
Uso avançado do GraphQL em sites Gatsby
Publicados: 2022-03-10Antes do lançamento do GraphQL em 2015, Representational State Transfer (REST) era a principal forma de interface com uma API. A introdução do GraphQL foi, portanto, uma grande mudança no desenvolvimento de software.
Como um gerador de site estático moderno, o Gatsby aproveita o GraphQL para fornecer uma metodologia concisa para trazer e manipular dados no framework. Neste artigo, examinaremos mais de perto o GraphQL e como podemos integrá-lo a um site do Gatsby, criando e implementando o fornecimento e a transformação de dados avançados no Gatsby. O resultado é o blog de um editor que pode ser usado por qualquer editora para compartilhar o conteúdo de seus autores.
O que é GraphQL?
Indo pelo QL em seu nome, GraphQL é uma linguagem de consulta combinada com um conjunto de ferramentas criadas para fornecer flexibilidade e eficiência na maneira como extraímos dados de uma fonte. Com o GraphQL, um cliente/consumidor pode solicitar exatamente os dados de que necessita. O servidor/provedor responde com uma assinatura de resposta JSON que corresponde aos requisitos especificados na consulta. Ele nos permite expressar nossas necessidades de dados de forma declarativa.
Por que usar o GraphQL?
Como um gerador de site estático, o Gatsby armazena arquivos estáticos, o que torna a consulta de dados quase impossível. Muitas vezes, existem componentes de página que precisam ser dinâmicos, como uma única página de postagem de blog, portanto, surgiria a necessidade de extrair dados de uma fonte e transformá-los no formato necessário, assim como ter postagens de blog armazenadas em arquivos de remarcação. Alguns plugins fornecem dados de várias fontes, o que deixa você consultando e transformando os dados necessários de uma fonte.
De acordo com uma lista em gatsby.org, o GraphQL é útil no Gatsby para:
- Eliminar o clichê
- Empurre complexidades de front-end em consultas
- Forneça uma solução perfeita para os dados sempre complexos de um aplicativo moderno
- Finalmente, para remover o excesso de código, melhorando assim o desempenho.
Conceitos do GraphQL
Gatsby mantém as mesmas ideias do GraphQL amplamente utilizadas; alguns desses conceitos são:
Linguagem de definição de esquema
GraphQL SDL é um sistema de tipos incorporado ao GraphQL e você pode usá-lo para criar novos tipos para seus dados.
Podemos declarar um tipo para um país e seus atributos podem incluir um nome, continente, população, PIB e número de estados.
Como exemplo abaixo, criamos um novo tipo com o nome de Aleem . Tem hobbies que são uma série de strings e não são obrigatórios, mas país, estado civil e posts são necessários devido ao ! eles incluem, também posts referenciam outro tipo, Post .
type Author { name: String!, hobbies: [String] country: String! married: Boolean! posts: [Post!] } type Post { title: String! body: String! } type Query { author: Author } schema { query: Query }Consultas
Podemos usar consultas para extrair dados de uma fonte GraphQL.
Considerando um conjunto de dados como o abaixo
{ data: { author: [ { hobbies: ["travelling", "reading"], married: false, country: "Nigeria", name: "Aleem Isiaka", posts: [ { title: "Learn more about how to improve your Gatsby website", }, { title: "The ultimate guide to GatsbyJS", }, { title: "How to start a blog with only GatsbyJS", }, ], }, ], }, };Podemos ter uma consulta para buscar o país e as postagens dos dados:
query { authors { country, posts { title } } }A resposta que obteremos deve conter dados JSON das postagens do blog com apenas o título e nada mais:
[ { country: “Nigeria”, posts: [{...}, {...}, {...}] }, { country: “Tunisia”, posts: [] }, { title: “Ghana”, posts: []}, ]Também podemos usar argumentos como condições para uma consulta:
query { authors (country: “Nigeria”) { country, posts { title } } }Que deve retornar
[ { country: “Nigeria”, posts: [{...}, {...}, {...}] } ]Campos aninhados também podem ser consultados, como os posts com o tipo Post, você pode pedir apenas os títulos:
query { authors(country: 'Nigeria') { country, posts { title } } }E deve retornar qualquer tipo de autor que corresponda à Nigéria retornando o país e a matriz de postagens contendo objetos apenas com o campo de título.
