
Kompletny przewodnik po tworzeniu skalowalnych skrobaków internetowych za pomocą Scrapy
Opublikowany: 2022-03-10Web scraping to sposób na pobieranie danych z witryn internetowych bez konieczności dostępu do interfejsów API lub bazy danych witryny. Potrzebujesz tylko dostępu do danych witryny — tak długo, jak Twoja przeglądarka ma dostęp do danych, będziesz mógł je zeskrobać.
Realistycznie rzecz biorąc, w większości przypadków można po prostu ręcznie przejść przez witrynę internetową i pobrać dane „ręcznie” za pomocą funkcji kopiowania i wklejania, ale w wielu przypadkach wymagałoby to wielu godzin ręcznej pracy, co może kosztować cię o wiele więcej niż dane są warte, zwłaszcza jeśli zatrudniłeś kogoś do wykonania tego zadania za Ciebie. Po co zatrudniać kogoś do pracy po 1-2 minutach na zapytanie, skoro można uzyskać program do automatycznego wykonywania zapytania co kilka sekund?
Załóżmy na przykład, że chcesz sporządzić listę zdobywców Oscara dla najlepszego filmu, wraz z reżyserem, aktorami w rolach głównych, datą premiery i czasem trwania. Korzystając z Google, możesz zobaczyć, że istnieje kilka witryn, które wyświetlają te filmy według nazwy i być może z dodatkowymi informacjami, ale generalnie będziesz musiał przejść za pomocą linków, aby przechwycić wszystkie potrzebne informacje.
Oczywiście niepraktyczne i czasochłonne byłoby przechodzenie przez każdy link od 1927 roku do dzisiaj i ręczne wyszukiwanie informacji na każdej stronie. W przypadku web scrapingu wystarczy znaleźć witrynę ze stronami, które zawierają wszystkie te informacje, a następnie skierować nasz program we właściwym kierunku za pomocą odpowiednich instrukcji.
W tym samouczku użyjemy Wikipedii jako naszej strony internetowej, ponieważ zawiera ona wszystkie potrzebne nam informacje, a następnie użyjemy Scrapy w Pythonie jako narzędzia do scrapowania naszych informacji.
Kilka uwag przed rozpoczęciem:
Zbieranie danych polega na zwiększeniu obciążenia serwera dla witryny, którą zbierasz, co oznacza wyższy koszt dla firm hostujących witrynę i niższą jakość dla innych użytkowników tej witryny. Jakość serwera, na którym działa witryna, ilość danych, które próbujesz uzyskać, oraz szybkość, z jaką wysyłasz żądania do serwera, będą moderować wpływ, jaki masz na serwer. Mając to na uwadze, musimy upewnić się, że trzymamy się kilku zasad.
Większość witryn ma również w głównym katalogu plik o nazwie robots.txt . Ten plik określa zasady dotyczące katalogów, do których witryny nie chcą uzyskiwać dostępu do scraperów. Strona Regulaminu witryny zazwyczaj informuje o zasadach dotyczących zbierania danych. Na przykład strona warunków IMDB zawiera następującą klauzulę:
Roboty i Screen Scraping: Użytkownik nie może korzystać z eksploracji danych, robotów, screen scrapingu lub podobnych narzędzi do gromadzenia i ekstrakcji danych na tej stronie, chyba że za naszą wyraźną pisemną zgodą, jak wskazano poniżej.
Zanim spróbujemy uzyskać dane witryny, zawsze powinniśmy sprawdzić warunki witryny i robots.txt , aby upewnić się, że pozyskujemy dane prawne. Budując nasze scrapery, musimy również upewnić się, że nie przytłoczymy serwera żądaniami, których nie może obsłużyć.
Na szczęście wiele serwisów dostrzega potrzebę pozyskiwania danych przez użytkowników i udostępnia je za pośrednictwem interfejsów API. Jeśli są one dostępne, zwykle łatwiej jest uzyskać dane za pośrednictwem interfejsu API niż przez skrobanie.
Wikipedia pozwala na scraping danych, o ile boty nie poruszają się „zbyt szybko”, jak określono w ich robots.txt . Zapewniają również zestawy danych do pobrania, dzięki czemu ludzie mogą przetwarzać dane na własnych komputerach. Jeśli pójdziemy zbyt szybko, serwery automatycznie zablokują nasze IP, więc zaimplementujemy liczniki czasu, aby zachować zgodność z ich regułami.
Rozpoczęcie pracy, instalowanie odpowiednich bibliotek za pomocą Pip
Przede wszystkim na początek zainstalujmy Scrapy.
Okna
Zainstaluj najnowszą wersję Pythona z https://www.python.org/downloads/windows/
Uwaga: użytkownicy systemu Windows będą również potrzebować Microsoft Visual C ++ 14.0, który można pobrać z "Narzędzi do budowania Microsoft Visual C ++" tutaj.
Upewnij się również, że masz najnowszą wersję pip.
W cmd.exe wpisz:
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapySpowoduje to automatyczną instalację Scrapy i wszystkich zależności.
