
Matematyka stojąca za uczeniem maszynowym: co musisz wiedzieć?
Opublikowany: 2021-03-10Uczenie maszynowe to dział sztucznej inteligencji, który koncentruje się na budowaniu aplikacji poprzez dokładne przetwarzanie dostępnych danych. Podstawowym celem uczenia maszynowego jest pomoc komputerom w przetwarzaniu obliczeń bez interwencji człowieka. Jest to możliwe dzięki umożliwieniu maszynie uczenia się naśladowania ludzkiej inteligencji za pomocą nadzorowanych lub nienadzorowanych metod uczenia się.
Uczenie maszynowe to połączenie wielu dziedzin, które obejmują statystykę, prawdopodobieństwo, algebrę liniową, rachunek różniczkowy itd., na podstawie których model uczenia maszynowego może tworzyć lub zasilać algorytmy do improwizacji zgodnie z ludzką inteligencją. Im bardziej złożona aplikacja, tym bardziej złożony będzie jej algorytm.
Produkty i narzędzia oparte na uczeniu maszynowym są wszędzie wokół nas, od asystentów cyfrowych i urządzeń inteligentnych po witryny polecające Twoje ulubione produkty w oparciu o Twoją aktywność online oraz telefony komórkowe powiadamiające Cię o rozkładzie lotów. Wraz ze wzrostem naszej zależności od inteligentnych urządzeń i urządzeń, wzrośnie też potrzeba wdrażania uczenia maszynowego.
W tym celu w tym artykule przyjrzymy się pojęciom matematycznym wymaganym przy pisaniu algorytmów uczenia maszynowego i ich implementacji.
Spis treści
Jakie jest znaczenie matematyki w uczeniu maszynowym?
Aplikacje do uczenia maszynowego zapewniają analizy i spostrzeżenia zebrane z dostępnych danych, które przyczyniają się do podejmowania praktycznych decyzji w firmach. Ponieważ uczenie maszynowe polega na studiowaniu i wdrażaniu algorytmów, ważne jest, aby wzmocnić swoje umiejętności matematyczne. Pomaga w eliminowaniu niepewności i dokładnym przewidywaniu wartości danych w przypadku złożonych parametrów i funkcji danych. Pomaga nam również lepiej zrozumieć kompromis między odchyleniem a odchyleniem.
Opanowanie uczenia maszynowego wymaga znajomości pojęć matematycznych, takich jak algebra liniowa, rachunek wektorowy, geometria analityczna, rozkłady macierzy, prawdopodobieństwo i statystyka. Silne ich zrozumienie pomaga w tworzeniu intuicyjnych aplikacji do uczenia maszynowego.

Algebra liniowa
Algebra liniowa zajmuje się wektorami i macierzami, a głównie obraca się wokół obliczeń. Odgrywa integralną rolę w uczeniu maszynowym i technikach głębokiego uczenia. Według Skylera Speakmana jest to matematyka XXI wieku.
Algebra liniowa jest zwykle używana przez inżynierów ML i naukowców zajmujących się danymi lub badaczy do tworzenia algorytmów liniowych, regresji logistycznych, drzew decyzyjnych i maszyn wektorów nośnych.
Rachunek różniczkowy
Rachunek różniczkowy napędza algorytmy uczenia maszynowego. Bez znajomości jego koncepcji nie byłoby możliwe przewidywanie wyników przy użyciu danego zestawu danych. Rachunek pomaga analizować tempo zmian ilości i dotyczy optymalnej wydajności algorytmów uczenia maszynowego. Integracje, różniczki, ograniczenia i pochodne to kilka koncepcji rachunku różniczkowego, które pomagają trenować głębokie sieci neuronowe.
Prawdopodobieństwo
Prawdopodobieństwo w uczeniu maszynowym przewiduje zestaw wyników, podczas gdy statystyki prowadzą do pozytywnego wyniku. Wydarzenie może być tak proste, jak rzucanie monetą. Prawdopodobieństwo można podzielić na dwie kategorie: prawdopodobieństwo warunkowe i prawdopodobieństwo wspólne. Wspólne prawdopodobieństwo ma miejsce, gdy zdarzenia są od siebie niezależne, natomiast prawdopodobieństwo warunkowe występuje, gdy jedno zdarzenie zastępuje drugie.
