
ProcessWire CMS — przewodnik dla początkujących
Opublikowany: 2022-03-10ProcessWire to system zarządzania treścią (CMS) rozpowszechniany na podstawie licencji Mozilla Public License w wersji 2.0 (MPL) oraz licencji MIT. Został zaprojektowany od podstaw, aby rozwiązać problemy spowodowane właśnie tego rodzaju opiniowaniem (co nieuchronnie prowadzi do sfrustrowanych programistów i użytkowników) poprzez bycie — zgadliście — brak opinii. W istocie opiera się na kilku prostych podstawowych koncepcjach i oferuje wyjątkowo łatwy w użyciu i potężny interfejs API do obsługi wszelkiego rodzaju treści. Przejdźmy od razu!
Dalsze czytanie na SmashingMag:
- Projektowanie dla systemów zarządzania treścią
- Dlaczego statyczne generatory stron internetowych to kolejna wielka rzecz?
- Zestaw ikon systemu zarządzania treścią (CMS) (12 darmowych ikon)
- Pierwsze kroki z systemami zarządzania treścią
GUI administratora
Po zainstalowaniu ProcessWire (który wymaga PHP 5.3.8+, MySQL 5.0.15+ i Apache) zobaczysz stronę główną domyślnego GUI administratora:

Uwaga: Strony, które widzisz w hierarchicznym drzewie stron (więcej o tym później) są dostępne, ponieważ podczas procesu instalacji wybrałem profil witryny „Domyślna (edycja dla początkujących)”. Jest to całkowicie opcjonalne. Możesz również zacząć od pustego profilu witryny, który pozwala budować wszystko od podstaw.
W rzeczywistości możesz wybierać spośród wielu motywów administracyjnych, chociaż dla ProcessWire 2.6+ zalecany jest motyw domyślny lub motyw Reno. Ponieważ Reno jest dostarczane z każdą instalacją ProcessWire, przejście na niego jest dość łatwe: po prostu zainstaluj i wybierz w swoim profilu użytkownika.
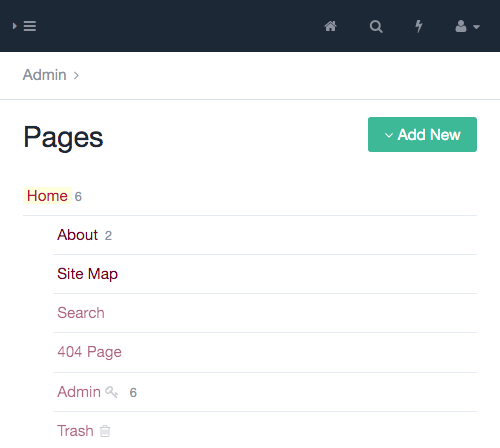
Rzućmy okiem na główną nawigację zaplecza:

- „Strony” To jest punkt wejścia GUI administratora. Zawiera hierarchiczne drzewo stron, a tym samym całą zawartość Twojej witryny na zapleczu.
- „Konfiguracja” W tym miejscu można skonfigurować ogólną architekturę modelu danych instalacji za pomocą szablonów i pól (więcej o tym później). Jest to również miejsce, w którym moduły ProcessWire często dodają wpis dotyczący ich specyficznej funkcjonalności i interfejsu użytkownika — na przykład wizualizacji komunikatów dziennika bezpośrednio w GUI administratora lub zarządzania wszystkimi różnymi językami w przypadku treści wielojęzycznych.
- „Moduły” Tutaj zarządzasz wszystkimi modułami swojej witryny. Pomyśl o modułach ProcessWire jak o wtyczkach do WordPressa: rozszerzają i dostosowują system.
- „Dostęp” Tutaj zarządzasz użytkownikami, rolami użytkowników i uprawnieniami użytkowników.
Trzy proste podstawowe koncepcje
Podstawowe koncepcje, które tworzą ogólną architekturę modelu danych ProcessWire, to dokładnie trzy: strony, pola i szablony . Przyjrzyjmy się każdemu po kolei.
Wszystko jest stroną: lub jednostronicowe drzewo, które rządzi nimi wszystkimi
Strona w ProcessWire może generować zwykłą stronę w interfejsie witryny, gotową do odwiedzenia przez użytkowników (np. „Strona główna” i „Informacje” na powyższym zrzucie ekranu). Ale strona może również istnieć wyłącznie w zapleczu, bez odpowiednika z przodu — na przykład ukryta strona ustawień, na której przechowujesz globalne hasło, logo i informację o prawach autorskich swojej witryny. Kiedy mówię „wszystko jest stroną” w ProcessWire, mam na myśli to. Heck, nawet główne linki nawigacyjne w GUI administratora składają się z ukrytych stron w hierarchicznym drzewie stron!
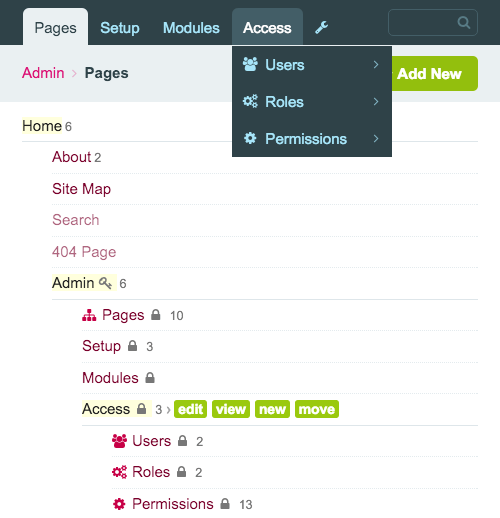
To jest tak meta, że przypomina mi się pewien mem Xzibit. Ale zostawmy to.
