
6 recursos que mudam o jogo do Apache Spark em 2022 [Como você deve usar]
Publicados: 2021-01-07Desde que o Big Data conquistou os mundos da tecnologia e dos negócios, houve um enorme aumento de ferramentas e plataformas de Big Data, principalmente do Apache Hadoop e Apache Spark. Hoje, vamos nos concentrar apenas no Apache Spark e discutir detalhadamente seus benefícios e aplicativos comerciais.
O Apache Spark ganhou destaque em 2009 e, desde então, gradualmente conquistou um nicho para si na indústria. De acordo com a Apache org., o Spark é um “mecanismo de análise unificado extremamente rápido” projetado para processar quantidades colossais de Big Data. Graças a uma comunidade ativa, hoje, o Spark é uma das maiores plataformas de Big Data de código aberto do mundo.
Índice
O que é Apache Spark?
Originalmente desenvolvido no AMPLab da Universidade da Califórnia (Berkeley), o Spark foi projetado como um mecanismo de processamento robusto para dados do Hadoop, com foco especial na velocidade e facilidade de uso. É uma alternativa de código aberto ao MapReduce do Hadoop. Essencialmente, o Spark é uma estrutura de processamento de dados paralelo que pode colaborar com o Apache Hadoop para facilitar o desenvolvimento suave e rápido de aplicativos sofisticados de Big Data no Hadoop.
O Spark vem com uma ampla variedade de bibliotecas para algoritmos de Machine Learning (ML) e algoritmos de gráficos. Não apenas isso, ele também suporta streaming em tempo real e aplicativos SQL via Spark Streaming e Shark, respectivamente. A melhor parte de usar o Spark é que você pode escrever aplicativos Spark em Java, Scala ou até Python, e esses aplicativos serão executados quase dez vezes mais rápido (no disco) e 100 vezes mais rápido (na memória) do que os aplicativos MapReduce.
O Apache Spark é bastante versátil, pois pode ser implantado de várias maneiras e também oferece associações nativas para linguagens de programação Java, Scala, Python e R. Ele suporta SQL, processamento de gráficos, streaming de dados e Machine Learning. É por isso que o Spark é amplamente utilizado em vários setores da indústria, incluindo bancos, empresas de telecomunicações, empresas de desenvolvimento de jogos, agências governamentais e, claro, em todas as principais empresas do mundo da tecnologia – Apple, Facebook, IBM e Microsoft.
6 melhores recursos do Apache Spark
Os recursos que fazem do Spark uma das plataformas de Big Data mais utilizadas são:

1. Velocidade de processamento ultrarrápida
O processamento de Big Data trata do processamento de grandes volumes de dados complexos. Portanto, quando se trata de processamento de Big Data, organizações e empresas desejam estruturas que possam processar grandes quantidades de dados em alta velocidade. Como mencionamos anteriormente, os aplicativos Spark podem ser executados até 100 vezes mais rápido na memória e 10 vezes mais rápido no disco em clusters do Hadoop.
Ele se baseia no Resilient Distributed Dataset (RDD) que permite que o Spark armazene dados de forma transparente na memória e os leia/grave no disco somente se necessário. Isso ajuda a reduzir a maior parte do tempo de leitura e gravação do disco durante o processamento de dados.
2. Facilidade de uso
O Spark permite que você escreva aplicativos escalonáveis em Java, Scala, Python e R. Assim, os desenvolvedores obtêm o escopo para criar e executar aplicativos Spark em suas linguagens de programação preferidas. Além disso, o Spark está equipado com um conjunto integrado de mais de 80 operadores de alto nível. Você pode usar o Spark interativamente para consultar dados de shells Scala, Python, R e SQL.
3. Oferece suporte para análises sofisticadas
O Spark não apenas suporta operações simples de “mapear” e “reduzir”, mas também suporta consultas SQL, dados de streaming e análises avançadas, incluindo algoritmos de ML e gráfico. Ele vem com uma poderosa pilha de bibliotecas, como SQL e DataFrames e MLlib (para ML), GraphX e Spark Streaming. O que é fascinante é que o Spark permite combinar os recursos de todas essas bibliotecas em um único fluxo de trabalho/aplicativo.
4. Processamento de fluxo em tempo real
O Spark foi projetado para lidar com streaming de dados em tempo real. Enquanto o MapReduce é construído para manipular e processar os dados que já estão armazenados em clusters do Hadoop, o Spark pode fazer as duas coisas e também manipular dados em tempo real por meio do Spark Streaming.
Ao contrário de outras soluções de streaming, o Spark Streaming pode recuperar o trabalho perdido e fornecer a semântica exata pronta para uso, sem exigir código ou configuração extra. Além disso, também permite que você reutilize o mesmo código para processamento em lote e fluxo e até mesmo para unir dados de streaming a dados históricos.
