
Myśli o przecenach
Opublikowany: 2022-03-10Markdown jest dla wielu z nas drugą naturą. Patrząc wstecz, pamiętam, że zacząłem pisać w Markdown niedługo po tym, jak John Gruber wydał swój pierwszy parser oparty na Perlu w 2004 roku, po współpracy nad językiem z Aaronem Swartzem.
Składnia Markdown jest przeznaczona do jednego celu: do wykorzystania jako format do pisania w Internecie.
— John Gruber
To prawie 20 lat temu — ojej! To, co zaczęło się jako bardziej przyjazna dla pisarza i czytelnika składnia HTML, stało się ulubionym sposobem pisania i przechowywania technicznej prozy dla programistów i ludzi obeznanych z technologią.
Markdown jest wyznacznikiem kultury programistów i majsterkowiczów. Ale od czasu jego wprowadzenia zmienił się również świat treści cyfrowych. Chociaż Markdown jest nadal w porządku w przypadku niektórych rzeczy, nie uważam, że powinien on być już celem dla treści.
Istnieją dwa główne powody takiego stanu rzeczy:
- Markdown nie został zaprojektowany, aby sprostać dzisiejszym potrzebom treści.
- Markdown ogranicza doświadczenie redakcyjne.
Oczywiście na to stanowisko wpływa praca na platformie dla treści ustrukturyzowanych. W Sanity.io spędzamy większość naszych dni myśląc o tym, jak treści jako dane odblokowują dużą wartość, i spędzamy dużo czasu głęboko zastanawiając się nad doświadczeniami edytorów oraz jak zaoszczędzić czas ludzi i sprawić, by praca z treściami cyfrowymi była zachwycająca . W grze jest więc skórka, ale mam nadzieję, że uda mi się pokazać, że mimo iż będę polemizować z Markdown jako podstawowym formatem treści, nadal głęboko doceniam jego znaczenie, zastosowanie i dziedzictwo.
Przed moim obecnym występem pracowałem jako konsultant ds. technologii w agencji, w której musieliśmy dosłownie walczyć z CMS-ami, które blokowały treści naszych klientów, osadzając je w prezentacjach i złożonych modelach danych (tak, nawet tych o otwartym kodzie źródłowym). Obserwowałem, jak ludzie zmagają się ze składnią Markdown i tracą motywację w pracy jako redaktorzy i twórcy treści. Spędziliśmy godziny (i pieniądze klienta) na tworzeniu niestandardowych rendererów tagów, które nigdy nie były używane, ponieważ ludzie nie mają czasu ani motywacji do używania składni. Nawet ja, gdy jestem bardzo zmotywowany, zrezygnowałem z przyczyniania się do tworzenia dokumentacji open source, ponieważ implementacja Markdown oparta na komponentach wprowadziła zbyt wiele problemów.
Ale widzę też drugą stronę medalu. Markdown ma imponujący ekosystem, a z punktu widzenia programisty, istnieje elegancka prostota plików tekstowych i łatwa do przeanalizowania składnia dla osób przyzwyczajonych do czytania kodu. Kiedyś spędziłem kilka dni na tworzeniu imponującego MultiMarkdown -> LaTeX -> real-time-PDF-preview-pipeline w Sublime Text do mojego pisania akademickiego. I ma sens, że plik README.md można otworzyć i edytować w edytorze kodu i ładnie renderować na GitHub. Nie ma wątpliwości, że Markdown zapewnia wygodę programistom w niektórych przypadkach użycia.
Dlatego też chcę stworzyć swoją radę przeciwko Markdownowi, patrząc wstecz na to, dlaczego został wprowadzony w pierwszej kolejności, i przeglądając niektóre z głównych zmian w treści w Internecie. Dla wielu z nas podejrzewam, że Markdown jest czymś, co przyjmujemy za pewnik jako „rzecz, która istnieje”. Ale cała technologia ma swoją historię i jest produktem interakcji międzyludzkich. Należy o tym pamiętać, gdy Ty, Czytelniku, opracowujesz technologię, z której mogą korzystać inni.
Smaki i specyfikacje
Markdown został zaprojektowany, aby ułatwić autorom stron internetowych pracę z artykułami w czasach, gdy publikowanie w sieci wymagało pisania HTML. Tak więc celem było uproszczenie interfejsu z formatowaniem tekstu w HTML. Nie była to pierwsza uproszczona składnia na świecie, ale przez lata zyskała największą popularność. Obecnie korzystanie z Markdown wykroczyło daleko poza jego intencję projektową, aby stać się prostszym sposobem czytania i pisania HTML, stając się podejściem do oznaczania zwykłego tekstu w wielu różnych kontekstach. Jasne, technologie i pomysły mogą ewoluować poza ich intencje, ale napięcie w dzisiejszym korzystaniu z Markdown można przypisać temu pochodzeniu i ograniczeniom nałożonym na jego projekt.