Koncepcja strony widocznej tylko na zapleczu jest dość potężna, ponieważ otwiera cały świat możliwości strukturyzowania i uzyskiwania dostępu do danych za pośrednictwem innych stron (ograniczeniem jest tylko Twoja wyobraźnia). Możesz zbudować ogromny katalog produktów, aplikację intranetową z setkami tysięcy elementów opartych na złożonej hierarchii stron lub po prostu prosty blog ze zwykłymi kategoriami i tagami bloga (każda kategoria i tag to strona w drzewie stron) .
Joss Sanglier, wybitny członek społeczności ProcessWire, dzieli koncepcję stron na następujące:
Strony [I]n ProcessWire […] nie są wielkimi łykami informacji, ale malutkimi drobiazgami, niczym więcej niż linkiem do ciekawszego świata pól i szablonów; tylko mały skrawek danych w Twojej ogromnej, fascynującej bazie danych.Strony w ProcessWire są używane do różnych rzeczy. Mogą być używane jako znacznik na liście stron. Mogą być używane jako nadrzędne grupy dla innych stron. Mogą być używane jako kategorie, tagi lub listy lub użytkownicy. Można ich nawet używać do prostych wyborów z listy rozwijanej — tylko po to, by podać etykietę i wartość.
Przejdźmy trochę w interakcję z hierarchicznym drzewem stron:
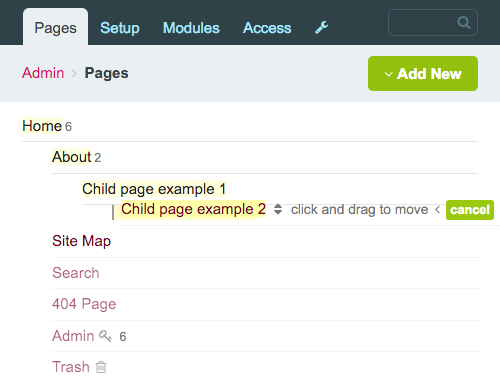
Jak widać, strony można edytować, przenosić lub wyrzucać i mogą mieć nieskończoną liczbę dzieci i wnuków.
Otwórzmy stronę „Strona główna”:
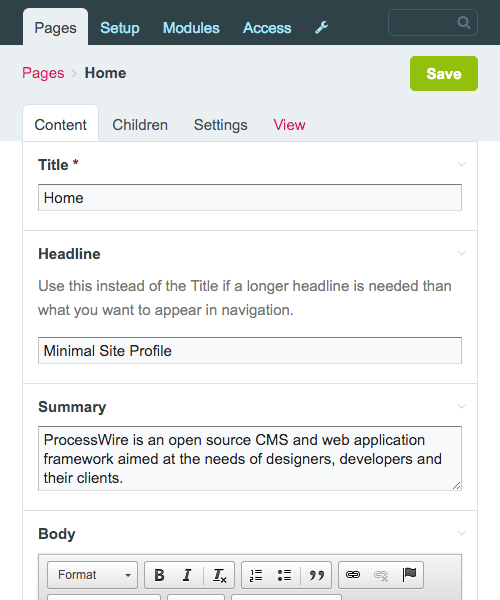
To prowadzi nas do kolejnej podstawowej koncepcji ProcessWire, pól.
Pola to pojemniki, w których umieszczasz dane
Pola to w zasadzie pojemniki, w których umieszczasz dane. W tym momencie ważne jest, aby zdać sobie sprawę, że ProcessWire nie ma koncepcji pól niestandardowych, tak jak WordPress, ponieważ każde pole w ProcessWire jest polem niestandardowym . Tworząc pole, możesz nadać mu etykietę, opis i dodatkowe uwagi, które pojawią się pod nim.
Edytujmy pole „Tytuł” i dodajmy do niego opis i uwagę:
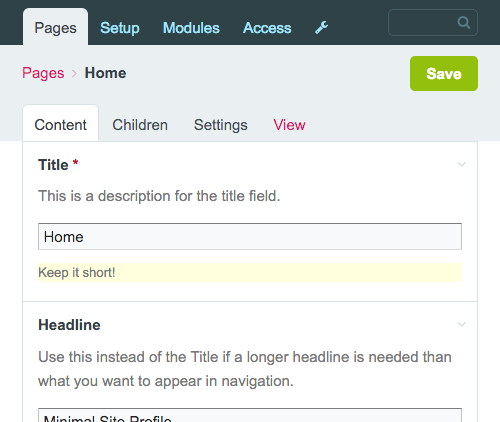
Preinstalowane typy pól pokrywają większość podstawowych potrzeb związanych z wprowadzaniem danych. Na przykład możesz tworzyć takie rzeczy, jak pola wyboru, selektory dat, zestawy pól (pole, które grupują inne pola w wizualnie logiczne jednostki), programy do przesyłania plików i obrazów oraz oczywiście pola tekstowe i tekstowe (domyślnym edytorem WYSIWYG jest CKEditor ).
Do wyboru jest również wiele wstępnie zapakowanych i innych typów pól. Przydatnym modułem podstawowym, który nie jest domyślnie instalowany, jest pole repeatera . Umożliwia dynamiczne tworzenie wierszy zestawów danych.
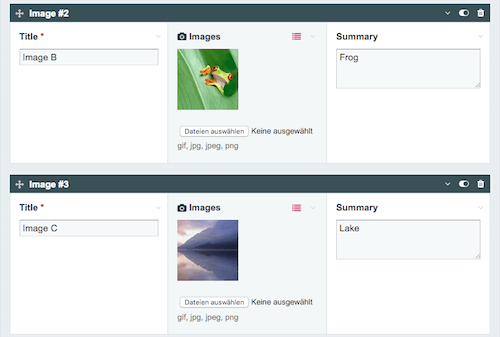
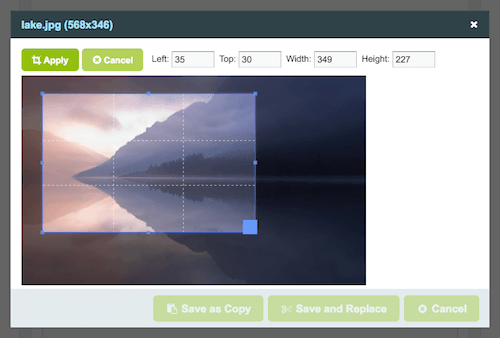
ProcessWire dobrze nadaje się również do obsługi obrazów . Na przykład, możesz zdecydować, które warianty obrazu ProcessWire powinien automatycznie utworzyć obraz po jego przesłaniu (co umożliwia ładne przypadki użycia dla responsywnych obrazów). A wybór miniatury dla obrazu to pestka.