Gatsby com GraphQL
Para evitar a sobrecarga de ter um servidor/serviço que fornece dados que o GraphQL pode transformar, o Gatsby executa as consultas do GraphQL em tempo de compilação. Os dados são fornecidos aos componentes durante o processo de compilação, tornando-os prontamente disponíveis dentro do navegador sem um servidor.
Ainda assim, o Gatsby pode ser executado como um servidor que pode ser consultado por outros clientes GraphQL, como o GraphiQL, em um navegador.
Gatsby Maneiras de interagir com GraphQL
Há dois lugares onde o Gatsby pode interagir com o GraphQL, por meio de um arquivo de API gatsby-node.js e por meio de componentes de página.
gatsby-node.js
A API createPage pode ser configurada como uma função que receberá um auxiliar graphql como parte dos itens do primeiro argumento passado para a função.
// gatsby-node.js source: https://www.gatsbyjs.org/docs/node-apis/#createPages exports.createPages = async ({ graphql, actions }) => { const result = await graphql(` query loadPagesQuery ($limit: Int!) { allMarkdownRemark(limit: $limit) { edges { node { frontmatter { slug } } } } }`) }No código acima, usamos o auxiliar GraphQL para buscar arquivos markdown da camada de dados do Gatsby. E podemos injetar isso para criar uma página e modificar os dados existentes dentro da camada de dados do Gatsby.
Componentes da página
Componentes de página dentro do diretório /pages ou modelos renderizados pela ação da API createPage podem importar graphql do módulo gatsby e exportar um pageQuery . Por sua vez, Gatsby injetaria novos data de prop nas props do componente de página contendo os dados resolvidos.
import React from "react"; import { graphql } from "gatsby"; const Page = props => { return{JSON.stringify(props.data)}; }; export const pageQuery = graphql` consulta { ... } `; exportar página padrão;
Em outros componentes
Outros componentes podem importar componentes graphql e StaticQuery do módulo gatsby , renderizar o <StaticQuery/> passando adereços de consulta que implementam o auxiliar Graphql e renderizam para obter os dados retornados.
import React from "react"; import { StaticQuery, graphql } from "gatsby"; const Brand = props => { return ( <div> <h1>{data.site.siteMetadata.title}</h1> </div> ); }; const Navbar = props => { return ( <StaticQuery query={graphql` query { site { siteMetadata { title } } } `} render={data => <Brand data={data} {...props} />} /> ); }; export default Navbar;Construindo um blog de publicação Gatsby moderno e avançado
Nesta seção, percorreremos um processo de criação de um blog que suporta marcação, categorização, paginação e agrupamento de artigos por autores. Usaremos plugins do ecossistema do Gatsby para trazer alguns recursos e usar lógicas nas consultas do GraphQL para fazer um blog do editor pronto para publicações de vários autores.
A versão final do blog que vamos construir pode ser encontrada aqui, também o código está hospedado no Github.
Inicializando o projeto
Como qualquer site do Gatsby, inicializamos a partir de um iniciador, aqui usaremos o iniciador avançado, mas modificado para atender ao nosso caso de uso.
Primeiro clone este repositório do Github, altere o branch de trabalho para o dev-init e, em seguida, execute npm run develop da pasta do projeto para iniciar o servidor de desenvolvimento disponibilizando o site em https://localhost:8000.
git clone [email protected]:limistah/modern-gatsby-starter.git cd modern-gatsby-starter git checkout dev-init npm install npm run developVisitar https://localhost:8000 mostrará a página inicial padrão para esta ramificação.
Criando conteúdo de postagens de blog
Algum conteúdo de postagem incluído no repositório do projeto pode ser acessado na ramificação dev-blog-content. A organização do diretório de conteúdo se parece com isso /content/YYYY_MM/DD.md , que agrupa as postagens pelo mês de um ano criado.