Statystyka
Statystyka skupia się na ilościowych i jakościowych aspektach algorytmu. Pomaga nam identyfikować cele i przekształcać zebrane dane w precyzyjne obserwacje, prezentując je zwięźle. Statystyki w uczeniu maszynowym skupiają się na statystykach opisowych i statystykach wnioskowanych.
Statystyka opisowa dotyczy opisu i podsumowania małego zbioru danych, nad którym pracuje model. Stosowane tutaj metody to średnia, mediana, moda, odchylenie standardowe i zmienność. Wyniki końcowe są przedstawiane jako reprezentacje obrazkowe.
Statystyka wnioskowania zajmuje się wydobywaniem spostrzeżeń z danej próbki podczas pracy z dużym zbiorem danych. Statystyka wnioskowa pozwala maszynom analizować dane wykraczające poza zakres dostarczanych informacji. Testy hipotez, rozkłady próbkowania, analiza wariancji to niektóre aspekty statystyki wnioskowania.
Poza tym sprawność kodowania jest kluczowym warunkiem uczenia maszynowego. Znajomość języków takich jak Python i Java pomaga w lepszym zrozumieniu modelowania danych. Formatowanie łańcuchów, definiowanie funkcji, pętle z wieloma iteratorami zmiennych, czy wyrażenia warunkowe to tylko niektóre z jego podstawowych funkcji.
Jeśli chodzi o modelowanie danych, jest to proces, za pomocą którego szacujemy strukturę zbiorów danych i wykrywamy możliwe odchylenia i wzorce. Aby móc dokonywać dokładnych prognoz, należy zdawać sobie sprawę z różnych właściwości danych zbiorczych.
Jak nauczyć się uczenia maszynowego?
Chociaż uczenie maszynowe jest lukratywną dziedziną, wymaga dużo praktyki i cierpliwości. Biorąc pod uwagę jego zastosowania w prawie każdej branży, inżynierowie zajmujący się uczeniem maszynowym są bardzo poszukiwani.
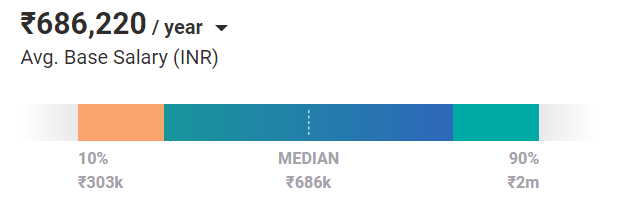
Średnia pensja inżyniera na poziomie podstawowym z doświadczeniem w uczeniu maszynowym wynosi 686 tys. Rs rocznie. A dzięki doświadczeniu i podnoszeniu umiejętności potencjał do zarabiania wyższej pensji rośnie wykładniczo.
Dostępnych jest kilka kursów dla kogoś, kto chce poszerzyć swoją bazę wiedzy w uczeniu maszynowym. Opanowanie tematu zajęłoby Ci minimum 6 miesięcy do 2 lat.
Z co najmniej tytułem licencjata i rocznym doświadczeniem zawodowym, jeszcze lepszym z matematyką lub statystyką, możesz kontynuować jeden z następujących kursów na upGrad , aby zwiększyć swoje szanse na sukces w tej dziedzinie.