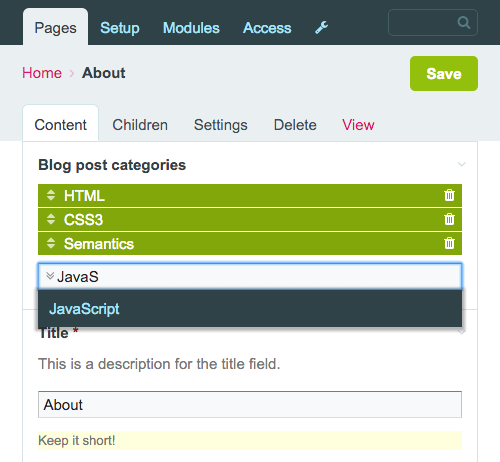
Innym przydatnym typem pola jest typ pola strony . Możesz połączyć inne strony ze stroną, którą aktualnie edytujesz, tworząc w ten sposób relację między nimi. W ustawieniach pola możesz zdecydować, jak powinien wyglądać wygląd danych wejściowych i interakcja z polem — na przykład, czy można wybrać jedną stronę, czy wiele stron, czy też można wybrać tylko strony podrzędne określonej strony nadrzędnej. Jeśli miałbyś napisać, powiedzmy, post na blogu, możesz zezwolić na autouzupełnianie tylko kategorii postów na blogu.
Przydatną funkcją, którą możesz włączyć w ustawieniach pola, jest możliwość edycji zawartości pola w interfejsie witryny . Gdy użytkownik zaloguje się do back-endu ProcessWire, może przełączyć się na front-end witryny i edytować oraz zapisywać treść dokładnie tam, gdzie zostanie ostatecznie wyrenderowana.
Po przejrzeniu stron i pól w ProcessWire możesz zadać sobie pytanie: Skąd strona wie, jakie posiada pola? A gdzie mogę określić, jak pola są uporządkowane i renderowane na stronie? Przejdźmy więc do ostatniej podstawowej koncepcji, szablonów.
Szablony są schematami stron
Za każdym razem, gdy tworzysz stronę w hierarchicznym drzewie stron, ProcessWire musi wiedzieć, który szablon jest z nią powiązany. Dzieje się tak, ponieważ strona musi wiedzieć, które pola ma renderować, a informacje te są zawsze częścią odpowiedniego szablonu.
Krótko mówiąc: szablony zawierają wszystkie informacje, które strona musi wiedzieć o swojej zawartości (jakie ma pola, jak te pola są renderowane i jak się zachowują).
Otwórzmy szablon „Home” z naszej przykładowej instalacji.
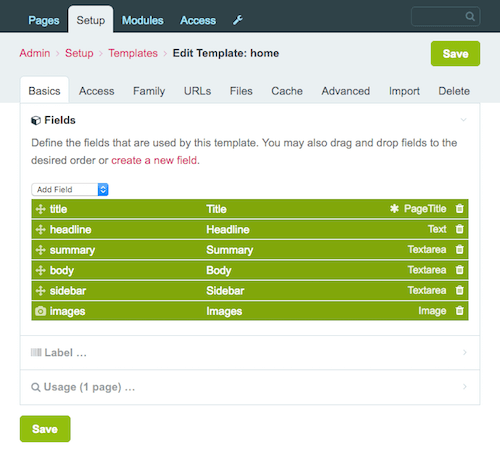
Najważniejszą rzeczą do zauważenia jest liczba ustawień. Jest tu naprawdę wiele do odkrycia. Na przykład możesz ograniczyć dostęp do stron utworzonych za pomocą tego szablonu do określonych ról użytkownika. Możesz też zdecydować, czy strony utworzone za pomocą tego szablonu powinny być buforowane przez określony czas (w celu zwiększenia wydajności) oraz warunki, w których pamięć podręczna musi zostać wyczyszczona.
Kolejne potężne ustawienie jest ukryte w zakładce „Rodzina”. Tutaj możesz określić, czy strony utworzone za pomocą tego szablonu mogą mieć strony podrzędne i które szablony są dozwolone dla strony nadrzędnej lub jej stron podrzędnych. Dzięki temu możesz utworzyć dokładnie taki rodzaj hierarchii rodziny szablonów, jaki chcesz. Jest to elastyczny i wygodny sposób (a właściwie jeden z najpotężniejszych) strukturyzacji danych i jest to jeden z wielu sposobów, w jaki ProcessWire pokazuje swoją elastyczność.
Zwróćmy uwagę na listę pól w szablonie. Na powyższym zrzucie ekranu widać, że kolejność pól przypomina kolejność, w jakiej pola będą renderowane na stronie głównej. Możesz po prostu przeciągać i upuszczać pola, aby zmienić kolejność na liście, zmieniając w ten sposób kolejność wyświetlania podczas edycji strony głównej.
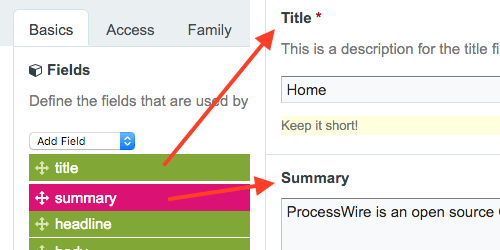
Możesz także zmienić szerokość pola na stronie. Po prostu kliknij pole i zmień je. Ustawmy obok siebie pola „Tytuł” i „Nagłówek”.