Dla tych, którzy nie znają składni, weź poniższą treść HTML:
<p>The <a href=”https://daringfireball.net/projects/markdown/syntax#philosophy”>Markdown syntax</a> is designed to be <em>easy-to-read</em> and <em>easy-to.write</em>.</p>Dzięki Markdown możesz wyrazić to samo formatowanie, co:
The [Markdown syntax](https://daringfireball.net/projects/markdown/syntax#philosophy) is designed to be _easy-to-read_ and _easy-to-write_.To jak prawo natury, że przyjęcie technologii wiąże się z presją rozwoju i dodawania do niej funkcji. Rosnąca popularność Markdown oznaczała, że ludzie chcieli dostosować go do swoich przypadków użycia. Chcieli więcej funkcji, takich jak obsługa przypisów i tabel. Pierwotna implementacja miała zdecydowane stanowisko, które w tamtym czasie było uzasadnione ze względu na intencje projektowe:
W przypadku każdego znacznika, który nie jest objęty składnią Markdown, wystarczy użyć samego kodu HTML. Nie trzeba go poprzedzać ani ograniczać, aby wskazać, że przechodzisz z Markdown na HTML; po prostu używasz tagów.
— John Gruber
Innymi słowy, jeśli chcesz mieć tabelę, użyj <table></table> . Przekonasz się, że nadal tak jest w przypadku oryginalnej implementacji. Jeden z duchowych następców Markdowna, MDX, przyjął tę samą zasadę, ale rozszerzył ją na JSX, język szablonów oparty na JS.
Od przecen do przecen?
Może wyglądać na to, że atrakcyjność Markdowna dla wielu nie była tak bardzo związana z HTML, ale ergonomią zwykłego tekstu i prostą składnią do formatowania. Niektórzy twórcy treści chcieli używać Markdown do innych zastosowań niż zwykłe artykuły w sieci. Implementacje takie jak MultiMarkdown wprowadziły afordancje dla pisarzy akademickich, którzy chcieli używać zwykłych plików tekstowych, ale potrzebowali więcej funkcji. Wkrótce będziesz miał wiele aplikacji do pisania, które akceptują składnię Markdown, bez konieczności przekształcania jej w HTML lub nawet używania składni Markdown jako formatu przechowywania.
W wielu aplikacjach znajdziesz edytory, które oferują ograniczony zestaw opcji formatowania, a niektóre z nich są bardziej „inspirowane” oryginalną składnią. W rzeczywistości jedną z opinii, które otrzymałem na temat wersji roboczej tego artykułu, było to, że do tej pory „Markdown” powinien być pisany małymi literami, ponieważ stał się tak powszechny, i aby odróżnić go od oryginalnej implementacji. Ponieważ to, co uznajemy za przecenę, również stało się bardzo zróżnicowane.
CommonMark: próba oswojenia przecen
Podobnie jak lody, Markdown występuje w wielu smakach, niektóre bardziej popularne niż inne. Kiedy ludzie zaczęli forkować oryginalną implementację i dodawać do niej funkcje, wydarzyły się dwie rzeczy:
- Stało się bardziej nieprzewidywalne, co ty jako pisarz możesz, a czego nie możesz zrobić z Markdown.
- Twórcy oprogramowania musieli podejmować decyzje o tym, jaką implementację zastosować w swoim oprogramowaniu. Oryginalna implementacja zawierała również pewne niespójności, które zwiększały trudności dla osób, które chciały z niej korzystać programowo.
Rozpoczęło to rozmowy na temat sformalizowania Markdown do właściwej specyfikacji. Coś, czemu Gruber się oparł i nadal robi, co ciekawe, ponieważ zauważył, że ludzie chcą używać Markdown do różnych celów i „Żadna składnia nie uszczęśliwi wszystkich”. To interesująca postawa, biorąc pod uwagę, że Markdown przekłada się na HTML, który jest specyfikacją, która ewoluuje w celu dostosowania do różnych potrzeb.
Mimo że oryginalna implementacja Markdown jest objęta licencją „podobną do BSD”, brzmi ona również: „Ani nazwa Markdown, ani nazwiska jej współpracowników nie mogą być używane do promowania lub promowania produktów opartych na tym oprogramowaniu bez uprzedniej pisemnej zgody. ” Możemy śmiało założyć, że większość produktów wykorzystujących „Markdown” jako część materiałów marketingowych nie uzyskała tej pisemnej zgody.
Najbardziej udaną próbą wprowadzenia Markdowna do wspólnej specyfikacji jest to, co jest dziś znane jako CommonMark. Kierowali nim Jeff Atwood (znany ze współzałożyciela Stack Overflow i Dyskursu) i Johna McFarlane'a (profesora filozofii w Berkely, który stoi za Babelmark i pandoc). Początkowo uruchomili go jako „Standard Markdown”, ale zmienili go na „CommonMark” po otrzymaniu krytyki od Grubera. Jego stanowisko było spójne, intencją Markdown jest bycie prostą składnią autorską, która przekłada się na HTML:
@davewiner I to właśnie jest wadą CommonMark. Chcą ułatwić pracę programistom jako główny cel. Tracą sens.
— John Gruber (@gruber) 8 września 2014 r.
Myślę, że to również oznaczało punkt, w którym Markdown wszedł do domeny publicznej. Mimo że CommonMark nie jest oznaczony jako „Markdown” (zgodnie z licencją), ta specyfikacja jest rozpoznawana i określana jako „markdown”. Dzisiaj znajdziesz CommonMark jako podstawową implementację oprogramowania takiego jak Discourse, GitHub, GitLab, Reddit, Qt, Stack Overflow i Swift. Projekty takie jak unified.js składnie, tłumacząc je na abstrakcyjne drzewa składni, również opierają się na CommonMark w zakresie obsługi przecen.
