
Como configurar uma API usando o Flask, o Cloud SQL do Google e o App Engine
Publicados: 2022-03-10Alguns frameworks Python podem ser usados para criar APIs, duas das quais são Flask e Django. Frameworks vem com funcionalidades que facilitam para os desenvolvedores implementarem os recursos que os usuários precisam para interagir com seus aplicativos. A complexidade de um aplicativo da Web pode ser um fator decisivo ao escolher com qual estrutura trabalhar.
Django
O Django é um framework robusto que possui uma estrutura predefinida com funcionalidade embutida. A desvantagem de sua robustez, no entanto, é que pode tornar a estrutura muito complexa para certos projetos. É mais adequado para aplicativos Web complexos que precisam aproveitar a funcionalidade avançada do Django.
Frasco
Flask, por outro lado, é um framework leve para construir APIs. Começar com ele é fácil, e os pacotes estão disponíveis para torná-lo robusto à medida que você avança. Este artigo se concentrará na definição das funções e do controlador de visualização e na conexão a um banco de dados no Google Cloud e na implantação no Google Cloud.
Para fins de aprendizado, construiremos uma API Flask com alguns endpoints para gerenciar uma coleção de nossas músicas favoritas. Os endpoints serão para solicitações GET e POST : busca e criação de recursos. Além disso, usaremos o conjunto de serviços na plataforma Google Cloud. Configuraremos o Cloud SQL do Google para nosso banco de dados e iniciaremos nosso aplicativo implantando no App Engine. Este tutorial é destinado a iniciantes que estão tentando usar o Google Cloud para o aplicativo pela primeira vez.
Configurando um projeto Flask
Este tutorial pressupõe que você tenha o Python 3.x instalado. Se você não fizer isso, vá até o site oficial para fazer o download e instalá-lo.
Para verificar se o Python está instalado, inicie sua interface de linha de comando (CLI) e execute o comando abaixo:
python -V Nosso primeiro passo é criar o diretório onde nosso projeto ficará. Vamos chamá-lo flask-app :
mkdir flask-app && cd flask-appA primeira coisa a fazer ao iniciar um projeto Python é criar um ambiente virtual. Ambientes virtuais isolam seu desenvolvimento Python em funcionamento. Isso significa que este projeto pode ter suas próprias dependências, diferente de outros projetos em suas máquinas. venv é um módulo que acompanha o Python 3.
Vamos criar um ambiente virtual em nosso diretório flask-app :
python3 -m venv env Este comando cria uma pasta env em nosso diretório. O nome (neste caso, env ) é um alias para o ambiente virtual e pode ser qualquer nome.
Agora que criamos o ambiente virtual, temos que dizer ao nosso projeto para usá-lo. Para ativar nosso ambiente virtual, use o seguinte comando:
source env/bin/activate Você verá que o prompt da CLI agora tem env no início, indicando que nosso ambiente está ativo.

(env) aparece antes do prompt (visualização grande)Agora, vamos instalar nosso pacote Flask:
pip install flask Crie um diretório chamado api em nosso diretório atual. Estamos criando este diretório para que tenhamos uma pasta onde residirão as outras pastas do nosso aplicativo.
mkdir api && cd api Em seguida, crie um arquivo main.py , que servirá como ponto de entrada para nosso aplicativo:
touch main.py Abra main.py e digite o seguinte código:
#main.py from flask import Flask app = Flask(__name__) @app.route('/') def home(): return 'Hello World' if __name__ == '__main__': app.run() Vamos entender o que fizemos aqui. Primeiro importamos a classe Flask do pacote Flask. Em seguida, criamos uma instância da classe e a atribuímos a app . Em seguida, criamos nosso primeiro endpoint, que aponta para a raiz do nosso aplicativo. Em resumo, esta é uma função de visualização que invoca a rota / — ela retorna Hello World .
Vamos executar o aplicativo:
python main.py Isso inicia nosso servidor local e serve nosso aplicativo em https://127.0.0.1:5000/ . Insira a URL em seu navegador e você verá a resposta Hello World impressa na tela.
