
Czy sieć powinna ujawniać możliwości sprzętowe?
Opublikowany: 2022-03-10Ostatnio interesowała mnie różnica opinii między różnymi dostawcami przeglądarek na temat przyszłości sieci — w szczególności w różnych wysiłkach zmierzających do zbliżenia możliwości platform internetowych do platform natywnych, takich jak Project Fugu firmy Chromium.
Główne stanowiska można podsumować jako:
- Google (wraz z partnerami takimi jak Intel, Microsoft i Samsung) agresywnie posuwa się naprzód i wprowadza innowacje dzięki mnóstwu nowych interfejsów API, takich jak te w Fugu, i dostarcza je w Chromium;
- Apple wycofuje się z bardziej konserwatywnym podejściem, oznaczając wiele nowych interfejsów API jako budzących obawy dotyczące bezpieczeństwa i prywatności;
- To (wraz z ograniczeniami Apple dotyczącymi wyboru przeglądarki w iOS) stworzyło stanowisko, że Safari jest nowym IE, jednocześnie twierdząc, że Apple spowalnia postęp sieci;
- Mozilla wydaje się w tej kwestii bliższa Apple niż Google.
Moim zamiarem w tym artykule jest przyjrzenie się twierdzeniom utożsamianym z Google, w szczególności twierdzeniom zawartym w teorii przylegania platform autorstwa lidera Project Fugu, Alexa Russella, przyjrzenie się dowodom przedstawionym w tych twierdzeniach i być może dojściem do własnego wniosku.
W szczególności zamierzam zagłębić się w WebUSB (konkretny kontrowersyjny interfejs API z Project Fugu), sprawdzić, czy roszczenia bezpieczeństwa wobec niego są zasadne i spróbować zobaczyć, czy pojawi się alternatywa.
Teoria sąsiedztwa platform
Wspomniana teoria stawia następujące twierdzenia:
- Oprogramowanie przenosi się do sieci, ponieważ jest lepszą wersją przetwarzania;
- Sieć jest meta-platformą — platformą wydzieloną z systemu operacyjnego;
- Sukces meta-platformy opiera się na osiągnięciu tego, czego oczekujemy od większości komputerów;
- Odmawianie dodawania sąsiadujących funkcji do meta-platformy internetowej ze względów bezpieczeństwa, przy jednoczesnym ignorowaniu tych samych problemów związanych z bezpieczeństwem na platformach natywnych, ostatecznie sprawi, że sieć będzie coraz mniej istotna;
- Apple i Mozilla właśnie to robią — odmawiając dodania sąsiadujących możliwości obliczeniowych do sieci, tym samym „rzucając sieć na bursztyn”.
Odnoszę się do pasji autora do utrzymywania aktualności otwartej sieci i do obawy, że zbyt powolne wzbogacanie sieci o nowe funkcje sprawi, że stanie się ona nieistotna. Jest to potęgowane przez moją niechęć do sklepów z aplikacjami i innych otoczonych murem ogrodów. Ale jako użytkownik mogę odnieść się do odwrotnej perspektywy — czasami dostaję zawrotów głowy, gdy nie wiem, jakie strony internetowe, które przeglądam, są w stanie, a jakie nie, i uważam, że ograniczenia platformy i audyty są dla mnie pocieszające.
Meta-platformy
Aby zrozumieć termin „meta-platforma”, przyjrzałem się, do czego teoria używa tej nazwy — Java i Flash, oba produkty przełomu tysiącleci.
Uważam, że porównywanie Javy lub Flasha z Internetem jest mylące. Zarówno Java, jak i Flash, jak wspomniano w teorii, były wówczas szeroko rozpowszechniane za pośrednictwem wtyczek do przeglądarek, co czyni je bardziej alternatywnymi środowiskami uruchomieniowymi jeżdżącymi na platformie przeglądarki. Dziś Java jest używana głównie na serwerze oraz jako część platformy Android i obie nie mają ze sobą wiele wspólnego poza językiem.
Dzisiaj Java po stronie serwera jest prawdopodobnie meta-platformą, a node.js jest również dobrym przykładem meta-platformy po stronie serwera. Jest to zestaw interfejsów API, wieloplatformowe środowisko uruchomieniowe i ekosystem pakietów. W rzeczywistości node.js zawsze dodaje więcej możliwości, które wcześniej były możliwe tylko jako część platformy.
Po stronie klienta, Qt, wieloplatformowy framework oparty na C++, nie jest dostarczany z oddzielnym środowiskiem wykonawczym, jest jedynie (dobrze!) wieloplatformową biblioteką do tworzenia interfejsu użytkownika.
To samo dotyczy Rusta — jest to menedżer języków i pakietów, ale nie zależy od preinstalowanych środowisk wykonawczych.
