
Um guia para regressão linear usando Scikit [com exemplos]
Publicados: 2021-06-18Os algoritmos de aprendizado supervisionado são geralmente de dois tipos: Regressão e classificação com a previsão de saídas contínuas e discretas.
O artigo a seguir discutirá a regressão linear e sua implementação usando uma das bibliotecas de aprendizado de máquina mais populares do python, a biblioteca Scikit-learn. Ferramentas para aprendizado de máquina e modelos estatísticos estão disponíveis na biblioteca python para classificação, regressão, agrupamento e redução de dimensionalidade. Escrito na linguagem de programação python, a biblioteca é construída sobre as bibliotecas python NumPy, SciPy e Matplotlib.
Índice
Regressão linear
A regressão linear realiza a tarefa de regressão sob o método de aprendizado supervisionado. Com base em variáveis independentes, um valor alvo é previsto. O método é usado principalmente para prever e identificar uma relação entre as variáveis.
Em álgebra, o termo linearidade significa uma relação linear entre variáveis. Uma linha reta é deduzida entre as variáveis em um espaço bidimensional.
Se uma linha é um gráfico entre as variáveis independentes no eixo X e as variáveis dependentes no eixo Y, uma linha reta é obtida por meio da regressão linear que melhor se ajusta aos pontos de dados.
A equação de uma reta tem a forma de

Y = mx + b
Onde, b = interceptar
m = inclinação da linha
Portanto, por meio de regressão linear,
- Os valores mais ótimos para o intercepto e a inclinação são determinados em duas dimensões.
- Não há alteração nas variáveis x e y, pois são os recursos de dados e, portanto, permanecem os mesmos.
- Apenas os valores de interceptação e inclinação podem ser controlados.
- Podem existir múltiplas linhas retas baseadas nos valores de inclinação e interceptação, porém através do algoritmo de regressão linear múltiplas linhas são ajustadas nos pontos de dados e a linha com o menor erro é retornada.
Regressão linear com Python
Para implementar a regressão linear em python, os pacotes apropriados devem ser aplicados junto com suas funções e classes. O pacote NumPy em Python é de código aberto e permite várias operações sobre os arrays, tanto arrays simples quanto multidimensionais.
Outra biblioteca amplamente usada em python é o Scikit-learn, que é usado para problemas de aprendizado de máquina.
Scikit-learnN
A biblioteca Scikit-learn oferece aos desenvolvedores algoritmos baseados em aprendizado supervisionado e não supervisionado. A biblioteca de código aberto do python foi projetada para tarefas de aprendizado de máquina.
Os cientistas de dados podem importar os dados, pré-processá-los, plotá-los e prever dados por meio do uso do scikit-learn.
David Cournapeau desenvolveu o scikit-learn pela primeira vez em 2007, e a biblioteca tem crescido desde décadas.
As ferramentas fornecidas pelo scikit-learn são:
- Regressão: Inclui a Regressão Logística e a Regressão Linear
- Classificação: Inclui o método de K-Nearest Neighbors
- Seleção de um modelo
- Clustering: inclui K-Means++ e K-Means
- Pré-processando
As vantagens da biblioteca são:
- A aprendizagem e implementação da biblioteca são fáceis.
- É uma biblioteca de código aberto e, portanto, gratuita.
- Aspectos de aprendizado de máquina podem ser cobertos, incluindo aprendizado profundo.
- É um pacote poderoso e versátil.
- A biblioteca possui documentação detalhada.
- Um dos kits de ferramentas mais usados para aprendizado de máquina.
Importando scikit-learn
O scikit-learn deve ser instalado primeiro pelo pip ou pelo conda.
- Requisitos: versão de 64 bits do python 3 com as bibliotecas instaladas NumPy e Scipy. Também para visualização de plotagem de dados, é necessário matplotlib.