Linux
Najpierw będziesz chciał zainstalować wszystkie zależności:
W Terminalu wpisz:
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-devPo zainstalowaniu wystarczy wpisać:
pip install --upgrade pipAby upewnić się, że pip jest zaktualizowany, a następnie:
pip install scrapyI wszystko gotowe.
Prochowiec
Najpierw musisz się upewnić, że masz c-kompilator w swoim systemie. W Terminalu wpisz:
xcode-select --installNastępnie zainstaluj homebrew z https://brew.sh/.
Zaktualizuj zmienną PATH, aby pakiety homebrew były używane przed pakietami systemowymi:
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrcZainstaluj Pythona:
brew install pythonA potem upewnij się, że wszystko jest zaktualizowane:
brew update; brew upgrade pythonPo wykonaniu tej czynności po prostu zainstaluj Scrapy za pomocą pip:
pip install Scrapy > ## Przegląd Scrapy, jak kawałki pasują do siebie, parsery, pająki itp.Będziesz pisać skrypt o nazwie „Pająk”, aby uruchomić Scrapy, ale nie martw się, pająki Scrapy wcale nie są przerażające pomimo swojej nazwy. Jedynym podobieństwem między pająkami Scrapy a prawdziwymi pająkami jest to, że lubią czołgać się po sieci.
Wewnątrz pająka znajduje się class , którą definiujesz, która mówi Scrapy'emu, co ma robić. Na przykład, od czego zacząć indeksowanie, rodzaje wysyłanych żądań, jak podążać za linkami na stronach i jak analizuje dane. Możesz nawet dodać niestandardowe funkcje do przetwarzania danych, zanim wyprowadzisz je z powrotem do pliku.
Aby uruchomić naszego pierwszego pająka, musimy najpierw stworzyć projekt Scrapy. Aby to zrobić, wpisz to w wierszu poleceń:
scrapy startproject oscarsSpowoduje to utworzenie folderu z Twoim projektem.
Zaczniemy od podstawowego pająka. Poniższy kod należy wpisać do skryptu Pythona. Otwórz nowy skrypt Pythona w /oscars/spiders i nazwij go oscars_spider.py
Zaimportujemy Scrapy.
import scrapyNastępnie zaczynamy definiować naszą klasę Spider. Najpierw ustalamy nazwę, a następnie domeny, które pająk może zeskrobać. Na koniec mówimy pająkowi, od czego ma zacząć skrobanie.
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']Następnie potrzebujemy funkcji, która przechwyci żądane przez nas informacje. Na razie pobierzemy tylko tytuł strony. Używamy CSS, aby znaleźć tag, który zawiera tekst tytułu, a następnie go wyodrębniamy. Na koniec zwracamy informacje z powrotem do Scrapy, aby zostały zarejestrowane lub zapisane w pliku.
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data Teraz zapisz kod w /oscars/spiders/oscars_spider.py
Aby uruchomić tego pająka, po prostu przejdź do wiersza poleceń i wpisz:
scrapy crawl oscarsPowinieneś zobaczyć wynik taki:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
Gratulacje, zbudowałeś swój pierwszy podstawowy skrobak Scrapy!

Pełny kod:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield dataOczywiście chcemy, aby robił trochę więcej, więc przyjrzyjmy się, jak używać Scrapy do analizowania danych.
Najpierw zapoznajmy się z powłoką Scrapy. Powłoka Scrapy może pomóc w przetestowaniu kodu, aby upewnić się, że Scrapy pobiera żądane dane.
Aby uzyskać dostęp do powłoki, wprowadź to w wierszu poleceń:
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”Zasadniczo otworzy to stronę, na którą go skierowałeś, i pozwoli ci uruchomić pojedyncze wiersze kodu. Na przykład możesz wyświetlić nieprzetworzony kod HTML strony, wpisując:
print(response.text)Lub otwórz stronę w domyślnej przeglądarce, wpisując:
view(response)Naszym celem jest tutaj znalezienie kodu, który zawiera potrzebne nam informacje. Na razie spróbujmy pobrać tylko nazwy tytułów filmów.
Najłatwiejszym sposobem znalezienia potrzebnego kodu jest otwarcie strony w naszej przeglądarce i sprawdzenie kodu. W tym przykładzie używam Chrome DevTools. Wystarczy kliknąć prawym przyciskiem myszy dowolny tytuł filmu i wybrać opcję „Sprawdź”:
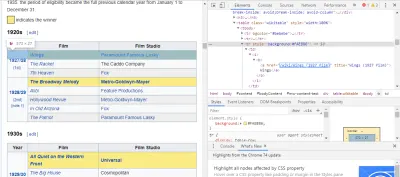
Jak widać, zdobywcy Oscarów mają żółte tło, podczas gdy nominowani mają tło gładkie. Jest tam również link do artykułu o tytule filmu, a linki do filmów kończą się na film) . Teraz, gdy już to wiemy, możemy użyć selektora CSS do pobrania danych. W powłoce Scrapy wpisz:
response.css(r"tr[] a[href*='film)']").extract()Jak widać, masz teraz listę wszystkich zdobywców Oscara za najlepsze zdjęcia!
