
Tworzenie umiejętności głosowych dla Asystenta Google i Amazon Alexa
Opublikowany: 2022-03-10W ciągu ostatniej dekady nastąpiła sejsmiczna zmiana w kierunku interfejsów konwersacyjnych. Gdy ludzie osiągają „ekran szczytowy”, a nawet zaczynają zmniejszać wykorzystanie urządzeń, dzięki funkcjom cyfrowego dobrego samopoczucia w większości systemów operacyjnych.
Aby zwalczyć zmęczenie ekranu, asystenci głosowi weszli na rynek, aby stać się preferowaną opcją szybkiego wyszukiwania informacji. Dobrze powtarzane statystyki mówią, że 50% wyszukiwań będzie przeprowadzanych głosowo w 2020 roku. Ponadto, wraz ze wzrostem liczby użytkowników, deweloperzy powinni dodać „Interfejsy konwersacyjne” i „Asystenty głosowe” do swojego paska narzędzi.
Projektowanie niewidzialnego
Dla wielu rozpoczęcie projektu głosowego interfejsu użytkownika (VUI) może być trochę jak wejście w nieznane. Dowiedz się więcej o lekcjach wyciągniętych przez Williama Merrilla podczas projektowania głosu. Przeczytaj powiązany artykuł →
Co to jest interfejs konwersacyjny?
Interfejs konwersacyjny (czasami skracany do CUI, to dowolny interfejs w ludzkim języku. Jest on typowany jako bardziej naturalny interfejs dla ogółu społeczeństwa niż graficzny interfejs użytkownika GUI, do którego tworzenia przyzwyczajeni są programiści front-end. GUI wymaga ludzi aby poznać jego specyficzną składnię interfejsu (przyciski myślowe, suwaki i listy rozwijane).
Ta kluczowa różnica w używaniu ludzkiego języka sprawia, że CUI jest bardziej naturalny dla ludzi; wymaga niewielkiej wiedzy i nakłada na urządzenie ciężar zrozumienia.
Zwykle CUI występuje w dwóch postaciach: Chatboty i Voice Assistants. Obydwa odnotowały ogromny wzrost popularności w ciągu ostatniej dekady dzięki postępom w przetwarzaniu języka naturalnego (NLP).
Zrozumienie żargonu głosowego

| Słowo kluczowe | Oznaczający |
|---|---|
| Umiejętność/działanie | Aplikacja głosowa, która może spełnić szereg intencji |
| Zamiar | Zamierzone działanie mające na celu spełnienie umiejętności, co użytkownik chce zrobić w odpowiedzi na to, co mówi. |
| Wypowiedź | Zdanie, które wypowiada lub wypowiada użytkownik. |
| Słowo budzenia | Słowo lub wyrażenie używane do rozpoczęcia słuchania przez asystenta głosowego, np. „Hej google”, „Alexa” lub „Hej Siri” |
| Kontekst | Fragmenty informacji kontekstowych w wypowiedzi, które pomagają umiejętności w spełnieniu intencji, np. „dzisiaj”, „teraz”, „kiedy wrócę do domu”. |
Co to jest asystent głosowy?
Asystent głosowy to oprogramowanie obsługujące NLP (przetwarzanie języka naturalnego). Otrzymuje polecenie głosowe i zwraca odpowiedź w formacie audio. W ostatnich latach zakres tego, w jaki sposób można współpracować z asystentem, rozszerza się i ewoluuje, ale sednem technologii jest wprowadzanie języka naturalnego, dużo obliczeń, język naturalny.
Dla szukających nieco więcej szczegółów:
- Oprogramowanie odbiera żądanie dźwiękowe od użytkownika, przetwarza dźwięk na fonemy, bloki budulcowe języka.
- Dzięki magii AI (Specifically Speech-To-Text) te fonemy są konwertowane na ciąg przybliżonego żądania, które jest przechowywane w pliku JSON, który zawiera również dodatkowe informacje o użytkowniku, żądaniu i sesji.
- JSON jest następnie przetwarzany (zwykle w chmurze) w celu ustalenia kontekstu i intencji żądania.