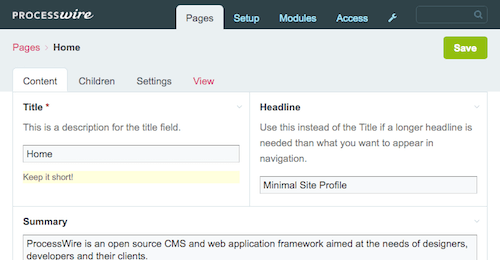
Innym przykładem dostosowywania i dostosowywania interfejsu użytkownika strony i jej pól są zależności inputfield. Umożliwiają one określenie warunków, w których określone pole w edytorze stron jest wyświetlane lub wymagane. Sprawmy, aby pole „Nagłówek” było widoczne w interfejsie użytkownika tylko wtedy, gdy użytkownik wprowadzi coś w polu „Tytuł”, a pole „Podsumowanie” jako wymagane tylko wtedy, gdy użytkownik wpisze coś w polu „Nagłówek”:
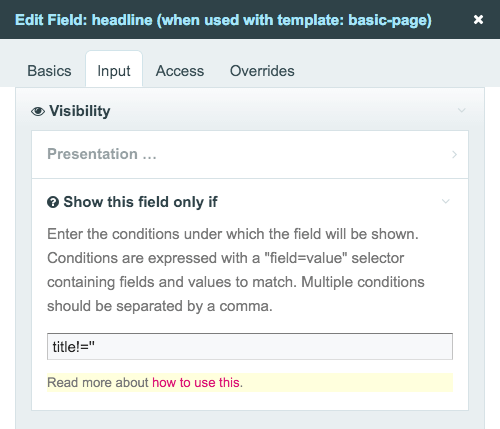
Oto wideo, które pokazuje, w jaki sposób można wykorzystać zależności inputfield do poprawy doświadczenia użytkownika podczas pracy z ProcessWire:
Liczba, kolejność i wygląd pól na stronie są całkowicie pod Twoją kontrolą. Możesz umieścić tylko jedno pole w szablonie, w ogóle żadnego (niezbyt przydatne) lub więcej niż 50 pól, 100 lub nawet więcej. Możesz je zamówić w dowolny sposób, określić, które są wymagane lub widoczne, a które nie oraz w jakich okolicznościach mają być wymagane lub widoczne. W tym miejscu błyszczy nieocenione podejście ProcessWire.
Podsumowanie: strony, pola, szablony
Podsumujmy techniczne relacje między stronami, polami i szablonami: dodajesz pola do szablonów i wybierasz szablon podczas tworzenia nowej strony. Pola, które widzisz podczas edycji strony, to pola dodane przez Ciebie do wybranego szablonu.
Innym sposobem spojrzenia na to jest analogia ze świata programowania:
- Szablony są jak zajęcia.
- Pola są jak właściwości klas.
- Strony są instancjami klas.
Kiedy już zinternalizujesz te koncepcje, będziesz wyposażony we wszystko, co musisz wiedzieć, aby rozwijać się w ProcessWire. Powodem tego jest to, że filozofia ProcessWire opiera się wyłącznie na tych trzech koncepcjach. Całkiem fajnie, prawda?
Pliki szablonów i API: para przeznaczona do bycia razem
Miejscem, w którym pobierasz dane wprowadzone do zaplecza ProcessWire i wyprowadzasz je na interfejsie, jest oczywiście system plików — a dokładniej folder /site/templates/ instalacji ProcessWire. Z szablonem może być powiązany fizyczny plik PHP o tej samej nazwie; więc szablon home miałby plik home.php w folderze /site/templates/ .
Uwaga: sposób tworzenia plików szablonów zależy wyłącznie od Ciebie. Jeśli znasz styl WordPressa, możesz kontynuować, tak jak przywykłeś. Lub, jeśli masz dość złożoną i dużą konfigurację i chcesz stworzyć bardziej wyrafinowaną architekturę, możesz użyć podejścia inspirowanego MVC, które działałoby równie dobrze. Ryan Cramer ma całkiem niezły samouczek wprowadzający, zatytułowany „Jak ustrukturyzować pliki szablonów”, w którym można nauczyć się różnych podejść do tworzenia plików szablonów w ProcessWire.
Kod, który piszesz w pliku szablonu, składa się głównie z podstawowych konstrukcji PHP (warunki if , pętle foreach , instrukcje echo ), znaczniki HTML i API ProcessWire. Interfejs API jest mocno inspirowany jQuery — tak naprawdę przypomina iterację i przechodzenie zawartości wprowadzonej w zapleczu za pomocą metod, selektorów i możliwości tworzenia łańcuchów (płynny interfejs). Jest łatwy w użyciu i bardzo wyrazisty, podobnie jak jQuery.
Zacznijmy od przyjrzenia się kilku prostym przykładom, które pomogą Ci zacząć korzystać z interfejsu API. Ale zanim zaczniemy, pamiętaj, aby dodać zakładkę do ściągawki API ProcessWire, pomocnej referencji z przeglądem wszystkich dostępnych metod API.
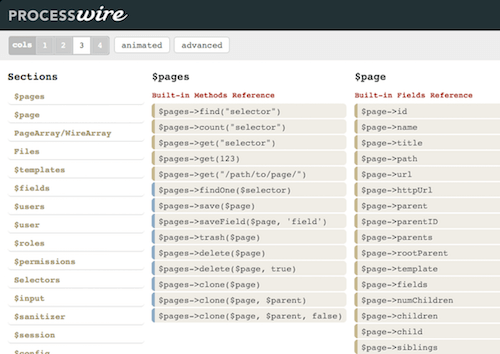
Pierwszą rzeczą, którą chcemy zrobić, jest uzyskanie dostępu i wyświetlenie zawartości pola strony. API udostępnia zmienną, która pozwala nam sobie z tym poradzić: $page .
