
Co to jest uczenie maszynowe w języku Java? Jak to wdrożyć?
Opublikowany: 2021-03-10Spis treści
Co to jest uczenie maszynowe?
Uczenie maszynowe to dział sztucznej inteligencji, który uczy się na podstawie dostępnych danych, przykładów i doświadczeń, aby naśladować ludzkie zachowanie i inteligencję. Program stworzony przy użyciu uczenia maszynowego może samodzielnie budować logikę bez konieczności ręcznego pisania kodu przez człowieka.
Wszystko zaczęło się od testu Turinga we wczesnych latach pięćdziesiątych, kiedy Alan Turning doszedł do wniosku, że aby komputer miał prawdziwą inteligencję, musiałby manipulować lub przekonać człowieka, że jest również człowiekiem. Uczenie maszynowe jest stosunkowo starą koncepcją, ale dopiero dziś ta rozwijająca się dziedzina może zostać zrealizowana, ponieważ komputery mogą teraz przetwarzać złożone algorytmy. Algorytmy uczenia maszynowego ewoluowały w ciągu ostatniej dekady, obejmując złożone umiejętności obliczeniowe, co z kolei doprowadziło do ulepszenia ich możliwości naśladowania.
W alarmującym tempie wzrosła również liczba zastosowań uczenia maszynowego. Od opieki zdrowotnej, finansów, analityki i edukacji po produkcję, marketing i operacje rządowe, każda branża odnotowała znaczny wzrost jakości i wydajności po wdrożeniu technologii uczenia maszynowego. Na całym świecie nastąpiły szeroko zakrojone ulepszenia jakościowe, co napędza zapotrzebowanie na specjalistów od uczenia maszynowego.
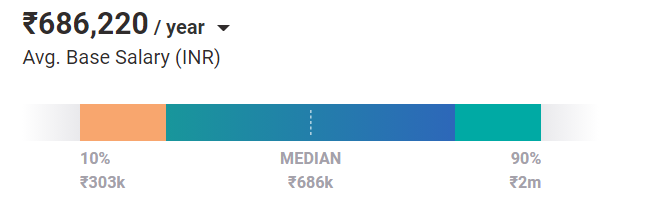
Obecnie inżynierowie uczenia maszynowego są warci przeciętnie 686 220 jenów rocznie . I tak jest w przypadku pozycji na poziomie podstawowym. Dzięki doświadczeniu i umiejętnościom mogą zarobić w Indiach do 2 mln funtów rocznie.
Rodzaje algorytmów uczenia maszynowego
Istnieją trzy typy algorytmów uczenia maszynowego:
1. Uczenie nadzorowane : w tego rodzaju uczeniu zestawy danych szkoleniowych kierują algorytmem do podejmowania dokładnych przewidywań lub decyzji analitycznych. Wykorzystuje uczenie się na podstawie wcześniejszych zestawów danych treningowych do przetwarzania nowych danych. Oto kilka przykładów modeli uczenia maszynowego uczenia nadzorowanego:

- Regresja liniowa
- Regresja logistyczna
- Drzewo decyzyjne
2. Nienadzorowane uczenie się : w tym typie uczenia się, model uczenia maszynowego uczy się z nieoznaczonych fragmentów informacji. Wykorzystuje grupowanie danych poprzez grupowanie obiektów lub zrozumienie relacji między nimi lub wykorzystywanie ich właściwości statystycznych do przeprowadzania analiz. Przykładami nienadzorowanych algorytmów uczenia się są:
- Grupowanie K-średnich
- Klastrowanie hierarchiczne
3. Uczenie się przez wzmacnianie : Ten proces opiera się na trafieniu i próbie. To uczenie się poprzez interakcję z przestrzenią lub środowiskiem. Algorytm RL uczy się na swoich przeszłych doświadczeniach poprzez interakcję z otoczeniem i określanie najlepszego sposobu działania.
Jak zaimplementować uczenie maszynowe w Javie?
Java jest jednym z najlepszych języków programowania wykorzystywanych do implementacji algorytmów uczenia maszynowego. Większość jego bibliotek jest typu open source, zapewniając obszerną obsługę dokumentacji, łatwą konserwację, zbywalność i łatwą czytelność.
