
Arquitetura Apache Kafka: guia abrangente para iniciantes [2022]
Publicados: 2021-12-23Antes de nos aprofundarmos nos detalhes da arquitetura Apache Kafka, é pertinente esclarecer por que Kafka é manchete em primeiro lugar. Para começar, o Apache Kafka encontra uso principalmente em arquiteturas de dados de streaming em tempo real para fornecer análises em tempo real. Durável, rápido, escalável e tolerante a falhas, o sistema de mensagens de publicação-assinatura da Kafka tem casos de uso para coisas como rastrear dados de sensores de IoT ou rastrear chamadas de serviço.
Empresas como LinkedIn, Netflix, Microsoft, Uber, Spotify, Goldman Sachs, Cisco, PayPal e muitas outras empregam o Apache Kafka para processar dados de streaming em tempo real. Por exemplo, o LinkedIn, de onde o Kafka se originou, o usa para rastrear métricas operacionais e dados de atividades. Da mesma forma, para a Netflix, o Apache Kafka é o padrão de fato para suas necessidades de mensagens, eventos e processamento de fluxo.
Aprenda o treinamento de desenvolvimento de software on-line das melhores universidades do mundo. Ganhe Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.
A utilidade do Apache Kafka é melhor apreciada com uma compreensão da arquitetura do Apache Kafka e seus componentes subjacentes. Então, vamos explorar os detalhes da arquitetura de Kafka.
Índice
Conceitos Fundamentais da Arquitetura Kafka
Os conceitos a seguir são básicos para entender a arquitetura Apache Kafka:
1. Tópicos
Os tópicos do Kafka definem os canais pelos quais os dados são transmitidos. Assim, os produtores publicam mensagens nos tópicos e os consumidores leem as mensagens dos tópicos que eles assinam. Não há limitação no número de tópicos criados em um cluster Kafka e um nome exclusivo identifica cada tópico.

2. Corretores
Brokers são servidores em um cluster Kafka que funcionam como contêineres e mantêm vários tópicos com partições distintas. Um ID inteiro exclusivo identifica os brokers em um cluster Kafka, e uma conexão com qualquer um desses brokers significa conectar-se com o cluster inteiro.
3. Partições
Os tópicos do Kafka são divididos em muitas partes conhecidas como partições. As partições são separadas em ordem e permitem que vários consumidores leiam dados de um determinado tópico paralelamente. As partições de um tópico são distribuídas por vários servidores no cluster Kafka, e cada servidor gerencia os dados e solicitações de seu lote de partições. As mensagens chegam ao broker e a uma chave, e a chave determina a partição para a qual a mensagem específica irá. Assim, as mensagens com a mesma chave vão para a mesma partição. Caso a chave não seja especificada, a partição é decidida seguindo uma abordagem round-robin.
4. Réplicas
No Kafka, as réplicas são como backups de partição para garantir que não haja perda de dados em caso de desligamento planejado ou falha. Em outras palavras, as réplicas são cópias de partições.
5. Deslocamentos de partição
Como as mensagens ou registros no Kafka são atribuídos a partições, cada registro é fornecido com um deslocamento para especificar sua posição dentro da partição. Assim, o valor de deslocamento associado a um registro auxilia na sua fácil identificação dentro da partição. Um deslocamento de partição tem significado apenas nessa partição específica e, como os registros são adicionados às extremidades da partição, os registros mais antigos terão valores de deslocamento mais baixos.
6. Produtores
Os produtores de Kafka publicam mensagens para um ou mais tópicos e enviam dados para o cluster Kafka. Assim que um produtor publica uma mensagem em um tópico Kafka, o broker recebe a mensagem e a adiciona a uma partição específica. Em seguida, os produtores podem escolher a partição onde desejam publicar sua mensagem.
7. Consumidores e Grupos de Consumidores
Os consumidores leem mensagens do cluster Kafka. Quando um consumidor está pronto para receber a mensagem, os dados são extraídos do broker. Os consumidores pertencem a um grupo de consumidores e cada consumidor dentro de um determinado grupo é responsável por ler um subconjunto das partições de cada tópico em que está inscrito.