Pobieranie bieżącej strony ze zmienną $page
Zmienna $page zawiera wszystkie pola pojedynczej strony. Obejmuje to pola wbudowane (takie jak nazwa szablonu strony), a także pola dodane przez programistę do szablonu strony.
Otwórzmy home.php , który jest plikiem szablonu szablonu home i dodajmy do niego następującą linię:
echo $page->title;To każe ProcessWire pobrać pole „Tytuł” strony, na której aktualnie się znajdujemy („Strona główna”) i wyprowadzić ją. Załóżmy, że na stronie mamy również pole „Nagłówek”, którego chcemy użyć zamiast pola „Tytuł”, ale tylko wtedy, gdy użytkownik coś w nim wprowadził.
echo $page->get("headline|title"); Użyliśmy metody get , aby uzyskać dostęp do pola strony (więc $page->get(“title”) jest w zasadzie odpowiednikiem pierwszego przykładu kodu powyżej) i napisaliśmy “headline|title” w metodzie get . To mówi ProcessWire, aby najpierw sprawdził pole „Nagłówek” i wysłał treść nagłówka. Ale jeśli pole „Nagłówek” jest puste, to pole „Tytuł” jest używane jako zastępcze.
Możliwe jest również użycie zmiennych API w ciągach PHP. Poniższe dwie instrukcje echo do wyprowadzania liczby dzieci strony są równoważne:
echo "This page has " . $page->numChildren . " children pages."; echo "This page has {$page->numChildren} children pages."; Pobierzmy dzieci naszej strony głównej (pamiętaj, że wciąż jesteśmy w home.php ) i wypiszmy je jako listę linków:
echo "<ul>"; foreach ($page->children as $child) { echo "<li><a href='{$child->url}'>{$child->title}</a></li>"; } echo "</ul>"; Innym przykładem pola wbudowanego (takiego jak children i url w powyższym przykładzie) jest iteracja przez wszystkich rodziców strony i tworzenie nawigacji w trybie nawigacyjnym:
echo "<ul>"; foreach ($page->parents as $parent) { echo "<li><a href='{$parent->url}'>{$parent->title}</a></li>"; } // output the page itself at the end echo "<li>{$page->title}</li>"; echo "</ul>"; Na stronie głównej („Home”) to po prostu wyświetli tytuł, ponieważ $page->parents będzie puste.
Wcześniej pokazałem, jak tworzyć miniatury obrazów w GUI administratora. Tworzenie miniaturek można również wykonać programowo za pomocą interfejsu API. Przejrzyjmy wszystkie obrazy przesłane w polu „Obrazy”, utwórzmy duży wariant obrazu o szerokości 600 pikseli z proporcjonalną wysokością i miniaturą o wymiarach 150 × 150 pikseli z określonymi opcjami, takimi jak ustawienia przycinania i jakość obrazu. Na koniec chcemy połączyć obraz miniatury z dużym obrazem. Brzmi skomplikowanie? Nie jest.
$options = array( "quality" => 90, "cropping" => "northwest" ); foreach ($page->images as $image) { $large = $image->width(600); $thumbnail = $image->size(150, 150, $options); echo "<a href='{$large->url}'><img src='{$thumbnail->url}' alt='></a>"; }ProcessWire jest pod tym względem całkiem sprytny, ponieważ tworzy obrazy w dowolnych rozmiarach w locie i przechowuje je w pamięci podręcznej, więc musi tworzyć wersje tylko raz.

Oto ostatni przykład $page , który pokazuje, że interfejs API jest bardzo podobny do interakcji z DOM podczas korzystania z jQuery. Pobierzmy ostatnie dziecko strony nadrzędnej, na której aktualnie się znajdujemy.
$wantedPage = $page->parent->children()->last(); Oprócz zmiennej $page interfejs API udostępnia jeszcze jedną ważną: $pages .
Pobieranie wszystkich stron ze zmienną $pages
Dzięki $pages masz dostęp do wszystkich stron w swojej instalacji ProcessWire. Innymi słowy, zapewnia dostęp do wszystkich treści z dowolnego miejsca .
Na przykład możesz mieć ukrytą (czyli niedostępną w interfejsie) stronę ustawień w swojej instalacji ProcessWire; możesz dodać ustawienia globalne, takie jak tytuł i opis swojej witryny; i możesz uzyskać dostęp do tych obiektów blob zawartości i wyprowadzić je z dowolnego pliku szablonu.
$settings = $pages->get("template=settings"); echo "<h1>{$settings->global_title}</h1>"; echo "<p>{$settings->global_description}</p>";Jednym z typowych przypadków użycia jednej strony tematycznej bloga jest pokazanie wszystkich postów na blogu, w których znajduje się odniesienie do danego tematu. Po prostu napisz to w pliku szablonu tematu:
$pages->find("template=blog-post, topics=$page"); Uwaga: topics to pole w szablonie blog-post , w którym można dodać wszystkie kategorie tematów, które są specyficzne dla wpisu na blogu.
Kolejne potężne ustawienie jest ukryte w zakładce „Rodzina”. Tutaj możesz określić, czy strony utworzone za pomocą tego szablonu mogą mieć strony podrzędne i które szablony są dozwolone dla strony nadrzędnej lub jej stron podrzędnych. Dzięki temu możesz utworzyć dokładnie taki rodzaj hierarchii rodziny szablonów, jaki chcesz. Jest to elastyczny i wygodny sposób (a właściwie jeden z najpotężniejszych) strukturyzacji danych i jest to jeden z wielu sposobów, w jaki ProcessWire pokazuje swoją elastyczność.
Zwróćmy uwagę na listę pól w szablonie. Na powyższym zrzucie ekranu widać, że kolejność pól przypomina kolejność, w jakiej pola będą renderowane na stronie głównej. Możesz po prostu przeciągać i upuszczać pola, aby zmienić kolejność na liście, zmieniając w ten sposób kolejność wyświetlania podczas edycji strony głównej.