W zależności od popularności, oto 10 najlepszych bibliotek uczenia maszynowego wykorzystywanych do implementacji uczenia maszynowego w Javie.
1. ADAMS
Zaawansowany system eksploracji danych i uczenia maszynowego lub ADAMS zajmuje się budowaniem nowatorskich i elastycznych systemów przepływu pracy oraz zarządzaniem złożonymi procesami w świecie rzeczywistym. Program ADAMS wykorzystuje architekturę podobną do drzewa do zarządzania przepływem danych zamiast wykonywania ręcznych połączeń wejścia-wyjścia.
Eliminuje potrzebę wyraźnych połączeń. Opiera się na zasadzie „mniej znaczy więcej” i wykonuje wyszukiwanie, wizualizację i wizualizacje oparte na danych. ADAMS jest biegły w przetwarzaniu danych, przesyłaniu strumieniowym danych, zarządzaniu bazami danych, pisaniu skryptów i dokumentacji.
2. JavaML
JavaML oferuje różne algorytmy uczenia maszynowego i eksploracji danych, które zostały napisane dla Javy, aby wspierać inżynierów oprogramowania, programistów, naukowców zajmujących się danymi i badaczy. Każdy algorytm ma wspólny interfejs, który jest łatwy w użyciu i ma obszerną obsługę dokumentacji, mimo że nie ma GUI.
W porównaniu z innymi algorytmami klastrowania, implementacja jest dość prosta i nieskomplikowana. Jego podstawowe funkcje obejmują manipulację danymi, dokumentację, zarządzanie bazami danych, klasyfikację danych, grupowanie, wybór funkcji i tak dalej.
Dołącz do kursu uczenia maszynowego online z najlepszych uniwersytetów na świecie — studiów magisterskich, programów podyplomowych dla kadry kierowniczej i zaawansowanego programu certyfikacji w zakresie uczenia maszynowego i sztucznej inteligencji, aby przyspieszyć swoją karierę.
3. WEKA
Weka to także biblioteka uczenia maszynowego typu open source napisana dla Javy, która obsługuje głębokie uczenie. Zapewnia zestaw algorytmów uczenia maszynowego i znajduje szerokie zastosowanie między innymi w eksploracji danych, przygotowaniu danych, grupowaniu danych, wizualizacji danych i regresji.
Przykład: zademonstrujemy to na małym zestawie danych dotyczących cukrzycy.
Krok 1 : Załaduj dane za pomocą Weka
| importuj weka.core.Instances; importuj weka.core.converters.ConverterUtils.DataSource; klasa publiczna Główna { public static void main(String[] args) wyrzuca Wyjątek { // Określanie źródła danych DataSource dataSource = new DataSource("data.arff"); // Ładowanie zbioru danych Instancje dataInstances = dataSource.getDataSet(); // Wyświetlanie liczby instancji log.info(„Liczba załadowanych instancji wynosi: ” + dataInstances.numInstances()); log.info(„dane:” + dataInstances.toString()); } } |
Krok 2: Zbiór danych zawiera 768 instancji. Musimy uzyskać dostęp do liczby atrybutów, tj. 9.
| log.info(„Liczba atrybutów (funkcji) w zbiorze danych: ” + dataInstances.numAttributes()); |
Krok 3 : Musimy określić kolumnę docelową, zanim zbudujemy model i znajdziemy liczbę klas.
| // Identyfikacja indeksu etykiety dataInstances.setClassIndex(dataInstances.numAttributes() – 1); // Uzyskanie liczby log.info(„Liczba klas: ” + dataInstances.numClasses()); |
Krok 4 : Zbudujemy teraz model za pomocą prostego klasyfikatora drzewa, J48.
| // Tworzenie klasyfikatora drzewa decyzyjnego J48 treeClassifier = new J48(); treeClassifier.setOptions(new String[] { “-U” }); treeClassifier.buildClassifier(dataInstances); |
Powyższy kod przedstawia sposób tworzenia nieoczyszczonego drzewa, które składa się z wystąpień danych wymaganych do uczenia modelu. Po wydrukowaniu struktury drzewa po uczeniu modelu możemy określić, w jaki sposób reguły zostały zbudowane wewnętrznie.
