
Czym jest drzewo decyzyjne w eksploracji danych? Typy, przykłady i zastosowania ze świata rzeczywistego
Opublikowany: 2021-06-15Spis treści
Wprowadzenie do eksploracji danych
Dane są często przedstawiane jako surowe dane, które należy skutecznie przetworzyć w celu przekształcenia ich w przydatne informacje. Przewidywanie wyników często opiera się na procesie znajdowania wzorców, anomalii lub korelacji w danych. Proces ten nazwano „odkrywaniem wiedzy w bazach danych”.
Dopiero w latach 90. ukuto termin „eksploracja danych”. Eksploracja danych powstała w trzech dyscyplinach: statystyka, sztuczna inteligencja i uczenie maszynowe. Zautomatyzowana eksploracja danych zmieniła proces analizy ze żmudnego na szybsze podejście. Eksploracja danych pozwala użytkownikowi:
- Usuń wszystkie zaszumione i chaotyczne dane
- Zrozum odpowiednie dane i wykorzystaj je do przewidywania przydatnych informacji.
- Proces przewidywania świadomych decyzji zostaje przyspieszony .
Eksploracja danych może być również określana jako proces identyfikacji ukrytych wzorców informacji, które wymagają kategoryzacji. Dopiero wtedy dane mogą zostać przekonwertowane na użyteczne dane. Użyteczne dane mogą być wprowadzane do hurtowni danych, algorytmów eksploracji danych, analizy danych w celu podejmowania decyzji.
Drzewo decyzyjne w eksploracji danych
Rodzaj techniki eksploracji danych, drzewo decyzyjne w eksploracji danych, buduje model klasyfikacji danych. Modele są zbudowane w formie struktury drzewiastej i dlatego należą do nadzorowanej formy uczenia się. Oprócz modeli klasyfikacyjnych drzewa decyzyjne są wykorzystywane do budowania modeli regresji do przewidywania etykiet klas lub wartości wspomagających proces podejmowania decyzji. Drzewo decyzyjne może wykorzystywać zarówno dane liczbowe, jak i kategoryczne, takie jak płeć, wiek itp.
Struktura drzewa decyzyjnego
Struktura drzewa decyzyjnego składa się z węzła głównego, gałęzi i węzłów liści. Węzły rozgałęzione są wynikiem drzewa, a węzły wewnętrzne reprezentują test atrybutu. Węzły liści reprezentują etykietę klasy.
Działanie drzewa decyzyjnego
1. Drzewo decyzyjne działa w ramach podejścia nadzorowanego uczenia się zarówno dla zmiennych dyskretnych, jak i ciągłych. Zestaw danych jest podzielony na podzbiory na podstawie najważniejszego atrybutu zestawu danych. Identyfikacja atrybutu i podział odbywa się za pomocą algorytmów.
2. Struktura drzewa decyzyjnego składa się z węzła głównego, który jest istotnym węzłem predykcyjnym. Proces dzielenia odbywa się z węzłów decyzyjnych, które są podwęzłami drzewa. Węzły, które nie dzielą się dalej, są określane jako węzły-liście lub węzły końcowe.
3. Zbiór danych jest podzielony na jednorodne i nienakładające się regiony zgodnie z podejściem odgórnym. Górna warstwa zapewnia obserwacje w jednym miejscu, które następnie rozdziela się na gałęzie. Proces ten jest określany jako „podejście chciwe” ze względu na skupienie się tylko na bieżącym węźle, a nie na przyszłych węzłach.
4. Dopóki nie zostanie osiągnięte kryterium zatrzymania, drzewo decyzyjne będzie nadal działać.
5. Wraz z budową drzewa decyzyjnego generowanych jest dużo hałasu i wartości odstających. Aby usunąć te wartości odstające i zaszumione dane, stosuje się metodę „przycinania drzew”. Stąd dokładność modelu wzrasta.
6. Dokładność modelu jest sprawdzana na zestawie testowym składającym się z krotek testowych i etykiet klas. Dokładny model jest definiowany na podstawie odsetka krotek i klas zestawu testów klasyfikacji według modelu.