O conteúdo do post do blog tem title , date , author , category , tags como seu frontmatter, que usaremos para distinguir um post e fazer algum processamento adicional, enquanto o restante do conteúdo é o corpo do post.
title: "Bold Mage" date: "2020-07-12" author: "Tunde Isiaka" category: "tech" tags: - programming - stuff - Ice cream - other --- # Donut I love macaroon chocolate bar Oat cake marshmallow lollipop fruitcake I love jelly-o. Gummi bears cake wafer chocolate bar pie. Marshmallow pastry powder chocolate cake candy chupa chups. Jelly beans powder souffle biscuit pie macaroon chocolate cake. Marzipan lemon drops chupa chups sweet cookie sesame snaps jelly halvah.Exibindo o conteúdo da postagem
Antes de podermos renderizar nossas postagens Markdown em HTML, precisamos fazer algum processamento. Primeiro, carregando os arquivos no armazenamento Gatsby, analisando o MD para HTML, vinculando dependências de imagem e curtidas. Para facilitar isso, usaremos uma série de plugins do ecossistema Gatsby.
Podemos usar esses plugins atualizando o gatsby-config.js na raiz do projeto para ficar assim:
module.exports = { siteMetadata: {}, plugins: [ { resolve: "gatsby-source-filesystem", options: { name: "assets", path: `${__dirname}/static/`, }, }, { resolve: "gatsby-source-filesystem", options: { name: "posts", path: `${__dirname}/content/`, }, }, { resolve: "gatsby-transformer-remark", options: { plugins: [ { resolve: `gatsby-remark-relative-images`, }, { resolve: "gatsby-remark-images", options: { maxWidth: 690, }, }, { resolve: "gatsby-remark-responsive-iframe", }, "gatsby-remark-copy-linked-files", "gatsby-remark-autolink-headers", "gatsby-remark-prismjs", ], }, }, ], };Instruímos o gatsby a incluir os plugins para nos ajudar a realizar algumas ações, notadamente a extração de arquivos da pasta /static para arquivos estáticos e /content para nossas postagens no blog. Além disso, incluímos um plug-in de transformação de comentários para transformar todos os arquivos que terminam com .md ou .markdown em um nó com todos os campos de observação para renderização de markdown como HTML.
Por último, incluímos plugins para operar nos nós gerados por gatsby-transformer-remark .
Implementando o arquivo de API gatsby-config.js
Seguindo em frente, dentro de gatsby-node.js na raiz do projeto, podemos exportar uma função chamada createPage e ter o conteúdo da função para usar o auxiliar graphQL para extrair nós da camada de conteúdo do GatsbyJS.
A primeira atualização desta página incluiria garantir que temos um slug definido nos nós de observação MarkDown. Ouviremos a API onCreateNode e obteremos o nó criado para determinar se é um tipo de MarkdownRemark antes de atualizarmos o nó para incluir um slug e data de acordo.
const path = require("path"); const _ = require("lodash"); const moment = require("moment"); const config = require("./config"); // Called each time a new node is created exports.onCreateNode = ({ node, actions, getNode }) => { // A Gatsby API action to add a new field to a node const { createNodeField } = actions; // The field that would be included let slug; // The currently created node is a MarkdownRemark type if (node.internal.type === "MarkdownRemark") { // Recall, we are using gatsby-source-filesystem? // This pulls the parent(File) node, // instead of the current MarkdownRemark node const fileNode = getNode(node.parent); const parsedFilePath = path.parse(fileNode.relativePath); if ( Object.prototype.hasOwnProperty.call(node, "frontmatter") && Object.prototype.hasOwnProperty.call(node.frontmatter, "title") ) { // The node is a valid remark type and has a title, // Use the title as the slug for the node. slug = `/${_.kebabCase(node.frontmatter.title)}`; } else if (parsedFilePath.name !== "index" && parsedFilePath.dir !== "") { // File is in a directory and the name is not index // eg content/2020_02/learner/post.md slug = `/${parsedFilePath.dir}/${parsedFilePath.name}/`; } else if (parsedFilePath.dir === "") { // File is not in a subdirectory slug = `/${parsedFilePath.name}/`; } else { // File is in a subdirectory, and name of the file is index // eg content/2020_02/learner/index.md slug = `/${parsedFilePath.dir}/`; } if (Object.prototype.hasOwnProperty.call(node, "frontmatter")) { if (Object.prototype.hasOwnProperty.call(node.frontmatter, "slug")) slug = `/${_.kebabCase(node.frontmatter.slug)}`; if (Object.prototype.hasOwnProperty.call(node.frontmatter, "date")) { const date = moment(new Date(node.frontmatter.date), "DD/MM/YYYY"); if (!date.isValid) console.warn(`WARNING: Invalid date.`, node.frontmatter); // MarkdownRemark does not include date by default createNodeField({ node, name: "date", value: date.toISOString() }); } } createNodeField({ node, name: "slug", value: slug }); } };A listagem de postagens
Neste ponto, podemos implementar a API createPages para consultar todas as remarcações e criar uma página com o caminho como o slug que criamos acima. Veja no Github.