8. Líder e Seguidor
Cada partição Kafka tem um servidor desempenhando o papel de líder. O líder executa todas as tarefas de leitura e gravação para essa partição específica. Por outro lado, o trabalho do seguidor é replicar os dados do líder. Quando um líder em uma partição específica falha, um dos nós seguidores assume o papel do líder. Uma partição pode ter nenhum ou muitos seguidores.
O diagrama a seguir é uma apresentação simplificada das inter-relações entre os componentes da arquitetura Apache Kafka discutidos acima.
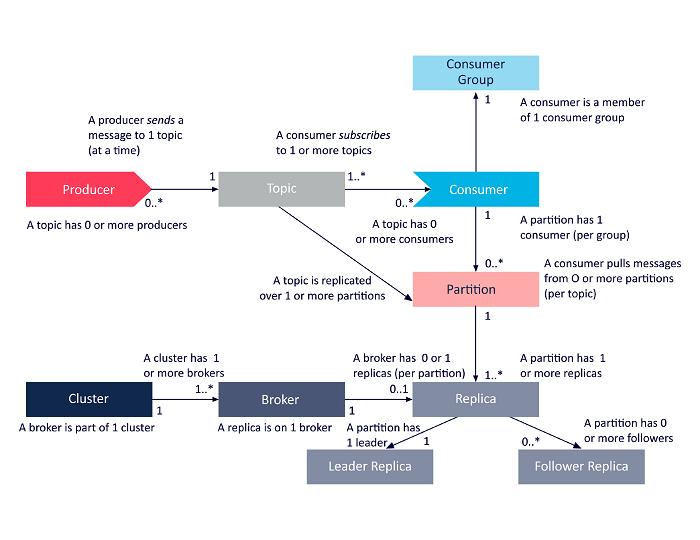
Fonte
Arquitetura de cluster Apache Kafka
Aqui está uma visão detalhada dos principais componentes arquitetônicos do Kafka:

1. Corretores Kafka
Os clusters Kafka normalmente contêm vários nós conhecidos como brokers. Os corretores mantêm o equilíbrio de carga. Cada corretor Kafka pode lidar com centenas e milhares de leituras e gravações a cada segundo. Um broker atua como líder para uma partição específica. O líder tem um ou vários seguidores, com os dados do líder replicados entre os seguidores dessa partição específica.
Os seguidores precisam ficar atualizados com os dados do líder. O líder, por sua vez, acompanha os seguidores que estão em sincronia com ele. Se um seguidor não alcançar o líder ou não estiver mais vivo, ele será removido da lista de réplicas sincronizadas associada ao líder específico. Um novo líder é eleito entre os seguidores após a morte do líder, e o ZooKeeper supervisiona a eleição. Como os brokers não têm estado, o ZooKeeper mantém seu estado de cluster. Os nós em um cluster enviam mensagens de pulsação ao ZooKeeper para informar ao último que eles estão ativos.
2. Produtores de Kafka
Os produtores de Kafka enviam dados diretamente para os corretores que desempenham o papel de líder para uma partição específica. Os brokers ou nós dos clusters Kafka ajudam os produtores a enviar mensagens diretas. Eles fazem isso respondendo a solicitações de metadados sobre quais servidores estão ativos e o status ativo dos líderes de partição de um tópico, permitindo que o produtor direcione suas solicitações de acordo. O produtor decide em qual partição deseja publicar mensagens. As mensagens em Kafka são enviadas em lotes, chamados de lotes de registro. Os produtores coletam mensagens na memória e as enviam em lotes após um período fixo decorrido ou após um certo número de mensagens acumuladas.
3. Consumidores de Kafka
Os consumidores do Kafka emitem solicitações aos corretores indicando as partições que desejam consumir. O consumidor especifica o deslocamento da partição em sua solicitação e recebe um pedaço de log (começando na posição de deslocamento) do broker. Um log contém os registros de um período configurável conhecido como período de retenção.
Os consumidores também podem consumir dados novamente, desde que o log contenha os dados. Os consumidores do Kafka trabalham em uma abordagem baseada em pull, o que significa que os corretores não enviam dados imediatamente para os consumidores. Em vez disso, primeiro, os consumidores enviam solicitações aos corretores sinalizando que estão prontos para consumir dados. Assim, o sistema baseado em pull garante que os consumidores não fiquem sobrecarregados com mensagens e possam alcançá-los se ficarem para trás.