CommonMark przyniósł wiele ujednolicenia sposobu implementacji przecen i na wiele sposobów ułatwił programistom zintegrowanie obsługi przecen w oprogramowaniu. Ale to nie doprowadziło do tego samego ujednolicenia sposobu pisania i używania przecen. Weź GitHub Flavored Markdown (GFM). Jest oparty na CommonMark, ale rozszerza go o więcej funkcji (takich jak tabele, listy zadań i przekreślenia). Reddit opisuje swoją „Reddit Flavored Markdown” jako „odmianę GFM” i wprowadza funkcje, takie jak składnia do oznaczania spoilerów. Myślę, że możemy śmiało stwierdzić, że zarówno grupa stojąca za CommonMarkiem, jak i Gruberem miała rację: to z pewnością pomaga przy wspólnych specyfikacjach, ale tak, ludzie chcą używać Markdowna do różnych konkretnych rzeczy.
Markdown jako skrót do formatowania
Gruber sprzeciwiał się formalizacji Markdowna we wspólnej specyfikacji, ponieważ zakładał, że uczyni to mniej narzędziem dla pisarzy, a bardziej narzędziem dla programistów. Widzieliśmy już, że nawet przy szerokim przyjęciu specyfikacji nie otrzymujemy automatycznie składni, która w przewidywalny sposób działa tak samo w różnych kontekstach. Specyfikacje takie jak CommonMark, choć popularne, również mają ograniczony sukces. Oczywistym przykładem jest implementacja markdown w Slacku (zwana mrkdown ), która tłumaczy *this* na mocne/pogrubione, a nie podkreślenie/kursywa, i nie obsługuje składni [link](https://slack.com) , ale używa <link|https://slack.com> zamiast tego.
Przekonasz się również, że możesz użyć składni podobnej do języka Markdown, aby zainicjować formatowanie w edytorach tekstu sformatowanego w oprogramowaniu takim jak Notion, Dropbox Paper, Craft i do pewnego stopnia Dokumenty Google (np. asterisk + space w nowym wierszu zostaną przekształcone w lista punktowana). Co jest obsługiwane i co jest tłumaczone na różne. Tak więc niekoniecznie możesz zabrać ze sobą pamięć mięśniową w tych aplikacjach. Dla niektórych osób jest to w porządku i mogą się dostosować. Dla innych jest to wycięta z papieru i uniemożliwia im korzystanie z tych funkcji. Co zadaje pytanie, dla kogo został zaprojektowany Markdown i kim są dzisiaj jego użytkownicy?
Kim mają być użytkownicy przecen?
Widzieliśmy, że przecena istnieje w napięciu między różnymi przypadkami użycia, odbiorcami i wyobrażeniami o tym, kim są jego użytkownicy. To, co zaczęło się jako język znaczników dla twórców stron internetowych biegłych w HTML, stało się ulubieńcem typów programistów.
W 2014 roku twórcy stron internetowych zaczęli odchodzić od przenoszenia plików przez parsery w Perlu i FTP. Systemy zarządzania treścią (CMS), takie jak WordPress, Drupal i Moveable Type (których, jak sądzę, Gruber nadal używa), stale rosły, aby stać się popularnymi narzędziami do publikowania w Internecie. Oferowali afordancje, takie jak edytory tekstu sformatowanego, których twórcy stron internetowych mogliby używać w swoich przeglądarkach.
Te edytory tekstu sformatowanego nadal zakładały HTML i Markdown jako podstawową składnię tekstu sformatowanego, ale usunęły część narzutu poznawczego, dodając przyciski w celu wstawienia tej składni do edytora. Coraz częściej pisarze nie byli i nie musieli być biegli w HTML. Założę się, że jeśli tworzyłeś strony internetowe z CMS-ami w 2010 roku, prawdopodobnie miałeś do czynienia z „śmieciowym kodem HTML”, który przechodził przez te edytory, gdy ludzie wklejali bezpośrednio z Worda.
Dzisiaj będę argumentować, że głównymi użytkownikami Markdown są programiści i osoby zainteresowane kodem. To nie przypadek, że Slack uczynił WYSIWYG domyślnym trybem wejściowym, gdy ich oprogramowanie było używane przez więcej osób spoza działów technicznych. A fakt, że była to tak kontrowersyjna decyzja, że musieli ją przywrócić jako opcję, pokazuje, jak głębokie jest zamiłowanie do przecen w społeczności programistów. Nie było zbyt wiele celebracji Slacka, który starał się uczynić go łatwiejszym i bardziej dostępnym dla wszystkich. I to jest sedno sprawy.
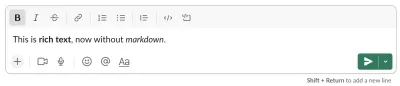
Ideologia przecen
Fakt, że przecena stała się stylem pisania lingua franca, i to, na co odpowiada większość frameworków stron internetowych, jest również głównym powodem, dla którego byłem trochę niespokojny, jeśli chodzi o publikację tego. Często mówi się o tym jako o nieodłącznym i niezaprzeczalnym dobru. Markdown stał się znakiem rozpoznawczym bycia przyjaznym dla programistów. Inteligentni i wykwalifikowani ludzie poświęcili wiele wspólnych godzin na umożliwienie przecen w różnych sytuacjach. Tak więc kwestionowanie jego hegemonii z pewnością niektórych zirytuje. Ale miejmy nadzieję, że może wywołać owocną dyskusję na temat rzeczy, które często są uważane za oczywiste.