Możesz także zmienić szerokość pola na stronie. Po prostu kliknij pole i zmień je. Ustawmy obok siebie pola „Tytuł” i „Nagłówek”.
Innym przykładem dostosowywania i dostosowywania interfejsu użytkownika strony i jej pól są zależności inputfield. Umożliwiają one określenie warunków, w których określone pole w edytorze stron jest wyświetlane lub wymagane. Sprawmy, aby pole „Nagłówek” było widoczne w interfejsie użytkownika tylko wtedy, gdy użytkownik wprowadzi coś w polu „Tytuł”, a pole „Podsumowanie” jako wymagane tylko wtedy, gdy użytkownik wpisze coś w polu „Nagłówek”:
Oto wideo, które pokazuje, w jaki sposób można wykorzystać zależności inputfield do poprawy doświadczenia użytkownika podczas pracy z ProcessWire:
Liczba, kolejność i wygląd pól na stronie są całkowicie pod Twoją kontrolą. Możesz umieścić tylko jedno pole w szablonie, w ogóle żadnego (niezbyt przydatne) lub więcej niż 50 pól, 100 lub nawet więcej. Możesz je zamówić w dowolny sposób, określić, które są wymagane lub widoczne, a które nie oraz w jakich okolicznościach mają być wymagane lub widoczne. W tym miejscu błyszczy nieocenione podejście ProcessWire.
Podsumowanie: strony, pola, szablony
Podsumujmy techniczne relacje między stronami, polami i szablonami: dodajesz pola do szablonów i wybierasz szablon podczas tworzenia nowej strony. Pola, które widzisz podczas edycji strony, to pola dodane przez Ciebie do wybranego szablonu.
Innym sposobem spojrzenia na to jest analogia ze świata programowania:
- Szablony są jak zajęcia.
- Pola są jak właściwości klas.
- Strony są instancjami klas.
Kiedy już zinternalizujesz te koncepcje, będziesz wyposażony we wszystko, co musisz wiedzieć, aby rozwijać się w ProcessWire. Powodem tego jest to, że filozofia ProcessWire opiera się wyłącznie na tych trzech koncepcjach. Całkiem fajnie, prawda?
Pliki szablonów i API: para przeznaczona do bycia razem
Miejscem, w którym pobierasz dane wprowadzone do zaplecza ProcessWire i wyprowadzasz je na interfejsie, jest oczywiście system plików — a dokładniej folder /site/templates/ instalacji ProcessWire. Z szablonem może być powiązany fizyczny plik PHP o tej samej nazwie; więc szablon home miałby plik home.php w folderze /site/templates/ .
Uwaga: sposób tworzenia plików szablonów zależy wyłącznie od Ciebie. Jeśli znasz styl WordPressa, możesz kontynuować, tak jak przywykłeś. Lub, jeśli masz dość złożoną i dużą konfigurację i chcesz stworzyć bardziej wyrafinowaną architekturę, możesz użyć podejścia inspirowanego MVC, które działałoby równie dobrze. Ryan Cramer ma całkiem niezły samouczek wprowadzający, zatytułowany „Jak ustrukturyzować pliki szablonów”, w którym można nauczyć się różnych podejść do tworzenia plików szablonów w ProcessWire.
Kod, który piszesz w pliku szablonu, składa się głównie z podstawowych konstrukcji PHP (warunki if , pętle foreach , instrukcje echo ), znaczniki HTML i API ProcessWire. Interfejs API jest mocno inspirowany jQuery — tak naprawdę przypomina iterację i przechodzenie zawartości wprowadzonej w zapleczu za pomocą metod, selektorów i możliwości tworzenia łańcuchów (płynny interfejs). Jest łatwy w użyciu i bardzo wyrazisty, podobnie jak jQuery.
Zacznijmy od przyjrzenia się kilku prostym przykładom, które pomogą Ci zacząć korzystać z interfejsu API. Ale zanim zaczniemy, pamiętaj, aby dodać zakładkę do ściągawki API ProcessWire, pomocnej referencji z przeglądem wszystkich dostępnych metod API.
Pierwszą rzeczą, którą chcemy zrobić, jest uzyskanie dostępu i wyświetlenie zawartości pola strony. API udostępnia zmienną, która pozwala nam sobie z tym poradzić: $page .
Pobieranie bieżącej strony ze zmienną $page
Zmienna $page zawiera wszystkie pola pojedynczej strony. Obejmuje to pola wbudowane (takie jak nazwa szablonu strony), a także pola dodane przez programistę do szablonu strony.
Otwórzmy home.php , który jest plikiem szablonu szablonu home i dodajmy do niego następującą linię:
echo $page->title;To każe ProcessWire pobrać pole „Tytuł” strony, na której aktualnie się znajdujemy („Strona główna”) i wyprowadzić ją. Załóżmy, że na stronie mamy również pole „Nagłówek”, którego chcemy użyć zamiast pola „Tytuł”, ale tylko wtedy, gdy użytkownik coś w nim wprowadził.
echo $page->get("headline|title"); Użyliśmy metody get , aby uzyskać dostęp do pola strony (więc $page->get(“title”) jest w zasadzie odpowiednikiem pierwszego przykładu kodu powyżej) i napisaliśmy “headline|title” w metodzie get . To mówi ProcessWire, aby najpierw sprawdził pole „Nagłówek” i wysłał treść nagłówka. Ale jeśli pole „Nagłówek” jest puste, to pole „Tytuł” jest używane jako zastępcze.