E voilá! Nosso aplicativo está funcionando. A próxima tarefa é torná-lo funcional.
Para chamar nossos endpoints, usaremos o Postman, que é um serviço que ajuda os desenvolvedores a testar endpoints. Você pode baixá-lo no site oficial.
Vamos fazer main.py retornar alguns dados:
#main.py from flask import Flask, jsonify app = Flask(__name__) songs = [ { "title": "Rockstar", "artist": "Dababy", "genre": "rap", }, { "title": "Say So", "artist": "Doja Cat", "genre": "Hiphop", }, { "title": "Panini", "artist": "Lil Nas X", "genre": "Hiphop" } ] @app.route('/songs') def home(): return jsonify(songs) if __name__ == '__main__': app.run() Aqui, incluímos uma lista de músicas, incluindo o título da música e o nome do artista. Em seguida, alteramos o root / route para /songs . Essa rota retorna o array de músicas que especificamos. Para obter nossa lista como um valor JSON, JSONificamos a lista passando-a por jsonify . Agora, em vez de ver um simples Hello world , vemos uma lista de artistas quando acessamos o endpoint https://127.0.0.1:5000/songs .
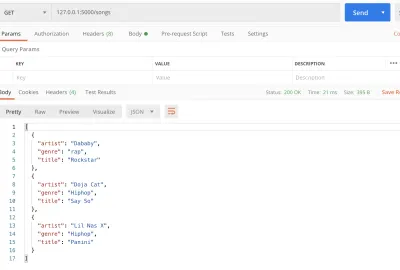
get visualização grande) Você deve ter notado que após cada alteração, tínhamos que reiniciar nosso servidor. Para habilitar o recarregamento automático quando o código muda, vamos habilitar a opção debug. Para fazer isso, altere app.run para isso:
app.run(debug=True) Em seguida, vamos adicionar uma música usando um post request ao nosso array. Primeiro, importe o objeto de request , para que possamos processar a solicitação recebida de nossos usuários. Mais tarde, usaremos o objeto de request na função de visualização para obter a entrada do usuário em JSON.
#main.py from flask import Flask, jsonify, request app = Flask(__name__) songs = [ { "title": "Rockstar", "artist": "Dababy", "genre": "rap", }, { "title": "Say So", "artist": "Doja Cat", "genre": "Hiphop", }, { "title": "Panini", "artist": "Lil Nas X", "genre": "Hiphop" } ] @app.route('/songs') def home(): return jsonify(songs) @app.route('/songs', methods=['POST']) def add_songs(): song = request.get_json() songs.append(song) return jsonify(songs) if __name__ == '__main__': app.run(debug=True) Nossa função de visualização add_songs pega uma música enviada pelo usuário e a anexa à nossa lista de músicas existente.
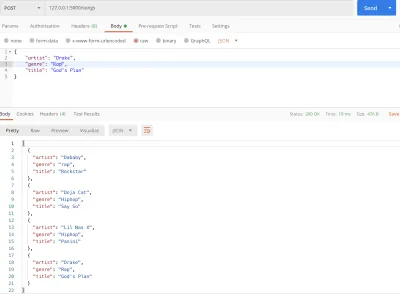
Até agora, retornamos nossos dados de uma lista do Python. Isso é apenas experimental, porque em um ambiente mais robusto, nossos dados recém-adicionados seriam perdidos se reiniciassemos o servidor. Isso não é viável, então precisaremos de um banco de dados ativo para armazenar e recuperar os dados. Entra o Cloud SQL.
Por que usar uma instância do Cloud SQL?
Segundo o site oficial:
“O Google Cloud SQL é um serviço de banco de dados totalmente gerenciado que facilita a configuração, manutenção, gerenciamento e administração de seus bancos de dados relacionais MySQL e PostgreSQL na nuvem. Hospedado no Google Cloud Platform, o Cloud SQL fornece uma infraestrutura de banco de dados para aplicativos executados em qualquer lugar.”
