
Apache Kafka: arquitetura, conceitos, recursos e aplicativos
Publicados: 2021-03-09Kafka foi lançado em 2011, tudo graças ao LinkedIn. Desde então, testemunhou um crescimento incrível a ponto de a maioria das empresas listadas na Fortune 500 agora usá-lo. É um produto altamente escalável, durável e de alto rendimento que pode lidar com grandes quantidades de dados de streaming. Mas essa é a única razão por trás de sua tremenda popularidade? Bem não. Ainda nem começamos com seus recursos, a qualidade que produz e a facilidade que oferece aos usuários.
Vamos mergulhar nisso mais tarde. Vamos primeiro entender o que é Kafka e onde é usado.
Índice
O que é Apache Kafka?
O Apache Kafka é um software de processamento de fluxo de código aberto que visa fornecer alto rendimento e baixa latência enquanto gerencia dados em tempo real. Escrito em Java e Scala, o Kafka oferece durabilidade por meio de microsserviços na memória e tem um papel fundamental a desempenhar na manutenção de eventos de fornecimento para Serviços de Streaming de Eventos Complexos, também conhecidos como CEP ou Sistemas de Automação.
É um sistema distribuído excepcionalmente versátil e à prova de falhas, que permite que empresas como a Uber gerenciem a correspondência de passageiros e motoristas. Ele também fornece dados em tempo real e manutenção proativa para os produtos domésticos inteligentes da British Gas, além de ajudar o LinkedIn a rastrear vários serviços em tempo real.
Frequentemente empregado na arquitetura de dados de streaming em tempo real para fornecer análises em tempo real, o Kafka é um sistema de mensagens rápido, robusto, escalável e de publicação-assinatura. O Apache Kafka pode ser usado como substituto do MOM tradicional devido à sua excelente compatibilidade e arquitetura flexível que permite rastrear chamadas de serviço ou dados de sensores de IoT.
Kafka funciona de forma brilhante com Apache Flume/Flafka, Apache Spark Streaming, Apache Storm, HBase, Apache Flink e Apache Spark para ingestão, pesquisa, análise e processamento de dados de streaming em tempo real. Os intermediários Kafka também facilitam relatórios de acompanhamento de baixa latência no Hadoop ou Spark. Kafka também tem um projeto subsidiário chamado Kafka Stream que funciona como uma ferramenta eficaz para análise em tempo real.

Arquitetura e componentes Kafka
Kafka é usado para transmitir dados em tempo real para vários sistemas de destinatários. Kafka funciona como uma camada central para desacoplar pipelines de dados em tempo real. Não encontra muito uso em cálculos diretos. É mais compatível com sistemas de alimentação de pista rápida, em tempo real ou baseados em dados operacionais, para transmitir uma quantidade significativa de dados para análise de dados em lote.
As estruturas Storm, Flink, Spark e CEP são alguns sistemas de dados com os quais Kafka trabalha para realizar análises em tempo real, criando backups, auditorias e muito mais. Também pode ser integrado a plataformas de big data ou sistemas de banco de dados como RDBMS e Cassandra, Spark, etc., para análise de dados, relatórios etc.
O diagrama abaixo ilustra o Ecossistema Kafka:
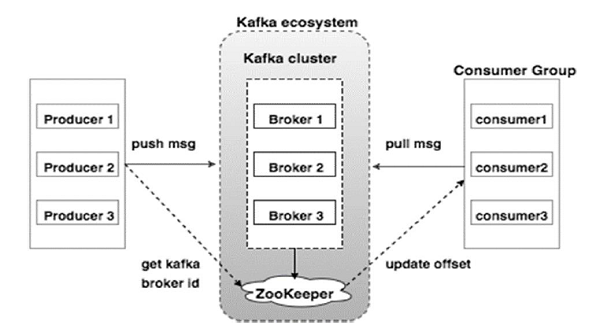
Fonte
Aqui estão os vários componentes do ecossistema Kafka, conforme ilustrado no diagrama de arquitetura Kafka:
1. Corretor Kafka
Kafka emula um cluster que compreende vários servidores, cada um conhecido como “broker”. Qualquer comunicação entre clientes e servidores segue um protocolo TCP de alto desempenho. É composto por mais de um corretor apátrida para lidar com cargas pesadas. Um único corretor Kafka é capaz de gerenciar várias leituras e gravações a cada segundo sem comprometer o desempenho. Eles usam o ZooKeeper para manter os clusters e eleger o líder do broker.
2. Kafka ZooKeeper
Como mencionado acima, o ZooKeeper é responsável pelo gerenciamento dos corretores Kafka. Qualquer nova adição ou falha de um corretor no ecossistema Kafka é informada a um produtor ou consumidor por meio do ZooKeeper.
3. Produtores de Kafka
Eles são responsáveis por enviar dados aos corretores. Os produtores não dependem de intermediários para confirmar o recebimento de uma mensagem. Em vez disso, eles determinam o quanto um corretor pode manipular e enviar mensagens de acordo.

