
15 najlepszych pytań i odpowiedzi podczas wywiadu Hadoop w 2022 r.
Opublikowany: 2021-01-09Wraz z rozwojem analityki danych nastąpił gwałtowny wzrost zapotrzebowania na ludzi, którzy dobrze radzą sobie z Big Data. Od analityków danych po naukowców zajmujących się danymi, Big Data tworzy dziś szereg profili zawodowych. Pierwszą i najważniejszą rzeczą, z którą oczekujesz, że będziesz mieć kontakt, jest Hadoop.
Bez względu na stanowisko/profil, prawdopodobnie będziesz pracować nad Hadoop w taki czy inny sposób. Tak więc zawsze możesz oczekiwać, że ankieterzy zastrzelą kilka pytań Hadoop na swój sposób.
W tym celu spójrzmy na 15 najczęściej zadawanych pytań do rozmowy kwalifikacyjnej Hadoop, których można się spodziewać podczas każdej rozmowy kwalifikacyjnej.
Co to jest Hadoop? Jakie są główne składniki Hadoop?
Hadoop to infrastruktura wyposażona w odpowiednie narzędzia i usługi wymagane do przetwarzania i przechowywania Big Data. Mówiąc dokładniej, Hadoop jest „rozwiązaniem” wszystkich wyzwań związanych z Big Data. Ponadto platforma Hadoop pomaga również organizacjom analizować Big Data i podejmować lepsze decyzje biznesowe.
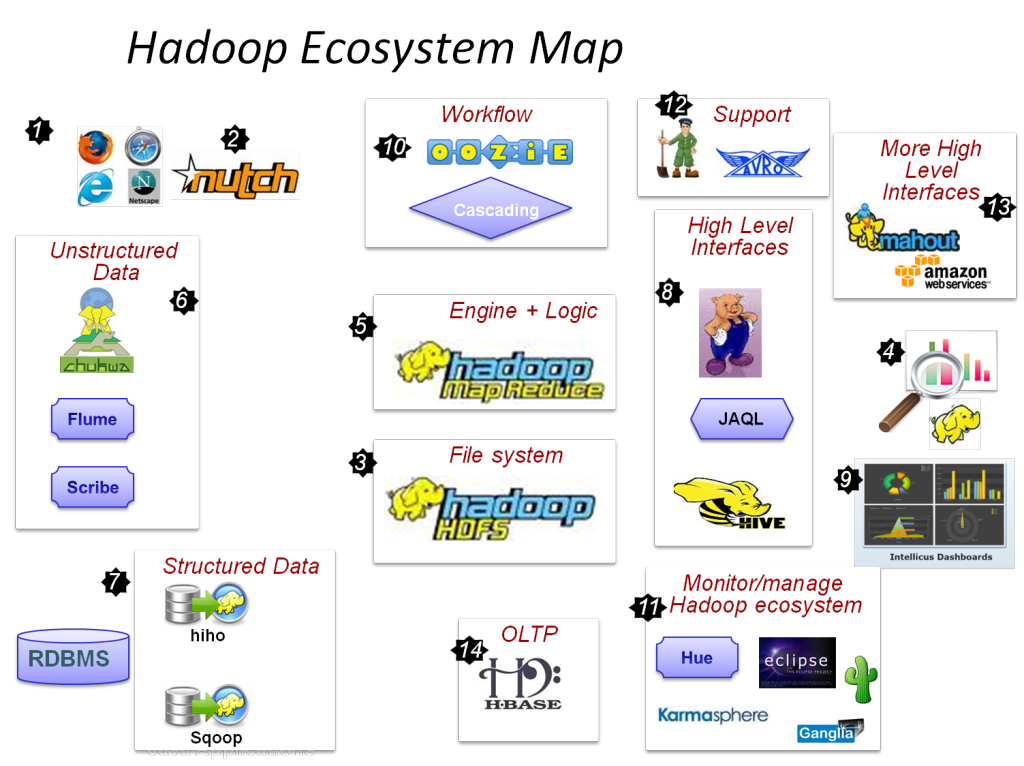
Główne składniki Hadoop to:
- HDFS
- Mapa HadoopReduce
- Hadoop Wspólne
- PRZĘDZA
- PIG i HIVE — komponenty dostępu do danych.
