
Zrozumienie Vary Header
Opublikowany: 2022-03-10Nagłówek HTTP Vary jest wysyłany w miliardach odpowiedzi HTTP każdego dnia. Jednak jego użycie nigdy nie spełniło swojej pierwotnej wizji, a wielu programistów źle rozumie, co robi lub nawet nie zdaje sobie sprawy, że wysyła go ich serwer sieciowy. Wraz z pojawieniem się wskazówek dla klientów, wariantów i kluczowych specyfikacji, zróżnicowane odpowiedzi zaczynają się od nowa.
Co się zmienia?
Historia Vary zaczyna się od pięknego pomysłu na to, jak powinna działać sieć. Zasadniczo adres URL nie reprezentuje strony internetowej, ale zasób koncepcyjny, taki jak wyciąg bankowy. Wyobraź sobie, że chcesz zobaczyć swój wyciąg bankowy: wchodzisz na bank.com i wysyłasz żądanie GET dla /statement . Jak na razie dobrze, ale nie podałeś, w jakim formacie chcesz otrzymać oświadczenie. Dlatego Twoja przeglądarka będzie zawierała również w żądaniu coś takiego jak Accept: text/html . Przynajmniej teoretycznie oznacza to, że możesz zamiast tego powiedzieć Accept: text/csv i uzyskać ten sam zasób w innym formacie.

Ponieważ ten sam adres URL generuje teraz różne odpowiedzi na podstawie wartości nagłówka Accept , każda pamięć podręczna przechowująca tę odpowiedź musi wiedzieć, że ten nagłówek jest ważny. Serwer informuje nas, że nagłówek Accept jest ważny w następujący sposób:
Vary: Accept Możesz przeczytać to jako: „Ta odpowiedź różni się w zależności od wartości nagłówka Accept twojego żądania”.
To w zasadzie nie działa w dzisiejszej sieci. Tak zwane „negocjacje treści” były świetnym pomysłem, ale się nie powiodły. Nie oznacza to jednak, że Vary są bezużyteczne. Przyzwoita część stron, które odwiedzasz w sieci, ma w odpowiedzi nagłówek „ Vary ” — być może Twoje witryny też je mają, a Ty o tym nie wiesz. Tak więc, jeśli nagłówek nie działa w przypadku negocjacji treści, dlaczego jest nadal tak popularny i jak radzą sobie z nim przeglądarki? Spójrzmy.
Pisałem wcześniej o Vary w odniesieniu do sieci dostarczania treści (CDN), tych pośrednich pamięci podręcznych (takich jak Fastly, CloudFront i Akamai), które można umieścić między serwerami a użytkownikiem. Przeglądarki muszą również rozumieć i reagować na reguły Vary, a sposób, w jaki to robią, różni się od sposobu, w jaki Vary są traktowane przez CDN. W tym poście będę badać mroczny świat zmienności pamięci podręcznej w przeglądarce.
Dzisiejsze przypadki użycia zmieniające się w przeglądarce
Jak widzieliśmy wcześniej, tradycyjnym zastosowaniem Vary jest przeprowadzanie negocjacji treści przy użyciu nagłówków Accept , Accept-Language i Accept-Encoding , i historycznie pierwsze dwa z nich nie powiodły się. Różnice w Accept-Encoding w celu dostarczenia odpowiedzi skompresowanych za pomocą Gzip lub Brotli, jeśli są obsługiwane, w większości działają dość dobrze, ale wszystkie przeglądarki obsługują obecnie Gzip, więc nie jest to zbyt ekscytujące.
A co z niektórymi z tych scenariuszy?
- Chcemy wyświetlać obrazy o dokładnej szerokości ekranu użytkownika. Jeśli użytkownik zmieni rozmiar przeglądarki, pobierzemy nowe obrazy (w zależności od wskazówek klienta).