Isso significa que podemos terceirizar o gerenciamento da infraestrutura de um banco de dados inteiramente para o Google, com preços flexíveis.
Diferença entre o Cloud SQL e um Compute Engine autogerenciado
No Google Cloud, podemos ativar uma máquina virtual na infraestrutura do Compute Engine do Google e instalar nossa instância SQL. Isso significa que seremos responsáveis pela escalabilidade vertical, replicação e uma série de outras configurações. Com o Cloud SQL, temos muitas configurações prontas para uso, para que possamos gastar mais tempo no código e menos tempo na configuração.
Antes de começarmos:
- Inscreva-se no Google Cloud. O Google oferece US$ 300 em crédito grátis para novos usuários.
- Crie um projeto. Isso é bastante simples e pode ser feito diretamente no console.
Criar uma instância do Cloud SQL
Depois de se inscrever no Google Cloud, no painel esquerdo, role até a guia “SQL” e clique nela.
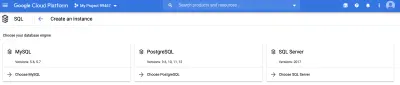
Primeiro, somos obrigados a escolher um mecanismo SQL. Nós iremos com o MySQL para este artigo.
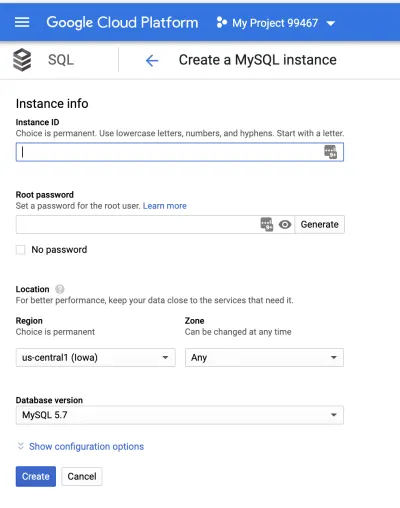
Em seguida, criaremos uma instância. Por padrão, nossa instância será criada nos EUA e a zona será selecionada automaticamente para nós.
Defina a senha de root e dê um nome à instância e clique no botão “Criar”. Você pode configurar ainda mais a instância clicando no menu suspenso "Mostrar opções de configuração". As configurações permitem configurar o tamanho da instância, capacidade de armazenamento, segurança, disponibilidade, backups e muito mais. Para este artigo, iremos com as configurações padrão. Não se preocupe, essas variáveis podem ser alteradas posteriormente.
Pode levar alguns minutos para que o processo seja concluído. Você saberá que a instância está pronta quando vir uma marca de seleção verde. Clique no nome da sua instância para ir para a página de detalhes.
Agora que estamos funcionando, vamos fazer algumas coisas:
- Crie um banco de dados.
- Crie um novo usuário.
- Coloque nosso endereço IP na lista de permissões.
Criar um banco de dados
Navegue até a guia "Banco de dados" para criar um banco de dados.
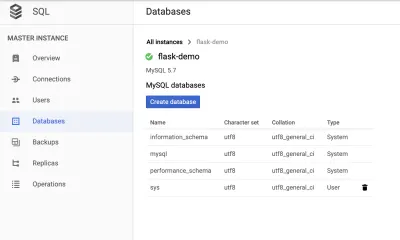
Criar um novo usuário
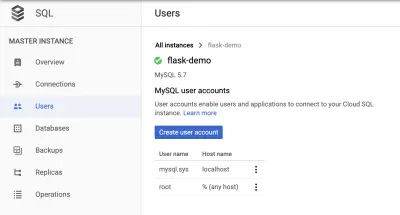
Na seção "Nome do host", defina-o para permitir "% (qualquer host)".

Endereço IP da lista de permissões
Você pode se conectar à sua instância de banco de dados de duas maneiras. Um endereço IP privado requer uma nuvem privada virtual (VPC). Se você optar por essa opção, o Google Cloud criará uma VPC gerenciada pelo Google e colocará sua instância nela. Para este artigo, usaremos o endereço IP público , que é o padrão. É público no sentido de que apenas as pessoas cujos endereços IP foram incluídos na lista de permissões podem acessar o banco de dados.
