
Drzewa w strukturze danych: 8 rodzajów drzew, o których powinien wiedzieć każdy specjalista ds. danych
Opublikowany: 2021-05-26Spis treści
Wstęp
W dziedzinie obliczeniowej struktury danych odnoszą się do wzorca rozmieszczenia danych na dysku, co umożliwia wygodne przechowywanie i wyświetlanie. Dotyczą one dziedziny nauki o danych, która zgodnie z przewidywaniami będzie lukratywnym wyborem kariery w 2021 roku. W oparciu o prognozy na najbliższe kilka lat, wielkoskalowe modele głębokiego uczenia i inteligentne urządzenia nowej generacji utorują przyszłość tym sektorze.
Zatem zdobycie wiedzy o strukturach danych byłoby niezbędne do znalezienia odpowiedniej kariery w warunkach zaawansowania technologicznego. Zgodnie z prognozą Data Science Industry na 2021 r. Stany Zjednoczone i Indie zatrudnią około 50 000 naukowców zajmujących się danymi i 300 000 analityków danych w swoich ponad 250 000 firmach. [1]
Struktury danych są stosowane do projektowania ścieżek alokacji, zarządzania i wyszukiwania informacji. Struktury danych są szczególnie potrzebne do opracowania i poprawy wydajności całości przetwarzanych danych. Zarządzają danymi grupując i porządkując je, aby skutecznie ułatwić wymianę informacji.
Drzewa w strukturach danych
„Drzewa” to rodzaj ADT (abstrakcyjnych typów danych), które stosują hierarchiczny wzorzec przydziału danych. Zasadniczo drzewo jest zbiorem wielu węzłów połączonych krawędziami. Te „drzewa” tworzą strukturę danych przypominającą drzewo, w którym węzeł „główny” prowadzi do węzłów „rodzicowych”, które ostatecznie prowadzą do węzłów „podrzędnych”. Połączenia wykonuje się liniami zwanymi „krawędziami”.
Węzły „liść” są punktami końcowymi bez dalszych węzłów podrzędnych pochodzących z nich. Drzewa w strukturach danych odgrywają istotną rolę ze względu na nieliniowy charakter ich rozmieszczenia. Umożliwia to szybszy czas reakcji podczas wyszukiwania, a także wygodę na wszystkich etapach projektowania.
