
Uma interface de usuário de voz alternativa para assistentes de voz
Publicados: 2022-03-10Para a maioria das pessoas, a primeira coisa que vem à mente ao pensar em interfaces de usuário de voz são assistentes de voz, como Siri, Amazon Alexa ou Google Assistant. Na verdade, os assistentes são o único contexto em que a maioria das pessoas já usou a voz para interagir com um sistema de computador.
Embora os assistentes de voz tenham trazido interfaces de usuário de voz para o mainstream, o paradigma do assistente não é a única, nem mesmo a melhor maneira de usar, projetar e criar interfaces de usuário de voz.
Neste artigo, analisarei os problemas que os assistentes de voz sofrem e apresentarei uma nova abordagem para interfaces de usuário de voz que chamo de interações diretas de voz.
Assistentes de voz são chatbots baseados em voz
Um assistente de voz é um software que usa linguagem natural em vez de ícones e menus como interface do usuário. Os assistentes normalmente respondem a perguntas e muitas vezes tentam ajudar o usuário de forma proativa.
Em vez de transações e comandos diretos, os assistentes imitam uma conversa humana e usam a linguagem natural bidirecionalmente como a modalidade de interação, o que significa que ela recebe entrada do usuário e responde ao usuário usando linguagem natural.
Os primeiros assistentes eram sistemas de perguntas e respostas baseados em diálogo. Um dos primeiros exemplos é o Clippy da Microsoft, que infame tentou ajudar os usuários do Microsoft Office, dando-lhes instruções com base no que achava que o usuário estava tentando realizar. Hoje em dia, um caso de uso típico para o paradigma do assistente são os chatbots, frequentemente usados para suporte ao cliente em uma discussão de bate-papo.
Os assistentes de voz, por outro lado, são chatbots que usam voz em vez de digitação e texto . A entrada do usuário não são seleções ou texto, mas fala e a resposta do sistema também é falada em voz alta. Esses assistentes podem ser assistentes gerais, como Google Assistant ou Alexa, que podem responder a uma infinidade de perguntas de maneira razoável ou assistentes personalizados criados para um propósito especial, como pedidos de fast-food.
Embora muitas vezes a entrada do usuário seja apenas uma ou duas palavras e possa ser apresentada como seleções em vez de texto real, à medida que a tecnologia evolui, as conversas serão mais abertas e complexas . A primeira característica definidora de chatbots e assistentes é o uso de linguagem natural e estilo de conversação em vez de ícones, menus e estilo transacional que define uma experiência de usuário típica de um aplicativo móvel ou site.
Leitura recomendada : Construindo um chatbot de IA simples com API de fala da Web e Node.js
A segunda característica definidora que deriva das respostas da linguagem natural é a ilusão de uma persona. O tom, a qualidade e a linguagem que o sistema usa definem tanto a experiência do assistente, a ilusão de empatia e suscetibilidade ao serviço, quanto sua persona. A idéia de uma boa experiência de assistente é como estar envolvido com uma pessoa real .
Como a voz é a maneira mais natural de nos comunicarmos, isso pode parecer incrível, mas há dois grandes problemas com o uso de respostas de linguagem natural. Um desses problemas, relacionado a quão bem os computadores podem imitar os humanos, pode ser corrigido no futuro com o desenvolvimento de tecnologias de IA conversacionais , mas o problema de como os cérebros humanos lidam com as informações é um problema humano, não solucionável no futuro próximo. Vamos analisar esses problemas a seguir.
Dois problemas com respostas de linguagem natural
As interfaces de usuário de voz são, obviamente, interfaces de usuário que usam a voz como uma modalidade. Mas a modalidade de voz pode ser usada para ambas as direções: para inserir informações do usuário e enviar informações do sistema de volta para o usuário. Por exemplo, alguns elevadores usam síntese de voz para confirmar a seleção do usuário depois que o usuário pressiona um botão. Mais tarde, discutiremos as interfaces de usuário de voz que só usam voz para inserir informações e usam interfaces gráficas de usuário tradicionais para mostrar as informações de volta ao usuário.