Inne sposoby tworzenia aplikacji po stronie klienta są głównie zależne od platformy, ale obejmują również niektóre wieloplatformowe rozwiązania mobilne, takie jak Flutter i Xamarin.
Możliwości a czas
Główny wykres w teorii pokazuje związek meta-platform na osi 2D możliwości w funkcji czasu:

Widzę, jak powyższy wykres ma sens, gdy mówimy o wspomnianych powyżej platformach programistycznych międzyplatformowych, takich jak Qt, Xamarin, Flutter i Rust, a także o platformach serwerowych, takich jak node.js i Java/Scala.
Ale wszystkie powyższe mają kluczową różnicę w porównaniu z siecią.
Trzeci wymiar
Wspomniane wcześniej metaplatformy rzeczywiście konkurują ze swoimi systemami hosta w wyścigu o możliwości, ale w przeciwieństwie do sieci nie mają zdania na temat zaufania i dystrybucji — trzeciego wymiaru, którego moim zdaniem brakuje na powyższym wykresie.
Qt i Rust to dobre sposoby na tworzenie aplikacji, które są dystrybuowane przez WebAssembly, pobierane i instalowane bezpośrednio w systemie operacyjnym hosta lub administrowane za pomocą menedżerów pakietów, takich jak Cargo lub dystrybucje Linuksa, takie jak Ubuntu. React Native, Flutter i Xamarin to przyzwoite sposoby tworzenia aplikacji, które są dystrybuowane za pośrednictwem sklepów z aplikacjami. Usługi node.js i Java są zwykle dystrybuowane za pośrednictwem kontenera dockera, maszyny wirtualnej lub innego mechanizmu serwera.
Użytkownicy są w większości nieświadomi tego, co zostało wykorzystane do opracowania ich treści, ale są do pewnego stopnia świadomi tego, w jaki sposób są one rozpowszechniane. Użytkownicy nie wiedzą, czym są Xamarin i node.js, a gdyby ich aplikacja Swift została pewnego dnia zastąpiona przez aplikację Flutter, większość użytkowników nie powinna się tym przejmować.
Ale użytkownicy znają sieć — wiedzą, że kiedy „przeglądają” w przeglądarce Chrome lub Firefox, są „online” i mają dostęp do treści, którym niekoniecznie ufają. Wiedzą, że pobieranie oprogramowania i instalowanie go stanowi potencjalne zagrożenie i może zostać zablokowane przez administratora IT. W rzeczywistości dla platformy internetowej ważne jest, aby użytkownicy wiedzieli, że aktualnie „przeglądają sieć”. Dlatego np. przełączenie na tryb pełnoekranowy pokazuje użytkownikowi czytelny monit z instrukcjami, jak z niego wrócić.
Sieć odniosła sukces, ponieważ nie jest przejrzysta — ale wyraźnie oddzielona od systemu operacyjnego hosta. Jeśli nie mogę ufać przeglądarce, że losowe strony internetowe nie będą czytać plików na moim twardym dysku, prawdopodobnie nie wszedłbym na żadną stronę.
Użytkownicy wiedzą również, że ich oprogramowanie komputerowe to „Windows” lub „Mac”, niezależnie od tego, czy ich telefony są z systemem Android czy iOS, i czy aktualnie korzystają z aplikacji (w systemie iOS lub Android, a do pewnego stopnia w systemie Mac OS). . System operacyjny i model dystrybucji są ogólnie znane użytkownikowi — użytkownik ufa swojemu systemowi operacyjnemu i sieci, że robią różne rzeczy i mają różne stopnie zaufania.
Nie można więc porównywać sieci do wieloplatformowych frameworków programistycznych bez uwzględnienia jej unikalnego modelu dystrybucji.
Z drugiej strony technologie internetowe są również wykorzystywane do rozwoju międzyplatformowego, z platformami takimi jak Electron i Cordova. Ale to nie do końca „sieć”. W porównaniu z Javą lub node.js, termin „Sieć” należy zastąpić terminem „Technologie internetowe”. A „technologie internetowe” używane w ten sposób niekoniecznie muszą być oparte na standardach lub działać w wielu przeglądarkach. Rozmowa na temat interfejsów API Fugu jest nieco styczna z Electron i Cordova.
Aplikacje natywne
Dodając możliwości do platformy internetowej, trzeciego wymiaru — modelu zaufania i dystrybucji — nie można ignorować ani lekceważyć. Kiedy autor twierdzi, że „Apple i Mozilla podają się za zagrożenia związane z nowymi możliwościami, przeczą akceptowanym istniejącym natywnym ryzykiem platformy” , umieszcza on platformę internetową i natywne w tym samym wymiarze, jeśli chodzi o zaufanie.