- Na podstawie intencji zwracana jest odpowiedź, ponownie w większej odpowiedzi JSON, jako ciąg znaków lub jako SSML (więcej o tym później)
- Odpowiedź jest przetwarzana z powrotem za pomocą sztucznej inteligencji (oczywiście odwrotnie - Text-To-Speech), która jest następnie zwracana użytkownikowi.
Dużo się tam dzieje, z których większość nie wymaga namysłu. Ale każda platforma robi to inaczej i to niuanse platformy wymagają nieco większego zrozumienia.

Urządzenia obsługujące głos
Wymagania, aby urządzenie mogło mieć wbudowanego asystenta głosowego, są dość niskie. Wymagają mikrofonu, połączenia internetowego i głośnika. Inteligentne głośniki, takie jak Nest Mini i Echo Dot, zapewniają tego rodzaju sterowanie głosowe o niskim poziomie głośności.
Następny w rankingu jest głos + ekran, znany jako urządzenie „multimodalne” (więcej o nich później) i są to urządzenia takie jak Nest Hub i Echo Show. Ponieważ smartfony mają tę funkcjonalność, można je również uznać za rodzaj multimodalnego urządzenia obsługującego głos.
Umiejętności głosowe
Po pierwsze, każda platforma ma inną nazwę dla swoich „umiejętności głosowych”, Amazon idzie z umiejętnościami, których będę się trzymał jako powszechnie rozumianego terminu. Google wybiera „Działania”, a Samsung „kapsułki”.
Każda platforma ma swoje własne umiejętności, takie jak pytanie o godzinę, pogodę i gry sportowe. Umiejętności stworzone przez programistę (zewnętrzne) można wywoływać za pomocą określonej frazy lub, jeśli platforma to lubi, można je wywołać w sposób dorozumiany, bez frazy kluczowej.
Jawne wywołanie : „Hej Google, porozmawiaj z <nazwa aplikacji>”.
Jest wyraźnie określone, o jaką umiejętność prosi się:
Inwokacja niejawna : „Hej Google, jaka jest dzisiaj pogoda?”
Z kontekstu żądania wynika, jakiej usługi oczekuje użytkownik.
Jakie są asystenci głosowi?
Na rynku zachodnim asystenci głosowi to w dużej mierze wyścig trzech koni. Apple, Google i Amazon mają bardzo różne podejście do swoich asystentów i jako takie przemawiają do różnych typów programistów i klientów.
Siri jabłoni
Nazwa urządzenia : „Siri”
Pobudka : „Hej Siri”
Siri ma ponad 375 milionów aktywnych użytkowników, ale w trosce o zwięzłość nie będę wdawał się w Siri zbytnio w szczegóły. Chociaż może być dobrze przyjęty na całym świecie i wbudowany w większość urządzeń Apple, wymaga od programistów posiadania już aplikacji na jednej z platform Apple i jest napisany szybko (podczas gdy inne można napisać w ulubionym przez wszystkich: JavaScript). Jeśli nie jesteś programistą aplikacji, który chce rozszerzyć ofertę swojej aplikacji, możesz obecnie pominąć Apple, dopóki nie otworzą swojej platformy.
Asystent Google
Nazwy urządzeń : „Google Home, Nest”
Pobudka : „Hej Google”
Google ma najwięcej urządzeń z wielkiej trójki, z ponad 1 miliardem na całym świecie, jest to głównie spowodowane masą urządzeń z Androidem, które mają wypieczonego Asystenta Google, w odniesieniu do ich dedykowanych inteligentnych głośników, liczby są nieco mniejsze. Ogólną misją Google z jej asystentem jest zachwycanie użytkowników, a oni zawsze byli bardzo dobrzy w dostarczaniu lekkich i intuicyjnych interfejsów.
Ich głównym celem na platformie jest wykorzystanie czasu — z myślą o tym, by stać się stałym elementem codziennej rutyny klientów. W związku z tym skupiają się przede wszystkim na użyteczności, rodzinnej zabawie i wspaniałych przeżyciach.
Umiejętności zbudowane dla Google są najlepsze, gdy są elementami zaangażowania i grami, skupiającymi się przede wszystkim na zabawie dla całej rodziny. Ich niedawne dodanie płótna do gier jest świadectwem tego podejścia. Platforma Google jest znacznie bardziej rygorystyczna w przypadku przesyłania umiejętności, a zatem ich katalog jest znacznie mniejszy.
