
Teorema de Bayes em Aprendizado de Máquina: Introdução, Como Aplicar e Exemplo
Publicados: 2021-02-04Índice
Introdução: O que é o Teorema de Bayes?
O Teorema de Bayes recebeu esse nome em homenagem ao matemático inglês Thomas Bayes, que trabalhou extensivamente na teoria da decisão, o campo da matemática que envolve probabilidades. O Teorema de Bayes também é amplamente utilizado em aprendizado de máquina, onde é uma maneira simples e eficaz de prever classes com precisão e exatidão. O método Bayesiano de cálculo de probabilidades condicionais é usado em aplicativos de aprendizado de máquina que envolvem tarefas de classificação.
Uma versão simplificada do Teorema de Bayes, conhecida como Classificação Naive Bayes, é usada para reduzir o tempo e os custos de computação. Neste artigo, mostramos esses conceitos e discutimos as aplicações do Teorema de Bayes no aprendizado de máquina.
Participe do curso de aprendizado de máquina on-line das principais universidades do mundo - mestrados, programas de pós-graduação executiva e programa de certificação avançada em ML e IA para acelerar sua carreira.
Por que usar o Teorema de Bayes em Machine Learning?
O Teorema de Bayes é um método para determinar probabilidades condicionais – isto é, a probabilidade de um evento ocorrer dado que outro evento já ocorreu. Como uma probabilidade condicional inclui condições adicionais – em outras palavras, mais dados – ela pode contribuir para resultados mais precisos.
Assim, as probabilidades condicionais são essenciais para determinar previsões e probabilidades precisas em Machine Learning. Dado que o campo está se tornando cada vez mais onipresente em uma variedade de domínios, é importante entender o papel de algoritmos e métodos como o teorema de Bayes no aprendizado de máquina.
Antes de entrarmos no teorema em si, vamos entender alguns termos através de um exemplo. Digamos que um gerente de livraria tenha informações sobre a idade e a renda de seus clientes. Ele quer saber como as vendas de livros são distribuídas em três classes etárias de clientes: jovens (18-35), meia-idade (35-60) e idosos (60+).

Vamos chamar nossos dados de X. Na terminologia Bayesiana, X é chamado de evidência. Temos alguma hipótese H, onde temos algum X que pertence a uma certa classe C.
Nosso objetivo é determinar a probabilidade condicional de nossa hipótese H dado X, ou seja, P(H | X).
Em termos simples, determinando P(H | X), obtemos a probabilidade de X pertencer à classe C, dado X. X tem atributos de idade e renda – digamos, por exemplo, 26 anos com renda de $ 2.000. H é nossa hipótese de que o cliente comprará o livro.
Preste muita atenção aos quatro termos a seguir:
- Evidência – Conforme discutido anteriormente, P(X) é conhecido como evidência. É simplesmente a probabilidade de que o cliente, neste caso, tenha 26 anos, ganhando $ 2.000.
- Probabilidade Antecipada – P(H), conhecida como probabilidade a priori, é a probabilidade simples de nossa hipótese – ou seja, que o cliente comprará um livro. Essa probabilidade não será fornecida com nenhuma entrada extra com base na idade e na renda. Como o cálculo é feito com menos informações, o resultado é menos preciso.
- Probabilidade posterior – P(H | X) é conhecida como probabilidade posterior. Aqui, P(H | X) é a probabilidade do cliente comprar um livro (H) dado X (que ele tem 26 anos e ganha $ 2.000).
- Probabilidade – P(X | H) é a probabilidade de verossimilhança. Nesse caso, dado que sabemos que o cliente comprará o livro, a probabilidade de probabilidade é a probabilidade de o cliente ter 26 anos e uma renda de $ 2.000.
Dado isso, o Teorema de Bayes afirma:
P(H | X) = [ P(X | H) * P(H) ] / P(X)
Observe a aparência dos quatro termos acima no teorema – probabilidade posterior, probabilidade de verossimilhança, probabilidade anterior e evidência.
Leia: Naive Bayes explicado
Como aplicar o teorema de Bayes no aprendizado de máquina
O Classificador Naive Bayes, uma versão simplificada do Teorema de Bayes, é usado como algoritmo de classificação para classificar dados em várias classes com precisão e rapidez.
Vejamos como o Classificador Naive Bayes pode ser aplicado como algoritmo de classificação.