Oczywiście, aplikacje natywne mają swoje własne problemy i wyzwania związane z bezpieczeństwem. Ale nie widzę, by to był argument na rzecz większej liczby możliwości sieciowych, takich jak tutaj. To błąd — wnioskiem powinno być rozwiązanie problemów związanych z bezpieczeństwem w aplikacjach natywnych, a nie rozluźnianie zabezpieczeń aplikacji internetowych, ponieważ są one w grze w nadrabianie zaległości z możliwościami systemu operacyjnego.
Native i web nie mogą być porównywane pod względem możliwości, bez uwzględnienia trzeciego wymiaru zaufania i modelu dystrybucji.
Ograniczenia sklepu z aplikacjami
Jeden z zarzutów dotyczących aplikacji natywnych w teorii dotyczy braku wyboru silnika przeglądarki w systemie iOS. Jest to powszechny wątek krytyki wobec Apple, ale istnieje więcej niż jedna perspektywa.
Krytyka dotyczy w szczególności punktu 2.5.6 wytycznych dotyczących recenzji sklepu z aplikacjami Apple:
„Aplikacje przeglądające strony internetowe muszą korzystać z odpowiedniej struktury WebKit i JavaScript WebKit”.
Może to wydawać się antykonkurencyjne i mam własne zastrzeżenia co do tego, jak restrykcyjny jest iOS. Ale punktu 2.5.6 nie można czytać bez kontekstu pozostałych wytycznych dotyczących przeglądu sklepu z aplikacjami, na przykład punktu 2.3.12:
„Aplikacje muszą jasno opisywać nowe funkcje i zmiany produktów w tekście „Co nowego”.
Gdyby aplikacja mogła otrzymać uprawnienia dostępu do urządzenia, a następnie zawierać własną strukturę, która mogłaby wykonywać kod z dowolnej witryny internetowej, te elementy w wytycznych dotyczących przeglądu sklepu z aplikacjami stałyby się bez znaczenia. W przeciwieństwie do aplikacji, strony internetowe nie muszą opisywać swoich funkcji i zmian produktów przy każdej zmianie.
Staje się to jeszcze większym problemem, gdy przeglądarki udostępniają funkcje eksperymentalne, takie jak te w projekcie Fugu, które nie są jeszcze uznawane za standard. Kto definiuje, czym jest przeglądarka? Pozwalając aplikacjom na dostarczanie dowolnych frameworków internetowych, sklep z aplikacjami zasadniczo umożliwiłby „aplikacji” uruchomienie dowolnego nieaudytowanego kodu lub całkowitą zmianę produktu, omijając proces recenzji sklepu.
Jako użytkownik zarówno stron internetowych, jak i aplikacji, myślę, że obie mają miejsce w świecie komputerów, chociaż mam nadzieję, że jak najwięcej da się przenieść do sieci. Ale biorąc pod uwagę obecny stan standardów sieciowych oraz to, jak daleko do rozwiązania kwestii zaufania i piaskownicy wokół takich rzeczy jak Bluetooth i USB, nie widzę, w jaki sposób umożliwienie aplikacjom swobodne uruchamianie treści z sieci byłoby korzystne dla użytkowników .
Pogoń za Appiness
W innym pokrewnym poście na blogu ten sam autor porusza niektóre z tych kwestii, mówiąc o aplikacjach natywnych:
„Bycie »aplikacją« to jedynie spełnienie zestawu arbitralnych i zmiennych konwencji systemu operacyjnego”.
Zgadzam się z poglądem, że definicja „aplikacji” jest arbitralna i że jej definicja opiera się na tym, kto definiuje zasady sklepu z aplikacjami. Ale dzisiaj to samo dotyczy przeglądarek. Twierdzenie z postu, że aplikacje internetowe są domyślnie bezpieczne, jest również nieco arbitralne. Kto na piasku rysuje granicę „co to jest przeglądarka”? Czy aplikacja Facebook z wbudowaną przeglądarką jest „przeglądarką”?
Definicja aplikacji jest dowolna, ale też ważna. Fakt, że każda wersja aplikacji korzystająca z funkcji niskopoziomowych jest kontrolowana przez kogoś , komu mogę zaufać, nawet jeśli jest to osoba arbitralna, sprawia, że aplikacje są tym, czym są. Jeśli ten ktoś jest producentem sprzętu, za który zapłaciłem, czyni to jeszcze mniej arbitralnym — firma, od której kupiłem komputer, jest jedyną, która kontroluje oprogramowanie o mniejszych możliwościach niż ten komputer.
Wszystko może być przeglądarką
Bez rysowania linii „co to jest przeglądarka”, co w zasadzie robi sklep z aplikacjami Apple, każda aplikacja może dostarczyć własny silnik internetowy, zachęcić użytkownika do przeglądania dowolnej witryny za pomocą przeglądarki w aplikacji i dodać dowolny kod śledzenia chce, niwelując różnicę 3 wymiaru między aplikacjami a witrynami.