Comando de instalação: pip install -U scikit-learn
Em seguida, verifique se a instalação está concluída
Instalação de Numpy, Scipy e matplotlib
A instalação pode ser confirmada através de:
Fonte
Regressão linear através do Scikit-learn
A implementação da regressão linear através do pacote scikit-learn envolve os seguintes passos.
- Os pacotes e as classes necessárias devem ser importados.
- Os dados são necessários para trabalhar e também para realizar as transformações apropriadas.
- Um modelo de regressão deve ser criado e ajustado com os dados existentes.
- Os dados de ajuste do modelo devem ser verificados para analisar se o modelo criado é satisfatório.
- As previsões devem ser feitas através da aplicação do modelo.
O pacote NumPy e a classe LinearRegression devem ser importados do sklearn.linear_model.

Fonte
As funcionalidades necessárias para a regressão linear do sklearn estão todas presentes para finalmente implementar a regressão linear. A classe sklearn.linear_model.LinearRegression é usada para realizar análises de regressão ( linear e polinomial ) e realizar previsões.
Para qualquer algoritmo de aprendizado de máquina e regressão linear scikit learn , o conjunto de dados deve ser importado primeiro. Três opções estão disponíveis no Scikit-learn para obter os dados:
- Conjuntos de dados como classificação de íris ou o conjunto de regressão para o preço da habitação de Boston.
- Conjuntos de dados do mundo real podem ser baixados da Internet diretamente por meio de funções predefinidas do Scikit-learn.
- Um conjunto de dados pode ser gerado aleatoriamente para correspondência com um padrão específico por meio do gerador de dados Scikit-learn.
Qualquer que seja a opção selecionada, os conjuntos de dados do módulo devem ser importados.

importar sklearn.datasets como conjuntos de dados
1. O conjunto de classificação de íris
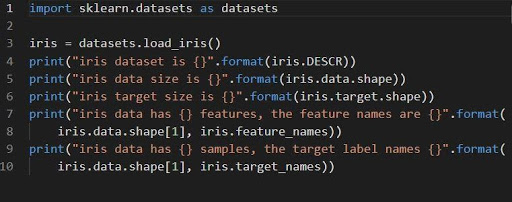
iris = datasets.load_iris()
A íris do conjunto de dados é armazenada como um campo de dados de matriz 2D de n_samples * n_features. Sua importação é realizada como objeto de um dicionário. Ele contém todos os dados necessários junto com os metadados.
As funções DESCR, shape e _names podem ser usadas para obter descrições e formatação dos dados. A impressão dos resultados da função exibirá as informações do conjunto de dados que podem ser necessárias ao trabalhar no conjunto de dados da íris.
O código a seguir carregará as informações do conjunto de dados da íris.
Fonte
2. Geração de dados de regressão
Se não houver necessidade de dados integrados, os dados poderão ser gerados por meio de uma distribuição que pode ser escolhida.
Gerando dados de regressão com um conjunto de 1 recurso informativo e 1 recurso.
X , Y = conjuntos de dados.make_regression(n_features=1, n_informative=1)
Os dados gerados são salvos em um conjunto de dados 2D com os objetos x e y. As características dos dados gerados podem ser alteradas alterando os parâmetros da função make_regression.
Neste exemplo, os parâmetros dos recursos informativos e dos recursos são alterados de um valor padrão de 10 para 1.
Outros parâmetros considerados são as amostras e alvos onde o número de variáveis alvo e amostra rastreadas são controlados.
- Os recursos que fornecem informações úteis aos algoritmos de ML são chamados de recursos informativos, enquanto aqueles que não ajudam são chamados de recursos informativos.
3. Dados de plotagem
Os dados são plotados usando a biblioteca matplotlib. Primeiro, o matplotlib deve ser importado.