- Considere um exemplo geral: X é um vetor que consiste em 'n' atributos, ou seja, X = {x1, x2, x3, …, xn}.
- Digamos que temos 'm' classes {C1, C2, …, Cm}. Nosso classificador terá que prever que X pertence a uma determinada classe. A classe que apresentar a maior probabilidade posterior será escolhida como a melhor classe. Assim, matematicamente, o classificador irá prever para a classe Ci se P(Ci | X) > P(Cj | X). Aplicando o Teorema de Bayes:
P(Ci | X) = [ P(X | Ci) * P(Ci) ] / P(X)
- P(X), sendo independente da condição, é constante para cada classe. Então, para maximizar P(Ci | X), devemos maximizar [P(X | Ci) * P(Ci)]. Considerando que todas as classes são igualmente prováveis, temos P(C1) = P(C2) = P(C3) … = P(Cn). Então, em última análise, precisamos maximizar apenas P(X | Ci).
- Como é provável que o grande conjunto de dados típico tenha vários atributos, é computacionalmente caro realizar a operação P(X | Ci) para cada atributo. É aqui que entra a independência condicional de classe para simplificar o problema e reduzir os custos de computação. Por independência condicional de classe, queremos dizer que consideramos os valores do atributo independentes uns dos outros condicionalmente. Esta é a Classificação Naive Bayes.
P(Xi | C) = P(x1 | C) * P(x2 | C) *… * P(xn | C)
Agora é fácil calcular as probabilidades menores. Uma coisa importante a ser observada aqui: como xk pertence a cada atributo, também precisamos verificar se o atributo com o qual estamos lidando é categórico ou contínuo .
- Se tivermos um atributo categórico , as coisas são mais simples. Podemos apenas contar o número de instâncias da classe Ci consistindo no valor xk para o atributo k e então dividir isso pelo número de instâncias da classe Ci.
- Se tivermos um atributo contínuo, considerando que temos uma função de distribuição normal, aplicamos a seguinte fórmula, com média ? e desvio padrão?:
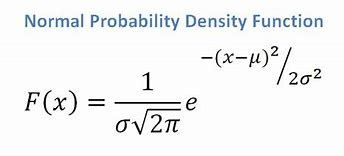

Fonte
Em última análise, teremos P(x | Ci) = F(xk, ?k, ?k).
- Agora, temos todos os valores necessários para usar o Teorema de Bayes para cada classe Ci. Nossa classe prevista será a classe que alcançará a maior probabilidade P(X | Ci) * P(Ci).
Exemplo: classificação preditiva de clientes de uma livraria
Temos o seguinte conjunto de dados de uma livraria:
| Idade | Renda | Aluna | Credit_Rating | Compras_Livro |
| Juventude | Alto | Não | Feira | Não |
| Juventude | Alto | Não | Excelente | Não |
| Meia-idade | Alto | Não | Feira | sim |
| Senior | Médio | Não | Feira | sim |
| Senior | Baixo | sim | Feira | sim |
| Senior | Baixo | sim | Excelente | Não |
| Meia-idade | Baixo | sim | Excelente | sim |
| Juventude | Médio | Não | Feira | Não |
| Juventude | Baixo | sim | Feira | sim |
| Senior | Médio | sim | Feira | sim |
| Juventude | Médio | sim | Excelente | sim |
| Meia-idade | Médio | Não | Excelente | sim |
| Meia-idade | Alto | sim | Feira | sim |
| Senior | Médio | Não | Excelente | Não |
Temos atributos como idade, renda, estudante e classificação de crédito. Nossa classe, buys_book, tem dois resultados: Sim ou Não.
Nosso objetivo é classificar com base nos seguintes atributos:
X = {idade = jovem, estudante = sim, renda = média, credit_rating = justo}.
Como mostramos anteriormente, para maximizar P(Ci | X), precisamos maximizar [ P(X | Ci) * P(Ci) ] para i = 1 e i = 2.
