
Distribuição binomial em Python com exemplos do mundo real [2022]
Publicados: 2021-01-09O valor da probabilidade e da estatística no campo da ciência de dados tem sido imenso, com inteligência artificial e aprendizado de máquina dependendo fortemente deles. Estamos usando modelos de processo de distribuição normal toda vez que realizamos testes A/B e modelagem de investimento.
No entanto, a distribuição binomial em Python é aplicada de várias maneiras para realizar vários processos. Mas, antes de começar com a distribuição binomial em Python , você precisa conhecer a distribuição binomial em geral e seu uso no dia a dia. Se você é iniciante e está interessado em aprender mais sobre ciência de dados, confira nosso treinamento em ciência de dados das melhores universidades.
Índice
O que é a Distribuição Binomial ?
Você já jogou uma moeda? Se você tiver, então você deve saber que a probabilidade de obter cara ou coroa é igual. Mas, e quanto à probabilidade de obter sete coroas no total de dez lançamentos de uma moeda? É aqui que a distribuição binomial pode ajudar a calcular os resultados de cada lançamento e, assim, descobrir a probabilidade de obter sete coroas para dez lançamentos de uma moeda.
O cerne da distribuição de probabilidade vem da variância de qualquer evento. Para cada dez jogadas de moedas, a probabilidade de obter cara e coroa pode ser de uma a dez vezes, igualmente e provável. A incerteza no resultado (também conhecida como variância) ajuda a gerar a distribuição dos resultados produzidos.
Em outras palavras, a distribuição binomial é um processo onde existem apenas dois resultados possíveis: verdadeiro ou falso. Portanto, tem uma probabilidade igual de ambos os resultados em todos os eventos, pois as mesmas ações são executadas a cada vez. Há apenas uma condição... As etapas não precisam ser completamente afetadas umas pelas outras, e os resultados podem ou não ser igualmente prováveis.
Portanto, a função de probabilidade de uma distribuição binomial é:
f f( k k , n n, p p) = P r Pr( k k; n n, p p) = P r Pr ( X X= k k) =
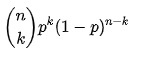
Fonte
Onde,
![]() = n ! k k !( n n!- k k!)
= n ! k k !( n n!- k k!)
Aqui, n = número total de tentativas
p = probabilidade de sucesso
k = número alvo de sucessos
Distribuição Binomial em Python
Para distribuição binomial via Python, você pode produzir a variável aleatória distinta da função binom.rvs(), onde 'n' é definido como a frequência total de tentativas e 'p' é igual à probabilidade de sucesso.
Você também pode mover a distribuição usando a função loc, e o tamanho define a frequência de uma ação que se repete na série. Adicionar um random_state pode ajudar a manter a reprodutibilidade.
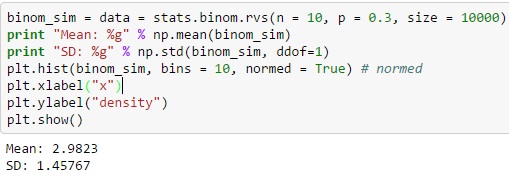
Fonte
Exemplos do mundo real de distribuição binomial em Python
Existem muito mais eventos (maiores que lançamentos de moedas) que podem ser abordados pela distribuição binomial em Python. Alguns dos casos de uso podem ajudar a rastrear e melhorar o ROI (retorno sobre investimentos) para grandes e pequenas empresas. Veja como:

- Pense em um call center onde cada funcionário recebe em média 50 ligações por dia.
- A probabilidade de conversão em cada chamada é igual a 4%.
- A geração média de receita para a empresa com base em cada conversão é de US$ 20.
- Se você analisar 100 desses funcionários, que recebem US$ 200 por dia, então
n = 50
p = 4%
O código pode gerar saída da seguinte forma:
- Taxa média de conversão para cada funcionário = 2,13
- O desvio padrão das conversões para cada equipe de call center = 1,48
- Conversão bruta = 213
- Geração de receita bruta = USD 21.300
- Despesa bruta = USD 20.000
- Lucro bruto = USD 1.300
Modelos de distribuição binomial e outras distribuições de probabilidade só podem prever uma aproximação que pode se aproximar do mundo real em termos dos parâmetros de ação, 'n' e 'p'. Isso nos ajuda a entender e identificar nossas áreas de foco e melhorar as chances gerais de melhor desempenho e eficácia.
Leia também: 13 ideias e tópicos interessantes de projetos de estrutura de dados para iniciantes
Qual o proximo?
Se você está curioso para aprender sobre ciência de dados, confira o Programa PG Executivo em Ciência de Dados do IIIT-B & upGrad, que é criado para profissionais que trabalham e oferece mais de 10 estudos de caso e projetos, workshops práticos práticos, orientação com especialistas do setor, 1 -on-1 com mentores do setor, mais de 400 horas de aprendizado e assistência de trabalho com as principais empresas.
Qual é a diferença entre distribuição de probabilidade discreta e distribuição de probabilidade contínua?
A distribuição de probabilidade discreta ou simplesmente distribuição discreta calcula as probabilidades de uma variável aleatória que pode ser discreta. Por exemplo, se lançarmos uma moeda duas vezes, os valores prováveis de uma variável aleatória X que denota o número total de caras serão {0, 1, 2} e não qualquer valor aleatório. Bernoulli, Binomial, Hipergeométrica são alguns exemplos de distribuição de probabilidade discreta. Por outro lado, a distribuição de probabilidade contínua fornece as probabilidades de um valor aleatório que pode ser qualquer número aleatório. Por exemplo, o valor de uma variável aleatória X que denota a altura dos cidadãos de uma cidade pode ser qualquer número como 161,2, 150,9, etc. Normal, T de Student, Qui-quadrado são alguns exemplos de distribuição contínua.
Qual é o significado da probabilidade na ciência de dados?
Como a ciência de dados trata do estudo de dados, a probabilidade desempenha um papel fundamental aqui. As razões a seguir descrevem como a probabilidade é uma parte indispensável da ciência de dados: Ela ajuda analistas e pesquisadores a fazer previsões a partir de conjuntos de dados. Esses tipos de resultados estimados são a base para uma análise mais aprofundada dos dados. A probabilidade também é usada durante o desenvolvimento de algoritmos usados em modelos de aprendizado de máquina. Ele ajuda a analisar os conjuntos de dados usados para treinar os modelos. Ele permite quantificar dados e derivar resultados como derivadas, média e distribuição. Todos os resultados obtidos usando a probabilidade eventualmente resumem os dados. Este resumo também ajuda na identificação de outliers existentes nos conjuntos de dados.
Explique a distribuição hipergeométrica. Em que caso tende a ser uma distribuição binomial?
sucessos sobre o número de tentativas sem qualquer substituição. Digamos que temos um saco cheio de bolas vermelhas e verdes e temos que encontrar a probabilidade de pegar uma bola verde em 5 tentativas, mas cada vez que pegamos uma bola, não a devolvemos ao saco. Este é um exemplo adequado da distribuição hipergeométrica.
Para N maior, é muito difícil calcular a distribuição hipergeométrica, mas quando N é pequeno, tende para a distribuição binomial neste caso.