Rysunek 1 : Przykład drzewa nieprzyciętego i przyciętego
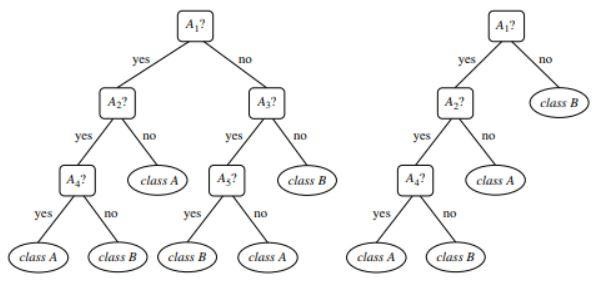
Źródło
Rodzaje drzew decyzyjnych
Drzewa decyzyjne prowadzą do opracowania modeli klasyfikacji i regresji opartych na strukturze drzewiastej. Dane są podzielone na mniejsze podzbiory. Wynikiem drzewa decyzyjnego jest drzewo zawierające węzły decyzyjne i węzły liści. Poniżej wyjaśniono dwa rodzaje drzew decyzyjnych:
1. Klasyfikacja
Klasyfikacja obejmuje tworzenie modeli opisujących ważne etykiety klas. Są stosowane w obszarach uczenia maszynowego i rozpoznawania wzorców. Drzewa decyzyjne w uczeniu maszynowym za pomocą modeli klasyfikacyjnych prowadzą do wykrywania oszustw, diagnozy medycznej itp. Dwuetapowy proces modelu klasyfikacji obejmuje:
- Nauka: budowany jest model klasyfikacji oparty na danych uczących.
- Klasyfikacja: Dokładność modelu jest sprawdzana, a następnie wykorzystywana do klasyfikacji nowych danych. Etykiety klas mają postać wartości dyskretnych, takich jak „tak” lub „nie” itp.
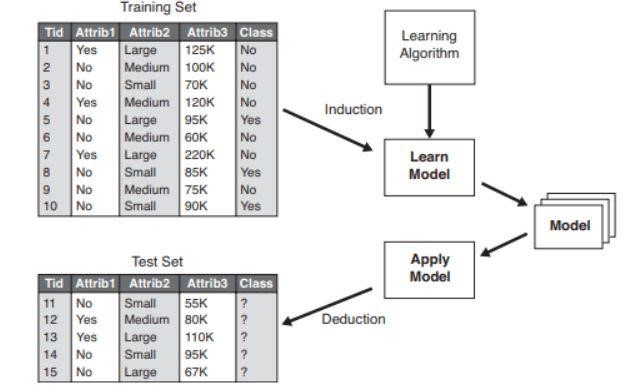
Rysunek 2 : Przykład modelu klasyfikacji .
Źródło
2. Regresja
Modele regresji służą do analizy regresji danych, tj. przewidywania atrybutów liczbowych. Są to również nazywane wartościami ciągłymi. Dlatego zamiast przewidywać etykiety klas, model regresji przewiduje wartości ciągłe.
Lista używanych algorytmów
Algorytm drzewa decyzyjnego znany jako „ID3” został opracowany w 1980 roku przez badacza maszyn, J. Rossa Quinlana. Algorytm ten został zastąpiony przez inne opracowane przez niego algorytmy, takie jak C4.5. Oba algorytmy zastosowały podejście zachłanne. Algorytm C4.5 nie używa śledzenia wstecznego, a drzewa są konstruowane w sposób rekurencyjny zstępujący, dziel i zwyciężaj. Algorytm używał uczącego zestawu danych z etykietami klas, które są dzielone na mniejsze podzbiory w miarę tworzenia drzewa.
- Wstępnie wybierane są trzy parametry — lista atrybutów, metoda wyboru atrybutu i podział danych. Atrybuty zestawu uczącego są opisane na liście atrybutów.
- Metoda selekcji atrybucji obejmuje metodę selekcji najlepszego atrybutu do dyskryminacji wśród krotek.
- Struktura drzewa zależy od metody wyboru atrybutów.