Portanto, P(compra_livro = sim) = 9/14 = 0,643
P(compra_livro = não) = 5/14 = 0,357
P(idade = jovem | livro_compras = sim) = 2/9 = 0,222
P(idade = jovem | livro_compras = não) =3/5 = 0,600
P(renda = média | buys_book = sim) = 4/9 = 0,444
P(renda = média | buys_book = não) = 2/5 = 0,400
P(aluno = sim | livro_compras = sim) = 6/9 = 0,667
P(aluno = sim | livro_compras = não) = 1/5 = 0,200
P(rating_crédito = justo | buys_book = sim) = 6/9 = 0,667
P(rating_crédito = justo | buys_book = não) = 2/5 = 0,400
Usando as probabilidades calculadas acima, temos
P(X | livro_compras = sim) = 0,222 x 0,444 x 0,667 x 0,667 = 0,044
Similarmente,
P(X | livro_compras = não) = 0,600 x 0,400 x 0,200 x 0,400 = 0,019
Qual classe Ci fornece o máximo P(X|Ci)*P(Ci)? Calculamos:
P(X | livro_compra = sim)* P(livro_compra = sim) = 0,044 x 0,643 = 0,028
P(X | livro_compra = não)* P(livro_compra = não) = 0,019 x 0,357 = 0,007
Comparando os dois acima, visto que 0,028 > 0,007, o Classificador Naive Bayes prevê que o cliente com os atributos mencionados comprará um livro.
Checkout: ideias e tópicos de projetos de aprendizado de máquina
O classificador bayesiano é um bom método?
Algoritmos baseados no Teorema de Bayes em aprendizado de máquina fornecem resultados comparáveis a outros algoritmos, e classificadores Bayesianos são geralmente considerados métodos simples de alta precisão. No entanto, deve-se ter o cuidado de lembrar que os classificadores Bayesianos são particularmente apropriados onde a suposição de independência condicional de classe é válida, e não em todos os casos. Outra preocupação prática é que a aquisição de todos os dados de probabilidade nem sempre é viável.
Conclusão
O Teorema de Bayes tem muitas aplicações em aprendizado de máquina, particularmente em problemas baseados em classificação. A aplicação dessa família de algoritmos no aprendizado de máquina envolve familiaridade com termos como probabilidade anterior e probabilidade posterior. Neste artigo, discutimos os fundamentos do Teorema de Bayes, seu uso em problemas de aprendizado de máquina e trabalhamos com um exemplo de classificação.
Como o Teorema de Bayes é uma parte crucial dos algoritmos baseados em classificação em Machine Learning, você pode aprender mais sobre o Advanced Certificate Program do upGrad em Machine Learning & NLP . Este curso foi elaborado tendo em mente vários tipos de alunos interessados em Machine Learning, oferecendo orientação individual e muito mais.
Por que usamos o teorema de Bayes em Machine Learning?
O Teorema de Bayes é um método para calcular probabilidades condicionais, ou a probabilidade de um evento ocorrer se outro já tiver ocorrido. Uma probabilidade condicional pode levar a resultados mais precisos ao incluir condições extras — em outras palavras, mais dados. Para obter estimativas e probabilidades corretas em Machine Learning, são necessárias probabilidades condicionais. Dada a crescente prevalência do campo em uma ampla gama de domínios, é fundamental compreender a importância de algoritmos e abordagens como o teorema de Bayes em aprendizado de máquina.
Classificador Bayesiano é uma boa escolha?
No aprendizado de máquina, os algoritmos baseados no Teorema de Bayes produzem resultados comparáveis aos de outros métodos, e os classificadores Bayesianos são amplamente considerados como abordagens simples de alta precisão. No entanto, é importante ter em mente que os classificadores Bayesianos são melhor usados quando a condição de independência condicional de classe está correta, não em todas as circunstâncias. Outra consideração é que a obtenção de todos os dados de probabilidade nem sempre é possível.
Como o teorema de Bayes pode ser aplicado na prática?
O teorema de Bayes calcula a probabilidade de ocorrência com base em novas evidências que estejam ou possam estar relacionadas a ela. O método também pode ser usado para ver como novas informações hipotéticas afetam a probabilidade de um evento, supondo que as novas informações sejam verdadeiras. Tomemos, por exemplo, uma única carta selecionada de um baralho de 52 cartas. A probabilidade de a carta se tornar um rei é 4 dividido por 52, ou 1/13, ou aproximadamente 7,69%. Tenha em mente que o baralho contém quatro reis. Digamos que é revelado que a carta escolhida é uma carta de rosto. Como há 12 cartas de rosto em um baralho, a probabilidade de que a carta escolhida seja um rei é 4 dividido por 12, ou aproximadamente 33,3%.