Os assistentes de voz, por outro lado, usam voz para entrada e saída . Esta abordagem tem dois problemas principais:
Problema nº 1: Imitação de um humano falha
Como humanos, temos uma inclinação inata para atribuir características humanas a objetos não humanos. Vemos as feições de um homem em uma nuvem passando ou olhamos para um sanduíche e parece que está sorrindo para nós. Isso se chama antropomorfismo .

Esse fenômeno também se aplica aos assistentes e é desencadeado por suas respostas de linguagem natural. Embora uma interface gráfica de usuário possa ser construída um tanto neutra, não há como um humano não começar a pensar se a voz de alguém pertence a uma pessoa jovem ou idosa ou se é homem ou mulher. Por causa disso, o usuário quase começa a pensar que o assistente é de fato um humano.
No entanto, nós humanos somos muito bons em detectar falsificações . Curiosamente, quanto mais próximo algo se assemelha a um humano, mais os pequenos desvios começam a nos perturbar. Há um sentimento de estranheza em relação a algo que tenta ser humano, mas não chega à altura disso. Em robótica e animações por computador, isso é chamado de “vale estranho”.

Quanto melhor e mais humano tentarmos tornar o assistente, mais assustadora e decepcionante pode ser a experiência do usuário quando algo dá errado. Todo mundo que tentou assistentes provavelmente se deparou com o problema de responder com algo que parece idiota ou até rude.
O vale estranho dos assistentes de voz apresenta um problema de qualidade na experiência do usuário assistente que é difícil de superar. De fato, o teste de Turing (em homenagem ao famoso matemático Alan Turing) é aprovado quando um avaliador humano que exibe uma conversa entre dois agentes não consegue distinguir entre qual deles é uma máquina e qual é um humano. Até agora, nunca foi passado.
Isso significa que o paradigma do assistente estabelece uma promessa de uma experiência de serviço semelhante à humana que nunca poderá ser cumprida e o usuário ficará desapontado. As experiências bem-sucedidas apenas aumentam a decepção final, pois o usuário começa a confiar em seu assistente humano.
Problema 2: interações sequenciais e lentas
O segundo problema dos assistentes de voz é que a natureza baseada em turnos das respostas de linguagem natural causa atraso na interação. Isso se deve ao modo como nosso cérebro processa informações.
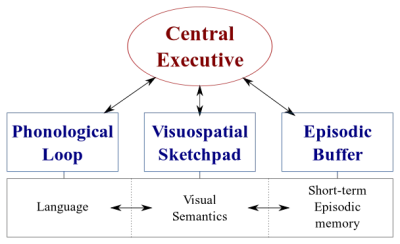
Existem dois tipos de sistemas de processamento de dados em nossos cérebros:
- Um sistema linguístico que processa a fala;
- Um sistema visuoespacial especializado no processamento de informações visuais e espaciais.
Esses dois sistemas podem operar em paralelo, mas ambos processam apenas uma coisa de cada vez . É por isso que você pode falar e dirigir um carro ao mesmo tempo, mas não pode enviar mensagens de texto e dirigir porque ambas as atividades aconteceriam no sistema visuoespacial.

Da mesma forma, quando você está falando com o assistente de voz, o assistente precisa ficar quieto e vice-versa. Isso cria uma conversa baseada em turnos , onde a outra parte é sempre totalmente passiva.
No entanto, considere um tópico difícil que você deseja discutir com seu amigo. Você provavelmente discutiria cara a cara ao invés de por telefone, certo? Isso ocorre porque em uma conversa cara a cara, usamos a comunicação não verbal para fornecer feedback visual em tempo real ao nosso parceiro de conversa. Isso cria um ciclo de troca de informações bidirecional e permite que ambas as partes se envolvam ativamente na conversa simultaneamente.