Mam wrażenie, że przyjazność dla programistów, z którą ludzie odnoszą się do Markdown, ma głównie związek z 3 czynnikami:
- Wygodna abstrakcja zwykłego pliku tekstowego.
- Istnieje ekosystem narzędzi.
- Możesz trzymać swoje treści blisko przepływu pracy programistycznej.
Nie mówię, że te postawy są błędne, ale zasugeruję, że wiążą się z kompromisami i pewnymi nierozsądnymi założeniami.
Prosty model mentalny zwykłego pliku tekstowego
Bazy danych to niesamowite rzeczy. Ale mają również zasłużoną reputację twardych i niedostępnych dla programistów frontendowych. Znam wielu świetnych programistów, którzy unikają kodu backendowego i baz danych, ponieważ reprezentują złożoność, na którą nie chcą spędzać czasu. Nawet w przypadku WordPressa, który robi wiele rzeczy po wyjęciu z pudełka, abyś nie musiał radzić sobie z bazą danych po konfiguracji, jego uruchomienie było zbyt skomplikowane.
Zwykłe pliki tekstowe są jednak bardziej namacalne i dość łatwe do zrozumienia (o ile jesteś przyzwyczajony do zarządzania plikami). Zwłaszcza w porównaniu z systemem, który dzieli zawartość na wiele tabel w relacyjnej bazie danych z pewną zastrzeżoną strukturą. W przypadku ograniczonych zastosowań, takich jak posty na blogu zawierające prosty tekst sformatowany z obrazami i linkami, przecena wykona zadanie. Możesz skopiować plik i umieścić go w folderze lub zaewidencjonować w git. Treść wydaje się twoja ze względu na namacalność plików. Nawet jeśli są hostowane w serwisie GitHub, który jest oprogramowaniem komercyjnym jako usługa należącym do firmy Microsoft, a zatem objętym warunkami korzystania z usługi.
W erze, w której trzeba było uruchomić lokalną bazę danych, aby uruchomić lokalny rozwój i poradzić sobie z synchronizacją ze zdalną, atrakcyjność plików tekstowych jest zrozumiała. Ale ta era już minęła wraz z pojawieniem się backendów jako usługi. Usługi i narzędzia, takie jak Fauna, Firestore, Hasura, Prisma, PlanetScale i Sanity's Content Lake, mocno inwestują w doświadczenie programistów. Nawet obsługa tradycyjnych baz danych dotyczących rozwoju lokalnego stała się mniej kłopotliwa w porównaniu do zaledwie 10 lat temu.
Jeśli się nad tym zastanowisz, czy jesteś mniej właścicielem swoich treści, jeśli są one przechowywane w bazie danych? A czy doświadczenie programistów w radzeniu sobie z bazami danych nie stało się znacznie prostsze wraz z pojawieniem się narzędzi SaaS? I czy można uczciwie powiedzieć, że zastrzeżona technologia baz danych wpływa na przenośność Twoich treści? Dzisiaj możesz uruchomić coś, co w zasadzie jest bazą danych Postgres bez umiejętności administratora, tworzyć tabele i kolumny, umieszczać w nich zawartość i w dowolnym momencie eksportować je jako zrzut .sql .
Możliwość przenoszenia treści ma znacznie więcej wspólnego ze sposobem, w jaki ustrukturyzujesz tę treść. Weź WordPress, jest w pełni open-source, możesz hostować własną bazę danych. Ma nawet ustandaryzowany format eksportu w XML. Ale każdy, kto próbował wyjść z dojrzałej instalacji WordPressa, wie, jak niewiele to pomaga, jeśli próbujesz uciec od WordPressa.
Ogromny ekosystem… dla programistów
Dotknęliśmy już rozległego ekosystemu przecen. Jeśli spojrzysz na współczesne frameworki stron internetowych, większość z nich przyjmuje przeceny jako podstawowy format treści, a niektóre z nich jako jedyny format. Na przykład Hugo, statyczny generator witryn używany przez Smashing Magazine, nadal wymaga plików przecen do publikacji z podziałem na strony. Oznacza to, że jeśli Smashing Magazine chce używać CMS do przechowywania artykułów, musi wchodzić w interakcje z plikami przecen lub konwertować całą zawartość do plików przecen. Jeśli zajrzysz do dokumentacji dla Next.js, Nuxt.js, VuePress, Gatsby.js i tak dalej, przecena będzie widoczna. Jest to również domyślna składnia plików README w serwisie GitHub, która używa jej również do formatowania notatek i komentarzy w pull requestach.
Istnieje kilka honorowych wzmianek o inicjatywach mających na celu przybliżenie masom ergonomii przecen. Netlify CMS i TinaCMS (duchowy potomek leśnictwa) zapewnią interfejsy użytkownika, w których składnia przecen jest w większości abstrakcyjna dla redaktorów. Często okazuje się, że edytory oparte na przecenach w systemach CMS zapewniają funkcjonalność podglądu formatowania. Niektóre edytory, takie jak Notion, pozwalają wkleić składnię przecen i przetłumaczą ją na ich natywne formatowanie. Ale myślę, że można śmiało powiedzieć, że energia, która została skierowana na innowacje w zakresie przecen, nie faworyzuje ludzi, którzy nie piszą jego składni. Jakby nie było.
Przepływy pracy dotyczące treści czy przepływy pracy dla programistów?