Importar matplotlib.pyplot como plt
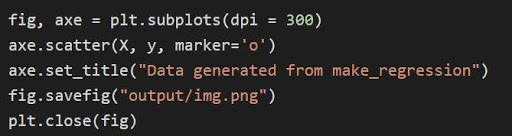
O gráfico acima é plotado através do matplotlib através do código
Fonte
No código acima:
- As variáveis de tupla são descompactadas e salvas como variáveis separadas na linha 1 do código. Portanto, os atributos separados podem ser manipulados e salvos.
- O conjunto de dados x, y é usado para gerar um gráfico de dispersão através da linha 2. Com a disponibilidade do parâmetro do marcador no matplotlib, os visuais são aprimorados marcando os pontos de dados com um ponto (o).
- O título do gráfico gerado é definido através da linha 3.
- A figura pode ser salva como um arquivo de imagem .png e então a figura atual é fechada.
O gráfico de regressão gerado através do código acima é
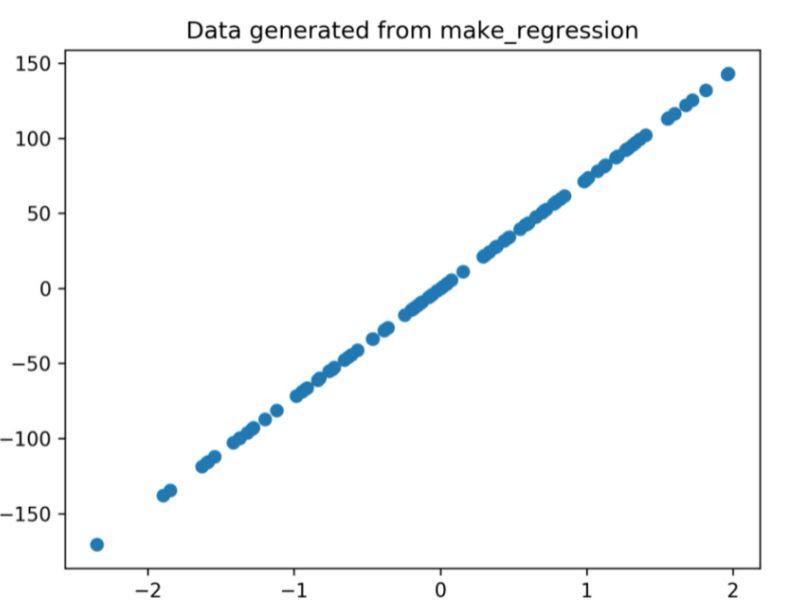
Figura 1: O gráfico de regressão gerado a partir do código acima.
4. Implementação do algoritmo de regressão linear
Usando os dados de amostra do preço da habitação de Boston, o algoritmo de regressão linear Scikit-learn é implementado no exemplo a seguir. Como outros algoritmos de ML, o conjunto de dados é importado e treinado usando os dados anteriores.
O método linear de regressão é usado pelas empresas, pois é um modelo preditivo que prevê a relação entre uma quantidade numérica e suas variáveis com o valor de saída com o significado de ter um valor na realidade.
Quando um registro de dados anteriores está presente, o modelo pode ser melhor aplicado, pois pode prever os resultados futuros do que acontecerá no futuro se houver uma continuação do padrão.
Matematicamente, os dados podem ser ajustados para minimizar a soma de todos os resíduos existentes entre os pontos de dados e o valor previsto.
O trecho a seguir mostra a implementação da regressão linear sklearn.