> response.css(r"tr[] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']Wracając do naszego głównego celu, chcemy otrzymać listę zdobywców Oscara za najlepszy obraz, wraz z ich reżyserem, aktorami w rolach głównych, datą premiery i czasem trwania. Aby to zrobić, potrzebujemy Scrapy, aby pobrać dane z każdej z tych stron filmów.
Będziemy musieli przepisać kilka rzeczy i dodać nową funkcję, ale nie martw się, to całkiem proste.
Zaczniemy od zainicjowania skrobaka w taki sam sposób, jak poprzednio.
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] Ale tym razem zmienią się dwie rzeczy. Najpierw zaimportujemy time wraz ze scrapy , ponieważ chcemy utworzyć licznik czasu, aby ograniczyć szybkość skrobania bota. Ponadto, gdy analizujemy strony po raz pierwszy, chcemy uzyskać tylko listę linków do każdego tytułu, abyśmy mogli zamiast tego pobrać informacje z tych stron.
def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req Tutaj robimy pętlę, aby wyszukać każdy link na stronie, który kończy się film) z żółtym tłem, a następnie łączymy te linki razem w listę adresów URL, które wyślemy do funkcji parse_titles , aby przekazać dalej. Wstawiamy również licznik czasu, aby żądał stron tylko co 5 sekund. Pamiętaj, że możemy użyć powłoki Scrapy do przetestowania naszych pól response.css , aby upewnić się, że otrzymujemy prawidłowe dane!
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data Prawdziwa praca jest wykonywana w naszej funkcji parse_data , w której tworzymy słownik o nazwie data , a następnie wypełniamy każdy klucz żądanymi informacjami. Ponownie, wszystkie te selektory zostały znalezione przy użyciu Chrome DevTools, jak zademonstrowano wcześniej, a następnie przetestowane z powłoką Scrapy.
Ostatnia linia zwraca słownik danych z powrotem do Scrapy do przechowywania.
Pełny kod:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield dataCzasami będziemy chcieli użyć serwerów proxy, ponieważ strony internetowe będą próbować blokować nasze próby skrobania.
Aby to zrobić, wystarczy zmienić kilka rzeczy. Korzystając z naszego przykładu, w naszym def parse() , musimy zmienić go na następujący:
def parse(self, response): for href in (r"tr[] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "https://yourproxy.com:80" yield reqSpowoduje to przekierowanie żądań przez serwer proxy.
Wdrożenie i logowanie, pokaż, jak właściwie zarządzać pająkiem w produkcji
Teraz nadszedł czas, aby uruchomić naszego pająka. Aby Scrapy zaczął zdrapywać, a następnie wyprowadzał do pliku CSV, wprowadź następujące polecenie w wierszu polecenia:
scrapy crawl oscars -o oscars.csvZobaczysz duży wynik, a po kilku minutach zakończy się i będziesz miał plik CSV w folderze projektu.
Kompilowanie wyników, pokaż, jak korzystać z wyników skompilowanych w poprzednich krokach
Po otwarciu pliku CSV zobaczysz wszystkie potrzebne nam informacje (posortowane według kolumn z nagłówkami). To naprawdę takie proste.
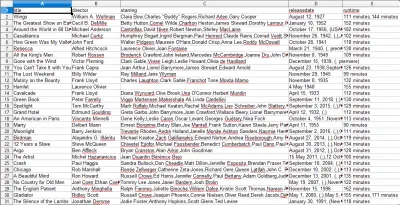
Dzięki zbieraniu danych możemy uzyskać prawie każdy niestandardowy zestaw danych, który chcemy, o ile informacje są publicznie dostępne. To, co chcesz zrobić z tymi danymi, zależy od Ciebie. Ta umiejętność jest niezwykle przydatna do prowadzenia badań rynkowych, aktualizowania informacji na stronie internetowej i wielu innych rzeczy.
Skonfigurowanie własnego skrobaka internetowego w celu samodzielnego uzyskania niestandardowych zestawów danych jest dość łatwe, jednak zawsze pamiętaj, że mogą istnieć inne sposoby uzyskania potrzebnych danych. Firmy dużo inwestują w dostarczanie żądanych danych, więc uczciwe jest przestrzeganie ich warunków.
Dodatkowe zasoby, aby dowiedzieć się więcej o scrappy i web scraping w ogóle
- Oficjalna strona Scrapy
- Strona GitHub Scrapy
- „10 najlepszych narzędzi do usuwania danych i narzędzi do pozyskiwania danych z sieci”, Scraper API
- „5 wskazówek dotyczących usuwania danych z sieci bez blokowania lub umieszczania na czarnej liście”, Scraper API
- Parsel, biblioteka Pythona do używania wyrażeń regularnych do wyodrębniania danych z HTML.