Amazonka Alexa
Nazwy urządzeń : „Amazon Fire, Amazon Echo”
Pobudka : „Alexa”
Amazon przekroczył 100 milionów urządzeń w 2019 roku, to głównie pochodzi ze sprzedaży ich inteligentnych głośników i inteligentnych wyświetlaczy, a także ich gamy „fire” lub tabletów i urządzeń do przesyłania strumieniowego.
Umiejętności zbudowane dla Amazon są zwykle ukierunkowane na zakup umiejętności. Jeśli szukasz platformy, na której możesz rozszerzyć swój e-commerce/usługę lub zaoferować subskrypcję, Amazon jest dla Ciebie. Biorąc to pod uwagę, dostawca usług internetowych nie jest wymagany dla umiejętności Alexa, obsługują one wszystkie rodzaje zastosowań i są znacznie bardziej otwarte na zgłoszenia.
Inni
Istnieje jeszcze więcej asystentów głosowych, takich jak Bixby firmy Samsung, Cortana firmy Microsoft i popularny asystent głosowy o otwartym kodzie źródłowym Mycroft. Wszystkie trzy mają rozsądną liczbę zwolenników, ale nadal stanowią mniejszość w porównaniu z trzema Goliatami Amazona, Google i Apple.
Opierając się na Amazon Alexa
Amazons Ecosystem for Voice ewoluował, aby umożliwić programistom budowanie wszystkich swoich umiejętności w konsoli Alexa, więc jako prosty przykład zamierzam użyć jego wbudowanych funkcji.
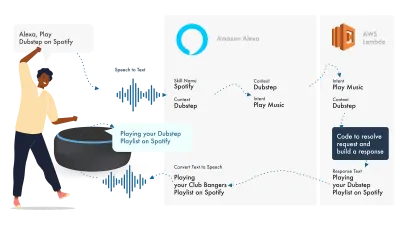
Alexa zajmuje się przetwarzaniem języka naturalnego, a następnie znajduje odpowiednią intencję, która jest przekazywana do naszej funkcji Lambda, która zajmuje się logiką. Spowoduje to zwrócenie niektórych bitów konwersacyjnych (SSML, tekst, karty itp.) do Alexy, która konwertuje te bity na dźwięk i obrazy, aby wyświetlić je na urządzeniu.
Praca na Amazon jest stosunkowo prosta, ponieważ pozwalają tworzyć wszystkie elementy swoich umiejętności w Konsoli programisty Alexa. Elastyczność umożliwia korzystanie z AWS lub punktu końcowego HTTPS, ale w przypadku prostych umiejętności wystarczy uruchomić wszystko w konsoli Dev.
Zbudujmy prostą umiejętność Alexa
Przejdź do konsoli Amazon Alexa, utwórz konto, jeśli go nie masz, i zaloguj się,
Kliknij Create Skill , a następnie nadaj jej nazwę,
Wybierz custom jako swój model,
i wybierz Alexa-Hosted (Node.js) jako zasób zaplecza.
Po zakończeniu obsługi administracyjnej będziesz mieć podstawową umiejętność Alexa, zbudujesz dla ciebie intencję i trochę kodu zaplecza, aby zacząć.
Jeśli klikniesz HelloWorldIntent w swoich Intencjach, zobaczysz kilka przykładowych wypowiedzi, które zostały już dla Ciebie skonfigurowane, dodajmy nowe u góry. Nasza umiejętność nazywa się hello world, więc dodaj Hello World jako przykładową wypowiedź. Chodzi o to, aby uchwycić wszystko, co użytkownik może powiedzieć, aby wywołać tę intencję. Może to być „Hi World”, „Howdy World” i tak dalej.
Co się dzieje w JS realizacji?
Więc co robi kod? Oto domyślny kod:
const HelloWorldIntentHandler = { canHandle(handlerInput) { return Alexa.getRequestType(handlerInput.requestEnvelope) === 'IntentRequest' && Alexa.getIntentName(handlerInput.requestEnvelope) === 'HelloWorldIntent'; }, handle(handlerInput) { const speakOutput = 'Hello World!'; return handlerInput.responseBuilder .speak(speakOutput) .getResponse(); } }; Wykorzystuje to ask-sdk-core i zasadniczo buduje dla nas JSON. canHandle informuje zapytanie, że może obsługiwać intencje, w szczególności „HelloWorldIntent”. handle pobiera dane wejściowe i buduje odpowiedź. To, co to generuje, wygląda tak:

{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }
Widzimy, że Speak wyprowadza ssml w naszym json, co użytkownik usłyszy jako speak przez Alexę.