Rodzaje drzew w strukturze danych
Poniżej szczegółowo wyjaśniono różne rodzaje drzew w strukturach danych :
1. Ogólne drzewo
Ogólne drzewo charakteryzuje się brakiem specyfikacji lub ograniczeń dotyczących liczby dzieci, które może mieć węzeł. Każde drzewo o strukturze hierarchicznej można sklasyfikować jako drzewo ogólne. Węzeł może mieć wiele dzieci i może istnieć dowolna kombinacja orientacji drzewa. Węzły mogą mieć dowolny stopień, od 0 do n.
Poniżej znajduje się klasyczny przykład ogólnego drzewa w strukturze danych, gdzie „2” na górze jest węzłem głównym.
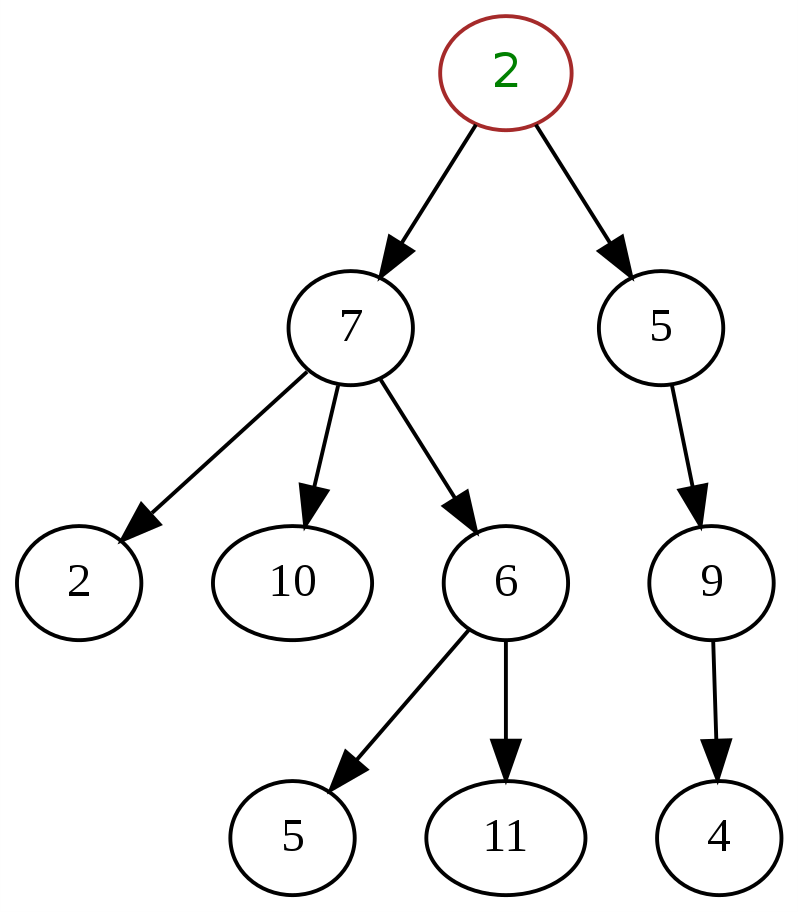
Źródło
2. Drzewo binarne
Zgodnie z definicją słowa „binary”, co oznacza dwie liczby, drzewo binarne składa się z węzłów, które mogą mieć 2 węzły podrzędne. Każdy węzeł w drzewie binarnym może mieć maksymalnie 0, 1 lub 2 węzły. Drzewa binarne w strukturach danych są wysoce funkcjonalnymi narzędziami ADT i można je dalej podzielić na wiele typów. Są one używane głównie w strukturach danych w dwóch celach:
- Aby uzyskać dostęp do węzłów i oznaczać je, jak zaobserwowano w Binary Search Trees.
- Do reprezentacji danych poprzez strukturę bifurkacyjną.
Poniżej znajduje się podstawowy schemat drzewa binarnego w strukturze danych:
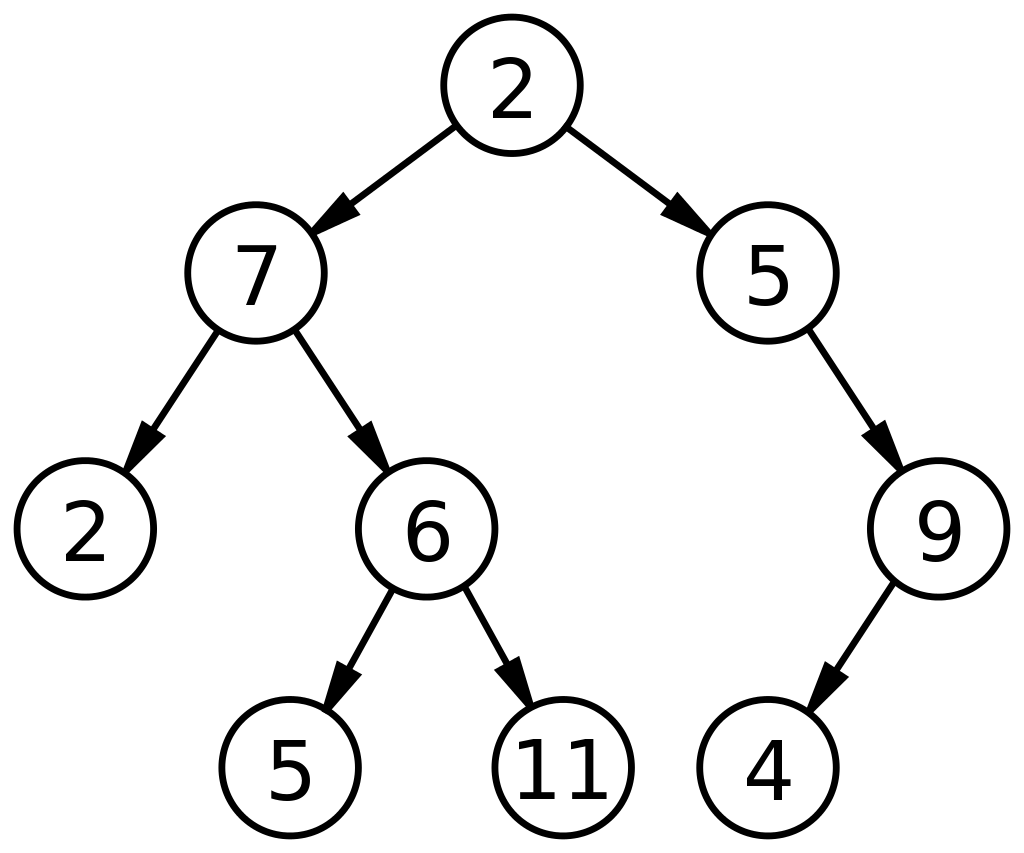
Źródło
3. Binarne drzewo wyszukiwania
Drzewo wyszukiwania binarnego (BST) to unikalny podtyp drzew binarnych, które są ułożone w sposób ułatwiający szybsze wyszukiwanie/wyszukiwanie lub dodawanie/usuwanie danych. BST jest definiowany przez reprezentację węzłów w oparciu o trzy pola: dane, jego lewy element potomny i jego prawy element potomny. Czynniki rządzące dla BST to:
- Każdy węzeł po lewej stronie (lewy element potomny) musi zawierać wartość mniejszą niż jego węzeł nadrzędny.