W przypadku programisty, który tworzy swojego bloga, korzystanie z plików przecenowych zmniejsza część kosztów związanych z jego uruchomieniem, ponieważ frameworki często zawierają wbudowane analizowanie lub często oferują je jako część kodu startowego. I nie ma nic do zapisania się. Możesz użyć git, aby zatwierdzić te pliki wraz z kodem. Jeśli znasz się na git diffs, będziesz miał nawet kontrolę nad wersjami, tak jak przywykłeś do programowania. Innymi słowy, ponieważ pliki przecen są w postaci zwykłego tekstu, można je zintegrować z przepływem pracy programisty.
Ale poza tym doświadczenie programisty wkrótce staje się bardziej złożone. I kończysz na kompromisie w zakresie doświadczenia użytkownika swojego zespołu jako twórców treści, a nasze własne doświadczenie programisty utknie w przecenach, aby rozwiązać problemy, które wykraczają poza zamierzenia projektowe.

Tak, może być fajnie, jeśli Twój zespół ds. treści użyje git i wprowadzi zmiany, ale jednocześnie czy jest to najlepsze wykorzystanie jego czasu? Czy naprawdę chcesz, aby twoi redaktorzy wpadali na konflikty scalania lub jak zmienić bazę gałęzi? Git jest wystarczająco trudny dla programistów, którzy używają go na co dzień. I czy ta konfiguracja naprawdę reprezentuje najlepszy przepływ pracy dla osób, które pracują głównie z treścią? Czy nie jest to przypadek, w którym doświadczenie programisty przebiło doświadczenie edytora i czy to nie koszt, czas i wysiłek, które można by poświęcić na stworzenie czegoś lepszego dla użytkowników?
Ponieważ oczekiwania i potrzeby dotyczące treści i środowisk edycji ewoluowały, nie sądzę, aby przecena zrobiła to za nas. Nie rozumiem, w jaki sposób część ergonomii programistów faworyzuje osoby niebędące programistami i myślę, że nawet dla programistów przecena wstrzymuje nasze własne tworzenie treści i potrzeby. Ponieważ treści w sieci znacznie się zmieniły od początku 2000 roku.
Od akapitów do bloków
Markdown zawsze miał możliwość rezygnacji z HTML, jeśli chciałeś bardziej skomplikowanych rzeczy. Działało to dobrze, gdy autor był jednocześnie webmasterem, a przynajmniej znał HTML. Działało to również dobrze, ponieważ strony internetowe zwykle były w większości HTML i CSS. Sposób, w jaki projektowałeś strony internetowe, polegał głównie na tworzeniu układów całych stron. Możesz przekształcić Markdown w znacznik HTML i umieścić go obok pliku style.css . Oczywiście w latach 2000. mieliśmy też systemy CMS i statyczne generatory witryn, ale w większości działały one tak samo, wstawiając zawartość HTML do szablonów bez przechodzenia „rekwizytów” między komponentami.
Ale większość z nas nie tworzy już tak naprawdę HTML, jak za dawnych czasów. Treści w sieci ewoluowały od artykułów z prostym formatowaniem tekstu do skomponowanych multimediów i wyspecjalizowanych komponentów, często z interaktywnością użytkownika (co jest fantazyjnym sposobem powiedzenia „wezwanie do rejestracji w biuletynie”).
Od artykułów do aplikacji
Na początku lat 2010, Web 2.0 przeżywał swój rozkwit, a firmy tworzące oprogramowanie jako usługa zaczęły używać Internetu w aplikacjach z dużą ilością danych. HTML, CSS i JavaScript były coraz częściej wykorzystywane do obsługi interaktywnych interfejsów użytkownika. Twitter Bootstrap o otwartym kodzie źródłowym, ich framework do budowania bardziej spójnych i odpornych interfejsów użytkownika. To napędzało coś, co możemy nazwać „komponentizacją” projektowania stron internetowych. W zasadniczy sposób zmieniło sposób, w jaki budujemy dla sieci.
Różne frameworki CSS, które pojawiły się w tej erze (np. Bootstrap i Foundation) zwykle używały standardowych nazw klas i zakładały specyficzne struktury HTML, aby ułatwić tworzenie elastycznych i responsywnych interfejsów użytkownika. Dzięki filozofii projektowania stron internetowych opartej na projektowaniu atomowym i konwencjom nazw klas, takim jak modyfikator elementów blokowych (BEM), domyślnie przesunięto z myślenia o układzie strony na rzecz postrzegania stron jako zbioru powtarzalnych i zgodnych elementów projektu.
Wszelkie treści, które masz w przecenach, nie są z tym zgodne. Chyba że wpadniesz w króliczą dziurę wtrącania parserów przecen i poprawiłeś je, aby uzyskać żądaną składnię (więcej o tym później). Nic dziwnego, że Markdown został zaprojektowany jako proste artykuły z bogatym tekstem zawierające natywne elementy HTML, na które można kierować za pomocą arkusza stylów.
Nadal jest to problem dla osób, które używają Markdown do zwiększania zawartości swoich witryn.