- Jeśli użytkownik się wyloguje, chcemy uniknąć używania stron, które były buforowane, gdy były zalogowane (używając pliku cookie jako
Key). - Użytkownicy przeglądarek obsługujących format obrazu WebP powinni otrzymać obrazy WebP; w przeciwnym razie powinni otrzymać pliki JPEG.
- Korzystając z przeglądarki na ekranie o dużej gęstości, użytkownik powinien uzyskać 2x obrazy. Jeśli przeniosą okno przeglądarki na ekran o standardowej gęstości i odświeżą, powinni otrzymać obrazy 1x.
Cache Cache w dół
W przeciwieństwie do pamięci podręcznych brzegowych, które działają jak jedna gigantyczna pamięć podręczna współdzielona przez wszystkich użytkowników, przeglądarka jest przeznaczona tylko dla jednego użytkownika, ale ma wiele różnych pamięci podręcznych do różnych, specyficznych zastosowań:
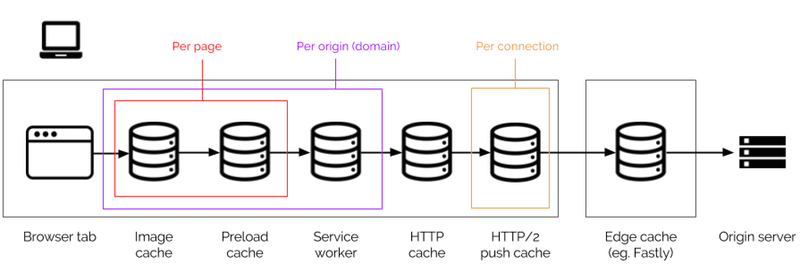
Niektóre z nich są całkiem nowe, a dokładne zrozumienie, z której pamięci podręcznej jest ładowana zawartość, jest złożonym obliczeniem, które nie jest dobrze obsługiwane przez narzędzia programistyczne. Oto, co robią te pamięci podręczne:
- pamięć podręczna obrazów
Jest to pamięć podręczna o zasięgu strony, która przechowuje zdekodowane dane obrazu, więc na przykład, jeśli wielokrotnie umieścisz ten sam obraz na stronie, przeglądarka musi go pobrać i zdekodować tylko raz. - wstępne ładowanie pamięci podręcznej
Jest to również zakres strony i przechowuje wszystko, co zostało wstępnie załadowane w nagłówkuLinklub w tagu<link rel="preload">, nawet jeśli zasób zwykle nie może być buforowany. Podobnie jak pamięć podręczna obrazów, pamięć podręczna ładowania wstępnego jest niszczona, gdy użytkownik opuszcza stronę. - Service Worker API cache
Zapewnia to zaplecze pamięci podręcznej z programowalnym interfejsem; więc nic nie jest tutaj przechowywane, chyba że specjalnie umieścisz je tam za pomocą kodu JavaScript w module Service Worker. Zostanie to również sprawdzone tylko wtedy, gdy wyraźnie zrobisz to w module obsługifetchprzez Service Worker. Pamięć podręczna procesu roboczego usługi jest objęta zakresem pochodzenia i chociaż nie ma gwarancji, że jest trwała, jest bardziej trwała niż pamięć podręczna HTTP przeglądarki. - Pamięć podręczna HTTP
To jest główna pamięć podręczna, z którą ludzie są najbardziej zaznajomieni. Jest to jedyna pamięć podręczna, która zwraca uwagę na nagłówki pamięci podręcznej na poziomie HTTP, takie jakCache-Control, i łączy je z własnymi regułami heurystycznymi przeglądarki, aby określić, czy coś buforować i na jak długo. Ma najszerszy zakres, wspólny dla wszystkich serwisów internetowych; jeśli więc dwie niepowiązane witryny ładują ten sam zasób (na przykład Google Analytics), mogą korzystać z tego samego działania w pamięci podręcznej. - Pamięć podręczna push HTTP/2 (lub „push cache H2”)
Jest to powiązane z połączeniem i przechowuje obiekty, które zostały wypchnięte z serwera, ale nie zostały jeszcze zażądane przez żadną stronę korzystającą z połączenia. Jest objęty zakresem do stron korzystających z określonego połączenia, które zasadniczo jest takie samo, jak zakres do jednego źródła, ale jest również niszczony po zamknięciu połączenia.