- Budowa drzewa zaczyna się od pojedynczego węzła.
- Podział krotek występuje, gdy różne etykiety klas są reprezentowane w krotce. Doprowadzi to do powstania gałęzi drzewa.
- Sposób podziału określa, który atrybut należy wybrać dla partycji danych. W oparciu o tę metodę gałęzie wyrastają z węzła na podstawie wyniku testu.
- Metoda dzielenia i partycjonowania jest przeprowadzana rekursywnie, co ostatecznie skutkuje powstaniem drzewa decyzyjnego dla krotek uczących zbiorów danych.
- Proces tworzenia drzewa trwa do momentu, aż pozostałe krotki nie będą mogły być dalej dzielone.
- Złożoność algorytmu oznaczona jest przez
n * |D| * log |D|
Gdzie n jest liczbą atrybutów w uczącym zbiorze danych D i |D| to liczba krotek.
Źródło
Rysunek 3: Podział wartości dyskretnych
Listy algorytmów wykorzystywanych w drzewie decyzyjnym to:
ID3
Cały zestaw danych S jest uważany za węzeł główny podczas tworzenia drzewa decyzyjnego. Następnie przeprowadza się iterację na każdym atrybucie i dzieli dane na fragmenty. Algorytm sprawdza i pobiera te atrybuty, które nie zostały wzięte przed iteracją. Dzielenie danych w algorytmie ID3 jest czasochłonne i nie jest idealnym algorytmem, ponieważ przepełnia dane.
C4,5
Jest to zaawansowana forma algorytmu, ponieważ dane są klasyfikowane jako próbki. W przeciwieństwie do ID3, można efektywnie obsługiwać zarówno wartości ciągłe, jak i dyskretne. Obecna jest metoda cięcia, która usuwa niechciane gałęzie.
WÓZEK
Algorytm może wykonać zarówno zadania klasyfikacyjne, jak i regresyjne. W przeciwieństwie do ID3 i C4.5, punkty decyzyjne są tworzone przez uwzględnienie indeksu Giniego. W metodzie podziału stosowany jest algorytm zachłanny mający na celu zmniejszenie funkcji kosztu. W zadaniach klasyfikacyjnych indeks Giniego jest używany jako funkcja kosztu do wskazania czystości węzłów liści. W zadaniach regresji błąd sumy kwadratów jest używany jako funkcja kosztu w celu znalezienia najlepszej prognozy.
CHAID
Jak sama nazwa wskazuje, oznacza to automatyczny detektor interakcji chi-kwadrat, proces zajmujący się dowolnymi zmiennymi. Mogą to być zmienne nominalne, porządkowe lub ciągłe. Drzewa regresji wykorzystują test F, natomiast w modelu klasyfikacyjnym test Chi-kwadrat.
MARS
Oznacza splajny wielowymiarowej adaptacyjnej regresji. Algorytm jest specjalnie zaimplementowany w zadaniach regresji, gdzie dane są w większości nieliniowe.

Greedy rekurencyjne dzielenie binarne
Występuje metoda dzielenia binarnego, w wyniku której powstają dwie gałęzie. Podział krotek odbywa się z obliczeniem funkcji kosztu podziału. Wybierany jest najniższy podział kosztów, a proces jest rekurencyjnie przeprowadzany w celu obliczenia funkcji kosztu innych krotek.
Drzewo decyzyjne z przykładem ze świata rzeczywistego
Przewiduj proces kwalifikowalności pożyczki na podstawie podanych danych.
Krok 1: Ładowanie danych
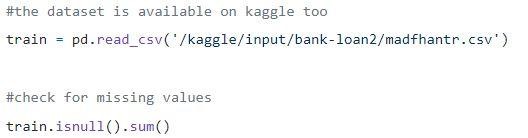
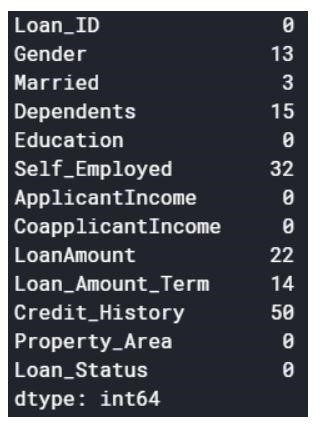
Wartości null mogą zostać usunięte lub wypełnione niektórymi wartościami. Kształt oryginalnego zestawu danych to (614,13), a nowy zestaw danych po usunięciu wartości null to (480,13).