Os assistentes não fornecem feedback visual em tempo real. Eles contam com uma tecnologia chamada end-pointing para decidir quando o usuário parou de falar e só responde depois disso. E quando eles respondem, eles não recebem nenhuma entrada do usuário ao mesmo tempo. A experiência é totalmente unidirecional e baseada em turnos.
Em uma conversa cara a cara bidirecional e em tempo real, ambas as partes podem reagir imediatamente a sinais visuais e linguísticos. Isso utiliza os diferentes sistemas de processamento de informações do cérebro humano e a conversa se torna mais suave e eficiente.
Os assistentes de voz estão presos no modo unidirecional porque estão usando linguagem natural como canais de entrada e saída. Embora a voz seja até quatro vezes mais rápida do que digitar para entrada, é significativamente mais lenta para digerir do que ler. Como as informações precisam ser processadas sequencialmente , essa abordagem só funciona bem para comandos simples, como “desligar as luzes”, que não exigem muita saída do assistente.

Anteriormente, prometi discutir interfaces de usuário de voz que empregam voz apenas para inserir dados do usuário. Esse tipo de interface de usuário de voz se beneficia das melhores partes das interfaces de usuário de voz - naturalidade, velocidade e facilidade de uso - mas não sofre com as partes ruins - vale estranho e interações sequenciais
Vamos considerar esta alternativa.
Uma alternativa melhor ao assistente de voz
A solução para superar esses problemas em assistentes de voz é deixar de lado as respostas de linguagem natural e substituí-las por feedback visual em tempo real. Alternar feedback para visual permitirá que o usuário dê e receba feedback simultaneamente. Isso permitirá que o aplicativo reaja sem interromper o usuário e permitindo um fluxo de informações bidirecional. Como o fluxo de informações é bidirecional, sua taxa de transferência é maior.
Atualmente, os principais casos de uso para assistentes de voz são definir alarmes, tocar música, verificar o clima e fazer perguntas simples. Todas essas são tarefas de baixo risco que não frustram muito o usuário ao falhar.
Como David Pierce, do Wall Street Journal , escreveu uma vez:
“Não consigo me imaginar reservando um voo ou gerenciando meu orçamento por meio de um assistente de voz ou acompanhando minha dieta gritando ingredientes no alto-falante.”
— David Pierce do Wall Street Journal
Essas são tarefas com muitas informações que precisam dar certo.
No entanto, eventualmente, a interface do usuário de voz falhará. A chave é cobrir isso o mais rápido possível. Muitos erros acontecem ao digitar em um teclado ou até mesmo em uma conversa cara a cara. No entanto, isso não é frustrante, pois o usuário pode se recuperar simplesmente clicando no backspace e tentando novamente ou pedindo esclarecimentos.
Essa rápida recuperação de erros permite que o usuário seja mais eficiente e não o force a uma conversa estranha com um assistente.
Interações diretas de voz
Na maioria dos aplicativos, as ações são executadas por meio da manipulação de elementos gráficos na tela, cutucando ou deslizando (em telas sensíveis ao toque), clicando com o mouse e/ou pressionando botões em um teclado. A entrada de voz pode ser adicionada como uma opção ou modalidade adicional para manipular esses elementos gráficos. Esse tipo de interação pode ser chamado de interação direta por voz .
A diferença entre interações diretas de voz e assistentes é que, em vez de pedir a um avatar, o assistente, para realizar uma tarefa, o usuário manipula diretamente a interface gráfica do usuário com voz.
“Isso não é semântica?”, você pode perguntar. Se você vai falar com o computador, realmente importa se você está falando diretamente com o computador ou através de uma pessoa virtual? Em ambos os casos, você está apenas falando com um computador!