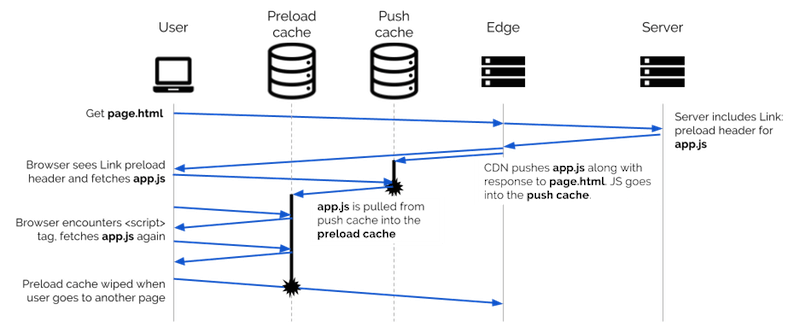
Spośród nich najlepiej zdefiniować pamięć podręczną HTTP i pamięć podręczną procesu roboczego. Jeśli chodzi o pamięci podręczne obrazów i wstępnego ładowania, niektóre przeglądarki mogą implementować je jako pojedynczą „pamięć podręczną” powiązaną z renderowaniem określonej nawigacji, ale model mentalny, który tutaj opisuję, nadal jest właściwym sposobem myślenia o tym procesie. Jeśli jesteś zainteresowany, zapoznaj się ze specyfikacją dotyczącą preload . W przypadku serwera push H2 dyskusja nad losem tej pamięci podręcznej pozostaje aktywna.
Kolejność, w której żądanie sprawdza te pamięci podręczne przed wejściem do sieci, jest ważna, ponieważ żądanie czegoś może przeciągnąć go z zewnętrznej warstwy pamięci podręcznej do wewnętrznej. Na przykład, jeśli Twój serwer HTTP/2 przesyła arkusz stylów wraz ze stroną, która go potrzebuje, a ta strona również wstępnie ładuje arkusz stylów ze <link rel="preload"> , arkusz stylów dotknie trzech pamięci podręczne w przeglądarce. Najpierw będzie siedzieć w pamięci podręcznej push H2, czekając na żądanie. Kiedy przeglądarka renderuje stronę i dotrze do tagu preload , wyciągnie arkusz stylów z pamięci podręcznej push, przez pamięć podręczną HTTP (która może go przechowywać, w zależności od nagłówka Cache-Control arkusza stylów) i zapisze go w pamięci podręcznej wstępnego ładowania.
Przedstawiamy Vary jako walidatora
OK, więc co się stanie, gdy weźmiemy tę sytuację i dodamy Vary do miksu?
W przeciwieństwie do pośrednich pamięci podręcznych (takich jak CDN) przeglądarki zazwyczaj nie implementują możliwości przechowywania wielu odmian na adres URL . Powodem tego jest to, że rzeczy, do których zwykle używamy Vary (głównie Accept-Encoding i Accept-Language ) nie zmieniają się często w kontekście pojedynczego użytkownika. Accept-Encoding może (ale prawdopodobnie nie) zmienić się po uaktualnieniu przeglądarki, a Accept-Language najprawdopodobniej zmieni się tylko wtedy, gdy zmienisz ustawienia regionalne języka systemu operacyjnego. Dużo łatwiej jest też zaimplementować w ten sposób Vary, chociaż niektórzy autorzy specyfikacji uważają, że był to błąd.
Przechowywanie przez przeglądarkę tylko jednej odmiany przez większość czasu nie jest wielką stratą, ale ważne jest, aby nie użyć przypadkowo odmiany, która nie jest już ważna, jeśli dane „varied on” ulegną zmianie.