//gatsby-node.js // previous code // Create Pages Programatically! exports.createPages = async ({ graphql, actions }) => { // Pulls the createPage action from the Actions API const { createPage } = actions; // Template to use to render the post converted HTML const postPage = path.resolve("./src/templates/singlePost/index.js"); // Get all the markdown parsed through the help of gatsby-source-filesystem and gatsby-transformer-remark const allMarkdownResult = await graphql(` { allMarkdownRemark { edges { node { fields { slug } frontmatter { title tags category date author } } } } } `); // Throws if any error occur while fetching the markdown files if (allMarkdownResult.errors) { console.error(allMarkdownResult.errors); throw allMarkdownResult.errors; } // Items/Details are stored inside of edges const postsEdges = allMarkdownResult.data.allMarkdownRemark.edges; // Sort posts postsEdges.sort((postA, postB) => { const dateA = moment( postA.node.frontmatter.date, siteConfig.dateFromFormat ); const dateB = moment( postB.node.frontmatter.date, siteConfig.dateFromFormat ); if (dateA.isBefore(dateB)) return 1; if (dateB.isBefore(dateA)) return -1; return 0; }); // Pagination Support for posts const paginatedListingTemplate = path.resolve( "./src/templates/paginatedListing/index.js" ); const { postsPerPage } = config; if (postsPerPage) { // Get the number of pages that can be accommodated const pageCount = Math.ceil(postsEdges.length / postsPerPage); // Creates an empty array Array.from({ length: pageCount }).forEach((__value__, index) => { const pageNumber = index + 1; createPage({ path: index === 0 ? `/posts` : `/posts/${pageNumber}/`, component: paginatedListingTemplate, context: { limit: postsPerPage, skip: index * postsPerPage, pageCount, currentPageNumber: pageNumber, }, }); }); } else { // Load the landing page instead createPage({ path: `/`, component: landingPage, }); } }; Na função createPages , usamos o auxiliar graphql fornecido pelo Gatsby para consultar dados da camada de conteúdo. Usamos uma consulta Graphql padrão para fazer isso e passamos uma consulta para obter conteúdo do tipo allMarkdownRemark . Em seguida, avançou para classificar as postagens pela data de criação.

Em seguida, extraímos uma propriedade postPerPage de um objeto de configuração importado, que é usado para reduzir o total de postagens para o número especificado de postagens para uma única página.
Para criar uma página de listagem que suporte paginação, precisamos passar o limite, pageNumber e o número de páginas a serem ignoradas para o componente que renderizaria a lista. Estamos conseguindo isso usando a propriedade context do objeto de configuração createPage . Estaremos acessando essas propriedades da página para fazer outra consulta graphql para buscar posts dentro do limite.
Também podemos notar que usamos o mesmo componente de modelo para a listagem, e apenas o caminho está mudando utilizando o índice do array de pedaços que definimos anteriormente. Gatsby passará os dados necessários para um determinado URL correspondente a /{chunkIndex} , para que possamos ter / para as dez primeiras postagens e /2 para as próximas dez postagens.
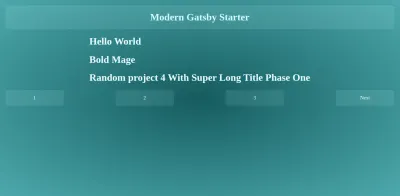
Renderizando Listagem de Posts
O componente que renderiza essas páginas pode ser encontrado em src/templates/singlePost/index.js da pasta do projeto. Ele também exporta um auxiliar graphql que extrai o limite e o parâmetro de consulta de página que recebeu do processo createPages para consultar gatsby por postagens dentro do intervalo da página atual.