- Zaawansowany program certyfikacji w uczeniu maszynowym i uczeniu głębokim z IIT Bangalore (6 miesięcy)
- Zaawansowany program certyfikacji w uczeniu maszynowym i NLP od IIT Bangalore (6 miesięcy)
- Program Executive PG w zakresie uczenia maszynowego i sztucznej inteligencji z IIT Bangalore (12 miesięcy)
- Zaawansowana certyfikacja w zakresie uczenia maszynowego i chmury od IIT Madras (12 miesięcy)
- Master of Science in Machine Learning i AI z LJMU i IIT Bangalore (18 miesięcy)
Wszystkie te kursy oferują minimum 240+ godzin nauki i co najmniej 5 studiów przypadku, które pomogą ci uzyskać dogłębne zrozumienie uczenia maszynowego i jego różnych dziedzin pomocniczych. Możesz omówić podstawowe tematy, takie jak Python, MySQL, Tensor, NLTK, statsmodels, excel itp., które stanowią podstawę kodowania. Oto szczegółowe spojrzenie na różne kursy doskonalące w zakresie uczenia maszynowego, dzięki czemu możesz wybrać ten, który najbardziej Ci odpowiada.

Dołącz do internetowego kursu sztucznej inteligencji z najlepszych światowych uniwersytetów — studiów magisterskich, programów podyplomowych dla kadry kierowniczej oraz zaawansowanego programu certyfikacji w zakresie uczenia się maszynowego i sztucznej inteligencji, aby przyspieszyć swoją karierę.
Zastosowania uczenia maszynowego
Uczenie maszynowe odgrywa kluczową rolę w naszym codziennym życiu, zarówno w sferze zawodowej, jak i osobistej. Jego możliwości analityczne i intuicyjne mogą drastycznie wpłynąć na sposób, w jaki wykonujemy nasze codzienne zadania. Okazał się zaradny w oszczędzaniu pieniędzy i czasu dla organizacji.
Chociaż uczenie maszynowe to szeroka dziedzina, która ma zastosowanie w prawie każdej branży, oto kilka najważniejszych przykładów:
- Rozpoznawanie obrazu jest jedną z najczęściej używanych aplikacji, ponieważ pomaga w wykrywaniu twarzy, tworząc w ten sposób osobną bazę danych dla każdej osoby. Może być również używany do identyfikacji stylów pisma ręcznego.
- Uczenie maszynowe w sektorze zdrowia zwiększyło możliwości dostawców opieki zdrowotnej. Może być stosowany w szybszej diagnostyce medycznej. W wielu przypadkach sztuczna inteligencja pomogła we wczesnej diagnozie chorób, umożliwiając w ten sposób lekarzom proponowanie terapii i środków zapobiegawczych, które mogą uratować życie.
- Uczenie maszynowe ma duże zastosowanie w sektorze finansowym, gdzie dotyczy inwestycji, fuzji i przejęć. Pomaga bankom i innym instytucjom gospodarczym dokonywać mądrych wyborów.
- Jego skuteczność jest prawdopodobnie najbardziej widoczna w branży obsługi klienta i usług, ponieważ uczenie maszynowe usprawnia operacje i zapewnia rozwiązania szybko i wydajniej.
- Uczenie maszynowe automatyzuje zadania, które w innym przypadku musiałby wykonać człowiek w terenie. Na przykład, gdybyśmy wzięli pod uwagę wirtualnych asystentów, mogłoby to być tak proste zadanie, jak zmiana hasła lub wieczorne sprawdzenie stanu konta bankowego. Dzięki uczeniu maszynowemu można teraz przydzielać zasoby ludzkie do bardziej naglących zadań, które wymagają skomplikowanego podejmowania decyzji lub ludzkiego dotyku.
Przyszły zakres uczenia maszynowego
Mimo że uczenie maszynowe istnieje od dziesięcioleci, jego zastosowanie jest najbardziej widoczne dzisiaj. Branża musi jeszcze prosperować i improwizować, co oznacza, że przyszłość uczenia maszynowego jest świetlana. Większość dużych firm już czerpie korzyści z uczenia maszynowego i skalowania swoich usług i produktów w celu stymulowania wzrostu.
Oczywiście inżynierowie ML są bardzo poszukiwani, a uczenie maszynowe przedstawia się jako lukratywna kariera, w którą można się dostać. Zapewnia firmom przewagę, której potrzebują. Sztuczna inteligencja wygenerowała do tej pory około 2,3 miliona miejsc pracy. Przewiduje się, że do końca 2022 r. światowy przemysł ML wzrośnie w CAGR na poziomie 42,2%, osiągając 9 miliardów USD .