Kompromis polega na traktowaniu Vary jako walidatora, a nie klucza. Przeglądarki obliczają klucze pamięci podręcznej w normalny sposób (zasadniczo przy użyciu adresu URL), a następnie, jeśli uzyskają trafienie, sprawdzają, czy żądanie spełnia wszelkie reguły Vary, które są wypiekane w buforowanej odpowiedzi. Jeśli tak się nie stanie, przeglądarka traktuje żądanie jako pominięcie pamięci podręcznej i przechodzi do następnej warstwy pamięci podręcznej lub do sieci. Po otrzymaniu nowej odpowiedzi nadpisze wersję z pamięci podręcznej, mimo że jest to technicznie inna odmiana.

Demonstrowanie różnych zachowań
Aby zademonstrować sposób obsługi Vary , stworzyłem mały zestaw testowy. Test ładuje szereg różnych adresów URL różniących się różnymi nagłówkami i wykrywa, czy żądanie trafiło do pamięci podręcznej, czy nie. Początkowo używałem do tego ResourceTiming, ale dla większej kompatybilności przełączyłem się na pomiar, jak długo trwa realizacja żądania (i celowo dodałem 1-sekundowe opóźnienie do odpowiedzi po stronie serwera, aby różnica była naprawdę wyraźna).
Przyjrzyjmy się każdemu z typów pamięci podręcznej i temu, jak powinna działać Vary i czy faktycznie tak działa. Dla każdego testu pokazuję tutaj, czy powinniśmy spodziewać się wyniku z pamięci podręcznej („HIT” kontra „MISS”) i co się właściwie wydarzyło.
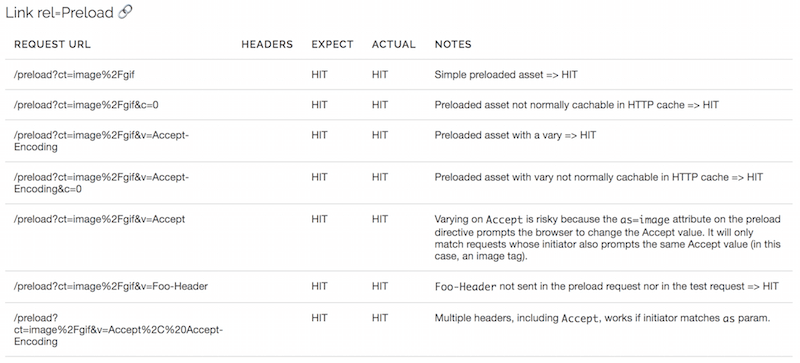
Wstępne ładowanie
Wstępne ładowanie jest obecnie obsługiwane tylko w Chrome, gdzie wstępnie załadowane odpowiedzi są przechowywane w pamięci podręcznej, dopóki strona nie będzie ich potrzebować. Odpowiedzi również zapełniają pamięć podręczną HTTP w drodze do pamięci podręcznej wstępnego ładowania, jeśli można ją buforować HTTP. Ponieważ określenie nagłówków żądań za pomocą wstępnego ładowania jest niemożliwe, a pamięć podręczna wstępnego ładowania działa tylko tak długo, jak strona, testowanie tego jest trudne, ale przynajmniej możemy zobaczyć, że obiekty z nagłówkiem Vary są pomyślnie wstępnie ładowane:
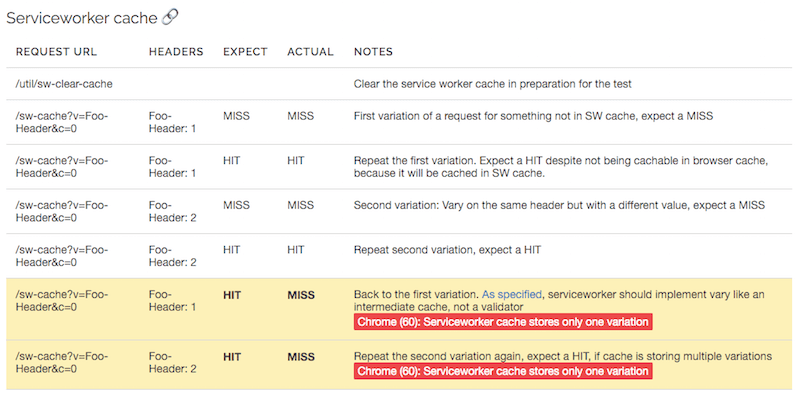
Interfejs API pamięci podręcznej Service Worker