import React from "react"; import { graphql, Link } from "gatsby"; import Layout from "../../layout"; import PostListing from "../../components/PostListing"; import "./index.css"; const Pagination = ({ currentPageNum, pageCount }) => { const prevPage = currentPageNum - 1 === 1 ? "/" : `/${currentPageNum - 1}/`; const nextPage = `/${currentPageNum + 1}/`; const isFirstPage = currentPageNum === 1; const isLastPage = currentPageNum === pageCount; return ( <div className="paging-container"> {!isFirstPage && <Link to={prevPage}>Previous</Link>} {[...Array(pageCount)].map((_val, index) => { const pageNum = index + 1; return ( <Link key={`listing-page-${pageNum}`} to={pageNum === 1 ? "/" : `/${pageNum}/`} > {pageNum} </Link> ); })} {!isLastPage && <Link to={nextPage}>Next</Link>} </div> ); }; export default (props) => { const { data, pageContext } = props; const postEdges = data.allMarkdownRemark.edges; const { currentPageNum, pageCount } = pageContext; return ( <Layout> <div className="listing-container"> <div className="posts-container"> <PostListing postEdges={postEdges} /> </div> <Pagination pageCount={pageCount} currentPageNum={currentPageNum} /> </div> </Layout> ); }; /* eslint no-undef: "off" */ export const pageQuery = graphql` query ListingQuery($skip: Int!, $limit: Int!) { allMarkdownRemark( sort: { fields: [fields___date], order: DESC } limit: $limit skip: $skip ) { edges { node { fields { slug date } excerpt timeToRead frontmatter { title tags author category date } } } } } `;A página de postagem
Para visualizar o conteúdo de uma página, precisamos criar a página programaticamente dentro do arquivo de API gatsby-node.js . Primeiro, temos que definir um novo componente para renderizar o conteúdo, para isso temos src/templates/singlePost/index.jsx .
import React from "react"; import { graphql, Link } from "gatsby"; import _ from "lodash"; import Layout from "../../layout"; import "./b16-tomorrow-dark.css"; import "./index.css"; import PostTags from "../../components/PostTags"; export default class PostTemplate extends React.Component { render() { const { data, pageContext } = this.props; const { slug } = pageContext; const postNode = data.markdownRemark; const post = postNode.frontmatter; if (!post.id) { post.id = slug; } return ( <Layout> <div> <div> <h1>{post.title}</h1> <div className="category"> Posted to{" "} <em> <Link key={post.category} style={{ textDecoration: "none" }} to={`/category/${_.kebabCase(post.category)}`} > <a>{post.category}</a> </Link> </em> </div> <PostTags tags={post.tags} /> <div dangerouslySetInnerHTML={{ __html: postNode.html }} /> </div> </div> </Layout> ); } } /* eslint no-undef: "off" */ export const pageQuery = graphql` query BlogPostBySlug($slug: String!) { markdownRemark(fields: { slug: { eq: $slug } }) { html timeToRead excerpt frontmatter { title date category tags } fields { slug date } } } `;Novamente, estamos usando um auxiliar graphQL para extrair uma página por uma consulta de slug que seria enviada para a página por meio da API createPages.
Em seguida, devemos adicionar o código abaixo ao gatsby-node.js no final da função da API createPages .
// Template to use to render the post converted HTML const postPage = path.resolve("./src/templates/singlePost/index.jsx"); // Loops through all the post nodes postsEdges.forEach((edge, index) => { // Create post pages createPage({ path: edge.node.fields.slug, component: postPage, context: { slug: edge.node.fields.slug, }, }); }); E poderíamos visitar '/{pageSlug}' e fazer com que ele renderizasse o conteúdo do arquivo markdown dessa página como HTML. Como exemplo, https://localhost:8000/the-butterfly-of-the-edge deve carregar o HTML convertido para o markdown em: content/2020_05/01.md , semelhante a todos os slugs válidos. Excelente!

Renderizando categorias e tags
O componente de modelo de postagem única tem um link para uma página no formato /categories/{categoryName} para listar postagens com categorias semelhantes.
Podemos primeiro capturar todas as categorias e tags à medida que construímos a página de postagem única no arquivo gatsby-node.js e, em seguida, criar páginas para cada categoria/tag capturada passando o nome da categoria/tag.