Kiedy używam aplikacji na iOS, wiem, że moje działania są obecnie widoczne dla dwóch graczy: Apple i zidentyfikowanego producenta aplikacji. Gdy korzystam ze strony internetowej w Safari lub w Safari WebView, moje działania są widoczne dla Apple i właściciela domeny najwyższego poziomu aktualnie przeglądanej strony internetowej. Kiedy używam przeglądarki w aplikacji z niezidentyfikowanym silnikiem, mam kontakt z Apple, producentem aplikacji, i właścicielem domeny najwyższego poziomu. Może to spowodować możliwe do uniknięcia naruszenia tego samego pochodzenia, takie jak śledzenie przez właściciela aplikacji wszystkich moich kliknięć w zagranicznych witrynach.
Zgadzam się, że być może linia na piasku „Tylko WebKit” jest zbyt ostra. Jaka byłaby alternatywna definicja przeglądarki, która nie tworzyłaby backdoora do śledzenia przeglądania użytkowników?
Inna krytyka dotycząca Apple
Teoria twierdzi, że odrzucenie przez Apple wdrożenia funkcji nie ogranicza się do obaw związanych z prywatnością/bezpieczeństwem. Zawiera link, który rzeczywiście pokazuje wiele funkcji zaimplementowanych w Chrome, a nie w Safari. Jednak podczas przewijania w dół wyświetla również sporą liczbę innych funkcji zaimplementowanych w Safari, a nie w Chrome.
Te dwa projekty przeglądarek mają różne priorytety, ale daleko im do kategorycznego stwierdzenia „Gra staje się jasna podczas pomniejszania” i ostrej krytyki, że Apple próbuje zamienić sieć w bursztyn.
Ponadto linki zatytułowane jest trudne i nie chcemy próbować prowadzić do oświadczeń Apple, że wdrożyliby funkcje, gdyby spełniono obawy dotyczące bezpieczeństwa/prywatności. Uważam, że umieszczanie tych linków w tych tytułach jest mylące.
Zgodziłbym się z bardziej wyważonym stwierdzeniem, że Google jest o wiele bardziej uparty niż Apple, jeśli chodzi o wdrażanie funkcji i rozwój sieci.
Monit o pozwolenie
Google podąża długimi, innowacyjnymi drogami w trzecim wymiarze, opracowując nowe sposoby pośredniczenia w zaufaniu między użytkownikiem, deweloperem i platformą, czasami z dużym sukcesem, jak w przypadku Trusted Web Activities.
Mimo to większość pracy w trzecim wymiarze w odniesieniu do interfejsów API urządzeń koncentruje się wokół monitów o pozwolenie i uczynienia ich bardziej przerażającymi, lub takich jak przyznawanie uprawnień w określonych ramach czasowych i domeny z listą bloków.
„Przerażające” monity, takie jak te w tym przykładzie, które widzimy od czasu do czasu, wyglądają tak, jakby miały zniechęcać ludzi do odwiedzania potencjalnie złośliwych stron. Ponieważ są tak rażące, te ostrzeżenia zachęcają programistów do przejścia na bezpieczniejsze interfejsy API i odnowienia swoich certyfikatów.
Chciałbym, abyśmy w przypadku możliwości dostępu do urządzenia mogli wymyślić podpowiedzi, które zachęcają do zaangażowania i zapewniają, że zaangażowanie jest bezpieczne, zamiast zniechęcać do niego i przenosić odpowiedzialność na użytkownika, bez żadnych środków zaradczych dostępnych dla twórcy stron internetowych. Więcej o tym później.
Zgadzam się z argumentem, że Mozilla i Apple powinny przynajmniej próbować wprowadzać innowacje w tej dziedzinie, a nie „odmawiać wdrażania”. Ale może są? Myślę, że na przykład isLoggedIn firmy Apple jest interesującą i odpowiednią propozycją w trzecim wymiarze, na której mogą opierać się przyszłe interfejsy API urządzeń — na przykład interfejsy API urządzeń, które są podatne na odciski palców, mogą zostać udostępnione, gdy bieżąca witryna internetowa już zna tożsamość użytkownik.

WebUSB
W kolejnej sekcji zagłębię się w WebUSB, sprawdzę na co pozwala i jak jest obsługiwane w 3 wymiarze — jaki jest model zaufania i dystrybucji? Czy to wystarczy? Jakie są alternatywy?
Przesłanka
Interfejs API WebUSB umożliwia pełny dostęp do protokołu USB dla klas urządzeń, które nie są wymienione na liście bloków.
Może osiągnąć potężne rzeczy, takie jak łączenie się z płytą Arduino lub debugowanie telefonu z Androidem.
Ekscytujące jest oglądanie filmów Suz Hinton o tym, jak ten interfejs API może pomóc osiągnąć rzeczy, które wcześniej były bardzo drogie.
