Guia do Iniciante para Rede Neural Convolucional (CNN)
Publicados: 2021-07-05A última década viu um tremendo crescimento em Inteligência Artificial e máquinas mais inteligentes. O campo deu origem a muitas subdisciplinas que se especializam em aspectos distintos da inteligência humana. Por exemplo, o processamento de linguagem natural tenta entender e modelar a fala humana, enquanto a visão computacional visa fornecer visão humana às máquinas.
Já que falaremos sobre Redes Neurais Convolucionais, nosso foco será principalmente na visão computacional. A visão computacional visa permitir que as máquinas vejam o mundo como nós e resolvam problemas relacionados ao reconhecimento de imagens, classificação de imagens e muito mais. As Redes Neurais Convolucionais são usadas para realizar várias tarefas de visão computacional. Também conhecidos como CNN ou ConvNet, eles seguem uma arquitetura que lembra os padrões e conexões dos neurônios no cérebro humano e são inspirados em vários processos biológicos que ocorrem no cérebro para fazer a comunicação acontecer.
Índice
O significado biológico de uma rede neural complicada
As CNNs são inspiradas pelo nosso córtex visual. É a área do córtex cerebral que está envolvida no processamento visual em nosso cérebro. O córtex visual tem várias pequenas regiões celulares que são sensíveis a estímulos visuais.
Essa ideia foi expandida em 1962 por Hubel e Wiesel em um experimento em que se descobriu que diferentes células neuronais distintas respondem (são disparadas) à presença de bordas distintas de uma orientação específica. Por exemplo, alguns neurônios disparariam ao detectar bordas horizontais, outros ao detectar bordas diagonais e alguns outros disparariam ao detectar bordas verticais. Através deste experimento. Hubel e Wiesel descobriram que os neurônios são organizados de forma modular, e todos os módulos juntos são necessários para produzir a percepção visual.
Essa abordagem modular – a ideia de que componentes especializados dentro de um sistema têm tarefas específicas – é o que forma a base das CNNs.
Com isso resolvido, vamos passar para como as CNNs aprendem a perceber as entradas visuais.

Aprendizado de Rede Neural Convolucional
As imagens são compostas de pixels individuais, que é uma representação entre os números 0 e 255. Assim, qualquer imagem que você vê pode ser convertida em uma representação digital adequada usando esses números – e é assim que os computadores também trabalham com imagens.
Aqui estão algumas das principais operações que fazem uma CNN aprender para detecção ou classificação de imagens. Isso lhe dará uma ideia de como o aprendizado ocorre nas CNNs.
1. Convolução
Convolução pode ser matematicamente entendida como a integração combinada de duas funções diferentes para descobrir como a influência da função diferente ou modificar uma à outra. Veja como isso pode ser definido em termos matemáticos:
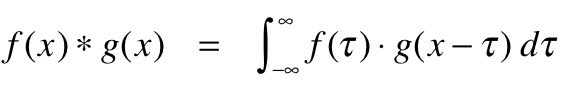
O objetivo da convolução é detectar diferentes recursos visuais nas imagens, como linhas, bordas, cores, sombras e muito mais. Esta é uma propriedade muito útil porque uma vez que sua CNN tenha aprendido as características de um determinado recurso na imagem, ele pode reconhecer esse recurso em qualquer outra parte da imagem.
CNNs utilizam kernels ou filtros para detectar os diferentes recursos que estão presentes em qualquer imagem. Kernels são apenas uma matriz de valores distintos (conhecidos como pesos no mundo das Redes Neurais Artificiais) treinados para detectar características específicas. O filtro percorre toda a imagem para verificar se a presença de algum recurso é detectada ou não. O filtro realiza a operação de convolução para fornecer um valor final que representa a confiança de que um determinado recurso está presente.
Se um recurso estiver presente na imagem, o resultado da operação de convolução será um número positivo com um valor alto. Se o recurso estiver ausente, a operação de convolução resultará em 0 ou em um número de valor muito baixo.
Vamos entender isso melhor usando um exemplo. Na imagem abaixo, um filtro foi treinado para detectar um sinal de mais. Em seguida, o filtro é passado sobre a imagem original. Como uma parte da imagem original contém os mesmos recursos para os quais o filtro é treinado, os valores em cada célula onde o recurso existe é um número positivo. Da mesma forma, o resultado de uma operação de convolução também resultará em um grande número.