Oto kilka najważniejszych trendów w uczeniu maszynowym:
- Coraz więcej algorytmów uczy się w kierunku nienadzorowanych wdrożeń. Firmy inwestują w obliczenia kwantowe w oparciu o te nienadzorowane algorytmy, które mogą przekształcić uczenie maszynowe. Przyczyniają się one do analizowania i rysowania znaczących spostrzeżeń, pomagając w ten sposób firmom osiągać lepsze wyniki, które nie byłyby możliwe przy użyciu klasycznych technik uczenia maszynowego.
- Roboty napędzane sztuczną inteligencją są wdrażane do wykonywania operacji biznesowych. Jednak technologie te są w początkowej fazie, a ponieważ firmy inwestują w tworzenie przyczółków AI i ML, roboty wkrótce pomogą w wykładniczym zwiększeniu produktywności. Jako przykład przytoczmy drony, które stanowią potężne narzędzia biznesowe na rynku konsumenckim, gdzie są wykorzystywane do wykonywania operacji handlowych i prostych zadań, takich jak dostarczanie towarów.
- Algorytmy uczenia maszynowego obsługują ulepszoną personalizację. Algorytmy te badają zachowanie potencjalnych klientów w Internecie i wysyłają informacje z powrotem do firm. Firmy z kolei przesyłają im rekomendacje produktów i usług. Te techniki uczenia maszynowego pomagają zidentyfikować upodobania i niechęci klientów. Dzięki uczeniu maszynowemu firmy dają swoim klientom to, czego pragną i kiedy tego pragną, co zwiększa retencję klientów i przyciąga więcej biznesu do organizacji. Ulepszona personalizacja to przyszłość uczenia maszynowego.
- Dzięki ulepszonym algorytmom uczenia maszynowego aplikacje mobilne i internetowe są teraz inteligentniejsze niż kiedykolwiek. Ulepszone usługi kognitywne umożliwiają programistom tworzenie oddzielnych baz danych dla każdego klienta na podstawie rozpoznawania wizualnego, ich mowy, dźwięku, głosu i tak dalej.
To prowadzi nas do końca artykułu. Mamy nadzieję, że te informacje okazały się pomocne!
Dlaczego homoskedastyczność jest wymagana w regresji liniowej?
Homoskedastyczność opisuje, jak podobne lub jak daleko odbiegają dane od średniej. Jest to ważne założenie, ponieważ parametryczne testy statystyczne są wrażliwe na różnice. Heteroskedastyczność nie powoduje błędu systematycznego w estymacji współczynników, ale zmniejsza ich precyzję. Przy mniejszej precyzji oszacowania współczynnika z większym prawdopodobieństwem będą odbiegać od prawidłowej wartości populacji. Aby tego uniknąć, homoskedastyczność jest kluczowym założeniem do stwierdzenia.
Jakie są dwa rodzaje współliniowości w regresji liniowej?
Współliniowość danych i strukturalna to dwa podstawowe typy współliniowości. Kiedy tworzymy wyraz modelowy z innych wyrazów, otrzymujemy strukturalną wielowspółliniowość. Innymi słowy, zamiast być obecny w samych danych, jest wynikiem dostarczonego przez nas modelu. Chociaż wielokoliniowość danych nie jest artefaktem naszego modelu, jest ona obecna w samych danych. W badaniach obserwacyjnych częściej występuje wielokolinearność danych.
Jakie są wady używania t-testu do niezależnych testów?
Występują problemy z powtarzaniem pomiarów zamiast różnic między projektami grupowymi podczas korzystania z testów t dla sparowanych próbek, co prowadzi do efektów przeniesienia. Ze względu na błędy typu I test t nie może być stosowany do porównań wielokrotnych. Trudno będzie odrzucić hipotezę zerową, wykonując sparowany test t na zbiorze próbek. Pozyskiwanie tematów do danych z próby jest czasochłonnym i kosztownym aspektem procesu badawczego.