Naprawdę chciałbym, aby platformy znalazły sposób na większą otwartość i umożliwienie na przykład szybkich iteracji projektów edukacyjnych sprzętu/oprogramowania.
Zabawne uczucie
Mimo to mam zabawne wrażenie, gdy patrzę na to, co umożliwia WebUSB i ogólnie na istniejące problemy z bezpieczeństwem USB.
USB wydaje się zbyt potężny jako protokół widoczny w sieci, nawet z monitami o pozwolenie.
Więc szukałem dalej.
Oficjalny pogląd Mozilli
Zacząłem od przeczytania, co David Baron miał do powiedzenia o tym, dlaczego Mozilla odrzuciła WebUSB, w oficjalnym stanowisku Mozilli dotyczącym standardów:
„Ponieważ wiele urządzeń USB nie jest zaprojektowanych do obsługi potencjalnie szkodliwych interakcji za pośrednictwem protokołów USB i ponieważ te urządzenia mogą mieć znaczący wpływ na komputer, do którego są podłączone, uważamy, że zagrożenia bezpieczeństwa związane z wystawieniem urządzeń USB w Internecie są zbyt duże. szerokie, aby narazić na nie użytkowników lub odpowiednio wyjaśnić użytkownikom końcowym w celu uzyskania znaczącej świadomej zgody.”
Monit o aktualne pozwolenie
Tak wygląda prośba o pozwolenie WebUSB przeglądarki Chrome w momencie publikowania tego posta:
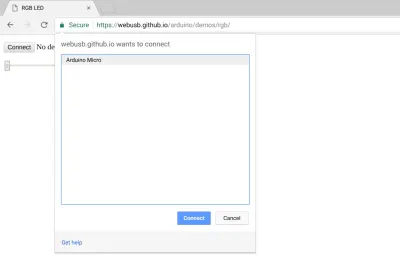
Konkretna domena Foo chce połączyć się z konkretnym urządzeniem Bar. Zrobic co? a skąd mam wiedzieć na pewno?
Przy udzielaniu dostępu do drukarki, aparatu, mikrofonu, GPS, a nawet kilku bardziej zawartych profili WebBluetooth GATT, takich jak monitorowanie tętna, pytanie to jest stosunkowo jasne i skupia się na treści lub działaniu , a nie na urządzeniu . Istnieje jasne zrozumienie, jakich informacji oczekuję od urządzenia peryferyjnego lub jakie działanie chcę z nim wykonać, a klient użytkownika pośredniczy i upewnia się, że ta konkretna czynność jest obsługiwana.
USB jest ogólny
W przeciwieństwie do urządzeń wymienionych powyżej, które są udostępniane za pośrednictwem specjalnych interfejsów API, USB nie jest zależne od zawartości. Jak wspomniano we wstępie do specyfikacji, WebUSB idzie dalej i jest celowo zaprojektowany dla nieznanych lub jeszcze nie wynalezionych typów urządzeń, a nie dla dobrze znanych klas urządzeń, takich jak klawiatury lub dyski zewnętrzne.
Tak więc, inaczej niż w przypadku drukarki, GPS i aparatu, nie wyobrażam sobie podpowiedzi, która informowałaby użytkownika o tym, co umożliwiłoby przyznanie stronie uprawnień do łączenia się z urządzeniem z WebUSB w sferze treści, bez głębokiego zrozumienia dane urządzenie i audyt kodu, który uzyskuje do niego dostęp.
Incydent i łagodzenie skutków w Yubikey
Dobrym przykładem sprzed niedawna jest incydent z Yubikey, w którym do phishingu danych z urządzenia uwierzytelniającego zasilanego przez USB wykorzystano WebUSB przeglądarki Chrome.
Ponieważ jest to problem bezpieczeństwa, który podobno został rozwiązany, chciałem zagłębić się w działania łagodzące Chrome w Chrome 67, które obejmują blokowanie określonego zestawu urządzeń i określonego zestawu klas.
Lista zablokowanych klas/urządzeń
Tak więc rzeczywista obrona Chrome przed exploitami WebUSB, które miały miejsce na wolności, oprócz obecnie bardzo ogólnego monitu o pozwolenie, polegała na blokowaniu określonych urządzeń i klas urządzeń.
Może to być proste rozwiązanie dla nowej technologii lub eksperymentu, ale stanie się coraz trudniejsze do osiągnięcia, gdy (i jeśli) WebUSB stanie się bardziej popularny.
Obawiam się, że osoby wprowadzające innowacje na urządzeniach edukacyjnych przez WebUSB mogą znaleźć się w trudnej sytuacji. Zanim zakończą tworzenie prototypów, mogą napotkać zestaw ciągle zmieniających się niestandardowych list bloków, które aktualizują się tylko wraz z wersjami przeglądarek, w oparciu o problemy z bezpieczeństwem, które nie mają z nimi nic wspólnego.