| plas <= 127 | masa <= 26,4 | | preg <= 7: testowany_ujemny (117.0/1.0) | | w ciąży > 7 | | | masa <= 0: testowany_dodatni (2.0) | | | masa > 0: testowane_ujemne (13.0) | masa > 26,4 | | wiek <= 28: testowany_ujemny (180,0/22,0) | | wiek > 28 | | | plas <= 99: testowane_ujemne (55.0/10.0) | | | plas > 99 | | | | pedi <= 0,56: testowane_ujemne (84,0/34,0) | | | | pedi> 0,56 | | | | | ciężar <= 6 | | | | | | wiek <= 30: testowany_pozytywny (4.0) | | | | | | wiek > 30 | | | | | | | wiek <= 34: testowany_ujemny (7,0/1,0) | | | | | | | wiek > 34 | | | | | | | | masa <= 33,1: testowany_dodatni (6.0) | | | | | | | | masa > 33,1: testowane_ujemne (4.0/1.0) | | | | | ciąża > 6: testowany_dodatni (13.0) plas > 127 | masa <= 29,9 | | plas <= 145: testowane_ujemne (41,0/6,0) | | plas > 145 | | | wiek <= 25: testowany_ujemny (4,0) | | | wiek > 25 | | | | wiek <= 61 | | | | | masa <= 27,1: testowany_dodatni (12.0/1.0) | | | | | masa > 27,1 | | | | | | ciśnienie <= 82 | | | | | | | pedi <= 0,396: testowany_dodatni (8,0/1,0)  | | | | | | | pedi > 0,396: testowane_ujemne (3,0) | | | | | | pres > 82: testowane_ujemne (4.0) | | | | wiek > 61 lat: testowany_negatywny (4.0) | masa > 29,9 | | plas <= 157 | | | pres <= 61: testowany_dodatni (15.0/1.0) | | | ciśnienie > 61 | | | | wiek <= 30: testowany_negatywny (40.0/13.0) | | | | wiek > 30 lat: test_pozytywny (60.0/17.0) | | plas > 157: test_pozytywny (92.0/12.0) Liczba liści: 22 Wielkość drzewka : 43 |
4. Apache Mahaut
Mahaut to zbiór algorytmów, które pomagają wdrożyć uczenie maszynowe przy użyciu języka Java. Jest to skalowalna struktura algebry liniowej, za pomocą której programiści mogą przeprowadzać matematykę, statystycy analizy. Jest zwykle używany przez naukowców zajmujących się danymi, inżynierów badawczych i specjalistów analitycznych do tworzenia aplikacji gotowych do użytku w przedsiębiorstwach. Jego skalowalność i elastyczność umożliwia użytkownikom szybkie i łatwe wdrażanie klastrów danych, systemów rekomendacji oraz tworzenie wydajnych aplikacji do uczenia maszynowego.
5. Głębokie uczenie4j
Deeplearning4j to biblioteka programistyczna napisana w Javie i oferująca szerokie wsparcie dla głębokiego uczenia. Jest to platforma typu open source, która łączy głębokie sieci neuronowe i głębokie uczenie się przez wzmacnianie w celu obsługi operacji biznesowych. Jest kompatybilny ze Scala, Kotlin, Apache Spark, Hadoop i innymi językami JVM oraz frameworkami obliczeniowymi Big Data.
Jest zwykle używany do wykrywania wzorców i emocji w głosie, mowie i tekście pisanym. Służy jako narzędzie do majsterkowania, które może wykrywać rozbieżności w transakcjach i obsługiwać wiele zadań. Jest to dystrybuowana biblioteka klasy komercyjnej, która posiada szczegółową dokumentację API ze względu na jej charakter open source.
Oto przykład, jak można wdrożyć uczenie maszynowe za pomocą Deeplearning4j.
Przykład : Używając Deeplearning4j, zbudujemy model Convolution Neural Network (CNN) do klasyfikacji odręcznych cyfr za pomocą biblioteki MNIST.