Budynek dla Asystenta Google
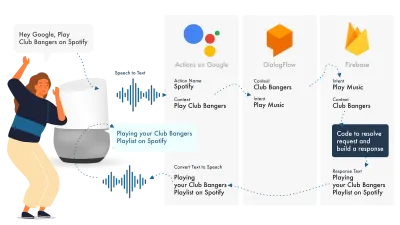
Najprostszym sposobem na zbudowanie Actions w Google jest użycie ich konsoli AoG w połączeniu z Dialogflow, możesz poszerzyć swoje umiejętności za pomocą Firebase, ale tak jak w przypadku samouczka Amazon Alexa, zachowajmy prostotę.
Asystent Google korzysta z trzech głównych części: AoG, która zajmuje się NLP, Dialogflow, która określa Twoje zamiary, oraz Firebase, która spełnia żądanie i generuje odpowiedź, która zostanie wysłana z powrotem do AoG.
Podobnie jak w przypadku Alexy, Dialogflow umożliwia budowanie funkcji bezpośrednio na platformie.
Zbudujmy akcję w Google
Istnieją trzy platformy, na których można żonglować jednocześnie z rozwiązaniem Google, do których można uzyskać dostęp z trzech różnych konsol, więc zakładka w górę!
Konfigurowanie Dialogflow
Zacznijmy od zalogowania się do konsoli Dialogflow. Po zalogowaniu utwórz nowego agenta z listy rozwijanej tuż pod logo Dialogflow.
Nadaj swojemu agentowi nazwę i dodaj „Rozwijane menu Google Project”, mając wybraną opcję „Utwórz nowy projekt Google”.
Kliknij przycisk tworzenia i pozwól mu działać magicznie, konfiguracja agenta zajmie trochę czasu, więc bądź cierpliwy.
Konfigurowanie funkcji Firebase
Tak, teraz możemy zacząć podłączać logikę realizacji.
Przejdź do zakładki Realizacja. Zaznacz, aby włączyć edytor wbudowany i użyj poniższych fragmentów kodu JS:
index.js
'use strict'; // So that you have access to the dialogflow and conversation object const { dialogflow } = require('actions-on-google'); // So you have access to the request response stuff >> functions.https.onRequest(app) const functions = require('firebase-functions'); // Create an instance of dialogflow for your app const app = dialogflow({debug: true}); // Build an intent to be fulfilled by firebase, // the name is the name of the intent that dialogflow passes over app.intent('Default Welcome Intent', (conv) => { // Any extra logic goes here for the intent, before returning a response for firebase to deal with return conv.ask(`Welcome to a firebase fulfillment`); }); // Finally we export as dialogflowFirebaseFulfillment so the inline editor knows to use it exports.dialogflowFirebaseFulfillment = functions.https.onRequest(app);pakiet.json
{ "name": "functions", "description": "Cloud Functions for Firebase", "scripts": { "lint": "eslint .", "serve": "firebase serve --only functions", "shell": "firebase functions:shell", "start": "npm run shell", "deploy": "firebase deploy --only functions", "logs": "firebase functions:log" }, "engines": { "node": "10" }, "dependencies": { "actions-on-google": "^2.12.0", "firebase-admin": "~7.0.0", "firebase-functions": "^3.3.0" }, "devDependencies": { "eslint": "^5.12.0", "eslint-plugin-promise": "^4.0.1", "firebase-functions-test": "^0.1.6" }, "private": true }Teraz wróć do swoich intencji, przejdź do Domyślnej intencji powitalnej i przewiń w dół do realizacji, upewnij się, że opcja „Włącz wywołanie webhooka dla tej intencji” jest zaznaczona dla wszelkich intencji, które chcesz spełnić za pomocą javascript. Hit Zapisz.