5. É flexível
O Spark pode ser executado de forma independente no modo de cluster e também pode ser executado no Hadoop YARN, Apache Mesos, Kubernetes e até na nuvem. Além disso, pode acessar diversas fontes de dados. Por exemplo, o Spark pode ser executado no gerenciador de cluster YARN e ler quaisquer dados existentes do Hadoop. Ele pode ler de qualquer fonte de dados do Hadoop, como HBase, HDFS, Hive e Cassandra. Esse aspecto do Spark o torna uma ferramenta ideal para migrar aplicativos Hadoop puros, desde que o caso de uso dos aplicativos seja amigável ao Spark.
6. Comunidade ativa e em expansão
Desenvolvedores de mais de 300 empresas contribuíram para projetar e construir o Apache Spark. Desde 2009, mais de 1.200 desenvolvedores contribuíram ativamente para tornar o Spark o que é hoje! Naturalmente, o Spark é apoiado por uma comunidade ativa de desenvolvedores que trabalham para melhorar continuamente seus recursos e desempenho. Para entrar em contato com a comunidade Spark, você pode usar listas de e-mail para qualquer dúvida e também participar de grupos e conferências do Spark.
A anatomia dos aplicativos Spark
Cada aplicativo Spark é composto por dois processos principais – um processo de driver primário e uma coleção de processos executores .
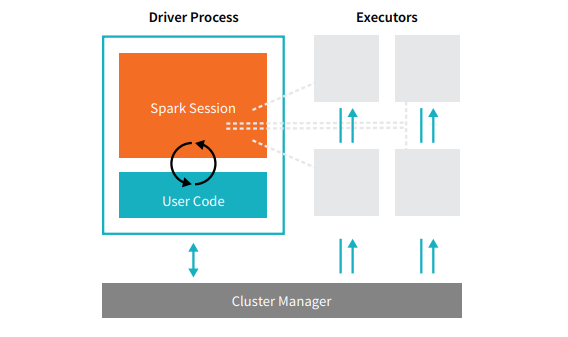
Fonte
O processo de driver que fica em um nó no cluster é responsável por executar a função main(). Ele também lida com três outras tarefas – manter informações sobre o aplicativo Spark, responder ao código ou entrada de um usuário e analisar, distribuir e agendar o trabalho entre os executores. O processo de driver forma o coração de um aplicativo Spark – ele contém e mantém todas as informações críticas que abrangem a vida útil do aplicativo Spark.

Os executores ou processos executores são itens secundários que devem executar a tarefa que lhes é atribuída pelo driver. Basicamente, cada executor executa duas funções cruciais – executar o código atribuído a ele pelo driver e relatar o estado da computação (nesse executor) ao nó do driver. Os usuários podem decidir e configurar quantos executores cada nó deve ter.
Em um aplicativo Spark, o gerenciador de cluster controla todas as máquinas e aloca recursos para o aplicativo. Aqui, o gerenciador de cluster pode ser qualquer um dos gerenciadores de cluster principais do Spark, incluindo YARN (gerenciador de cluster autônomo do Spark) ou Mesos. Isso implica que um cluster pode executar vários aplicativos Spark simultaneamente.
Aplicativos Apache Spark do mundo real
O Spark é uma plataforma Big Dara mais bem avaliada e amplamente utilizada na indústria moderna. Alguns dos exemplos mais aclamados do mundo real de aplicativos Apache Spark são:
Spark para aprendizado de máquina
O Apache Spark possui uma biblioteca de aprendizado de máquina escalável – MLlib. Essa biblioteca é explicitamente projetada para simplicidade, escalabilidade e facilita a integração perfeita com outras ferramentas. O MLlib não apenas possui a escalabilidade, compatibilidade de linguagem e velocidade do Spark, mas também pode executar uma série de tarefas de análise avançada, como classificação, clustering, redução de dimensionalidade. Graças ao MLlib, o Spark pode ser usado para análise preditiva, análise de sentimentos, segmentação de clientes e inteligência preditiva.
Outro recurso impressionante do Apache Spark está no domínio da segurança da rede. O Spark Streaming permite que os usuários monitorem os pacotes de dados em tempo real antes de enviá-los para o armazenamento. Durante esse processo, ele pode identificar com êxito quaisquer atividades suspeitas ou maliciosas que surjam de fontes conhecidas de ameaça. Mesmo depois que os pacotes de dados são enviados para o armazenamento, o Spark usa o MLlib para analisar melhor os dados e identificar possíveis riscos para a rede. Esse recurso também pode ser usado para detecção de fraudes e eventos.