Krok 1 : Załaduj zbiór danych, aby wyświetlić jego rozmiar.
| DataSetIterator MNISTTrain = new MnistDataSetIterator(batchSize,true,seed); DataSetIterator MNISTTest = new MnistDataSetIterator(batchSize,false,seed); |
Krok 2 : Upewnij się, że zbiór danych zawiera dziesięć unikalnych etykiet.
| log.info(„Liczba wszystkich etykiet znalezionych w treningowym zbiorze danych ” + MNISTTrain.totalOutcomes()); log.info(„Liczba wszystkich etykiet znalezionych w testowym zestawie danych ” + MNISTTest.totalOutcomes()); |
Krok 3 : Teraz skonfigurujemy architekturę modelu przy użyciu dwóch warstw splotu wraz ze spłaszczoną warstwą, aby wyświetlić dane wyjściowe.
W Deeplearning4j dostępne są opcje, które pozwalają zainicjować schemat wag.
| // Budowa modelu CNN MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(seed)//losowe seed .l2(0.0005) // regularyzacja .weightInit(WeightInit.XAVIER) // inicjalizacja schematu wag .updater(new Adam(1e-3)) // Ustawianie algorytmu optymalizacji .lista() .layer(nowy ConvolutionLayer.Builder(5, 5) //Ustawianie kroku, rozmiaru jądra i funkcji aktywacji. .nIn(nKanały) .krok(1,1) .nOut(20) .aktywacja(Aktywacja.IDENTYFIKACJA) .zbudować()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // próbkowanie w dół splotu .kernelSize(2,2) .krok(2,2) .zbudować()) .layer(nowy ConvolutionLayer.Builder(5, 5) // Ustawienie kroku, rozmiaru jądra i funkcji aktywacji. .krok(1,1) .nOut(50) .aktywacja(Aktywacja.IDENTYFIKACJA) .zbudować()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // próbkowanie w dół splotu .kernelSize(2,2) .krok(2,2) .zbudować()) .layer(nowy DenseLayer.Builder().activation(Activation.RELU) .nOut(500).build()) .layer(nowy OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(numerwyjściowy) .aktywacja(Aktywacja.SOFTMAX) .zbudować()) // końcowa warstwa wyjściowa ma wymiary 28×28 i głębokość 1. .setInputType(InputType.convolutionalFlat(28,28,1)) .zbudować(); |
Krok 4 : Po skonfigurowaniu architektury zainicjujemy tryb i treningowy zestaw danych oraz rozpoczniemy trenowanie modelu.
| Model sieci wielowarstwowej = new MultiLayerNetwork(conf); // zainicjuj wagi modeli. model.init(); log.info(„Krok 2: rozpocznij trenowanie modelu”); //Ustawianie słuchacza co 10 iteracji i ocenianie na zestawie testowym w każdej epoce model.setListeners(nowy ScoreIterationListener(10), nowy EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); // Trening modelki model.fit(Pociąg MNIST, Epoki); |
Gdy rozpocznie się uczenie modelu, otrzymasz macierz pomyłek dokładności klasyfikacji.
Oto dokładność modelu po dziesięciu epokach treningowych:
| =====Matryca zamieszania======================== == 0 1 2 3 4 5 6 7 8 9 —————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. ELKI
Środowisko do tworzenia aplikacji KDD Obsługiwane przez Index-structure lub ELKI to zbiór wbudowanych algorytmów i programów służących do eksploracji danych. Napisana w Javie jest biblioteką typu open source, która zawiera wysoce konfigurowalne parametry w algorytmach. Jest zwykle używany przez naukowców i studentów w celu uzyskania wglądu w zbiory danych. Jak sama nazwa wskazuje, zapewnia środowisko do tworzenia zaawansowanych programów do eksploracji danych i baz danych przy użyciu struktury indeksu.
7. JSAT
Java Statistical Analysis Tool lub JSAT to biblioteka GPL3, która wykorzystuje framework zorientowany obiektowo, aby pomóc użytkownikom wdrażać uczenie maszynowe w języku Java. Jest zwykle używany do samokształcenia przez studentów i programistów. W porównaniu do innych bibliotek implementacyjnych AI, JSAT ma największą liczbę algorytmów ML i jest najszybszy spośród wszystkich frameworków. Przy zerowych zależnościach zewnętrznych jest wysoce elastyczny i wydajny oraz oferuje wysoką wydajność.