Możliwe jest również użycie zmiennych API w ciągach PHP. Poniższe dwie instrukcje echo do wyprowadzania liczby dzieci strony są równoważne:
echo "This page has " . $page->numChildren . " children pages."; echo "This page has {$page->numChildren} children pages."; Pobierzmy dzieci naszej strony głównej (pamiętaj, że wciąż jesteśmy w home.php ) i wypiszmy je jako listę linków:
echo "<ul>"; foreach ($page->children as $child) { echo "<li><a href='{$child->url}'>{$child->title}</a></li>"; } echo "</ul>"; Innym przykładem pola wbudowanego (takiego jak children i url w powyższym przykładzie) jest iteracja przez wszystkich rodziców strony i tworzenie nawigacji w trybie nawigacyjnym:
echo "<ul>"; foreach ($page->parents as $parent) { echo "<li><a href='{$parent->url}'>{$parent->title}</a></li>"; } // output the page itself at the end echo "<li>{$page->title}</li>"; echo "</ul>"; Na stronie głównej („Home”) to po prostu wyświetli tytuł, ponieważ $page->parents będzie puste.
Wcześniej pokazałem, jak tworzyć miniatury obrazów w GUI administratora. Tworzenie miniaturek można również wykonać programowo za pomocą interfejsu API. Przejrzyjmy wszystkie obrazy przesłane w polu „Obrazy”, utwórzmy duży wariant obrazu o szerokości 600 pikseli z proporcjonalną wysokością i miniaturą o wymiarach 150 × 150 pikseli z określonymi opcjami, takimi jak ustawienia przycinania i jakość obrazu. Na koniec chcemy połączyć obraz miniatury z dużym obrazem. Brzmi skomplikowanie? Nie jest.
$options = array( "quality" => 90, "cropping" => "northwest" ); foreach ($page->images as $image) { $large = $image->width(600); $thumbnail = $image->size(150, 150, $options); echo "<a href='{$large->url}'><img src='{$thumbnail->url}' alt='></a>"; }ProcessWire jest pod tym względem całkiem sprytny, ponieważ tworzy obrazy w dowolnych rozmiarach w locie i przechowuje je w pamięci podręcznej, więc musi tworzyć wersje tylko raz.
Oto ostatni przykład $page , który pokazuje, że interfejs API jest bardzo podobny do interakcji z DOM podczas korzystania z jQuery. Pobierzmy ostatnie dziecko strony nadrzędnej, na której aktualnie się znajdujemy.
$wantedPage = $page->parent->children()->last(); Oprócz zmiennej $page interfejs API udostępnia jeszcze jedną ważną: $pages .
Pobieranie wszystkich stron ze zmienną $pages
Dzięki $pages masz dostęp do wszystkich stron w swojej instalacji ProcessWire. Innymi słowy, zapewnia dostęp do wszystkich treści z dowolnego miejsca .
Na przykład możesz mieć ukrytą (czyli niedostępną w interfejsie) stronę ustawień w swojej instalacji ProcessWire; możesz dodać ustawienia globalne, takie jak tytuł i opis swojej witryny; i możesz uzyskać dostęp do tych obiektów blob zawartości i wyprowadzić je z dowolnego pliku szablonu.
$settings = $pages->get("template=settings"); echo "<h1>{$settings->global_title}</h1>"; echo "<p>{$settings->global_description}</p>";Jednym z typowych przypadków użycia jednej strony tematycznej bloga jest pokazanie wszystkich postów na blogu, w których znajduje się odniesienie do danego tematu. Po prostu napisz to w pliku szablonu tematu:
$pages->find("template=blog-post, topics=$page"); Uwaga: topics to pole w szablonie blog-post , w którym można dodać wszystkie kategorie tematów, które są specyficzne dla wpisu na blogu.
Popracujmy trochę więcej z silnikiem selektora ProcessWire. Pozwólcie, że pokażę wam kilka przykładów, odsyłając was do strony demonstracyjnej ProcessWire, katalogu amerykańskich drapaczy chmur. Witryna demonstracyjna zawiera wiele stron i ma ciekawą architekturę modelu danych (tj. takie elementy jak architekci, miasta, budynki i lokalizacje odwołujące się do siebie) i jest dobrym przykładem użycia, aby pokazać, co można zrobić za pomocą selektorów.
W tym przykładzie znajdują się wszystkie drapacze chmur, które w swojej kopii ciała używają wyrażenia „budowanie państwa imperium”:
$pages->get("template=cities")->find("template=skyscraper, body*=empire state building"); Uwaga: Najpierw otrzymujemy stronę z szablonami cities ; następnie otrzymujemy wszystkie strony z szablonem skyscraper . Powodem, dla którego możemy łączyć metody w ten sposób, jest to, że wszystkie strony drapaczy chmur są podrzędnymi stronami strony „Miasta”.
Znajdźmy wszystkie drapacze chmur autorstwa architektów Adriana Smitha, Erica Kuhne lub Williama Pereira i posortujmy wyniki według wysokości w porządku rosnącym:
$adrian = $pages->get("template=architect, name=adrian-smith"); $eric = $pages->get("template=architect, name=eric-kuhne"); $william = $pages->get("template=architect, name=william-pereira"); $skyscrapers = $pages->find("template=skyscraper, architects=$adrian|$eric|$william, sort=height");Możesz zoptymalizować kod, znajdując wszystkich żądanych architektów w jednym kroku, zamiast w trzech:
$architects = $pages->find("template=architect, name=adrian-smith|eric-kuhne|william-pereira"); $skyscrapers = $pages->find("template=skyscraper, architects=$architects, sort=height"); Uwaga: Metoda get potencjalnie zawsze zwraca jedną stronę; metoda find potencjalnie zawsze zwraca wiele stron.
Możesz dalej korygować kod za pomocą podselektorów (tak, możesz mieć selektory wewnątrz selektorów):
$skyscrapers = $pages->find("template=skyscraper, architects=[name=adrian-smith|eric-kuhne|william-pereira], sort=height");Inne zmienne API
$page i $pages nie są jedynymi zmiennymi API, z którymi możesz pracować. Istnieje wiele innych, takich jak $session (do logowania i wylogowywania użytkowników oraz przekierowywania na inne strony), $user (do nawiązywania połączenia z użytkownikiem aktualnie przeglądającym stronę) i $config (służą do ustawienia specyficzne dla danej instalacji ProcessWire). Spójrzmy na dwa przykłady.