Chrome i Firefox obsługują serviceworkers, a opracowując specyfikację serviceworker, autorzy chcieli naprawić to, co uważali za niepoprawne implementacje w przeglądarkach, aby Vary w przeglądarce działały bardziej jak CDN. Oznacza to, że chociaż przeglądarka powinna przechowywać tylko jedną odmianę w pamięci podręcznej HTTP, powinna przechowywać wiele odmian w Cache API. Firefox (54) robi to poprawnie, podczas gdy Chrome używa tej samej logiki różnicowania jako walidatora, której używa do pamięci podręcznej HTTP (błąd jest śledzony).
Pamięć podręczna HTTP
Główna pamięć podręczna HTTP powinna przestrzegać Vary i robi to konsekwentnie (jako walidator) we wszystkich przeglądarkach. Więcej informacji na ten temat można znaleźć w poście Marka Nottinghama „State of Browser Caching, Revisited”.
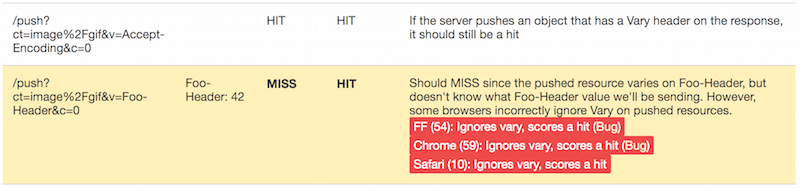
Pamięć podręczna wypychania HTTP/2
Należy przestrzegać wartości Vary , ale w praktyce żadna przeglądarka tak naprawdę tego nie przestrzega, a przeglądarki będą z radością dopasowywać i wykorzystywać wypychane odpowiedzi z żądaniami, które zawierają losowe wartości w nagłówkach, na których odpowiedzi są różnicowane.
Zmarszczka „304 (niezmodyfikowana)”
Stan odpowiedzi HTTP „304 (niezmodyfikowany)” jest fascynujący. Nasz „drogi lider”, Artur Bergman, zwrócił mi uwagę na tę perełkę w specyfikacji buforowania HTTP (podkreślenie moje):
Serwer generujący odpowiedź 304 musi wygenerować dowolne z następujących pól nagłówka, które zostałyby wysłane w odpowiedzi 200 (OK) na to samo żądanie:
Cache-Control,Content-Location,Date,ETag,ExpiresiVary.
Dlaczego odpowiedź 304 miałaby zwracać nagłówek Vary ? Fabuła gęstnieje, gdy czytasz o tym, co masz zrobić po otrzymaniu odpowiedzi 304 , która zawiera te nagłówki:
Jeśli przechowywana odpowiedź jest wybrana do aktualizacji, pamięć podręczna musi \[…] używać innych pól nagłówka podanych w odpowiedzi 304 (Niezmodyfikowana), aby zastąpić wszystkie wystąpienia odpowiednich pól nagłówka w przechowywanej odpowiedzi.
Czekaj, co? Więc jeśli nagłówek Vary 304 różni się od nagłówka w istniejącym buforowanym obiekcie, mamy zaktualizować buforowany obiekt? Ale może to oznaczać, że nie pasuje już do naszej prośby!