Para colocar seu endereço IP na lista de permissões, digite my ip em uma pesquisa do Google para obter seu IP. Em seguida, vá para a guia "Conexões" e "Adicionar rede".
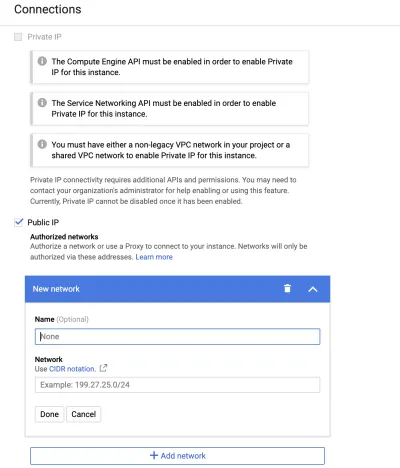
Conecte-se à instância
Em seguida, navegue até o painel "Visão geral" e conecte-se usando o shell da nuvem.
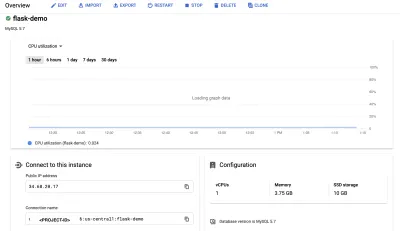
O comando para se conectar à nossa instância do Cloud SQL será pré-digitado no console.
Você pode usar o usuário root ou o usuário que foi criado anteriormente. No comando abaixo, estamos dizendo: Conecte-se à instância do flask-demo como o usuário USERNAME . Você será solicitado a inserir a senha do usuário.
gcloud sql connect flask-demo --user=USERNAMESe você receber um erro informando que não tem um ID do projeto, poderá obter o ID do seu projeto executando isto:
gcloud projects list Pegue o ID do projeto que foi gerado pelo comando acima e insira-o no comando abaixo, substituindo PROJECT_ID por ele.
gcloud config set project PROJECT_ID Em seguida, execute o comando gcloud sql connect e estaremos conectados.
Execute este comando para ver os bancos de dados ativos:
> show databases; 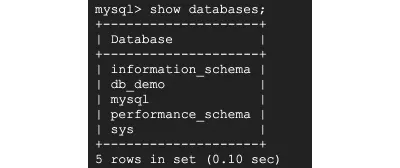
Meu banco de dados se chama db_demo e executarei o comando abaixo para usar o banco de dados db_demo . Você pode ver alguns outros bancos de dados, como information_schema e performance_schema . Eles estão lá para armazenar metadados de tabela.
> use db_demo;Em seguida, crie uma tabela que espelhe a lista do nosso aplicativo Flask. Digite o código abaixo em um bloco de notas e cole-o em seu shell de nuvem:
create table songs( song_id INT NOT NULL AUTO_INCREMENT, title VARCHAR(255), artist VARCHAR(255), genre VARCHAR(255), PRIMARY KEY(song_id) ); Esse código é um comando SQL que cria uma tabela chamada songs , com quatro colunas ( song_id , title , artist e genre ). Também instruímos que a tabela deve definir song_id como chave primária e incrementar automaticamente a partir de 1.
Agora, execute show tables; para confirmar que a tabela foi criada.
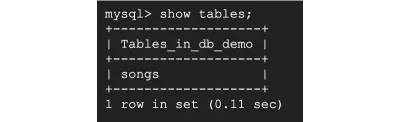
E assim, criamos um banco de dados e nossa tabela de songs .
Nossa próxima tarefa é configurar o Google App Engine para que possamos implantar nosso aplicativo.
Google App Engine
O App Engine é uma plataforma totalmente gerenciada para desenvolver e hospedar aplicativos da Web em escala. Uma vantagem da implantação no App Engine é que ele permite que um aplicativo seja dimensionado automaticamente para atender ao tráfego de entrada.