- Każdy węzeł po prawej stronie (prawe dziecko) musi posiadać wartość wyższą niż jego węzeł nadrzędny.
Taki układ skraca czasy wyszukiwania do połowy wyszukiwania liniowego, jakie można znaleźć w tablicy. Tak więc drzewa wyszukiwania binarnego w strukturach danych mają szerokie zastosowanie do wyszukiwania i sortowania w porównaniu z innymi narzędziami ADT.
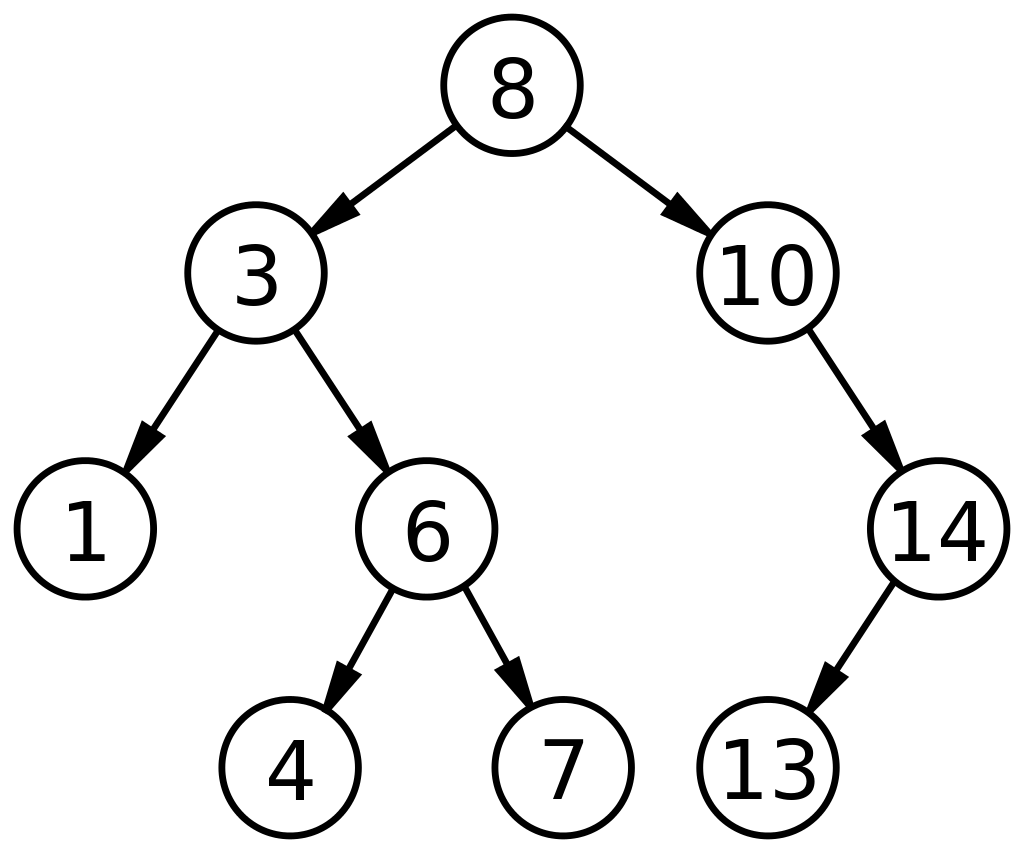
Źródło
Chociaż zarówno BT, jak i BST są zasadniczo drzewami w strukturach danych , nie dajcie się zmylić podobieństwem ich nazw. Dowiedz się szczegółowo o różnicy między drzewem binarnym a drzewem wyszukiwania binarnego na upGrad.