Uma modificação na seção para criar uma página de postagem única no gatsby-node.js se parece com isso:
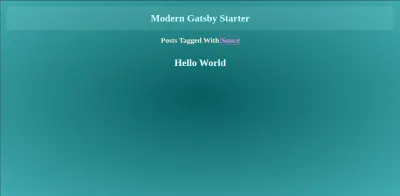
const categorySet = new Set(); const tagSet = new Set(); const categoriesListing = path.resolve( "./src/templates/categoriesListing/index.jsx" ); // Template to use to render posts based on categories const tagsListingPage = path.resolve("./src/templates/tagsListing/index.jsx"); // Loops through all the post nodes postsEdges.forEach((edge, index) => { // Generate a list of categories if (edge.node.frontmatter.category) { categorySet.add(edge.node.frontmatter.category); } // Generate a list of tags if (edge.node.frontmatter.tags) { edge.node.frontmatter.tags.forEach((tag) => { tagSet.add(tag); }); } // Create post pages createPage({ path: edge.node.fields.slug, component: postPage, context: { slug: edge.node.fields.slug, }, }); }); E dentro do componente de listagem de posts por tags, podemos ter a pageQuery export query graphql para posts, incluindo essa tag em sua lista de tags. Usaremos a função de filter de graphql e o operador $in para conseguir isso:
// src/templates/tagsListing/ import React from "react"; import { graphql } from "gatsby"; import Layout from "../../layout"; import PostListing from "../../components/PostListing"; export default ({ pageContext, data }) => { const { tag } = pageContext; const postEdges = data.allMarkdownRemark.edges; return ( <Layout> <div className="tag-container"> <div>Posts posted with {tag}</div> <PostListing postEdges={postEdges} /> </div> </Layout> ); }; /* eslint no-undef: "off" */ export const pageQuery = graphql` query TagPage($tag: String) { allMarkdownRemark( limit: 1000 sort: { fields: [fields___date], order: DESC } filter: { frontmatter: { tags: { in: [$tag] } } } ) { totalCount edges { node { fields { slug date } excerpt timeToRead frontmatter { title tags author date } } } } } `;E temos o mesmo processo no componente de listagem de categorias, e a diferença é que só precisamos descobrir onde as categorias correspondem precisamente com o que passamos para ela.
// src/templates/categoriesListing/index.jsx import React from "react"; import { graphql } from "gatsby"; import Layout from "../../layout"; import PostListing from "../../components/PostListing"; export default ({ pageContext, data }) => { const { category } = pageContext; const postEdges = data.allMarkdownRemark.edges; return ( <Layout> <div className="category-container"> <div>Posts posted to {category}</div> <PostListing postEdges={postEdges} /> </div> </Layout> ); }; /* eslint no-undef: "off" */ export const pageQuery = graphql` query CategoryPage($category: String) { allMarkdownRemark( limit: 1000 sort: { fields: [fields___date], order: DESC } filter: { frontmatter: { category: { eq: $category } } } ) { totalCount edges { node { fields { slug date } excerpt timeToRead frontmatter { title tags author date } } } } } `;Perceptível, dentro dos componentes de tags e categorias, renderizamos links para a página de postagem única para leitura adicional do conteúdo de uma postagem.
Adicionando suporte para autores
Para oferecer suporte a vários autores, precisamos fazer algumas modificações no conteúdo do nosso post e introduzir novos conceitos.
Carregar arquivos JSON
Primeiro, devemos ser capazes de armazenar o conteúdo dos autores em um arquivo JSON como este:
{ "mdField": "aleem", "name": "Aleem Isiaka", "email": "[email protected]", "location": "Lagos, Nigeria", "avatar": "https://api.adorable.io/avatars/55/[email protected]", "description": "Yeah, I like animals better than people sometimes... Especially dogs. Dogs are the best. Every time you come home, they act like they haven't seen you in a year. And the good thing about dogs... is they got different dogs for different people.", "userLinks": [ { "label": "GitHub", "url": "https://github.com/limistah/modern-gatsby-starter", "iconClassName": "fa fa-github" }, { "label": "Twitter", "url": "https://twitter.com/limistah", "iconClassName": "fa fa-twitter" }, { "label": "Email", "url": "mailto:[email protected]", "iconClassName": "fa fa-envelope" } ] } Estaríamos armazenando-os no diretório de um autor na raiz do nosso projeto como /authors . Observe que o JSON do autor tem mdField que seria o identificador exclusivo para o campo do autor que iremos introduzir no conteúdo do blog markdown; isso garante que os autores possam ter vários perfis.