O site do App Engine diz:
“Com zero gerenciamento de servidor e zero implantações de configuração, os desenvolvedores podem se concentrar apenas na criação de ótimos aplicativos sem a sobrecarga de gerenciamento.”
Configurar o App Engine
Existem algumas maneiras de configurar o App Engine: por meio da IU do Google Cloud Console ou do Google Cloud SDK. Usaremos o SDK para esta seção. Ele nos permite implantar, gerenciar e monitorar nossa instância do Google Cloud em nossa máquina local.
Instale o SDK do Google Cloud
Siga as instruções para baixar e instalar o SDK para Mac ou Windows. O guia também mostrará como inicializar o SDK em sua CLI e como escolher um projeto do Google Cloud.
Agora que o SDK foi instalado, vamos atualizar nosso script Python com as credenciais do nosso banco de dados e implantar no App Engine.
Configuração local
Em nosso ambiente local, atualizaremos a configuração para se adequar à nossa nova arquitetura, que inclui Cloud SQL e App Engine.
Primeiro, adicione um arquivo app.yaml à nossa pasta raiz. Este é um arquivo de configuração que o App Engine requer para hospedar e executar nosso aplicativo. Ele informa ao App Engine sobre nosso tempo de execução e outras variáveis que podem ser necessárias. Para nosso aplicativo, precisaremos adicionar as credenciais do nosso banco de dados como variáveis de ambiente, para que o App Engine esteja ciente da instância do nosso banco de dados.
No arquivo app.yaml , adicione o snippet abaixo. Você terá obtido as variáveis de tempo de execução e de banco de dados ao configurar o banco de dados. Substitua os valores pelo nome de usuário, senha, nome do banco de dados e nome da conexão que você usou ao configurar o Cloud SQL.
#app.yaml runtime: python37 env_variables: CLOUD_SQL_USERNAME: YOUR-DB-USERNAME CLOUD_SQL_PASSWORD: YOUR-DB-PASSWORD CLOUD_SQL_DATABASE_NAME: YOUR-DB-NAME CLOUD_SQL_CONNECTION_NAME: YOUR-CONN-NAMEAgora, vamos instalar o PyMySQL. Este é um pacote Python MySQL que conecta e executa consultas em um banco de dados MySQL. Instale o pacote PyMySQL executando esta linha em sua CLI:
pip install pymysqlNeste ponto, estamos prontos para usar o PyMySQL para se conectar ao nosso banco de dados Cloud SQL a partir do aplicativo. Isso nos permitirá obter e inserir consultas em nosso banco de dados.
Inicializar o conector de banco de dados
Primeiro, crie um arquivo db.py em nossa pasta raiz e adicione o código abaixo:
#db.py import os import pymysql from flask import jsonify db_user = os.environ.get('CLOUD_SQL_USERNAME') db_password = os.environ.get('CLOUD_SQL_PASSWORD') db_name = os.environ.get('CLOUD_SQL_DATABASE_NAME') db_connection_name = os.environ.get('CLOUD_SQL_CONNECTION_NAME') def open_connection(): unix_socket = '/cloudsql/{}'.format(db_connection_name) try: if os.environ.get('GAE_ENV') == 'standard': conn = pymysql.connect(user=db_user, password=db_password, unix_socket=unix_socket, db=db_name, cursorclass=pymysql.cursors.DictCursor ) except pymysql.MySQLError as e: print(e) return conn def get_songs(): conn = open_connection() with conn.cursor() as cursor: result = cursor.execute('SELECT * FROM songs;') songs = cursor.fetchall() if result > 0: got_songs = jsonify(songs) else: got_songs = 'No Songs in DB' conn.close() return got_songs def add_songs(song): conn = open_connection() with conn.cursor() as cursor: cursor.execute('INSERT INTO songs (title, artist, genre) VALUES(%s, %s, %s)', (song["title"], song["artist"], song["genre"])) conn.commit() conn.close()Fizemos algumas coisas aqui.