Krok 2: spojrzenie na zbiór danych.

Krok 3: Podział danych na zestawy treningowe i testowe.
Krok 4: Zbuduj model i dopasuj zestaw pociągów

Przed wizualizacją należy wykonać pewne obliczenia.
Obliczenie 1: oblicz entropię całego zbioru danych.

Obliczenie 2: Znajdź entropię i zysk dla każdej kolumny.
- Kolumna Płeć
- Warunek 1: zestaw danych ze wszystkimi mężczyznami w nim, a następnie,
p = 278, n=116 , p+n=489
Entropia (G=mężczyzna) = 0,87
- Warunek 2: zestaw danych z wszystkimi kobietami w nim, a następnie,
p = 54 , n = 32 , p+n = 86
Entropia (G=kobieta) = 0,95
- Średnia informacja w kolumnie płeć

- Kolumna żonaty
- Warunek 1: Żonaty = Tak(1)
W tym podziale cały zestaw danych ze statusem Żonaty tak
p = 227 , n = 84 , p+n = 311
E(żonaty = Tak) = 0,84
- Warunek 2: żonaty = Nie (0)
W tym podziale cały zestaw danych ze statusem Żonaty nr
p = 105 , n = 64 , p+n = 169
E(żonaty = nie) = 0,957
- Średnia informacja w kolumnie Żonaty to
- Kolumna edukacyjna
- Warunek 1: Edukacja = Absolwent(1)
p = 271 , n = 112 , p+n = 383
E(Wykształcenie = Absolwent) = 0,87
- Warunek 2: Wykształcenie = brak absolwenta (0)
p = 61 , n = 36 , p+n = 97
E (Wykształcenie = Nie Absolwent) = 0,95
- Kolumna Średnia informacja o edukacji = 0,886
Zysk = 0,01
4) Kolumna samozatrudniona
- Warunek 1: Samozatrudniony = Tak(1)
p = 43 , n = 23 , p+n = 66
E(Samozatrudniony=Tak) = 0,93
- Warunek 2: Samozatrudniony = Nie(0)
p = 289 , n = 125 , p+n = 414
E (samozatrudniony = nie) = 0,88
- Średnia informacja w kolumnie Samozatrudnieni w edukacji = 0,886
Zysk = 0,01
- Kolumna Credit Score: kolumna ma wartość 0 i 1.
- Warunek 1: Ocena kredytowa = 1
p = 325 , n = 85 , p+n = 410
E (wynik kredytowy = 1) = 0,73
- Warunek 2: Ocena kredytowa = 0
p = 63 , n = 7 , p+n = 70
E (wynik kredytowy = 0) = 0,46
- Średnia informacja w kolumnie Credit Score = 0,69
Zysk = 0,2
Porównaj wszystkie wartości wzmocnienia

Punktacja kredytowa ma najwyższy zysk. Dlatego będzie używany jako węzeł główny.