Sim, a diferença é sutil, mas crítica. Ao clicar em um botão ou item de menu em uma GUI ( Interface Gráfica do Usuário) é flagrantemente óbvio que estamos operando uma máquina. Não há ilusão de uma pessoa. Ao substituir esse clique por um comando de voz, estamos melhorando a interação humano-computador. Com o paradigma assistente, por outro lado, estamos criando uma versão deteriorada da interação humano-humano e, portanto, viajando para o vale misterioso.
A combinação de funcionalidades de voz na interface gráfica do usuário também oferece o potencial de aproveitar o poder de diferentes modalidades. Embora o usuário possa usar a voz para operar o aplicativo, ele também pode usar a interface gráfica tradicional. Isso permite que o usuário alterne facilmente entre toque e voz e escolha a melhor opção com base em seu contexto e tarefa.
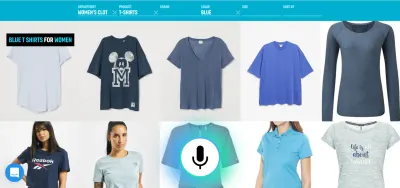
Por exemplo, a voz é um método muito eficiente para inserir informações ricas. Selecionar entre algumas alternativas válidas, toque ou clique é provavelmente melhor. O usuário pode substituir a digitação e a navegação dizendo algo como "Mostre-me voos de Londres para Nova York com partida amanhã" e selecionar a melhor opção da lista usando o toque.
Agora você pode perguntar “OK, isso parece ótimo, então por que não vimos exemplos dessas interfaces de usuário de voz antes? Por que as grandes empresas de tecnologia não estão criando ferramentas para algo assim?” Bem, provavelmente há muitas razões para isso. Uma razão é que o paradigma atual do assistente de voz é provavelmente a melhor maneira de aproveitar os dados que obtêm dos usuários finais. Outra razão tem a ver com a forma como sua tecnologia de voz é construída.
Uma interface de usuário de voz que funcione bem requer duas partes distintas:
- Reconhecimento de fala que transforma fala em texto;
- Componentes de compreensão de linguagem natural que extraem significado desse texto.
A segunda parte é a mágica que transforma os enunciados “Apague as luzes da sala” e “Por favor, apague as luzes da sala” na mesma ação.
Leitura recomendada : Como criar sua própria ação para o Google Home usando API.AI
Se você já usou um assistente com tela (como Siri ou Google Assistant), provavelmente notou que obtém a transcrição quase em tempo real, mas depois de parar de falar, leva alguns segundos para que o sistema realmente executa a ação que você solicitou. Isso se deve ao reconhecimento de fala e à compreensão da linguagem natural ocorrendo sequencialmente.
Vamos ver como isso pode ser mudado.
Compreensão da linguagem falada em tempo real: o molho secreto para comandos de voz mais eficientes
A rapidez com que um aplicativo reage à entrada do usuário é um fator importante na experiência geral do usuário do aplicativo. A inovação mais importante do iPhone original foi a tela sensível ao toque extremamente responsiva e reativa. A capacidade de uma interface de usuário de voz reagir instantaneamente à entrada de voz é igualmente importante.
Para estabelecer um loop rápido de troca de informações bidirecional entre o usuário e a interface do usuário, a GUI habilitada para voz deve ser capaz de reagir instantaneamente - mesmo no meio da frase - sempre que o usuário disser algo acionável. Isso requer uma técnica chamada streaming de compreensão da linguagem falada .
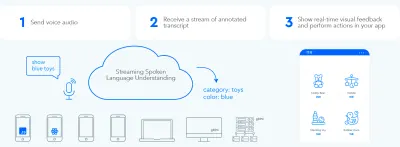
Ao contrário dos sistemas tradicionais de assistente de voz baseados em turnos que esperam que o usuário pare de falar antes de processar a solicitação do usuário, os sistemas que usam streaming de compreensão da linguagem falada tentam ativamente compreender a intenção do usuário desde o momento em que o usuário começa a falar. Assim que o usuário diz algo acionável, a interface do usuário reage instantaneamente a isso.