Primeiro, recuperamos nossas credenciais de banco de dados do arquivo app.yaml usando o método os.environ.get . O App Engine pode disponibilizar no aplicativo as variáveis de ambiente definidas em app.yaml .
Em segundo lugar, criamos uma função open_connection . Ele se conecta ao nosso banco de dados MySQL com as credenciais.
Em terceiro lugar, adicionamos duas funções: get_songs e add_songs . O primeiro inicia uma conexão com o banco de dados chamando a função open_connection . Em seguida, ele consulta a tabela de songs para cada linha e, se estiver vazia, retorna “Nenhuma música no banco de dados”. A função add_songs insere um novo registro na tabela de songs .
Finalmente, voltamos para onde começamos, nosso arquivo main.py Agora, em vez de obter nossas músicas de um objeto, como fizemos anteriormente, chamamos a função add_songs para inserir um registro e chamamos a função get_songs para recuperar os registros do banco de dados.
Vamos refatorar main.py :
#main.py from flask import Flask, jsonify, request from db import get_songs, add_songs app = Flask(__name__) @app.route('/', methods=['POST', 'GET']) def songs(): if request.method == 'POST': if not request.is_json: return jsonify({"msg": "Missing JSON in request"}), 400 add_songs(request.get_json()) return 'Song Added' return get_songs() if __name__ == '__main__': app.run() Importamos as funções get_songs e add_songs e as chamamos em nossa função de visualização song songs() . Se estivermos fazendo uma requisição post , chamamos a função add_songs , e se estivermos fazendo uma requisição get , chamamos a função get_songs .
E nosso aplicativo está pronto.
O próximo passo é adicionar um arquivo requirements.txt . Este arquivo contém uma lista de pacotes necessários para executar o aplicativo. O App Engine verifica esse arquivo e instala os pacotes listados.
pip freeze | grep "Flask\|PyMySQL" > requirements.txt Essa linha obtém os dois pacotes que estamos usando para o aplicativo (Flask e PyMySQL), cria um arquivo requirements.txt e anexa os pacotes e suas versões ao arquivo.
Neste ponto, adicionamos três novos arquivos: db.py , app.yaml e requirements.txt .
Implantar no Google App Engine
Execute o seguinte comando para implantar seu aplicativo:
gcloud app deploySe tudo correu bem, seu console produzirá isso:
Seu aplicativo agora está sendo executado no App Engine. Para vê-lo no navegador, execute gcloud app browse em sua CLI.
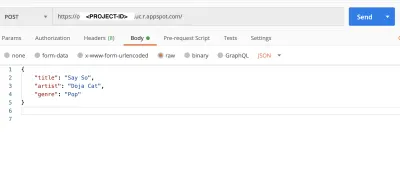
Podemos iniciar o Postman para testar nossa post e get solicitações.
get (visualização grande)Nosso aplicativo agora está hospedado na infraestrutura do Google e podemos ajustar a configuração para obter todos os benefícios de uma arquitetura sem servidor. No futuro, você pode desenvolver este artigo para tornar seu aplicativo sem servidor mais robusto.
Conclusão
Usar uma infraestrutura de plataforma como serviço (PaaS) como App Engine e Cloud SQL basicamente abstrai o nível de infraestrutura e nos permite construir mais rapidamente. Como desenvolvedores, não precisamos nos preocupar com configuração, backup e restauração, sistema operacional, dimensionamento automático, firewalls, migração de tráfego e assim por diante. No entanto, se você precisar de controle sobre a configuração subjacente, talvez seja melhor usar um serviço personalizado.
Referências
- “Baixar Python”
- “venv — Criação de Ambientes Virtuais”, Python (documentação)
- “Baixar Carteiro”
- “Cloud SQL”, Google Cloud
- Google Cloud
- "Nível gratuito do Google Cloud", Google Cloud
- “Criação e gerenciamento de projetos”, Google Cloud
- “VPC Overview” (nuvem privada virtual), Google Cloud
- "App Engine", Google Cloud
- "Inícios rápidos" (faça o download do SDK do Google Cloud), Google Cloud
- Documentação do PyMySQL