Krok 5: Wizualizuj drzewo decyzyjne

Rysunek 5: Drzewo decyzyjne z kryterium Gini
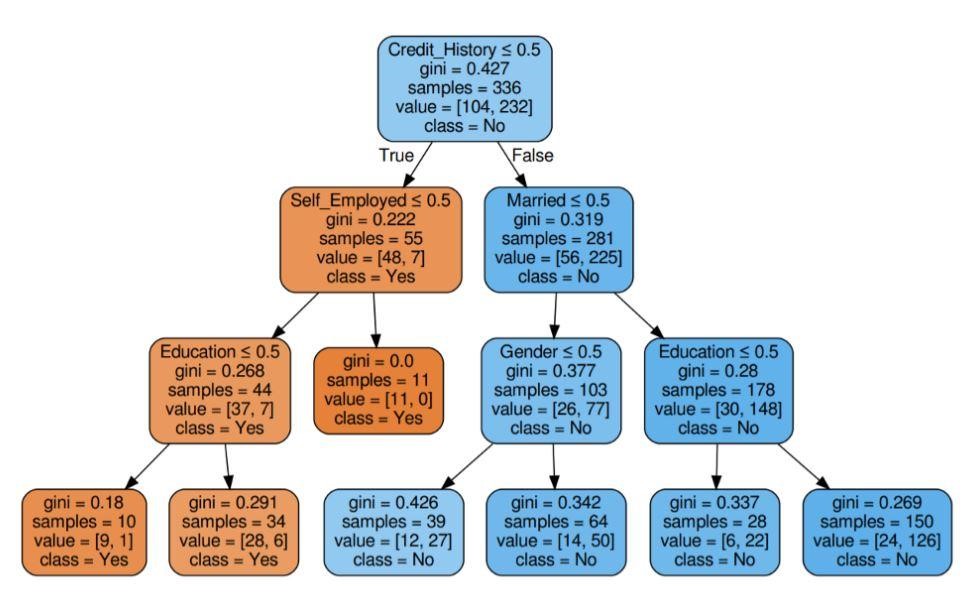 Źródło
Źródło
Rysunek 6: Drzewo decyzyjne z entropią kryterium
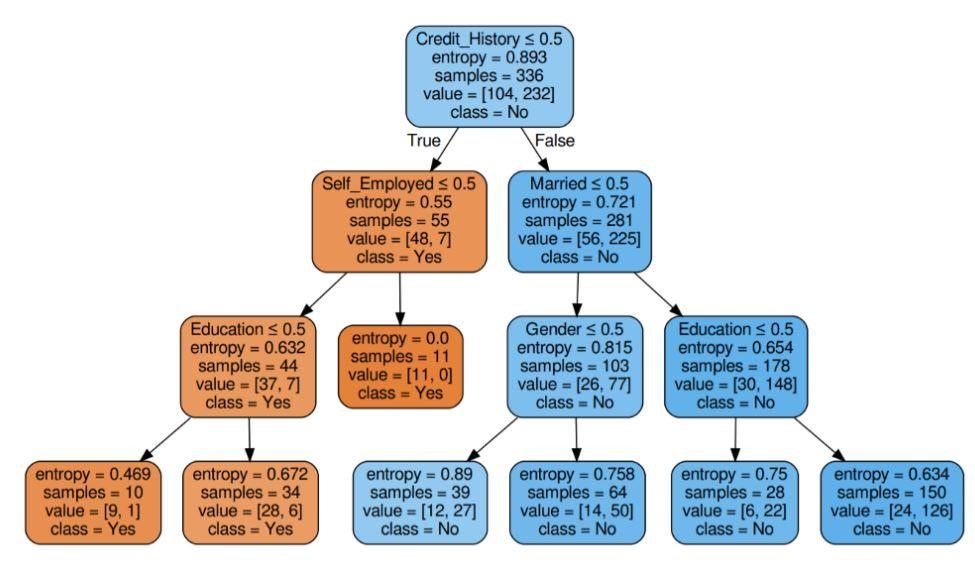
Źródło
Krok 6: Sprawdź wynik modelu
Prawie 80% trafności osiągnięta.
Lista aplikacji
Drzewa decyzyjne są najczęściej wykorzystywane przez ekspertów ds. informacji do prowadzenia badań analitycznych. Mogą być szeroko wykorzystywane do celów biznesowych do analizowania lub przewidywania trudności. Elastyczność drzewa decyzyjnego pozwala na ich wykorzystanie w innym obszarze:
1. Opieka zdrowotna
Drzewa decyzyjne umożliwiają przewidywanie, czy pacjent cierpi na konkretną chorobę z uwzględnieniem wieku, wagi, płci itp. Inne przewidywania obejmują decydowanie o działaniu leku z uwzględnieniem takich czynników, jak skład, okres produkcji itp.