- HBase – do przechowywania danych
- Ambari, Oozie i ZooKeeper – komponent zarządzania i monitorowania danych
- Thrift i Avro — komponenty do serializacji danych
- Apache Flume, Sqoop, Chukwa – komponenty integracji danych
- Apache Mahout and Drill — komponenty do analizy danych
Jakie są podstawowe koncepcje platformy Hadoop?
Hadoop opiera się zasadniczo na dwóch podstawowych koncepcjach. Oni są:
- HDFS: HDFS lub Hadoop Distributed File System to niezawodny system plików oparty na Javie, używany do przechowywania ogromnych zestawów danych w formacie blokowym. Napędza go architektura Master-Slave.
- MapReduce: MapReduce to struktura programistyczna, która pomaga przetwarzać duże zestawy danych. Ta funkcja jest dalej podzielona na dwie części – podczas gdy „mapa” segreguje zbiory danych na krotki, „redukcja” wykorzystuje krotki mapy i tworzy kombinację mniejszych fragmentów krotek.
Nazwij najpopularniejsze formaty wejściowe w Hadoop?
W Hadoop istnieją trzy popularne formaty wejściowe:
- Format wprowadzania tekstu: jest to domyślny format wprowadzania w Hadoop.
- Format wejściowy pliku sekwencyjnego: Ten format wejściowy jest używany do odczytywania plików w kolejności.
- Format wejściowy wartości klucza: Ten służy do odczytywania plików tekstowych.
Co to jest PRZĘDZA?
YARN to skrót od Yet Another Resource Negotiator. Jest to struktura przetwarzania danych Hadoop, która zarządza zasobami danych i tworzy środowisko do pomyślnego przetwarzania. 
Co to jest „świadomość szafy”?
„Świadomość szafy” to algorytm, którego NameNode używa do określenia wzorca, w którym bloki danych i ich repliki są przechowywane w klastrze Hadoop. Osiąga się to za pomocą definicji szaf, które zmniejszają przeciążenie między węzłami danych znajdującymi się w tej samej szafie.

Co to są aktywne i pasywne węzły nazw?
System Hadoop o wysokiej dostępności zazwyczaj zawiera dwa NameNode – Active NameNode i Passive NameNode.
NameNode, na którym działa klaster Hadoop, nosi nazwę Active NameNode, a rezerwowy NameNode, który przechowuje dane Active NameNode, jest pasywnym NameNode.
Celem posiadania dwóch NameNode jest to, że jeśli aktywny NameNode ulegnie awarii, pasywny NameNode może przejąć prowadzenie. W ten sposób NameNode zawsze działa w klastrze, a system nigdy nie zawodzi.
Jakie są różne harmonogramy w ramach Hadoop?
W ramach Hadoop istnieją trzy różne harmonogramy:
- COSHH — COSHH pomaga planować decyzje poprzez przeglądanie klastra i obciążenia w połączeniu z heterogenicznością.
- FIFO Scheduler — FIFO ustawia zadania w kolejce na podstawie czasu ich przybycia, bez używania heterogeniczności.
- Sprawiedliwe udostępnianie — Sprawiedliwe udostępnianie tworzy pulę dla indywidualnych użytkowników zawierającą wiele map i zmniejsza liczbę miejsc w zasobie, których mogą używać do wykonywania określonych zadań.
Co to jest wykonanie spekulacyjne?
Często w ramach Hadoop niektóre węzły mogą działać wolniej niż pozostałe. To ogranicza cały program. Aby rozwiązać ten problem, Hadoop najpierw wykrywa lub „spekuluje”, kiedy zadanie działa wolniej niż zwykle, a następnie uruchamia równoważną kopię zapasową tego zadania. Tak więc w tym procesie węzeł główny wykonuje oba zadania jednocześnie i cokolwiek zostanie zakończone jako pierwsze, zostanie zaakceptowane, podczas gdy drugie zostanie zabite. Ta funkcja tworzenia kopii zapasowych Hadoop jest znana jako wykonywanie spekulacyjne.

Nazwij główne składniki Apache HBase?
Apache HBase składa się z trzech komponentów:
- Serwer regionu: po podzieleniu tabeli na wiele regionów klastry tych regionów są przekazywane klientom za pośrednictwem serwera regionu.
- HMaster: Jest to narzędzie, które pomaga zarządzać i koordynować serwer regionu.
- ZooKeeper: ZooKeeper jest koordynatorem w rozproszonym środowisku HBase. Pomaga utrzymać stan serwera wewnątrz klastra poprzez komunikację w sesjach.