Em seguida, temos que atualizar os plugins gatsby-config.js instruindo o gatsby-source-filesystem a carregar o conteúdo do diretório author authors/ no nó de arquivos.
// gatsby-config.js { resolve: `gatsby-source-filesystem`, options: { name: "authors", path: `${__dirname}/authors/`, }, } Por fim, instalaremos o gatsby-transform-json para transformar os arquivos JSON criados para fácil manuseio e processamento adequado.
npm install gatsby-transformer-json --save E inclua-o dentro dos plugins de gatsby-config.js ,
module.exports = { plugins: [ // ...other plugins `gatsby-transformer-json` ], };Página de consulta e criação de autores
Para começar, precisamos consultar todos os autores em nosso diretório authors/ dentro do gatsby-config.js que foram carregados na camada de dados, devemos anexar o código abaixo à função da API createPages
const authorsListingPage = path.resolve( "./src/templates/authorsListing/index.jsx" ); const allAuthorsJson = await graphql(` { allAuthorsJson { edges { node { id avatar mdField location name email description userLinks { iconClassName label url } } } } } `); const authorsEdges = allAuthorsJson.data.allAuthorsJson.edges; authorsEdges.forEach((author) => { createPage({ path: `/authors/${_.kebabCase(author.node.mdField)}/`, component: authorsListingPage, context: { authorMdField: author.node.mdField, authorDetails: author.node, }, }); }); Neste snippet, estamos puxando todos os autores do tipo allAuthorsJson e, em seguida, chamando forEach nos nós para criar uma página onde passamos o mdField para distinguir o autor e o authorDetails para obter informações completas sobre o autor.
Renderizando as postagens do autor
No componente renderizando a página que pode ser encontrada em src/templates/authorsListing/index.jsx , temos o conteúdo abaixo para o arquivo
import React from "react"; import { graphql } from "gatsby"; import Layout from "../../layout"; import PostListing from "../../components/PostListing"; import AuthorInfo from "../../components/AuthorInfo"; export default ({ pageContext, data }) => { const { authorDetails } = pageContext; const postEdges = data.allMarkdownRemark.edges; return ( <Layout> <div> <h1 style={{ textAlign: "center" }}>Author Roll</h1> <div className="category-container"> <AuthorInfo author={authorDetails} /> <PostListing postEdges={postEdges} /> </div> </div> </Layout> ); }; /* eslint no-undef: "off" */ export const pageQuery = graphql` query AuthorPage($authorMdField: String) { allMarkdownRemark( limit: 1000 sort: { fields: [fields___date], order: DESC } filter: { frontmatter: { author: { eq: $authorMdField } } } ) { totalCount edges { node { fields { slug date } excerpt timeToRead frontmatter { title tags author date } } } } } `; No código acima, exportamos o pageQuery como fazemos, para criar uma consulta GraphQL para buscar postagens correspondidas por um autor, estamos usando o operador $eq para conseguir isso, gerando links para uma única página de postagem para leitura adicional.

Conclusão
No Gatsby, podemos consultar qualquer dado que exista dentro de sua camada de acesso a dados com o uso da consulta GraphQL e passar variáveis usando algumas construções definidas pela arquitetura do Gatsby. vimos como poderíamos usar o auxiliar graphql em vários lugares e entender padrões amplamente usados para consultar dados nos sites do Gatsby com a ajuda do GraphQL.
GraphQL é muito poderoso e pode fazer outras coisas como mutação de dados em um servidor. O Gatsby não precisa atualizar seus dados em tempo de execução, portanto, não suporta o recurso de mutação do GraphQL.
O GraphQL é uma ótima tecnologia, e o Gatsby torna muito interessante usá-lo em seu framework.
Referências
- Suporte Gatsby para GraphQL
- Por que Gatsby usa GraphQL
- Conceitos do GraphQL no Gatsby
- Como GraphQL: Conceitos Básicos
- Linguagem de definição de esquema no GraphQL
- Uma introdução ao GraphQL
- Iniciante Avançado Gatsby