2. Sektory bankowe
Drzewa decyzyjne pomagają w przewidywaniu, czy dana osoba kwalifikuje się do pożyczki, biorąc pod uwagę jej stan majątkowy, wynagrodzenie, członków rodziny itp. Może również identyfikować oszustwa związane z kartami kredytowymi, niespłacanie kredytów itp.
3. Sektory edukacyjne
Krótka lista ucznia na podstawie jego osiągnięć, frekwencji itp. może zostać określona za pomocą drzew decyzyjnych.
Lista zalet
- Interpretowalne wyniki modelu decyzyjnego można przedstawić kierownictwu wyższego szczebla i interesariuszom.
- Podczas budowania modelu drzewa decyzyjnego nie jest wymagane wstępne przetwarzanie danych tj. normalizacja, skalowanie itp.
- Oba typy danych – numeryczne i kategoryczne mogą być obsługiwane przez drzewo decyzyjne, które wykazuje wyższą efektywność wykorzystania w porównaniu z innymi algorytmami.
- Brakująca wartość w danych nie wpływa na proces drzewa decyzyjnego, co czyni go elastycznym algorytmem.
Co następne?
Jeśli jesteś zainteresowany zdobyciem praktycznego doświadczenia w eksploracji danych i przeszkoleniem przez ekspertów w dziedzinie, możesz zapoznać się z programem PG Executive PG w dziedzinie nauki o danych. Kurs jest skierowany do każdej grupy wiekowej w wieku 21-45 lat z minimalnymi kryteriami kwalifikacyjnymi wynoszącymi 50% lub równoważnymi ocenami końcowymi. Każdy pracujący profesjonalista może dołączyć do tego wykonawczego programu PG certyfikowanego przez IIIT Bangalore.
Drzewa decyzyjne w eksploracji danych mają możliwość obsługi bardzo skomplikowanych danych. Wszystkie drzewa decyzyjne mają trzy istotne węzły lub części. Omówmy każdy z nich poniżej. Teraz, gdy zrozumieliśmy działanie drzew decyzyjnych, spróbujmy przyjrzeć się kilku zaletom korzystania z drzew decyzyjnych w eksploracji danychCzym jest drzewo decyzyjne w eksploracji danych?
Drzewo decyzyjne to sposób na budowanie modeli w eksploracji danych. Można to rozumieć jako odwrócone drzewo binarne. Zawiera węzeł główny, niektóre gałęzie i węzły liściowe na końcu.
Każdy z wewnętrznych węzłów w drzewie decyzyjnym oznacza badanie atrybutu. Każdy z podziałów oznacza konsekwencję tego konkretnego badania lub egzaminu. I wreszcie, każdy węzeł liścia reprezentuje tag klasy.
Głównym celem budowania drzewa decyzyjnego jest stworzenie ideału, który można wykorzystać do przewidzenia konkretnej klasy za pomocą procedur oceny na poprzednich danych.
Zaczynamy od węzła głównego, tworzymy pewne relacje ze zmienną główną i dokonujemy podziałów, które zgadzają się z tymi wartościami. Na podstawie wyborów bazowych przeskakujemy do kolejnych węzłów. Jakie są niektóre z ważnych węzłów używanych w drzewach decyzyjnych?
Kiedy połączymy wszystkie te węzły, otrzymamy podziały. Wykorzystując te węzły i podziały nieskończoną ilość razy, możemy tworzyć drzewa o różnych trudnościach. Jakie są zalety korzystania z drzew decyzyjnych?
1. Kiedy porównamy je z innymi metodami, drzewa decyzyjne nie wymagają tak wielu obliczeń do uczenia danych podczas wstępnego przetwarzania.
2. Stabilizacja informacji nie jest zaangażowana w drzewa decyzyjne.
3. Ponadto nie wymagają nawet skalowania informacji.
4. Nawet jeśli niektóre wartości zostaną pominięte w zbiorze danych, nie przeszkadza to w konstrukcji drzew.
5. Te modele są instynktownie identyczne. Są również bezstresowe dla opisu.