W tym scenariuszu, na pierwszy rzut oka, 304 wydaje się mówić jednocześnie, że możesz i nie możesz korzystać z wersji z pamięci podręcznej. Oczywiście, gdyby serwer naprawdę nie chciał, abyś używał wersji z pamięci podręcznej, wysłałby 200 , a nie 304 ; więc zdecydowanie należy użyć wersji z pamięci podręcznej — ale po zastosowaniu do niej aktualizacji może nie zostać ponownie wykorzystana w przyszłych żądaniach identycznych z tym, które faktycznie zapełniło pamięć podręczną.
(Uwaga na marginesie: w Fastly nie szanujemy tego dziwactwa specyfikacji. Tak więc, jeśli otrzymamy 304 z twojego serwera pochodzenia, będziemy nadal używać buforowanego obiektu w niezmienionej postaci, poza zresetowaniem TTL.)
Przeglądarki wydają się to szanować, ale z dziwactwem. Aktualizują nie tylko nagłówki odpowiedzi, ale nagłówki żądań, które są z nimi sparowane, aby zagwarantować, że po aktualizacji zbuforowana odpowiedź jest zgodna z bieżącym żądaniem. Wydaje się to mieć sens. Specyfikacja nie wspomina o tym, więc dostawcy przeglądarek mogą robić to, co im się podoba; na szczęście wszystkie przeglądarki wykazują to samo zachowanie.
Wskazówki dla klientów
Funkcja wskazówek klienta Google to jedna z najważniejszych nowych rzeczy, które od dłuższego czasu mogą się przydarzyć w przeglądarce Vary. W przeciwieństwie do Accept-Encoding i Accept-Language , wskazówki dla klientów opisują wartości, które mogą się regularnie zmieniać, gdy użytkownik porusza się po Twojej witrynie, w szczególności następujące:
-
DPR
Współczynnik pikseli urządzenia, gęstość pikseli ekranu (może się różnić, jeśli użytkownik ma wiele ekranów) -
Save-Data
Czy użytkownik włączył tryb oszczędzania danych -
Viewport-Width
Szerokość pikseli bieżącego obszaru roboczego -
Width
Pożądana szerokość zasobów w fizycznych pikselach
Nie tylko te wartości mogą się zmienić dla pojedynczego użytkownika, ale zakres wartości dla tych związanych z szerokością jest duży. Tak więc możemy całkowicie użyć Vary z tymi nagłówkami, ale ryzykujemy zmniejszenie wydajności naszej pamięci podręcznej lub nawet uczynienie pamięci podręcznej nieefektywną.
Kluczowa propozycja nagłówka
Wskazówki dla klientów i inne bardzo szczegółowe nagłówki nadają się do propozycji, nad którą pracował Mark, o nazwie Key. Spójrzmy na kilka przykładów:
Key: Viewport-Width;div=50 Oznacza to, że odpowiedź różni się w zależności od wartości nagłówka żądania Viewport-Width , ale jest zaokrąglana w dół do najbliższej wielokrotności 50 pikseli!
Key: cookie;param=sessionAuth;param=flags Dodanie tego nagłówka do odpowiedzi oznacza, że korzystamy z dwóch konkretnych plików cookie: sessionAuth i flags . Jeśli nie uległy zmianie, możemy ponownie wykorzystać tę odpowiedź do przyszłej prośby.
Tak więc główne różnice między Key a Vary to:
-
Keyumożliwia różnicowanie w podpolach w nagłówkach, co nagle sprawia, że staje się możliwe różnicowanie plików cookie, ponieważ możesz różnicować tylko jeden plik cookie — byłoby to ogromne; - poszczególne wartości można podzielić na zakresy , aby zwiększyć prawdopodobieństwo trafienia w pamięć podręczną, co jest szczególnie przydatne do różnicowania takich rzeczy, jak szerokość widocznego obszaru.