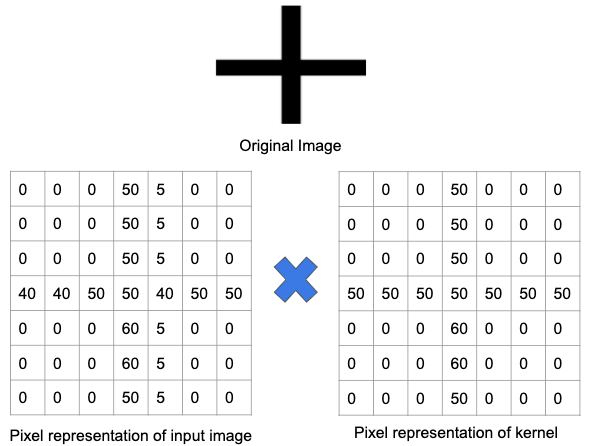
No entanto, quando o mesmo filtro é passado sobre uma imagem com um conjunto diferente de recursos e arestas, a saída de uma operação de convolução será menor – o que implica que não houve forte presença de nenhum sinal de mais na imagem.
Portanto, no caso de imagens complexas com vários recursos, como curvas, bordas, cores e assim por diante, precisaremos de um número N desses detectores de recursos.
Quando este filtro é passado pela imagem, é gerado um mapa de características que é basicamente a matriz de saída que armazena as circunvoluções deste filtro em diferentes partes da imagem. No caso de muitos filtros, acabaremos com uma saída 3D. Este filtro deve ter o mesmo número de canais que a imagem de entrada para que a operação de convolução ocorra.
Além disso, um filtro pode ser deslizado sobre a imagem de entrada em diferentes intervalos, usando um valor de passo. O valor do passo informa o quanto o filtro deve se mover a cada passo.
O número de camadas de saída de um determinado bloco convolucional pode, portanto, ser determinado usando a seguinte fórmula:

2. Preenchimento
Um problema ao trabalhar com camadas convolucionais é que alguns pixels tendem a ser perdidos no perímetro da imagem original. Como geralmente os filtros usados são pequenos, os pixels perdidos por filtro podem ser poucos, mas isso aumenta à medida que aplicamos diferentes camadas convolucionais, resultando em muitos pixels perdidos.
O conceito de preenchimento é adicionar pixels extras à imagem enquanto um filtro de uma CNN a processa. Esta é uma solução para ajudar o filtro no processamento da imagem – preenchendo a imagem com zeros para permitir mais espaço para o kernel cobrir toda a imagem. Ao adicionar zero paddings aos filtros, o processamento de imagem pela CNN é muito mais preciso e exato.
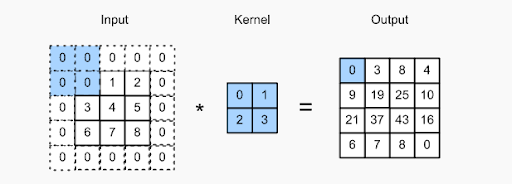

Verifique a imagem acima – o preenchimento foi feito adicionando zeros adicionais no limite da imagem de entrada. Isso permite a captura de todos os recursos distintos sem perder nenhum pixel.
3. Mapa de Ativação
Os mapas de recursos precisam ser passados por uma função de mapeamento que não seja linear por natureza. Os mapas de características são incluídos com um termo de polarização e, em seguida, passam pela função de ativação (ReLu), que é não linear. Esta função visa trazer alguma quantidade de não linearidade para a CNN, uma vez que as imagens que estão sendo detectadas e examinadas também são de natureza não linear, sendo compostas por diferentes objetos.
4. Estágio de Agrupamento
Quando a fase de ativação termina, passamos para a etapa de pooling, na qual a CNN reduz a amostragem dos recursos convolvidos, o que ajuda a economizar tempo de processamento. Isso também ajuda a reduzir o tamanho geral da imagem, overfitting e outros problemas que ocorreriam se as Redes Neurais Convolutas fossem alimentadas com muitas informações – especialmente se essas informações não forem muito relevantes na classificação ou detecção da imagem.
O pooling é basicamente de dois tipos - pooling máximo e pooling mínimo. No primeiro, uma janela é passada sobre a imagem de acordo com um valor de passo definido e, em cada etapa, o valor máximo incluído na janela é agrupado na matriz de saída. No agrupamento mínimo, os valores mínimos são agrupados na matriz de saída.
A nova matriz formada como resultado das saídas é chamada de mapa de recursos agrupados.
Fora do pool mínimo e máximo, um benefício do pool máximo é que ele permite que a CNN se concentre em alguns neurônios que tenham valores altos em vez de se concentrar em todos os neurônios. Essa abordagem torna muito menos provável o superajuste dos dados de treinamento e faz com que a previsão geral e a generalização funcionem bem.
5. Achatamento
Depois que o pooling é feito, a representação 3D da imagem agora foi convertida em um vetor de recursos. Este é então passado para um perceptron multicamada para produzir a saída. Confira a imagem abaixo para entender melhor a operação de achatamento:
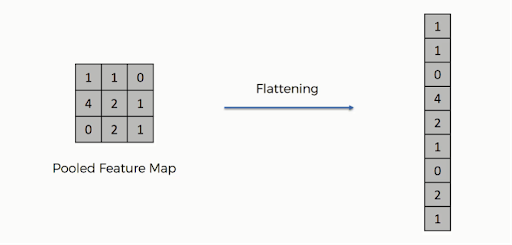
Como você pode ver, as linhas da matriz são concatenadas em um único vetor de recursos. Se várias camadas de entrada estiverem presentes, todas as linhas serão conectadas para formar um vetor de recurso achatado mais longo.