4. Consumidores de Kafka
É responsabilidade dos consumidores do Kafka manter um registro do número de mensagens consumidas pelo deslocamento da partição. Reconhecer uma mensagem indica que as mensagens foram enviadas antes de serem consumidas. Para garantir que o broker tenha um buffer de bytes pronto para enviar ao consumidor, o consumidor inicia uma solicitação de pull assíncrona. O ZooKeeper tem um papel a desempenhar na manutenção do valor de deslocamento de pular ou retroceder uma mensagem.
O mecanismo de Kafka envolve o envio de mensagens entre aplicativos em sistemas distribuídos. O Kafka emprega um log de confirmação, que, quando inscrito, publica os dados presentes em uma variedade de aplicativos de streaming. O remetente envia mensagens para o Kafka, enquanto o destinatário recebe as mensagens do fluxo distribuído pelo Kafka.
As mensagens são reunidas em tópicos — uma deliberação eficaz de Kafka. Um determinado tópico representa um fluxo organizado de dados com base em um tipo ou classificação específica. O produtor escreve mensagens para os consumidores lerem baseadas em um tópico.
Cada tópico recebe um nome exclusivo. Qualquer mensagem de um determinado tópico enviada por um remetente é recebida por todos os usuários que estão sintonizando esse tópico. Uma vez publicados, os dados em um tópico não podem ser atualizados ou modificados.
Características do Kafka
- O Kafka consiste em um registro de confirmação perpétuo que permite que você assine e, posteriormente, publique dados em vários sistemas ou aplicativos em tempo real.
- Ele dá aos aplicativos a capacidade de controlar esses dados à medida que eles chegam. A API Streams no Apache Kafka é uma biblioteca poderosa e leve que facilita o processamento de dados em lote em tempo real.
- É uma aplicação Java que permite regular o seu fluxo de trabalho e reduz significativamente qualquer necessidade de manutenção.
- O Kafka funciona como um “armazenamento da verdade” distribuindo dados para vários nós, permitindo a implantação de dados por meio de vários sistemas de dados.
- O log de confirmação do Kafka o torna um sistema de armazenamento confiável. O Kafka cria réplicas/backups de uma partição que ajudam a prevenir a perda de dados (as configurações corretas podem resultar em perda zero de dados). Isso também evita falhas no servidor e aumenta a durabilidade do Kafka.
- Os tópicos no Kafka têm milhares de partições, tornando-o capaz de lidar com uma quantidade arbitrária de dados e cargas pesadas.
- Kafka depende do kernel do sistema operacional para mover dados em um ritmo acelerado. Esses clusters de informações são criptografados de ponta a ponta, do produtor ao sistema de arquivos ao consumidor final.
- Batching no Kafka aumenta a eficiência da compactação de dados e diminui a latência de E/S.
Aplicações de Kafka
Muitas empresas que lidam com grandes quantidades de dados diariamente usam o Kafka.

- O LinkedIn usa o Kafka para rastrear a atividade do usuário e as métricas de desempenho. O Twitter o combina com o Storm para habilitar uma estrutura de processamento de fluxo.
- A Square usa o Kafka para facilitar a movimentação de todos os eventos do sistema para outros data centers da Square. Isso inclui logs, eventos personalizados e métricas.
- Outras empresas populares que aproveitam os benefícios do Kafka incluem Netflix, Spotify, Uber, Tumblr, CloudFlare e PayPal.
Por que você deve aprender Apache Kafka?
Kafka é uma excelente plataforma de streaming de eventos que pode manipular, rastrear e monitorar dados em tempo real com eficiência. Sua arquitetura escalável e tolerante a falhas permite a integração de dados de baixa latência, resultando em uma alta taxa de transferência de eventos de streaming. Kafka reduz significativamente o “tempo de retorno” dos dados.
Ele funciona como o sistema fundamental que produz informações para as organizações, eliminando “logs” em torno dos dados. Isso permite que cientistas de dados e especialistas acessem facilmente as informações a qualquer momento.
Por esses motivos, é a principal plataforma de streaming escolhida por muitas empresas de ponta e, portanto, os candidatos com qualificação em Apache Kafka são muito procurados.
Se você estiver interessado em aprender mais sobre Kafka, Big Data, você deve conferir o PG Diploma in Software Development Specialization in Big Data da upGrad, que oferece mais de 7 estudos de caso e projetos e orientação de professores de classe mundial e especialistas do setor. O programa de 13 meses abrange 14 linguagens de programação e ensina Processamento de Dados, MapReduce, Data Warehousing, Processamento em Tempo Real, Processamento de Big Data na Nuvem, entre outras habilidades.
Confira nossos outros Cursos de Engenharia de Software no upGrad.