Najpierw przekierujmy użytkownika na stronę główną:
$session->redirect($pages->get("template=home")->url);I zróbmy coś, jeśli aktualny użytkownik jest zalogowany:
if ($user->isLoggedin()) { /* do something */ }Rozszerzanie funkcjonalności ProcessWire o moduły
ProcessWire jest zbudowany na modułowej i łatwo rozszerzalnej architekturze i pokazuje: Każda instalacja składa się z rdzenia ProcessWire (istota ProcessWire, który umożliwia podstawową funkcjonalność) oraz zestawu wstępnie zapakowanych modułów (tzw. modułów rdzeniowych), które znajdują się na górze rdzenia i przedłuż go.
Moduły podstawowe
Niektóre z tych gotowych modułów są domyślnie instalowane i aktywowane, a inne są domyślnie odinstalowywane. Na przykład wbudowany system komentarzy ProcessWire to moduł, który można włączyć lub wyłączyć w dowolnym momencie. Ponadto takie rzeczy, jak pole repeatera , o którym mówiliśmy wcześniej, i wielojęzyczna obsługa treści to w zasadzie tylko moduły, które możesz zainstalować, jeśli potrzebujesz ich w swoim projekcie.
Other examples of neat little core modules are Page Names , which validates text input when you're typing a page name (automatically transforming, say, umlauts like a to ae ), and Page Path History , which keeps track of past URLs where pages have lived and automatically redirects to the new location whenever an old URL is accessed.
Finding and Installing Modules
The official modules repository is the main spot where you can find and download ProcessWire modules. On a module's page, you will find the description and purpose of the module and links to the respective GitHub repository and support forum. Module authors are highly encouraged to post their modules in the official repository because it has the highest visibility and is the place people think of first when they want to find a ProcessWire module.
Installing a module is as easy as dragging the module's files to the /site/modules/ directory and installing it in the admin GUI. There are other ways to install a module, such as by installing the Modules Manager, which enables you to browse (and install) modules without leaving the admin GUI.
Commercial Modules
While most modules are free, there are a few commercial ones, too. The ones being promoted in ProcessWire's store are by the lead developer, Ryan Cramer. There you will find the following modules:
- ProDrafts enables you to maintain separate draft and live versions of any page. It also provides a comparison and diff tool, as well as automatic saving capabilities.
- ProFields are a group of ProcessWire modules that help you manage more data with fewer fields, saving you time and energy.
- ProCache (among other things) provides an impressive performance boost for your website by completely bypassing PHP and MySQL and enabling your web server to deliver pages of your ProcessWire website as if they were static HTML files.
Don't miss the screenshots and videos on the module pages to get a first impression. This is finely executed software.
There are also commercial modules outside of the official website, such as Padloper, an e-commerce platform built on top of ProcessWire. To be fair, what is definitely missing in the ProcessWire cosmos is a way for module authors to easily publish their commercial modules in a centralized spot.
How Do ProcessWire Modules Generally Compare to WordPress Plugins?
The reason why ProcessWire has so fewer modules than WordPress (approximately 400 versus more than 40,000) is not so much because it is less popular (an understatement, of course), but more because the core itself is already so feature-rich that adding a ton of modules to extend it is simply not necessary. For example, you don't need a module to create a gallery slideshow or to get the first child of something or to generate thumbnails. All of that (and much more) is already covered out of the box.
So, whereas in WordPress your typical method of solving a problem would be to search for a plugin, in ProcessWire you would first look to the tools available in core; in 90% of cases, that would provide you with the solution.
What You Can Build With ProcessWire
Because ProcessWire behaves more like a framework than a CMS (the core is actually a framework, and the CMS is an application built on top of it), the use cases for building things with ProcessWire are pretty broad. You may want to check out some websites powered by ProcessWire (especially the most liked websites).
ProcessWire is a good fit if you want to develop a JSON REST API, an image-resizing app for employees, a front end for managing millions of products (scalability is pretty impressive — you can have literally millions of pages on a single installation), a web application for displaying the financial results of companies, a simple blog, a website for a big university, or just a simple one-page informational website.
Where To Go From Here: There's A Lot To Discover
Naturally, a beginner's guide can't talk about everything the tool has to offer. So, here is a short list of other ProcessWire features, facts, links and tools worth mentioning:
- Check out ProcessWire Weekly and ProcessWire's blog to stay up to date on the latest news.
- ProcessWire has built-in caching mechanisms (for example, a template and markup cache).
- Wireshell is a command-line interface for ProcessWire based on the Symphony Console component.
- Security is a top priority for ProcessWire.
- Visit grab.pw (isn't that the coolest domain name ever?) to download the latest stable version of ProcessWire (ZIP file, 10MB).
- ProcessWire has a small and friendly community. The discussion board is the central place to discuss any questions and problems.
- ProcessWire has good multi-language support. The multi-language modules are part of the prepackaged core modules.
- ProcessWire has a transparent roadmap, and development is very active. There is a new minor release nearly every week.
- See what others have to say about ProcessWire in the reviews section and on alternativeTo. There's also an interesting Quora thread titled “How does ProcessWire compare to WordPress.”
- ProcessWire.tv is a searchable collection of ProcessWire tutorial videos.
Streszczenie
ProcessWire is a system that rewards you [for] being curious. We aim to show you how to fish so that you can catch the big fish.
This statement by Ryan Cramer, the creator of ProcessWire, encapsulates what ProcessWire is all about.
I think what resonates with a lot of people is that ProcessWire is a system that goes from simple to complex, not the other way around. It doesn't assume what you want to build, but instead lays a strong, non-opinionated foundation by offering you effective, powerful tools and leaving the rest to you. That conceptual aesthetic has, to me, a certain appeal to it.