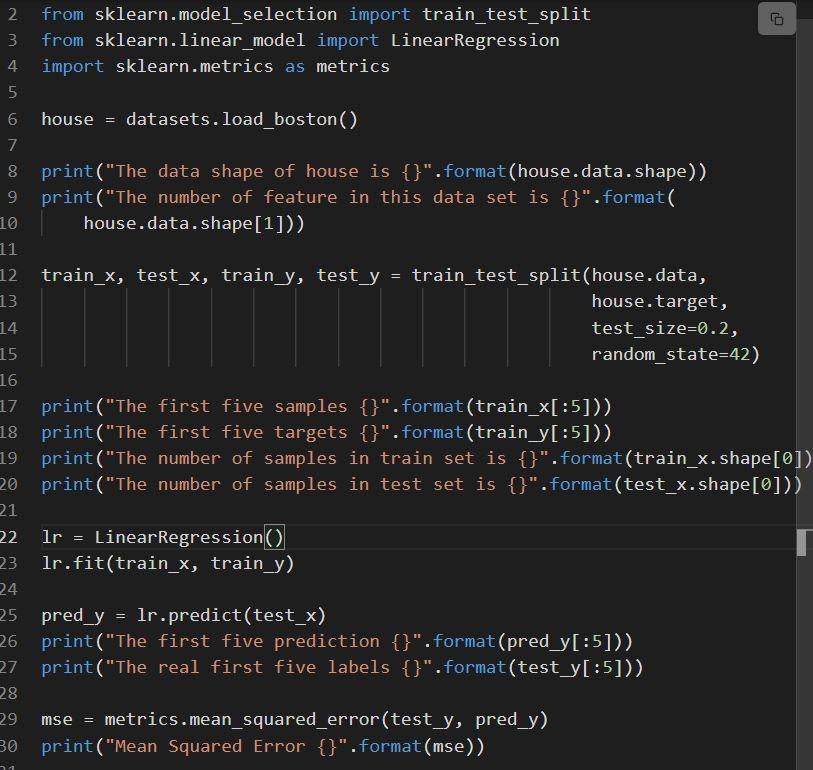
Fonte
O código é explicado como:
- A linha 6 carrega o conjunto de dados chamado load_boston.
- O conjunto de dados é dividido na linha 12, ou seja, o conjunto de treinamento com 80% de dados e o conjunto de teste com 20% de dados.
- Criação de um modelo de regressão linear na linha 23 e depois treinado em.
- O desempenho do modelo é avaliado no linho 29 através da chamada mean_squared_error.
O gráfico de regressão linear sklearn é mostrado abaixo:
Modelo de regressão linear dos dados de amostra de preços de habitação de Boston
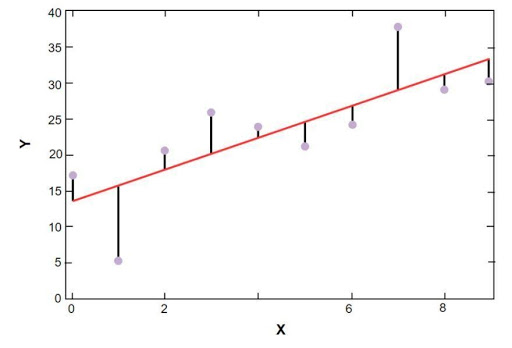
Fonte
Na figura acima, a linha vermelha representa o modelo linear que foi resolvido para os dados amostrais do preço da habitação em Boston. Os pontos azuis representam os dados originais e a distância entre a linha vermelha e os pontos azuis representam a soma do resíduo. O objetivo do modelo de regressão linear scikit-learn é reduzir a soma dos resíduos.
Conclusão
O artigo discutiu a regressão linear e sua implementação através do uso de um pacote python de código aberto chamado scikit-learn. Até agora, você pode obter o conceito de como implementar a regressão linear por meio deste pacote. Vale a pena aprender a usar a biblioteca para sua análise de dados.
Se você tiver interesse em explorar mais o tópico, como a implementação de pacotes python em aprendizado de máquina e problemas relacionados à IA, consulte o curso Master of Science in Machine Learning & AI oferecido pelo upGrad . Voltado para profissionais iniciantes de 21 a 45 anos, o curso visa treinar os alunos em aprendizado de máquina por meio de mais de 650 horas de treinamento online, mais de 25 estudos de caso e atribuições. Certificado pela LJMU , o curso oferece a perfeita orientação e assistência na colocação profissional. Se você tiver alguma dúvida ou pergunta, deixe-nos uma mensagem, teremos o maior prazer em entrar em contato com você.