Spark para computação em neblina
O Apache Spark é uma excelente ferramenta para computação em névoa, principalmente quando se trata da Internet das Coisas (IoT). A IoT depende fortemente do conceito de processamento paralelo em larga escala. Como a rede IoT é composta por milhares e milhões de dispositivos conectados, os dados gerados por essa rede a cada segundo estão além da compreensão.
Naturalmente, para processar volumes tão grandes de dados produzidos por dispositivos IoT, você precisa de uma plataforma escalável que suporte processamento paralelo. E nada melhor do que a arquitetura robusta e os recursos de computação em névoa do Spark para lidar com grandes quantidades de dados!
A computação em névoa descentraliza os dados e o armazenamento e, em vez de usar o processamento em nuvem, executa a função de processamento de dados na borda da rede (principalmente incorporada nos dispositivos IoT).
Para fazer isso, a computação em névoa requer três recursos, a saber, baixa latência, processamento paralelo de ML e algoritmos de análise de gráficos complexos – cada um dos quais está presente no Spark. Além disso, a presença do Spark Streaming, Shark (uma ferramenta de consulta interativa que pode funcionar em tempo real), MLlib e GraphX (um mecanismo de análise de gráficos) aprimora ainda mais a capacidade de computação em névoa do Spark.
Spark para análise interativa
Ao contrário do MapReduce, ou Hive, ou Pig, que têm velocidade de processamento relativamente baixa, o Spark pode se orgulhar de análises interativas de alta velocidade. Ele é capaz de lidar com consultas exploratórias sem exigir amostragem dos dados. Além disso, o Spark é compatível com quase todas as linguagens de desenvolvimento populares, incluindo R, Python, SQL, Java e Scala.
A versão mais recente do Spark – Spark 2.0 – apresenta uma nova funcionalidade conhecida como Structured Streaming. Com esse recurso, os usuários podem executar consultas estruturadas e interativas em dados de streaming em tempo real.
Usuários do Spark
Agora que você está bem ciente dos recursos e habilidades do Spark, vamos falar sobre os quatro usuários proeminentes do Spark!
1. Yahoo
O Yahoo usa o Spark para dois de seus projetos, um para personalizar páginas de notícias para visitantes e outro para executar análises para publicidade. Para personalizar as páginas de notícias, o Yahoo usa algoritmos avançados de ML executados no Spark para entender os interesses, preferências e necessidades de usuários individuais e categorizar as histórias de acordo.
Para o segundo caso de uso, o Yahoo aproveita a capacidade interativa do Hive on Spark (para integração com qualquer ferramenta que se conecte ao Hive) para visualizar e consultar os dados analíticos de publicidade do Yahoo reunidos no Hadoop.
2. Uber
A Uber usa Spark Streaming em combinação com Kafka e HDFS para ETL (extrair, transformar e carregar) grandes quantidades de dados em tempo real de eventos discretos em dados estruturados e utilizáveis para análise posterior. Esses dados ajudam a Uber a criar soluções aprimoradas para os clientes.

3. Viva
Como uma empresa de streaming de vídeo, a Conviva obtém uma média de mais de 4 milhões de feeds de vídeo por mês, o que leva a uma grande perda de clientes. Esse desafio é agravado ainda mais pelo problema de gerenciar o tráfego de vídeo ao vivo. Para combater esses desafios de forma eficaz, a Conviva usa o Spark Streaming para conhecer as condições da rede em tempo real e otimizar seu tráfego de vídeo de acordo. Isso permite que a Conviva forneça uma experiência de visualização consistente e de alta qualidade aos usuários.
4. Pinterest
No Pinterest, os usuários podem fixar seus tópicos favoritos como e quando quiserem enquanto navegam na Web e nas mídias sociais. Para oferecer uma experiência personalizada e aprimorada ao cliente, o Pinterest usa os recursos de ETL do Spark para identificar as necessidades e interesses exclusivos de usuários individuais e fornecer recomendações relevantes a eles no Pinterest.
Conclusão
Para concluir, o Spark é uma plataforma de Big Data extremamente versátil com recursos criados para impressionar. Por ser um framework de código aberto, está continuamente melhorando e evoluindo, com novos recursos e funcionalidades sendo adicionados a ele. À medida que as aplicações de Big Data se tornam mais diversificadas e expansivas, os casos de uso do Apache Spark também se tornam.
Se você estiver interessado em saber mais sobre Big Data, confira nosso programa PG Diploma in Software Development Specialization in Big Data, projetado para profissionais que trabalham e fornece mais de 7 estudos de caso e projetos, abrange 14 linguagens e ferramentas de programação, práticas práticas workshops, mais de 400 horas de aprendizado rigoroso e assistência para colocação de emprego com as principais empresas.
Confira nossos outros Cursos de Engenharia de Software no upGrad.