Myślę, że standaryzacja tego interfejsu API bez rozwiązania tego problemu przyniesie efekt przeciwny do zamierzonego dla programistów, którzy na nim polegają. Na przykład ktoś mógłby spędzić cykle na opracowywaniu aplikacji WebUSB dla detektorów ruchu, tylko po to, by później dowiedzieć się, że detektory ruchu stają się klasą zablokowaną, albo ze względów bezpieczeństwa, albo dlatego, że system operacyjny decyduje się je obsłużyć, powodując, że cały wysiłek WebUSB jest skierowany do marnować.
Bezpieczeństwo a funkcje
Teoria sąsiedztwa platform pod pewnymi względami uważa możliwości i bezpieczeństwo za grę o sumie zerowej, a zbyt konserwatywne podejście do kwestii bezpieczeństwa i prywatności spowoduje, że platformy stracą na znaczeniu.
Weźmy za przykład Arduino. Komunikacja Arduino jest możliwa dzięki WebUSB i jest głównym przypadkiem użycia. Ktoś opracowujący urządzenie Arduino będzie teraz musiał rozważyć nowy scenariusz zagrożenia, w którym witryna próbuje uzyskać dostęp do urządzenia za pomocą WebUSB (z pewnymi uprawnieniami użytkownika). Zgodnie ze specyfikacją ten producent urządzeń musi teraz „zaprojektować swoje urządzenia tak, aby akceptowały tylko podpisane oprogramowanie układowe”. Może to zwiększyć obciążenie programistów oprogramowania układowego i zwiększyć koszty rozwoju, podczas gdy celem specyfikacji jest działanie przeciwne.
Co sprawia, że WebUSB różni się od innych urządzeń peryferyjnych?
W przeglądarkach istnieje wyraźne rozróżnienie między interakcjami użytkownika a interakcjami syntetycznymi (interakcjami inicjowanymi przez stronę internetową).
Na przykład strona internetowa nie może samodzielnie zdecydować o kliknięciu łącza lub wybudzeniu procesora/wyświetlacza. Ale urządzenia zewnętrzne mogą — na przykład mysz może kliknąć łącze w imieniu użytkownika, a prawie każde urządzenie USB może obudzić procesor, w zależności od systemu operacyjnego.
Tak więc nawet przy obecnej specyfikacji WebUSB urządzenia mogą zdecydować się na implementację kilku interfejsów, np. debugowania dla adb i HID do wprowadzania wskaźnika oraz używania złośliwego kodu, który wykorzystuje ADB, stać się keyloggerem i przeglądać strony internetowe w imieniu użytkownika, biorąc pod uwagę właściwy mechanizm flashowania oprogramowania układowego.
Dodanie tego urządzenia do listy blokowania byłoby za późno dla urządzeń z oprogramowaniem układowym, które zostało zhakowane za pomocą ADB lub innych dozwolonych form flashowania, i sprawiłoby, że producenci urządzeń byliby jeszcze bardziej zależni od wersji przeglądarek w zakresie poprawek bezpieczeństwa powiązanych z ich urządzeniami.
Świadoma zgoda i treść
Problem ze świadomą zgodą i USB, jak wspomniano wcześniej, polega na tym, że USB (szczególnie w dodatkowych przypadkach użycia WebUSB) nie jest specyficzny dla treści. Użytkownicy wiedzą, czym jest drukarka, czym jest kamera, ale „USB” dla większości użytkowników to tylko kabel (lub gniazdo) — środek do celu — bardzo niewielu użytkowników wie, że USB to protokół i co umożliwia korzystanie z niego między stronami internetowymi i urządzenia oznaczają.
Jedną z sugestii było wprowadzenie „przerażającego” podpowiedzi, coś w rodzaju „Pozwól tej stronie przejąć urządzenie” (co jest ulepszeniem w stosunku do pozornie nieszkodliwego „chce się połączyć”).
Ale choć monity są przerażające, nie potrafią wyjaśnić zakresu możliwych rzeczy, które można zrobić z surowym dostępem do urządzenia peryferyjnego USB, którego przeglądarka nie zna dokładnie, a gdyby tak się stało, żaden użytkownik przy zdrowych zmysłach nie kliknąłby „Tak ”, chyba że jest to urządzenie, któremu w pełni ufają, że jest wolne od błędów, a witryna, której naprawdę ufają, że jest aktualna i nie jest złośliwa.
Możliwy komunikat taki brzmi: „Pozwól tej stronie potencjalnie przejąć kontrolę nad twoim komputerem”. Nie sądzę, aby taki przerażający monit był korzystny dla społeczności WebUSB, a ciągłe zmiany w tych oknach dialogowych sprawią, że społeczność będzie zdezorientowana.