Wbudowana sieć
Ale coś się stało również z naszymi treściami. Nie tylko mogliśmy zacząć go znajdować poza semantycznymi tagami HTML <article> , ale zaczął zawierać więcej… rzeczy. Wiele naszych treści przeniosło się z naszych LiveJournals i blogów do mediów społecznościowych: Facebook, Twitter, tumblr, YouTube. Aby umieścić fragmenty treści z powrotem w naszych artykułach, musieliśmy mieć możliwość ich osadzenia. Konwencja HTML zaczęła używać tagu <iframe> do przekierowywania odtwarzacza wideo z YouTube, a nawet wstawiania pola tweet między akapitami tekstu. Niektóre systemy zaczęły abstrahować to do „krótkich kodów”, najczęściej nawiasów zawierających jakieś słowo kluczowe w celu zidentyfikowania, jaki blok treści powinien reprezentować, oraz kilka atrybutów klucz-wartość. Na przykład, dev.to umożliwiło wstawienie składni z cieczy języka szablonów do swojego edytora Markdown:
{% youtube dQw4w9WgXcQ %}Oczywiście wymaga to użycia dostosowanego parsera Markdown i specjalnej logiki, aby upewnić się, że poprawny kod HTML został wstawiony, gdy składnia została zmieniona na HTML. A twoi twórcy treści będą musieli zapamiętać te kody (chyba że istnieje jakiś pasek narzędzi do automatycznego ich wstawiania). A jeśli nawias zostanie usunięty lub zepsuty, może to spowodować uszkodzenie witryny.
Ale co z MDX?
Próbą rozwiązania zapotrzebowania na zawartość blokową jest MDX, prezentowany pod hasłem „Markdown dla ery komponentów”. MDX umożliwia korzystanie z języka szablonów JSX, a także JavaScript, przeplatanych w składni markdown. W społeczności wokół MDX istnieje wiele imponujących rozwiązań inżynieryjnych, w tym Unified.js , który specjalizuje się w analizowaniu różnych składni w abstrakcyjne drzewa składni (AST), dzięki czemu są one bardziej dostępne do użycia programistycznego. Zwróć uwagę, że standaryzacja przecen ułatwiłaby pracę osobom stojącym za Unified.js i jego użytkownikom, ponieważ istnieje mniej przypadków brzegowych, którymi można się zająć.
MDX z pewnością zapewnia lepsze wrażenia programistów w integrowaniu komponentów w Markdown. Ale nie zapewnia to lepszych wrażeń z pracy edytora, ponieważ wnosi dużo narzutu poznawczego do produkcji i edycji treści:
import {Chart} from './snowfall.js' export const year = 2018 # Last year's snowfall In {year}, the snowfall was above average. It was followed by a warm spring which caused flood conditions in many of the nearby rivers. <Chart year={year} color="#fcb32c" />Ilość zakładanej wiedzy tylko dla tego prostego przykładu jest znaczna. Musisz wiedzieć o modułach ES6, zmiennych JavaScript, składni szablonów JSX oraz o tym, jak używać props, kodów szesnastkowych i typów danych, a także musisz wiedzieć, jakich komponentów możesz używać i jak ich używać. Musisz wpisać to poprawnie i w środowisku, które daje jakąś informację zwrotną. Nie mam wątpliwości, że oprócz MDX pojawią się bardziej dostępne narzędzia do tworzenia, wydaje się, że rozwiązywanie czegoś, co nie musi być problemem.
Jeśli nie jesteś wyjątkowo sumienny w komponowaniu i nazywaniu komponentów MDX, wiąże to również treść z konkretną prezentacją. Wystarczy wziąć powyższy przykład ze strony głównej MDX. Na wykresie znajdziesz zakodowany szesnastkowy kolor. Po przeprojektowaniu witryny ten kolor może nie być zgodny z nowym systemem projektowania. Oczywiście nic nie stoi na przeszkodzie, abyś wyabstrahował to i skorzystał z rekwizytu color=”primary” , ale nie ma też nic w narzędziu, które skłania cię do podejmowania takich mądrych decyzji.
Umieszczanie konkretnych problemów związanych z prezentacją w treści coraz częściej staje się obowiązkiem i czymś, co stanie na przeszkodzie w dostosowywaniu, iteracji i szybkim poruszaniu się z treścią. Blokuje go w sposób znacznie bardziej subtelny niż posiadanie zawartości w bazie danych. Ryzykujesz, że skończysz w tym samym miejscu, co wyprowadzenie się z dojrzałej instalacji WordPressa z wtyczkami. Rozłączenie struktury i prezentacji jest kłopotliwe.
Popyt na treści strukturalne
W przypadku bardziej złożonych witryn i podróży użytkowników widzimy również potrzebę prezentowania tych samych elementów treści w całej witrynie. Jeśli prowadzisz witrynę e-commerce, chcesz umieścić informacje o produkcie w wielu miejscach poza jedną stroną produktu. Jeśli prowadzisz nowoczesną witrynę marketingową, chcesz mieć możliwość udostępniania tej samej kopii w wielu spersonalizowanych widokach.
Aby zrobić to skutecznie i niezawodnie, musisz dostosować ustrukturyzowaną treść. Oznacza to, że Twoje treści muszą być osadzone z metadanymi i podzielone w sposób, który umożliwi analizę pod kątem intencji. Jeśli programista widzi po prostu „stronę” z „treścią”, bardzo trudno jest umieścić właściwe rzeczy we właściwych miejscach. Jeśli mogą dostać się do wszystkich „opisów produktów” za pomocą API lub zapytania, to wszystko jest łatwiejsze.