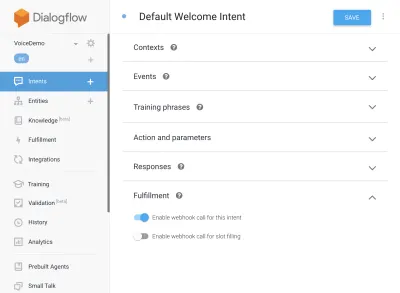
Konfiguracja AoG
Jesteśmy już blisko mety. Przejdź do zakładki Integracje i kliknij Ustawienia integracji w opcji Asystenta Google u góry. Spowoduje to otwarcie modalnego, więc kliknijmy test, który zintegruje Dialogflow z Google i otworzy okno testowe w Actions on Google.
W oknie testowym możemy kliknąć Porozmawiaj z moją aplikacją testową (zmienimy to za sekundę) i voila, mamy wiadomość z naszego javascriptu wyświetlającą się w teście asystenta Google.
Nazwę asystenta możemy zmienić w zakładce Develop, u góry.
Więc co się dzieje w JS realizacji?
Po pierwsze, używamy dwóch pakietów npm, actions-on-google, które zapewniają wszystko, czego potrzebują zarówno AoG, jak i Dialogflow, a po drugie, funkcje Firebase, które zgadłeś, zawierają helpery dla Firebase.
Następnie tworzymy „aplikację”, która jest obiektem zawierającym wszystkie nasze intencje.
Każda utworzona intencja przeszła ciąg „conv”, który jest wysyłanym obiektem rozmowy Actions On Google. Możemy wykorzystać zawartość conv do wykrywania informacji o poprzednich interakcjach z użytkownikiem (takich jak jego identyfikator i informacje o sesji z nami).
Zwracamy „obiekt conv.ask”, który zawiera nasz komunikat zwrotny do użytkownika, gotowy do odpowiedzi z inną intencją. Moglibyśmy użyć „konw.zamknij”, aby zakończyć rozmowę, gdybyśmy chcieli ją tam zakończyć.
Na koniec pakujemy wszystko w funkcję Firebase HTTPS, która zajmuje się dla nas logiką żądania-odpowiedzi po stronie serwera.
Ponownie, jeśli spojrzymy na wygenerowaną odpowiedź:
{ "payload": { "google": { "expectUserResponse": true, "richResponse": { "items": [ { "simpleResponse": { "textToSpeech": "Welcome to a firebase fulfillment" } } ] } } } } Widzimy, że conv.ask ma swój tekst wstrzyknięty do obszaru textToSpeech . Gdybyśmy wybrali conv.close , właściwość expectUserResponse miałaby wartość false , a konwersacja zostałaby zamknięta po dostarczeniu wiadomości.
Zewnętrzni twórcy głosu
Podobnie jak w branży aplikacji, gdy głos zyskuje na popularności, narzędzia innych firm zaczęły pojawiać się w celu odciążenia programistów, umożliwiając im budowanie po wdrożeniu dwa razy.
Jovo i Voiceflow to obecnie dwa najbardziej popularne, zwłaszcza od czasu przejęcia PullString przez Apple. Każda platforma oferuje inny poziom abstrakcji, więc tak naprawdę zależy to tylko od uproszczenia interfejsu.
Rozszerzanie umiejętności
Teraz, gdy już zdążyłeś się zająć budowaniem podstawowej umiejętności „Hello World”, istnieje mnóstwo dzwonków i gwizdów, które można dodać do swojej umiejętności. Są to wisienka na torcie asystentów głosowych i zapewnią użytkownikom dodatkową wartość, prowadząc do powtórzenia niestandardowych i potencjalnych możliwości handlowych.
SSML
SSML oznacza język znaczników syntezy mowy i działa z podobną składnią do HTML, kluczową różnicą jest to, że tworzysz odpowiedź głosową, a nie treść na stronie internetowej.
„SSML” jako termin jest trochę mylący, może zrobić o wiele więcej niż synteza mowy! Możesz mieć głosy biegnące równolegle, możesz dołączyć odgłosy otoczenia, komunikaty mowy (warte posłuchania same w sobie, pomyśl emoji dla znanych fraz) i muzykę.
Kiedy powinienem używać SSML?