Prototypowanie a produkt
Widzę możliwy wyjątek od tego. Jeśli założeniem WebUSB i innych interfejsów API projektu Fugu było wspieranie prototypowania, a nie urządzeń klasy produktowej, wszystkie ogólne podpowiedzi mogą mieć sens.
Jednak aby było to wykonalne, myślę, że musi się wydarzyć, co następuje:
- Używaj języka w specyfikacjach, które określają oczekiwania dotyczące prototypowania;
- Mieć dostęp do tych interfejsów API tylko po wykonaniu jakiegoś gestu zgody, np. gdy użytkownik włączy je ręcznie w ustawieniach przeglądarki;
- Wyświetlaj „przerażające” monity o pozwolenie, takie jak te dotyczące nieprawidłowych certyfikatów SSL.
Brak powyższego sprawia, że myślę, że te interfejsy API są dla prawdziwych produktów, a nie dla prototypów, i jako takie, opinie są aktualne.
Alternatywna propozycja
Jedną z części oryginalnego wpisu na blogu, z którą się zgadzam, jest to, że nie wystarczy powiedzieć „nie” — główni gracze w świecie sieci, którzy odrzucają niektóre interfejsy API ze względu na ich szkodliwość, powinni również obrażać się i proponować sposoby, w jakie te możliwości mają znaczenie dla użytkowników i programistów mogą być bezpiecznie ujawnione. Nie reprezentuję żadnego większego gracza, ale zamierzam spróbować z pokorą.
Wierzę, że odpowiedź na to pytanie leży w trzecim wymiarze zaufania i relacji, i że jest to poza ramką pytań o pozwolenie i list blokowania.
Prosty i zweryfikowany monit
Głównym argumentem, który zamierzam przedstawić, jest to, że monit powinien dotyczyć treści lub działania, a nie urządzenia peryferyjnego, oraz że świadoma zgoda może zostać udzielona na konkretną prostą czynność z określonym zestawem zweryfikowanych parametrów, a nie na ogólne działanie, takie jak „przejęcie” lub „łączenie się” z urządzeniem.
Przykład drukarki 3D
W specyfikacji WebUSB drukarki 3D są podane jako przykład, więc zamierzam go tutaj użyć.
Podczas tworzenia aplikacji WebUSB dla drukarki 3D chcę, aby monit przeglądarki/systemu operacyjnego pytał mnie o coś w stylu Zezwalaj AutoDesk 3ds-mask na drukowanie modelu na Twojej drukarce CreatBot 3D? , zostanie wyświetlone okno dialogowe przeglądarki/systemu operacyjnego z niektórymi parametrami drukowania, takimi jak udoskonalenie, grubość i wymiary wyjściowe oraz podgląd tego, co zostanie wydrukowane. Wszystkie te parametry powinny zostać zweryfikowane przez zaufanego agenta użytkownika, a nie przez stronę internetową typu drive-by.
Obecnie przeglądarka nie zna drukarki i może zweryfikować tylko niektóre twierdzenia w monicie:
- Domena żądająca ma certyfikat zarejestrowany w AutoDesk, więc jest pewne, że jest to AutoDesk Inc;
- Żądane urządzenie peryferyjne nazywa się „drukarką 3d CreatBot”;
- To urządzenie, klasa urządzenia i domena nie znajdują się na listach zablokowanych przeglądarki;
- Użytkownik odpowiedział „Tak” lub „Nie” na zadane mu ogólne pytanie.
Ale aby wyświetlić prawdziwy monit i dialog z powyższymi szczegółami, przeglądarka musiałaby również zweryfikować następujące elementy:
- Po udzieleniu pozwolenia wykonywana akcja będzie drukowaniem modelu 3D i nic poza tym;
- Wybrane parametry (wyrafinowanie/grubość/wymiary itp.) będą przestrzegane;
- Użytkownikowi pokazano zweryfikowany podgląd tego, co ma zostać wydrukowane;
- W niektórych wrażliwych przypadkach dodatkowa weryfikacja, że jest to w rzeczywistości AutoDesk, może z czymś w rodzaju odwołalnego tokena o krótkim czasie życia.
Bez weryfikacji powyższego strona, która otrzymała pozwolenie na „połączenie się” lub „przejęcie” drukarki 3D, może zacząć drukować ogromne modele 3D z powodu błędu (lub złośliwego kodu w jednej z jej zależności).
Ponadto wyobrażona w pełni rozbudowana funkcja drukowania 3D w Internecie przyniosłaby znacznie więcej niż to, co może zapewnić WebUSB — na przykład buforowanie i kolejkowanie różnych żądań drukowania. Jak miałoby to być obsługiwane, gdyby okno przeglądarki było zamknięte? Nie zbadałem wszystkich możliwych przypadków użycia urządzeń peryferyjnych WebUSB, ale zgaduję, że patrząc na nie z perspektywy treści/działania, większość będzie potrzebować czegoś więcej niż tylko dostępu do USB.
