
Testowanie potoku 101 do testowania frontend
Opublikowany: 2022-03-10Wyobraź sobie taką sytuację: szybko zbliżasz się do terminu i wykorzystujesz każdą wolną minutę, aby osiągnąć swój cel, jakim jest zakończenie tej złożonej refaktoryzacji, z dużą ilością zmian w plikach CSS. Pracujesz nawet nad ostatnimi krokami podczas jazdy autobusem. Jednak twoje lokalne testy wydają się za każdym razem zawodne i nie możesz ich zmusić do pracy. Twój poziom stresu rośnie .
Rzeczywiście, podobna scena jest w dobrze znanym serialu: pochodzi z trzeciego sezonu serialu telewizyjnego Netflix „Jak sprzedawać narkotyki w Internecie (szybko)”:
Cypress + Vue są prezentowane *W PROGRAMIE NETFLIX TV*
— jess (@_jessicasachs) 7 sierpnia 2021
Jest to komedia zatytułowana „Jak sprzedawać narkotyki (szybko)” i zawiera jedne z najbardziej realistycznych obrazów webdev.
Sezon 3, Odcinek 1 o 20:20 i raz lub dwa wcześniej. pic.twitter.com/ICSAwMxyFB
Można by pomyśleć, że przynajmniej używa testów. Możesz się zastanawiać, dlaczego wciąż jest w niebezpieczeństwie? Jest jeszcze wiele miejsca na poprawę i uniknięcie takiej sytuacji, nawet jeśli piszesz testy. Jak myślisz o monitorowaniu bazy kodu i wszystkich zmian od samego początku? Dzięki temu nie doświadczysz tak przykrych niespodzianek, prawda? Uwzględnienie takich automatycznych procedur testowania nie jest zbyt trudne: stwórzmy ten potok testowy razem od początku do końca.
Chodźmy!
Najpierw najważniejsze: podstawowe terminy
Rutyna budowania może pomóc Ci zachować pewność siebie podczas bardziej złożonej refaktoryzacji, nawet w przypadku małych projektów pobocznych. Nie oznacza to jednak, że musisz być inżynierem DevOps. Niezbędne jest poznanie kilku terminów i strategii, i po to tu jesteś, prawda? Na szczęście jesteś we właściwym miejscu! Zacznijmy od podstawowych pojęć, z którymi wkrótce się spotkasz, mając do czynienia z potokiem testowym dla Twojego projektu front-endowego.
Jeśli przeszukujesz ogólnie świat testów, może się zdarzyć, że natknąłeś się już na termin „CI/CD” jako jeden z pierwszych terminów. Jest skrótem od „Continuous Integration, Continuous Delivery” i „Continuous Deployment” i dokładnie to opisuje: Jak zapewne już słyszałeś, jest to metoda dystrybucji oprogramowania używana przez zespoły programistów do częstszego i bardziej niezawodnego wdrażania zmian w kodzie. CI/CD obejmuje dwa uzupełniające się podejścia, które w dużej mierze opierają się na automatyzacji.
- Ciągła integracja
Jest to termin określający środki automatyzacji służące do wdrażania niewielkich, regularnych zmian w kodzie i łączenia ich we wspólne repozytorium. Ciągła integracja obejmuje etapy tworzenia i testowania kodu.
CD to skrót od „Continuous Delivery” i „Continuous Deployment”, które są pojęciami podobnymi do siebie, ale czasami używanymi w różnych kontekstach. Różnica między nimi tkwi w zakresie automatyzacji:
- Ciągła dostawa
Odnosi się do procesu Twojego kodu, który był już wcześniej testowany, skąd zespół operacyjny może teraz wdrożyć go w środowisku produkcyjnym na żywo. Ten ostatni krok może być jednak ręczny. - Ciągłe wdrażanie
Koncentruje się na aspekcie „wdrożenia”, jak sama nazwa wskazuje. Jest to określenie na w pełni zautomatyzowany proces wydawania zmian deweloperskich z repozytorium aż po produkcję, gdzie klient może z nich korzystać bezpośrednio.
Procesy te mają na celu umożliwienie programistom i zespołom posiadania produktu, który można wydać w dowolnym momencie, jeśli zechcą: mieć pewność, że aplikacja jest stale monitorowana, testowana i wdrażana.
Aby osiągnąć dobrze zaprojektowaną strategię CI/CD, większość ludzi i organizacji stosuje procesy zwane „potokami”. „Pipeline” to słowo, którego używaliśmy już w tym przewodniku, nie wyjaśniając go. Jeśli myślisz o takich rurociągach, nie jest zbyt daleko idące, aby myśleć o rurach służących jako dalekosiężne linie do transportu takich rzeczy jak gaz. Potok w obszarze DevOps działa całkiem podobnie: to oprogramowanie „transportujące” do wdrożenia.
Zaczekaj, to brzmi jak wiele rzeczy do nauczenia się i zapamiętania, prawda? Czy nie rozmawialiśmy o testowaniu? Masz rację: pokrycie całej koncepcji potoku CI/CD zapewni wystarczającą zawartość dla wielu artykułów, a my chcemy zadbać o potok testowy dla małych projektów front-end. Lub brakuje Ci tylko aspektu testowania swoich potoków, przez co koncentrujesz się wyłącznie na procesach ciągłej integracji. Dlatego w szczególności skupimy się na części „Testowanie” rurociągów. Dlatego w tym przewodniku stworzymy „mały” potok testowy.