Co to jest „punkt kontrolny”? Jaka jest jego korzyść?
Checkpointing odnosi się do procedury, w której FsImage i Edit log są łączone w celu utworzenia nowego FsImage. Dlatego zamiast odtwarzać dziennik edycji, NameNode może bezpośrednio załadować końcowy stan w pamięci z FsImage. Za ten proces odpowiada drugorzędny NameNode.
Zaletą, jaką oferuje Checkpointing, jest to, że minimalizuje czas uruchamiania NameNode, dzięki czemu cały proces jest bardziej wydajny.
Aplikacje Big Data w popkulturze
Jak debugować kod Hadoop?
Aby debugować kod Hadoop, najpierw musisz sprawdzić listę aktualnie uruchomionych zadań MapReduce. Następnie musisz sprawdzić, czy jakiekolwiek osierocone zadania są uruchomione jednocześnie. Jeśli tak, musisz znaleźć lokalizację dzienników Menedżera zasobów, wykonując następujące proste czynności:
Uruchom „ps –ef | grep –I ResourceManager” i w wyświetlonym wyniku spróbuj znaleźć, czy wystąpił błąd związany z określonym identyfikatorem zadania.
Teraz zidentyfikuj węzeł roboczy, który został użyty do wykonania zadania. Zaloguj się do węzła i uruchom „ps –ef | grep –iNodeManager.”
Na koniec przejrzyj dziennik Menedżera węzłów. Większość błędów jest generowanych z dzienników na poziomie użytkownika dla każdego zadania redukcji mapy.
Jaki jest cel RecordReader w Hadoop?
Hadoop dzieli dane na formaty blokowe. RecordReader pomaga zintegrować te bloki danych w jeden czytelny rekord. Na przykład, jeśli dane wejściowe są podzielone na dwa bloki –
Wiersz 1 – Witamy w
Wiersz 2 – Ulepszenie
RecordReader odczyta to jako „Witamy w UpG rad”.
W jakich trybach działa Hadoop?
Tryby, w których może działać Hadoop, to:
- Tryb autonomiczny — jest to domyślny tryb usługi Hadoop, który jest używany do celów debugowania. Nie obsługuje HDFS.
- Tryb pseudo-dystrybuowany — ten tryb wymagał konfiguracji plików mapred-site.xml, core-site.xml i hdfs-site.xml. Zarówno węzeł główny, jak i podrzędny są tutaj takie same.
- Tryb w pełni rozproszony — tryb w pełni rozproszony to etap produkcji usługi Hadoop, na którym dane są rozprowadzane w różnych węzłach klastra Hadoop. Tutaj węzły Master i Slave są przydzielane osobno.
Wymień kilka praktycznych zastosowań Hadoopa.
Oto kilka rzeczywistych przypadków, w których Hadoop robi różnicę:
- Zarządzanie ruchem ulicznym
- Wykrywanie i zapobieganie oszustwom
- Analizuj dane klientów w czasie rzeczywistym, aby poprawić obsługę klienta
- Dostęp do nieustrukturyzowanych danych medycznych od lekarzy, HCP itp. w celu poprawy usług opieki zdrowotnej.
Jakie są najważniejsze narzędzia Hadoop, które mogą zwiększyć wydajność Big Data?
Narzędzia Hadoop, które znacznie zwiększają wydajność Big Data, to

• Ula
• HDFS
• HBase
• SQL
• NoSQL
• Oozie
• Chmury
• Awró
• Koryto
• ZooKeeper
Inżynierowie Big Data: mity kontra rzeczywistość
Wniosek
Te pytania do rozmowy kwalifikacyjnej Hadoop powinny być bardzo pomocne podczas następnej rozmowy kwalifikacyjnej. Chociaż czasami ankieterzy mają tendencję do przekręcania niektórych pytań do rozmowy kwalifikacyjnej Hadoop, nie powinno to stanowić problemu, jeśli masz uporządkowane podstawy.
Jeśli chcesz dowiedzieć się więcej o Big Data, sprawdź nasz program PG Diploma in Software Development Specialization in Big Data, który jest przeznaczony dla pracujących profesjonalistów i zawiera ponad 7 studiów przypadków i projektów, obejmuje 14 języków programowania i narzędzi, praktyczne praktyczne warsztaty, ponad 400 godzin rygorystycznej pomocy w nauce i pośrednictwie pracy w najlepszych firmach.