4. Drzewo AVL
Drzewo AVL wywodzi swoją nazwę od jego wynalazców: Adelson-Velsky i Landis. Drzewo AVL charakteryzuje się samobalansującą naturą. Wysokości dwóch poddrzew jego węzłów głównych są ograniczone do mniej niż dwóch. Gdy różnica wysokości wzrośnie powyżej 1, węzły podrzędne zostaną ponownie zrównoważone.
Drzewa AVL są zrównoważone pod względem wysokości, a to przywracanie równowagi następuje poprzez pojedyncze lub podwójne obroty. Współczynnik równoważenia to różnica między wysokościami lewego poddrzewa i prawego poddrzewa, a wartości to -1, 0 i 1.
5. Czerwone czarne drzewo
Ten typ przypomina drzewa AVL, ponieważ czerwono-czarne drzewa są również wyrównane wysokościowo. To, co je dzieli, to fakt, że nie wymagają więcej niż dwóch obrotów, aby je zrównoważyć. Zawierają dodatkowy bit, który określa czerwony lub czarny kolor węzła, co zapewnia równowagę drzew podczas usuwania i wstawiania. Kodowanie w kolorze czerwono-czarnym jest również przemalowywane podczas zmian, ale prawie bez dodatkowych kosztów pamięci.

6. Rozwiń drzewo
Inny podtyp drzewa wyszukiwania binarnego, drzewo splay, ma unikalną właściwość wykonywania operacji obrotowych w celu dostosowania ostatniego węzła. Węzeł, do którego uzyskano ostatnio dostęp, jest ustawiany jako węzeł główny poprzez wykonanie rotacji. Jest to drzewo zrównoważone, ale nie zrównoważone wysokościowo.
Akcja „rozkładania” jest przeprowadzana po wstępnym przeszukiwaniu drzewa binarnego, ponieważ rotacje drzew są wykonywane w określony sposób. Po każdej operacji drzewo jest obracane, aby się zrównoważyć, a poszukiwany element jest umieszczany na górze jako węzeł główny.
7. Trep
„Skarby” w strukturach danych są kombinacją drzew i stert. W BST wartość lewego dziecka musi być mniejsza niż węzeł główny, a wartość prawego dziecka musi być wyższa. W strukturze danych sterty węzeł główny ma najniższą wartość, a jego węzły podrzędne (zarówno lewy, jak i prawy) mają większe wartości.
Zatem treap zawiera wartość w postaci klucza (przypominającego BST) i priorytetu (jak sterty). Węzły o najwyższym priorytecie są wstawiane jako pierwsze do drzewa wyszukiwania binarnego w taki sposób, że liczby o priorytecie są niezależnymi liczbami losowymi. Utrzymują dynamiczny zestaw uporządkowanych kluczy i umożliwiają wyszukiwanie binarne w swoich kluczach.
8. B-drzewo
Jako samobalansujące drzewo w strukturach danych, B-Tree sortuje dane, aby umożliwić wyszukiwanie, dostęp sekwencyjny, usuwanie i wstawianie w czasie logarytmicznym. W przeciwieństwie do drzewa binarnego, B-drzewo pozwala swoim węzłom mieć więcej niż dwoje dzieci. Są kompatybilne z bazami danych i systemami plików, które odczytują i zapisują większe bloki danych.
Drzewo B w strukturach danych jest używane w przypadku większych systemów pamięci masowej, takich jak dyski. Wszystkie liście nie zawierają żadnych informacji i pojawiają się na tym samym poziomie. Wewnętrzne węzły B-drzewa mogą mieć zmienną wielkość węzłów potomnych powiązanych zakresem.
Są to drzewa w strukturach danych , które są implementowane przez programistów projektujących przepływ danych. Poznanie ich unikalnych cech i zastosowań jest niezbędne na drodze do stania się naukowcem danych. Inną metodą podnoszenia umiejętności byłaby praktyka poprzez różne projekty, które wymagają znajomości drzew w strukturach danych i innych formach ADT.
Aby zastosować swoją wiedzę w projektach DS, poniższe linki na blogu zawierają 13 ciekawych pomysłów na projekty dotyczące struktury danych i tematy dla początkujących [2021] .