A seguir está um diagrama simplificado da arquitetura do Apache Kafka:
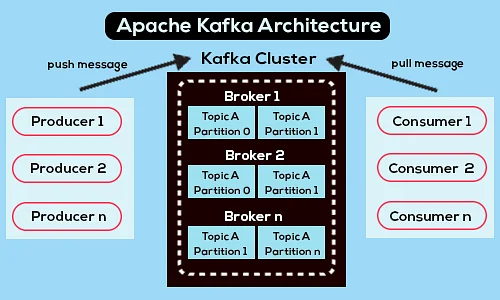
Fonte
Saiba mais sobre o Apache Kafka.
Arquitetura da API Apache Kafka
O Apache Kafka tem quatro APIs principais – a API Streams, API Connector, API Producer e API Consumer. Vamos ver qual é o papel de cada um no aprimoramento dos recursos do Apache Kafka:
1. API de fluxos
A API de fluxos do Kafka permite que um aplicativo processe dados usando um algoritmo de processamento de fluxos. Usando a API de fluxos, os aplicativos podem consumir fluxos de entrada de um ou vários tópicos, processá-los com operações de fluxo, produzir fluxos de saída e, eventualmente, enviá-los para um ou mais tópicos. Assim, a API Streams facilita a transformação de fluxos de entrada em fluxos de saída.
2. API do conector
A API do conector do Kafka é útil para criar, executar e gerenciar produtores e consumidores reutilizáveis que conectam tópicos do Kafka a sistemas de dados ou aplicativos existentes. Por exemplo, um conector para um banco de dados relacional pode capturar todas as atualizações e garantir que as alterações estejam disponíveis em um tópico Kafka.

3. API do produtor
A API do produtor do Kafka permite que os aplicativos publiquem um fluxo de registros nos tópicos do Kafka.
4. API do consumidor
A API de consumo do Kafka Permite que os aplicativos assinem tópicos do Kafka. Ele também permite que os aplicativos processem fluxos de registro que são produzidos para esses tópicos Kafka.
Caminho a seguir
A arquitetura Apache Kafka é apenas uma pequena parte do vasto repertório de ferramentas e linguagens que os desenvolvedores de software lidam. Suponha que você seja um desenvolvedor de software iniciante com inclinação para Big Data. Nesse caso, você pode dar o primeiro passo em direção aos seus objetivos com o Programa PG Executivo em Desenvolvimento de Software da upGrad – Especialização em Big Data .
Aqui está uma visão geral do programa com alguns destaques principais:
- Executive PGP do IIIT Bangalore com certificações em Data Science e Cloud Infrastructure
- Sessões online e palestras ao vivo com mais de 400 horas de conteúdo
- 7+ estudos de caso e projetos
- Mais de 14 linguagens e ferramentas de programação
- Suporte de carreira 360 graus
- Rede de pares e da indústria
Inscreva-se para mais detalhes sobre o curso!
Para que serve o Kafka?
O Apache Kafka é usado principalmente para criar pipelines de dados de streaming em tempo real e aplicativos que se adaptam a esses fluxos de dados. Ele permite o armazenamento e a análise de dados históricos e em tempo real por meio de uma combinação de mensagens, armazenamento e processamento de fluxo.
Kafka é um framework?
O Apache Kafka é um software de código aberto que fornece uma estrutura para armazenar, ler e analisar dados de streaming. Por ser de código aberto, o Kafka é gratuito para uso com muitos desenvolvedores e usuários contribuindo para novos recursos, atualizações e suporte para novos usuários.
Por que precisamos de fluxos Kafka?
Kafka Streams é uma biblioteca cliente para construir microsserviços e aplicativos de streaming onde os dados de entrada e de saída são armazenados no cluster Apache Kafka. Por um lado, oferece os benefícios da tecnologia de cluster do lado do servidor do Apache Kafka. Por outro lado, simplifica a escrita e implantação de aplicativos Scala e Java padrão no lado do cliente.