Dzięki przecenie jesteś ograniczony do wyrażania taksonomii i ustrukturyzowanej treści albo do jakiejś organizacji folderów (co utrudnia umieszczenie tego samego fragmentu treści w wielu taksonomach) lub musisz rozszerzyć składnię o coś innego.
Jekyll, wczesny Static Site Generator (SSG) zbudowany dla plików przecen, wprowadził „Front Matter” jako sposób na dodawanie metadanych do postów za pomocą YAML (prosty format klucz-wartość, który wykorzystuje spacje do tworzenia zakresu) między trzema myślnikami u góry pliku. Tak więc teraz będziesz miał do czynienia z dwiema składniami. YAML ma również reputację złośliwego (zwłaszcza jeśli jesteś z Norwegii). Niemniej jednak inne SSG przyjęły tę konwencję, podobnie jak CMS oparte na git, które używają przecen jako formatu treści.
Kiedy musisz dodać dodatkową składnię do swoich zwykłych plików, aby uzyskać pewne afordancje ustrukturyzowanej zawartości, możesz zacząć się zastanawiać, czy naprawdę warto. I dla kogo ten format jest i kogo wyklucza.
Jeśli o tym pomyślisz, wiele z tego, co robimy w sieci, to nie tylko konsumowanie treści, my je tworzymy! Obecnie piszę ten długi artykuł w zaawansowanym edytorze tekstu w mojej przeglądarce.
Istnieje coraz większe oczekiwanie, że powinieneś być w stanie tworzyć treści blokowe w nowoczesnych aplikacjach treści. Ludzie zaczęli przyzwyczajać się do wspaniałych doświadczeń użytkownika, które działają i ładnie wyglądają, i gdzie nie trzeba uczyć się specjalistycznej składni. Medium spopularyzowało pogląd, że można tworzyć zachwycające i intuicyjne treści w sieci. Mówiąc o „pojęciu”, popularna aplikacja do notatek zajęła się treścią blokową i pozwala użytkownikom mieszać maksimum z szerokiej gamy różnych typów. Większość z tych bloków wykracza poza przecenę i natywne elementy HTML.
Warto zauważyć, że Notion, opisując proces udostępniania treści za pośrednictwem wyczekiwanego interfejsu API, zwraca uwagę na wybór formatu treści, który:
Dokumenty z jednego edytora Markdown często są analizowane i renderowane inaczej w innej aplikacji. Niespójność wydaje się być łatwa do opanowania w przypadku prostych dokumentów, ale jest to duży problem dla bogatej biblioteki bloków i opcji formatowania wbudowanego Notion, z których wiele po prostu nie jest obsługiwanych w żadnej powszechnie używanej implementacji Markdown.
Notion poszedł z formatem opartym na JSON, który pozwolił im wyrazić jako dane strukturalne. Ich argumentem jest to, że ułatwia to i bardziej przewidywalną interakcję z programistami, którzy chcą zbudować własną prezentację zawartości bloku, która pochodzi z API Notion.
Jeśli nie przecena, to co?
Podejrzewam, że znaczenie Markdown hamuje innowacyjność i postęp w zakresie treści cyfrowych. Tak więc, kiedy twierdzę, że powinniśmy przestać wybierać to jako podstawowy sposób przechowywania treści, trudno jest udzielić prostej odpowiedzi na to, co powinno ją zastąpić. Wiemy jednak, czego powinniśmy oczekiwać od nowoczesnych formatów treści i narzędzi autorskich.
Zainwestujmy w dostępne doświadczenia autorskie
Korzystanie z przecen wymaga nauczenia się składni, a często wielu składni i niestandardowych tagów, aby być praktycznym przy współczesnych oczekiwaniach. Dziś wydaje się to zupełnie niepotrzebnym oczekiwaniem na większość ludzi. Chciałabym, abyśmy mogli skierować więcej energii na tworzenie przystępnych i zachwycających doświadczeń redakcyjnych, które tworzą nowoczesne przenośne formaty treści.
Mimo że tworzenie świetnych edytorów treści blokowych jest bardzo trudne, istnieje kilka realnych opcji, które można rozszerzyć i dostosować do konkretnego przypadku użycia (na przykład Slate.js, Quill.js lub Prosemiror). Z drugiej strony inwestowanie w społeczności wokół tych narzędzi może również pomóc w ich dalszym rozwoju.
Coraz częściej ludzie będą oczekiwać, że narzędzia do tworzenia będą dostępne, działające w czasie rzeczywistym i oparte na współpracy. Dlaczego w 2021 r. trzeba wciskać przycisk zapisu w sieci? Dlaczego nie miałoby być możliwe dokonanie zmiany w dokumencie bez narażania się na wyścig, skoro zdarzyło się, że kolega miał dokument otwarty w zakładce? Czy powinniśmy oczekiwać, że autorzy będą musieli radzić sobie z konfliktami scalającymi? I czy nie powinniśmy ułatwiać twórcom treści pracy z ustrukturyzowanymi treściami z wizualnymi afordancjami, które mają sens?
By być nieco polemicznym: innowacje ostatniej dekady w reaktywnych frameworkach JavaScript i komponentach interfejsu użytkownika są idealne do tworzenia niesamowitych narzędzi do tworzenia. Zamiast używać ich do transpilacji języka Markdown do HTML i do abstrakcyjnego drzewa składni, aby następnie zintegrować go z językiem szablonów JavaScript, który generuje HTML.