Wniosek
Poznanie pojęć, takich jak drzewa w strukturze danych, może być trudne, a aspiranci do programowania potrzebują wskazówek ekspertów, aby się kształcić. Aby dowiedzieć się więcej o drzewach w strukturze danych, zapoznaj się z kursami online upGrad . Program Executive PG w tworzeniu oprogramowania – Specjalizacja w DevOps z DevOps by IIIT-B i upGrad może pomóc Ci zbudować karierę jako programista.
Ponieważ biegłość w zakresie struktur danych jest integralną częścią procesu kodowania, może pomóc uczniowi stać się ekspertem w zakresie programowania i programisty. Programiści i analitycy danych z pewnością będą potrzebni w nadchodzących dekadach.
W Indiach mamy 500 milionów użytkowników Internetu, którzy generują i zużywają duże ilości danych, co wymaga zatrudnienia tysięcy naukowców zajmujących się danymi, aby sprostać zapotrzebowaniu. [2] Ci naukowcy zajmujący się danymi potrzebują odpowiedniego wykształcenia, z odpowiednią wiedzą technologiczną, aby szukać pracy w tym sektorze.
Program Executive PG w tworzeniu oprogramowania – specjalizacja w rozwoju pełnego stosu , kuratorowany przez upGrad i IIIT-Bangalore, może pomóc w poprawie twojego profilu i zapewnieniu lepszych możliwości zatrudnienia jako programista.
- Drzewo wyszukiwania to struktura danych używana do lokalizowania określonych kluczy w zestawie danych. Klucz każdego węzła musi być większy niż klucze w poddrzewach po lewej stronie, ale mniejszy niż klucze w poddrzewach po prawej stronie, aby drzewo działało jako drzewo wyszukiwania. Dane hierarchiczne, takie jak struktura folderów, struktura organizacyjna i dane XML/HTML, powinny być przechowywane w drzewach. Idealne drzewo binarne to takie, w którym każdy węzeł wewnętrzny ma dwoje potomków, a każdy liść ma tę samą głębokość lub poziom. Wykres pochodzenia (niekazirodczego) osoby do określonej głębokości jest przykładem doskonałego drzewa binarnego, ponieważ każda osoba ma dokładnie dwóch biologicznych rodziców (matkę i ojca).Jakich drzew można użyć do wyszukiwania?<br />
- Gdy drzewo jest dość zrównoważone, to znaczy liście na obu końcach mają równoważną głębokość, drzewa wyszukiwania mają przewagę pod względem czasu wyszukiwania. Istnieje wiele różnych struktur danych w drzewie wyszukiwania, z których niektóre dodatkowo pozwalają na sprawne wstawianie i usuwanie elementów, których działania muszą następnie zachować równowagę drzewa.
— Tablica asocjacyjna jest często implementowana przy użyciu drzew wyszukiwania. Algorytm drzewa wyszukiwania lokalizuje miejsce przy użyciu klucza z pary klucz-wartość, a następnie aplikacja przechowuje w tym miejscu całą parę klucz-wartość.
- Drzewa wyszukiwania binarnego, B-drzewa, (a,b)-drzewa i ternarne drzewa wyszukiwania są przykładami drzew wyszukiwania. Jakie są główne zastosowania struktury danych drzewa?
1. Drzewo wyszukiwania binarnego to drzewo, które umożliwia szybkie wyszukiwanie, wstawianie i usuwanie posortowanych danych. Pomaga również zlokalizować przedmiot, który jest najbliżej Ciebie.
2. Sterta jest drzewiastą strukturą danych, która wykorzystuje tablice i służy do konstruowania kolejek priorytetowych.
3. B-Tree i B+ Tree to dwa rodzaje drzew indeksujących używanych w bazach danych.
4. Kompilatory używają drzewa składni.
5. Drzewo partycjonujące przestrzeń używane do organizowania punktów w przestrzeni wymiarowej K jest znane jako Drzewo KD.
6. Trie to struktura danych używana do tworzenia słowników z wyszukiwaniem prefiksów.
7. Drzewo przyrostków służy do szybkiego wyszukiwania wzorców w ustalonym tekście.
8. W sieciach komputerowych routery i mosty wykorzystują odpowiednio drzewa opinające oraz drzewa o najkrótszej ścieżce. Czym jest idealne drzewo?