6. Camada Totalmente Conectada (FCL)
Nesta etapa, o mapa achatado é alimentado a uma rede neural. A conexão completa de uma rede neural inclui uma camada de entrada, a FCL, e uma camada de saída final. A camada totalmente conectada pode ser entendida como as camadas ocultas nas Redes Neurais Artificiais, exceto que, diferentemente das camadas ocultas, essas camadas são totalmente conectadas. As informações passam por toda a rede e um erro de previsão é calculado. Este erro é então enviado como feedback (backpropagation) através dos sistemas para ajustar os pesos e melhorar o resultado final, para torná-lo mais preciso.
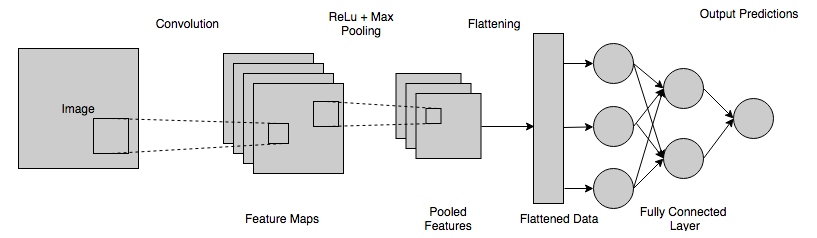
A saída final obtida da camada acima da rede neural geralmente não soma um. Essas saídas precisam ser reduzidas a números na faixa de [0,1] – que representarão as probabilidades de cada classe. Para isso, é utilizada a função Softmax.
A saída obtida da camada densa é alimentada à função de ativação Softmax. Através disso, todas as saídas finais são mapeadas para um vetor onde a soma de todos os elementos resulta em um.
A camada totalmente conectada funciona observando a saída da camada anterior e determinando qual recurso mais se correlaciona com uma classe específica. Assim, se o programa prever se uma imagem contém ou não um gato, ela terá valores altos nos mapas de ativação que representam características como quatro patas, patas, cauda e assim por diante. Da mesma forma, se o programa estiver prevendo outra coisa, ele terá diferentes tipos de mapas de ativação. Uma camada totalmente conectada cuida dos diferentes recursos que se correlacionam fortemente com classes e pesos específicos para que o cálculo entre os pesos e a camada anterior seja preciso e você obtenha probabilidades corretas para classes distintas de saída.
Um rápido resumo do funcionamento das CNNs
Aqui está um resumo rápido de todo o processo de como a CNN funciona e ajuda na visão computacional:
- Os diferentes pixels da imagem são alimentados na camada convolucional, onde é realizada uma operação de convolução.
- A etapa anterior resulta em um mapa convoluído.
- Este mapa é passado por uma função retificadora para dar origem a um mapa retificado.
- A imagem é processada com diferentes convoluções e funções de ativação para localizar e detectar diferentes recursos.
- As camadas de agrupamento são usadas para identificar partes específicas e distintas da imagem.
- A camada agrupada é achatada e usada como entrada para a camada totalmente conectada.
- A camada totalmente conectada calcula as probabilidades e fornece uma saída na faixa de [0,1].
Para concluir
O funcionamento interno da CNN é muito empolgante e abre muitas possibilidades de inovação e criação. Da mesma forma, outras tecnologias sob o guarda-chuva da Inteligência Artificial são fascinantes e estão tentando trabalhar entre as capacidades humanas e a inteligência da máquina. Consequentemente, pessoas de todo o mundo, pertencentes a diferentes domínios, estão percebendo seu interesse neste campo e estão dando os primeiros passos.
Felizmente, a indústria de IA é excepcionalmente acolhedora e não faz distinção com base em sua formação acadêmica. Tudo o que você precisa é de conhecimento prático das tecnologias, juntamente com qualificações básicas, e está tudo pronto!
Se você deseja dominar o âmago da questão de ML e IA, o curso de ação ideal seria se inscrever em um programa profissional de IA/ML. Por exemplo, nosso Programa Executivo em Aprendizado de Máquina e IA é o curso perfeito para aspirantes a ciência de dados. O programa abrange assuntos como estatísticas e análise exploratória de dados, aprendizado de máquina e processamento de linguagem natural. Além disso, inclui mais de 13 projetos do setor, mais de 25 sessões ao vivo e 6 projetos fundamentais. A melhor parte deste curso é que você pode interagir com colegas de todo o mundo. Facilita a troca de ideias e ajuda os alunos a construir conexões duradouras com pessoas de diversas origens. Nossa assistência profissional 360 graus é exatamente o que você precisa para se destacar em sua jornada de ML e IA!
Lidere a revolução tecnológica orientada por IA