- wszystkie odmiany z tym samym adresem URL muszą mieć ten sam klucz. Jeśli więc pamięć podręczna otrzyma nową odpowiedź dla adresu URL, dla którego ma już niektóre istniejące warianty, a wartość nagłówka
Keynowej odpowiedzi nie jest zgodna z wartościami w tych istniejących wariantach, wszystkie warianty muszą zostać usunięte z pamięci podręcznej.
W chwili pisania tego tekstu żadna przeglądarka ani CDN nie obsługuje Key , chociaż w niektórych sieciach CDN możesz uzyskać ten sam efekt, dzieląc przychodzące nagłówki na wiele prywatnych nagłówków i zmieniając je (zobacz nasz post „Jak najlepiej wykorzystać Szybko”), więc przeglądarki są głównym obszarem, w którym Key może wywierać wpływ.
Wymóg, aby wszystkie odmiany miały ten sam kluczowy przepis, jest nieco ograniczający i chciałbym zobaczyć w specyfikacji jakąś opcję „wczesnego wyjścia”. Umożliwiłoby to wykonywanie takich czynności, jak „Udostępniaj stan uwierzytelniania, a po zalogowaniu zmieniaj również preferencje”.
Propozycja wariantów
Key to fajny ogólny mechanizm, ale niektóre nagłówki mają bardziej złożone reguły dotyczące ich wartości, a zrozumienie semantyki tych wartości może pomóc nam znaleźć automatyczne sposoby zmniejszania zmienności pamięci podręcznej. Na przykład wyobraź sobie, że przychodzą dwa żądania z różnymi wartościami Accept-Language , en-gb i en-us , ale chociaż Twoja witryna obsługuje różne wersje językowe, masz tylko jeden „angielski”. Jeśli odpowiemy na żądanie dotyczące języka angielskiego w USA, a odpowiedź zostanie zapisana w pamięci podręcznej w sieci CDN, nie można jej ponownie użyć w żądaniu w języku angielskim w Wielkiej Brytanii, ponieważ wartość Accept-Language byłaby inna, a pamięć podręczna nie jest wystarczająco inteligentna, aby wiedzieć lepiej .
Wejdź ze sporymi fanfarami do propozycji wariantów. Umożliwiłoby to serwerom opisanie obsługiwanych wariantów, umożliwiając pamięciom podręcznym podejmowanie mądrzejszych decyzji o tym, które warianty są faktycznie różne, a które faktycznie takie same.
W tej chwili Variants jest bardzo wczesną wersją roboczą, a ponieważ ma pomóc w Accept-Encoding i Accept-Language , jego użyteczność jest raczej ograniczona do współdzielonych pamięci podręcznych, takich jak CDN, a nie do pamięci podręcznych przeglądarki. Ale ładnie łączy się z Key i uzupełnia obraz, zapewniając lepszą kontrolę zmienności pamięci podręcznej.
Wniosek
Jest tu wiele do zrobienia i chociaż zrozumienie, jak przeglądarka działa pod maską, może być interesujące, można z niej wydobyć kilka prostych rzeczy:
- Większość przeglądarek traktuje
Varyjako walidator. Jeśli chcesz, aby było buforowanych wiele osobnych odmian, znajdź sposób na użycie różnych adresów URL. - Przeglądarki ignorują opcję
Varyw przypadku zasobów przekazywanych za pomocą serwera wypychanego HTTP/2, więc nie udostępniaj niczego, co wypychasz. - Przeglądarki mają mnóstwo pamięci podręcznych i działają na różne sposoby. Warto spróbować zrozumieć, jak decyzje dotyczące buforowania wpływają na wydajność w każdym z nich, zwłaszcza w kontekście
Vary. -
Varynie jest tak przydatne, jak mogłoby być, aKeyw połączeniu z wskazówkami klienta zaczyna to zmieniać. Postępuj zgodnie z obsługą przeglądarek, aby dowiedzieć się, kiedy możesz zacząć z nich korzystać.
Idź naprzód i bądź zmienny.