira consulta usando métodos integrados no driver. Este primeiro pedaço de código retornará as referências de banco de dados que podemos usar para obter dados completos para todos os nossos links favoritos. Usamos o método Paginate , como auxiliar para gerenciar o estado do cursor, caso decidamos paginar os dados antes de entregá-los a 11ty. No nosso caso, apenas retornaremos todas as referências.
Neste exemplo, estou assumindo que você instalou e conectou o FaunaDB por meio da CLI do Netlify Dev. Usando esse processo, você obtém variáveis de ambiente locais dos segredos do FaunaDB. Se você não o instalou dessa maneira ou não está executando o netlify dev em seu projeto, você precisará de um pacote como dotenv para criar as variáveis de ambiente. Você também precisará adicionar suas variáveis de ambiente à configuração do site Netlify para que as implantações funcionem mais tarde.
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })Este código retornará um array de todos os nossos links em forma de referência. Agora podemos construir uma lista de consultas para enviar ao nosso banco de dados.
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) A partir daqui, só precisamos limpar os dados retornados. É aí que mapBookmarks() !
mapBookmarks()
Nesta função, lidamos com dois aspectos dos dados.
Primeiro, obtemos um dateTime gratuito no FaunaDB. Para qualquer dado criado, há uma propriedade timestamp ( ts ). Não está formatado de uma maneira que deixe o filtro de data padrão do Liquid feliz, então vamos corrigir isso.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } Com isso fora do caminho, podemos construir um novo objeto para nossos dados. Nesse caso, ele terá uma propriedade de time e usaremos o operador Spread para desestruturar nosso objeto de data para torná-los todos vivos em um nível.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }Aqui estão nossos dados antes de nossa função:
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }Aqui estão nossos dados após nossa função:

{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }Agora, temos dados bem formatados que estão prontos para o nosso modelo!
Vamos escrever um modelo simples. Vamos percorrer nossos favoritos e validar que cada um tem um pageTitle e um url para que não pareçamos bobos.
<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>Agora estamos ingerindo e exibindo dados do FaunaDB. Vamos parar um momento e pensar em como é bom que isso renderize HTML puro e não há necessidade de buscar dados no lado do cliente!
Mas isso não é realmente suficiente para tornar este um aplicativo útil para nós. Vamos descobrir uma maneira melhor do que adicionar um marcador no console do FaunaDB.
Entre nas funções do Netlify
O complemento Functions da Netlify é uma das maneiras mais fáceis de implantar funções lambda da AWS. Como não há etapa de configuração, é perfeito para projetos de bricolage em que você deseja apenas escrever o código.
Essa função ficará em uma URL em seu projeto que se parece com isso: https://myproject.com/.netlify/functions/bookmarks assumindo que o arquivo que criamos em nossa pasta de funções é bookmarks.js .
Fluxo Básico
- Passe um URL como parâmetro de consulta para nosso URL de função.
- Use a função para carregar o URL e extrair o título e a descrição da página, se disponível.
- Formate os detalhes do FaunaDB.
- Envie os detalhes para nossa coleção FaunaDB.
- Reconstrua o site.
Requisitos
Temos alguns pacotes que precisaremos enquanto construímos isso. Usaremos a CLI netlify-lambda para construir nossas funções localmente. request-promise é o pacote que usaremos para fazer solicitações. Cheerio.js é o pacote que usaremos para extrair itens específicos de nossa página solicitada (pense em jQuery para Node). E por fim, precisaremos do FaunaDb (que já deve estar instalado.
npm install --save netlify-lambda request-promise cheerioUma vez instalado, vamos configurar nosso projeto para construir e servir as funções localmente.
Modificaremos nossos scripts “build” e “serve” em nosso package.json para ficar assim:
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } Atenção: Há um erro com o driver NodeJS do Fauna ao compilar com o Webpack, que as Funções do Netlify usam para compilar. Para contornar isso, precisamos definir um arquivo de configuração para o Webpack. Você pode salvar o código a seguir em um novo — ou existente — webpack.config.js .
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; Uma vez que esse arquivo exista, quando usarmos o comando netlify-lambda , precisaremos dizer a ele para ser executado a partir dessa configuração. É por isso que nossos scripts “serve” e “build usam o valor --config para esse comando.
Função Limpeza
Para manter nosso arquivo de função principal o mais limpo possível, criaremos nossas funções em um diretório de bookmarks separado e as importaremos para nosso arquivo de função principal.
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
A função getDetails() um URL, passado de nosso manipulador exportado. A partir daí, acessaremos o site nesse URL e pegaremos partes relevantes da página para armazenar como dados para nosso favorito.
Começamos exigindo os pacotes NPM que precisamos:
const rp = require('request-promise'); const cheerio = require('cheerio'); Em seguida, usaremos o módulo request-promise para retornar uma string HTML para a página solicitada e passá-la para o cheerio para nos dar uma interface muito parecida com o jQuery.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }A partir daqui, precisamos obter o título da página e uma meta descrição. Para fazer isso, usaremos seletores como você faria no jQuery.