SSML jest świetny; zapewnia to znacznie bardziej angażujące wrażenia dla użytkownika, ale jednocześnie zmniejsza elastyczność wyjścia audio. Polecam używać go do bardziej statycznych obszarów mowy. Możesz używać w nim zmiennych dla nazw itp., ale jeśli nie zamierzasz budować generatora SSML, większość SSML będzie dość statyczna.
Zacznij od prostej mowy w swoich umiejętnościach, a po jej ukończeniu popraw obszary, które są bardziej statyczne za pomocą SSML, ale popraw rdzeń, zanim przejdziesz do dzwonków i gwizdów. Biorąc to pod uwagę, niedawny raport mówi, że 71% użytkowników woli ludzki (prawdziwy) głos od syntetycznego, więc jeśli masz do tego możliwość, wyjdź i zrób to!

W Zakupach Umiejętności
Zakupy w ramach umiejętności (lub ISP) są podobne do koncepcji zakupów w aplikacji. Umiejętności wydają się być bezpłatne, ale niektóre pozwalają na zakup treści/subskrypcji „premium” w aplikacji, które mogą poprawić wrażenia użytkownika, odblokować nowe poziomy w grach lub umożliwić dostęp do płatnych treści.
Multimodalny
Odpowiedzi multimodalne obejmują znacznie więcej niż głos, w tym przypadku asystenci głosowi mogą naprawdę zabłysnąć uzupełniającymi się wizualizacjami na obsługujących je urządzeniach. Definicja multimodalnych doświadczeń jest znacznie szersza i zasadniczo oznacza wiele wejść (klawiatura, mysz, ekran dotykowy, głos itd.).
Umiejętności multimodalne mają na celu uzupełnienie podstawowego doświadczenia głosowego, dostarczając dodatkowych informacji uzupełniających, aby poprawić UX. Budując multimodalne doświadczenie pamiętaj, że głos jest podstawowym nośnikiem informacji. Wiele urządzeń nie ma ekranu, więc Twoje umiejętności nadal muszą działać bez niego, więc upewnij się, że testujesz z wieloma typami urządzeń; albo w rzeczywistości, albo w symulatorze.

Wielojęzyczny
Umiejętności wielojęzyczne to umiejętności, które działają w wielu językach i otwierają Twoje umiejętności na wiele rynków.
Złożoność tworzenia wielojęzyczności zależy od tego, jak dynamiczne są twoje odpowiedzi. Umiejętności ze stosunkowo statycznymi odpowiedziami, np. za każdym razem zwracanie tej samej frazy lub używanie tylko małego wiaderka fraz, są znacznie łatwiejsze do stworzenia wielojęzyczności niż rozległe umiejętności dynamiczne.
Sztuczka z wielojęzycznością polega na posiadaniu godnego zaufania partnera tłumaczeniowego, niezależnie od tego, czy jest to agencja, czy tłumacz na Fiverr. Musisz być w stanie ufać dostarczonym tłumaczeniom, zwłaszcza jeśli nie rozumiesz języka, na który jest tłumaczone. Tłumacz Google nie pokroi tutaj musztardy!
Wniosek
Jeśli kiedykolwiek był czas, aby wejść do branży głosowej, byłby to teraz. Zarówno w okresie szczytowym, jak i niemowlęcym, a także w wielkiej dziewiątce, przeznaczają miliardy na jej uprawę i wprowadzanie asystentów głosowych do wszystkich domów i codziennych zajęć.
Wybór platformy, z której chcesz skorzystać, może być trudny, ale w zależności od tego, co zamierzasz zbudować, platforma, której chcesz użyć, powinna błyszczeć lub, w przypadku jej niepowodzenia, skorzystać z narzędzia innej firmy, aby zabezpieczyć swoje zakłady i budować na wielu platformach, zwłaszcza jeśli masz umiejętności jest mniej skomplikowany z mniejszą liczbą ruchomych części.
Ja na przykład jestem podekscytowany przyszłością głosu, gdy stanie się on wszechobecny; Zależność od ekranu zmniejszy się, a klienci będą mogli w naturalny sposób wchodzić w interakcję ze swoim asystentem. Ale najpierw od nas zależy zbudowanie umiejętności, których ludzie będą chcieli od swojego asystenta.