A resposta instantânea valida imediatamente que o sistema está entendendo o usuário e o encoraja a continuar. É análogo a um aceno de cabeça ou um curto “a-ha” na comunicação entre humanos. Isso resulta em enunciados mais longos e mais complexos suportados. Respectivamente, se o sistema não entender o usuário ou o usuário falar errado, o feedback instantâneo permite uma recuperação rápida . O usuário pode imediatamente corrigir e continuar, ou até mesmo se corrigir verbalmente: “Eu quero isso, não, eu quis dizer, eu quero aquilo”. Você pode experimentar esse tipo de aplicativo em nossa demonstração de pesquisa por voz.
Como você pode ver na demonstração, o feedback visual em tempo real permite que o usuário se corrija naturalmente e o incentiva a continuar com a experiência de voz. Como eles não são confundidos por uma persona virtual, eles podem se relacionar com possíveis erros de maneira semelhante a erros de digitação – não como insultos pessoais. A experiência é mais rápida e natural porque a informação fornecida ao usuário não é limitada pela taxa típica de fala de cerca de 150 palavras por minuto.
Leitura recomendada : Designing Voice Experiences por Lyndon Cerejo
Conclusões
Embora os assistentes de voz tenham sido de longe o uso mais comum para interfaces de usuário de voz até agora, o uso de respostas em linguagem natural os torna ineficientes e não naturais. A voz é uma ótima modalidade para inserir informações, mas ouvir uma máquina falando não é muito inspirador. Esta é a grande questão dos assistentes de voz.
O futuro da voz, portanto, não deve estar nas conversas com um computador, mas na substituição das tarefas tediosas do usuário pela forma mais natural de comunicação: a fala . As interações diretas de voz podem ser usadas para melhorar a experiência de preenchimento de formulários em aplicativos da Web ou móveis, para criar melhores experiências de pesquisa e para permitir uma maneira mais eficiente de controlar ou navegar em um aplicativo.
Designers e desenvolvedores de aplicativos estão constantemente procurando maneiras de reduzir o atrito em seus aplicativos ou sites. Aprimorar a interface gráfica do usuário atual com uma modalidade de voz permitiria interações do usuário várias vezes mais rápidas, especialmente em determinadas situações, como quando o usuário final está no celular e em trânsito e é difícil digitar. Na verdade, a pesquisa por voz pode ser até cinco vezes mais rápida do que uma interface de usuário de filtragem de pesquisa tradicional, mesmo ao usar um computador desktop.
Da próxima vez, quando estiver pensando em como tornar uma determinada tarefa do usuário em seu aplicativo mais fácil de usar, mais agradável de usar ou estiver interessado em aumentar as conversões, considere se essa tarefa do usuário pode ser descrita com precisão em linguagem natural. Se sim, complemente sua interface de usuário com uma modalidade de voz, mas não force seus usuários a conversar com um computador.
Recursos
- “Voz em primeiro lugar versus as interfaces de usuário multimodais do futuro”, Joan Palmiter Bajorek, UXmatters
- “Diretrizes para a criação de aplicativos produtivos habilitados para voz”, Hannes Heikinheimo, Speechly
- “6 razões pelas quais seus aplicativos de tela sensível ao toque devem ter recursos de voz”, Ottomatias Peura, UXmatters
- Misturando o tangível e o intangível: projetando interfaces multimodais usando o Adobe XD, Nick Babich, Smashing Magazine
( O Adobe XD pode ser para prototipar algo semelhante ) - “Eficiência na velocidade do som: a promessa das operações habilitadas por voz”, Eric Turkington, RAIN
- Uma demonstração mostrando feedback visual em tempo real na filtragem de pesquisa por voz de comércio eletrônico (versão em vídeo)
- Speechly fornece ferramentas de desenvolvedor para esse tipo de interface de usuário
- Alternativa de código aberto: voice2json