Nota: Neste código, usamos 'head > title' como seletor para obter o título da página. Se você não especificar isso, pode acabar recebendo tags <title> dentro de todos os SVGs na página, o que é menos que o ideal.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }Com os dados em mãos, é hora de enviar nosso marcador para nossa Coleção no FaunaDB!
saveBookmark(details)
Para nossa função save, queremos passar os detalhes que adquirimos de getDetails , bem como a URL como um objeto singular. O operador Spread ataca novamente!
const savedResponse = await saveBookmark({url, ...details}); Em nosso arquivo create.js , também precisamos exigir e configurar nosso driver FaunaDB. Isso deve parecer muito familiar em nosso arquivo de dados 11ty.
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });Assim que tirarmos isso do caminho, podemos codificar.
Primeiro, precisamos formatar nossos detalhes em uma estrutura de dados que o Fauna espera para nossa consulta. Fauna espera um objeto com uma propriedade de dados contendo os dados que desejamos armazenar.
const saveBookmark = async function(details) { const data = { data: details }; ... }Em seguida, abriremos uma nova consulta para adicionar à nossa coleção. Nesse caso, usaremos nosso auxiliar de consulta e usaremos o método Create. Create() recebe dois argumentos. A primeira é a coleção na qual queremos armazenar nossos dados e a segunda são os próprios dados.
Depois de salvar, retornamos sucesso ou falha ao nosso manipulador.
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }Vamos dar uma olhada no arquivo Function completo.
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
O olho perspicaz notará que temos mais uma função importada para nosso manipulador: rebuildSite() . Essa função usará a funcionalidade Deploy Hook do Netlify para reconstruir nosso site a partir dos novos dados toda vez que enviarmos um novo — bem-sucedido — salvamento de favoritos.
Nas configurações do seu site no Netlify, você pode acessar suas configurações de Build & Deploy e criar um novo “Build Hook”. Hooks têm um nome que aparece na seção Deploy e uma opção para uma ramificação não-mestre a ser implantada, se assim o desejar. No nosso caso, vamos chamá-lo de “new_link” e implantar nosso branch master.
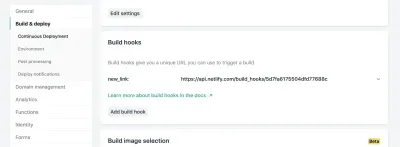
A partir daí, basta enviar uma solicitação POST para a URL fornecida.
Precisamos de uma maneira de fazer solicitações e, como já instalamos request-promise , continuaremos a usar esse pacote exigindo-o no topo do nosso arquivo.
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } Configurando um atalho para iOS
Então, temos um banco de dados, uma maneira de exibir dados e uma função para adicionar dados, mas ainda não somos muito amigáveis.
A Netlify fornece URLs para nossas funções do Lambda, mas elas não são divertidas de digitar em um dispositivo móvel. Também teríamos que passar um URL como parâmetro de consulta para ele. Isso é MUITO esforço. Como podemos fazer isso com o menor esforço possível?
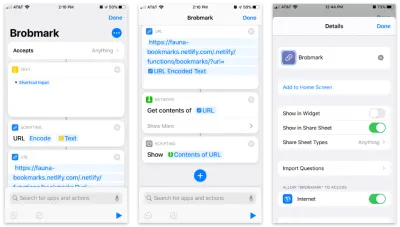
O aplicativo Atalhos da Apple permite a criação de itens personalizados para entrar em sua planilha de compartilhamento. Dentro desses atalhos, podemos enviar vários tipos de solicitações de dados coletados no processo de compartilhamento.
Aqui está o atalho passo a passo:
- Aceite quaisquer itens e armazene esse item em um bloco de “texto”.
- Passe esse texto em um bloco “Scripting” para codificação de URL (apenas no caso).
- Passe essa string para um bloco de URL com a URL da nossa função Netlify e um parâmetro de consulta de
url. - De “Network” use um bloco “Get contents” para POST para JSON para nosso URL.
- Opcional: De “Scripting” “Mostrar” o conteúdo do último passo (para confirmar os dados que estamos enviando).
Para acessar isso no menu de compartilhamento, abrimos as configurações deste atalho e ativamos a opção “Mostrar na planilha de compartilhamento”.
A partir do iOS13, essas “Ações” de compartilhamento podem ser favoritadas e movidas para uma posição alta na caixa de diálogo.
Agora temos um "aplicativo" funcional para compartilhar marcadores em várias plataformas!
Superar as expectativas!
Se você está inspirado para tentar isso sozinho, há muitas outras possibilidades para adicionar funcionalidade. A alegria da web DIY é que você pode fazer com que esses tipos de aplicativos funcionem para você. Aqui estão algumas ideias:
- Use uma falsa “chave de API” para autenticação rápida, para que outros usuários não postem no seu site (o meu usa uma chave de API, então não tente postar nele!).
- Adicione funcionalidade de tag para organizar marcadores.
- Adicione um feed RSS ao seu site para que outras pessoas possam se inscrever.
- Envie um e-mail de resumo semanal programaticamente para os links que você adicionou.
Realmente, o céu é o limite, então comece a experimentar!