W związku z powyższym korzystanie z WebUSB do drukowania 3D będzie prawdopodobnie szalone i krótkotrwałe, a programiści, którzy na nim polegają, będą musieli w pewnym momencie dostarczyć „prawdziwy” sterownik do swojej drukarki. Na przykład, jeśli dostawcy systemów operacyjnych zdecydują się dodać wbudowaną obsługę drukarek 3D, wszystkie witryny korzystające z tej drukarki z WebUSB przestaną działać.
Propozycja: Organ Kontroli Kierowców
Tak więc nadrzędne uprawnienia, takie jak „przejęcie urządzenia peryferyjnego”, są problematyczne, nie mamy wystarczających informacji, aby wyświetlić pełne okno dialogowe parametrów i zweryfikować, czy jego wyniki będą przestrzegane, a nie chcemy wysyłać użytkownik w niebezpiecznej podróży, aby pobrać losowy plik wykonywalny z sieci.
Ale co by było, gdyby istniał kontrolowany fragment kodu, sterownik, który używał wewnętrznie interfejsu API WebUSB i wykonywał następujące czynności:
- Wdrożono polecenie „drukuj”;
- Wyświetlono okno dialogowe drukowania poza stroną;
- Podłączony do określonego zestawu urządzeń USB;
- Wykonywał część swoich akcji, gdy strona jest w tle (np. w service workerze), a nawet gdy przeglądarka jest zamknięta.
Audyt sterownika takiego jak ten może upewnić się, że to, co robi, sprowadza się do „drukowania”, że respektuje parametry i pokazuje podgląd wydruku.
Widzę to jako podobne do urzędów certyfikacji, ważnego elementu ekosystemu internetowego, który jest nieco oddzielony od dostawców przeglądarek.
Syndykacja kierowców
Sterowniki nie muszą być kontrolowane przez Google/Apple, chociaż dostawca przeglądarki/systemu operacyjnego może samodzielnie przeprowadzić audyt sterowników. Może działać jak urzędy certyfikacji SSL — wystawcą jest wysoce zaufana organizacja; na przykład producent konkretnego urządzenia peryferyjnego lub organizacja certyfikująca wiele sterowników lub platforma taka jak Arduino. (Wyobrażam sobie, że pojawiają się organizacje podobne do Let's Encrypt).
Wystarczy powiedzieć użytkownikom: „Arduino ufa, że ten kod spowoduje flashowanie twojego Uno z tym oprogramowaniem” (z podglądem oprogramowania).
Zastrzeżenia
To oczywiście nie jest wolne od potencjalnych problemów:
- Sam sterownik może być błędny lub złośliwy. Ale przynajmniej jest skontrolowany;
- Jest mniej „webby” i generuje dodatkowe obciążenie programistyczne;
- Nie istnieje dzisiaj i nie można go rozwiązać za pomocą wewnętrznych innowacji w silnikach przeglądarek.
Inne alternatywy
Inne alternatywy mogą polegać na standaryzacji i ulepszeniu interfejsu API rozszerzeń dla różnych przeglądarek i przekształceniu istniejących sklepów z dodatkami do przeglądarki, takich jak Chrome Web Store, w coś w rodzaju organu kontroli sterowników, pośredniczącego między żądaniami użytkowników a dostępem peryferyjnym.
Podsumowanie opinii
Odważne wysiłki autora, Google i partnerów, aby utrzymać adekwatność otwartej sieci poprzez zwiększanie jej możliwości, są inspirujące.
Kiedy przechodzę do szczegółów, widzę, że bardziej konserwatywne podejście Apple i Mozilli do sieci oraz ich defensywne podejście do nowych możliwości urządzeń mają zalety techniczne. Podstawowe problemy związane ze świadomą zgodą na temat otwartych możliwości sprzętowych są dalekie od rozwiązania.
Apple mógłby być bardziej otwarty w dyskusji, aby znaleźć nowe sposoby włączania możliwości urządzeń, ale uważam, że wynika to z innej perspektywy komputerowej, z punktu widzenia, który był częścią tożsamości Apple przez dziesięciolecia, a nie z antykonkurencyjnego punktu widzenia.
Aby wesprzeć takie rzeczy jak nieco otwarte możliwości sprzętowe w projekcie Fugu, a w szczególności WebUSB, model zaufania w sieci musi ewoluować poza monity o pozwolenie i listy blokowania domen/urządzeń, czerpiąc inspirację z ekosystemów zaufania, takich jak urzędy certyfikacji i dystrybucje pakietów.
Dalsze czytanie na SmashingMag:
- Jak poprawa wydajności strony internetowej może pomóc ocalić planetę?
- W stronę sieci bez reklam: dywersyfikacja gospodarki online
- Czy istnieje przyszłość poza pisaniem świetnego kodu?
- Korzystanie z etyki w projektowaniu stron internetowych