8. Struktura uczenia maszynowego Encog
Encog jest napisany w Javie i C# i zawiera biblioteki, które pomagają implementować algorytmy uczenia maszynowego. Służy do budowania algorytmów genetycznych, sieci bayesowskich, modeli statystycznych, takich jak ukryty model Markowa i nie tylko.
9. Młotek
Uczenie maszynowe dla Language Toolkit lub Mallet jest wykorzystywane w przetwarzaniu języka naturalnego (NLP). Podobnie jak większość innych struktur implementacji ML, Mallet zapewnia również obsługę modelowania danych, grupowania danych, przetwarzania dokumentów, klasyfikacji dokumentów i tak dalej.
10. Spark MLlib
Spark MLlib jest używany przez firmy do zwiększania wydajności i skalowalności zarządzania przepływem pracy. Przetwarza duże ilości danych i obsługuje mocno obciążone algorytmy ML.
Zamówienie: Pomysły na projekty uczenia maszynowego
Wniosek
To prowadzi nas do końca artykułu. Aby uzyskać więcej informacji na temat koncepcji uczenia maszynowego, skontaktuj się z najlepszymi wydziałami IIIT Bangalore i Liverpool John Moores University w ramach programu upGrad Master of Science in Machine Learning & AI.
Dlaczego powinniśmy używać Javy razem z uczeniem maszynowym?
Specjalistom ds. uczenia maszynowego łatwiej będzie komunikować się z obecnymi repozytoriami kodu, jeśli wybiorą Java jako język programowania dla swoich projektów. Jest to preferowany język uczenia maszynowego ze względu na takie funkcje, jak łatwość obsługi, usługi pakietowe, lepsza interakcja z użytkownikiem, szybkie debugowanie i graficzna ilustracja danych. Java ułatwia programistom uczenia maszynowego skalowanie swoich systemów, dzięki czemu jest doskonałym wyborem do tworzenia od podstaw dużych, wyrafinowanych aplikacji uczenia maszynowego. Java Virtual Machine (JVM) obsługuje szereg zintegrowanych środowisk programistycznych (IDE), które umożliwiają uczącym się maszynom szybkie projektowanie nowych narzędzi.
Czy nauka Javy jest łatwa?
Ponieważ Java jest językiem wysokiego poziomu, jest łatwy do zrozumienia. Jako uczeń nie będziesz musiał zagłębiać się w szczegóły, ponieważ jest to dobrze ustrukturyzowany, zorientowany obiektowo język, który jest na tyle prosty, że nowicjusze mogą go nauczyć. Ponieważ istnieje wiele procedur, które działają automatycznie, możesz je szybko opanować. Nie musisz zagłębiać się w szczegóły tego, jak tam działają. Java to niezależny od platformy język programowania. Umożliwia programiście stworzenie aplikacji mobilnej, z której można korzystać na dowolnym urządzeniu. Jest to preferowany język Internetu Rzeczy, a także najlepsze narzędzie do tworzenia aplikacji na poziomie korporacyjnym.
Co to jest ADAMS i jak jest pomocny w uczeniu maszynowym?
Zaawansowany system eksploracji danych i uczenia maszynowego (ADAMS) to silnik przepływu pracy na licencji GPLv3 do szybkiego tworzenia i zarządzania reaktywnymi przepływami pracy opartymi na danych, które można łatwo włączyć do procesów biznesowych. Sercem ADAMS jest silnik przepływu pracy, który działa zgodnie z zasadą „mniej znaczy więcej”. Program ADAMS wykorzystuje strukturę podobną do drzewa, zamiast umożliwiać użytkownikowi rozmieszczenie operatorów (lub aktorów w żargonie programu ADAMS) na kanwie, a następnie ręczne łączenie danych wejściowych i wyjściowych. Nie są wymagane żadne wyraźne połączenia, ponieważ ta struktura i aktorzy kontrolujący określają sposób przepływu danych w procesie. Wewnętrzna reprezentacja obiektu i zagnieżdżanie podoperatorów w ramach obsługi operatorów skutkują strukturą podobną do drzewa. ADAMS zapewnia zróżnicowany zestaw agentów do pobierania, przetwarzania, eksploracji i wyświetlania danych.