Zawartość bloku powinna być zgodna ze specyfikacją
Nie wspomniałem o edytorach WYSIWYG dla HTML. Ponieważ są niewłaściwą rzeczą. Nowoczesne edytory treści blokowych powinny najlepiej współpracować z określonym formatem. Wspomniani redaktorzy mają przynajmniej rozsądny wewnętrzny model dokumentu, który można przekształcić w coś bardziej przenośnego. If you look at the content management system landscape, you start to see various JSON-based block content formats emerge. Some of them are still tied to HTML assumptions or overly concerned with character positions. And none of them aren't really offered as a generic specification.
At Sanity.io, we decided early that the block content format should never assume HTML as neither input nor output, and that we could use algorithms to synchronize text strings. More importantly, was it that block content and rich text should be deeply typed and queryable. The result was the open specification Portable Text. Its structure not only makes it flexible enough to accommodate custom data structures as blocks and inline spans; it's also fully queryable with open-source query languages like GROQ.
Portable Text isn't design to be written or be easily readable in its raw form; it's designed to be produced by an user interface, manipulated by code, and to be serialized and rendered where ever it needs to go. For example, you can use it to express content for voice assistants.
{ "style": "normal", "_type": "block", "children": [ { "_type": "span", "marks": ["a-key", "emphasis"], "text": "some text" } ], "markDefs": [ { "_key": "a-key", "_type": "markType", "extraData": "some data" } ] }An interesting side-effect of turning block content into structured data is exactly that: It becomes data! And data can be queried and processed. That can be highly useful and practical, and it lets you ask your content repository questions that would be otherwise harder and more errorprone in formats like Markdown.
For example, if I for some reason wanted to know what programming languages we've covered in examples on Sanity's blog, that's within reach with a short query. You can imagine how trivial it is to build specialized tools and views on top of this that can be helpful for content editors:
distinct( *["code" in body[]._type] .body[_type == "code"] .language ) // output [ "text", "javascript", "json", "html", "markdown", "sh", "groq", "jsx", "bash", "css", "typescript", "tsx", "scss" ]Example: Get a distinct list of all programming languages that you have code blocks of.
Portable Text is also serializable, meaning that you can recursively loop through it, and make an API that exposes its nodes in callback functions mapped to block types, marked-up spans, and so on. We have spent the last years learning a lot about how it works and how it can be improved, and plan to take it to 1.0 in the near future. The next step is to offer an editor experience outside of Sanity Studio. As we have learned from Markdown, the design intent is important.
Of course, whatever the alternative to markdown is, it doesn't need to be Portable Text, but it needs to be portable text. And it needs to share a lot of its characteristics. There have been a couple of other JSON-based block content format popping up the last few years, but a lot of them seem to bring with them a lot of “HTMLism.” The convenience is understandable, since a lot of content still ends up on the web serialized into HTML, but the convenience limits the portability and the potential for reuse.
You can disregard my short pitch for something we made at Sanity, as long as you embrace the idea of structured content and formats that let you move between systems in a fundamental manner. For example, a goal for Portable Text will be improved compatibility with Unified.js, so it's easier to travel between formats.
Embracing The Legacy Of Markdown
Markdown we wszystkich jego smakach, interpretacjach i widelcach nie zniknie. I suspect that plain text files will always have a place in developers' note apps, blogs, docs, and digital gardens. As a writer who has used markdown for almost two decades, I've become accustomed to “markdown shortcuts” that are available in many rich text editors and am frequently stumped from Google Docs' lack of markdownisms. But I'm not sure if the next generation of content creators and even developers will be as bought in on markdown, and nor should they have to be.
I also think that markdown captured a culture of savvy tinkerers who love text, markup, and automation. I'd love to see that creative energy expand and move into collectively figuring out how we can make better and more accessible block content editors, and building out an ecosystem around specifications that can express block content that's agnostic to HTML. Structured data formats for block content might not have the same plain text ergonomics, but they are highly “tinkerable” and open for a lot of creativity of expression and authoring.
If you are a developer, product owner, or a decision-maker, I really want you to be circumspect of how you want to store and format your content going forward. If you're going for markdown, at least consider the following trade-offs:
Markdown is not great for the developer experience in modern stacks :
- It can be a hassle to parse and validate, even with great tooling.
- Even if you adopt CommonMark, you aren't guaranteed compatibility with tooling or people's expectations.
- It's not great for structured content, YAML frontmatter only takes you so far.
Markdown is not great for editorial experience :
- Most content creators don't want to learn syntax, their time is better spent on other things.
- Most markdown systems are brittle, especially when people get syntax wrong (which they will).
- It's hard to accommodate great collaborative user experiences for block content on top of markdown.
Markdown is not great in block content age , and shouldn't be forced into it. Block content needs to:
- Be untangled from HTMLisms and presentation agnostic.
- Accommodate structured content, so it can be easily used wherever it needs to be used.
- Have stable specification(s), so it's possible to build on.
- Support real-time collaborative systems.
What's common for people like me who challenge the prevalence of markdown, and those who are really into the simple way of expressing text formating is an appreciation of how we transcribe intent into code. That's where I think we can all meet. But I do think it's time to look at the landscape and the emerging content formats that try to encompass modern needs, and ask how we can make sure that we build something that truly caters to editorial experience, and that can speak to developer experience as well.
I want to express my gratitude to Titus Wormer (@wooorm) for his insightful feedback on my first draft of this post, and for the great work he and the Unified.js team have done for the web community.