W porządku, więc skupiamy się na „części testowej”. W tym kontekście, jakie testy już znasz i na pierwszy rzut oka przychodzą Ci na myśl? Jeśli myślę o testowaniu w ten sposób, spontanicznie myślę o następujących rodzajach testów:
- Testowanie jednostkowe to rodzaj testu, w którym drobne testowalne części lub jednostki aplikacji, zwane jednostkami, są indywidualnie i niezależnie testowane pod kątem prawidłowego działania.
- Testowanie integracyjne koncentruje się na interakcji między komponentami lub systemami. Ten rodzaj testowania oznacza, że sprawdzamy wzajemne oddziaływanie jednostek i ich współpracę.
- Testowanie end-to-end lub testowanie E2E oznacza, że rzeczywiste interakcje użytkownika są symulowane przez komputer; w ten sposób testowanie E2E powinno obejmować jak najwięcej obszarów funkcjonalnych i części stosu technologicznego używanego w aplikacji.
- Testy wizualne to proces sprawdzania widocznych wyników aplikacji i porównywania ich z oczekiwanymi wynikami. Innymi słowy, pomaga znaleźć „błędy wizualne” w wyglądzie strony lub ekranu różniące się od błędów czysto funkcjonalnych.
- Analiza statyczna nie jest dokładnym testowaniem, ale myślę, że należy o tym wspomnieć tutaj. Możesz sobie wyobrazić, że działa to jak korekta pisowni: debuguje kod bez uruchamiania programu i wykrywa problemy ze stylem kodu. Ten prosty środek może zapobiec wielu błędom.
Aby mieć pewność połączenia ogromnej refaktoryzacji w naszym unikalnym projekcie, powinniśmy rozważyć użycie wszystkich tych typów testów w naszym potoku testowym. Ale zaczynanie od przewagi szybko prowadzi do frustracji: możesz czuć się zagubiony w ocenie tego typu testów. Od czego powinienem zacząć? Ile testów, których typy są rozsądne?
Strategia: piramidy i trofea
Musimy popracować nad strategią testowania, zanim zaczniemy budować nasz potok. Szukając wcześniej odpowiedzi na wszystkie te pytania, możliwe rozwiązanie możesz znaleźć w niektórych metaforach: w sieci, a konkretnie w społecznościach testujących, ludzie mają tendencję do używania analogii, aby dać ci wyobrażenie o tym, ile testów powinieneś użyć jakiego typu.
Pierwszą metaforą, na którą prawdopodobnie natkniesz się, jest piramida automatyzacji testów. Mike Cohn wymyślił tę koncepcję w swojej książce „Succeeding with Agile”, rozwiniętej dalej jako „Praktyczna piramida testowa” Martina Fowlera. To wygląda tak:
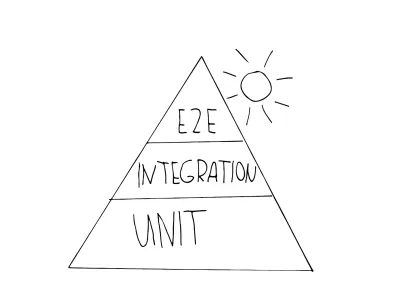
Jak widać, składa się on z trzech poziomów, które odpowiadają trzem przedstawionym poziomom testu. Piramida ma na celu wyjaśnienie właściwej kombinacji różnych testów, aby poprowadzić Cię podczas opracowywania strategii testowej:
- Jednostka
Testy te znajdują się na warstwie podstawowej piramidy, ponieważ są szybkie w wykonaniu i łatwe w utrzymaniu. Wynika to z ich izolacji i faktu, że celują w najmniejsze jednostki. Zobacz ten przykład typowego testu jednostkowego testującego bardzo mały produkt. - Integracja
Znajdują się one w środku piramidy, ponieważ nadal są akceptowalne, jeśli chodzi o szybkość wykonania, ale nadal dają pewność, że są bliżej użytkownika niż testy jednostkowe. Przykładem testu typu integracyjnego jest test API, również testy komponentowe można uznać za tego typu. - Testy E2E (zwane również testami UI )
Jak widzieliśmy, testy te symulują prawdziwego użytkownika i jego interakcję. Testy te wymagają więcej czasu na wykonanie, a co za tym idzie są droższe — są umieszczane na szczycie piramidy. Jeśli chcesz sprawdzić typowy przykład testu E2E, przejdź do tego.
Jednak w ostatnich latach ta metafora wydawała się nieaktualna. W szczególności jedna z jego wad jest dla mnie kluczowa: w tej strategii pomijane są analizy statyczne. Użycie naprawiaczy w stylu kodu lub innych rozwiązań lintingowych nie jest brane pod uwagę w tej metaforze, co moim zdaniem jest ogromną wadą. Lint i inne narzędzia do analizy statycznej są integralną częścią używanego potoku i nie należy ich ignorować.
Więc skróćmy to: powinniśmy zastosować bardziej zaktualizowaną strategię. Ale brakujące narzędzia do lintingu to nie jedyna wada — jest jeszcze ważniejszy punkt do rozważenia. Zamiast tego możemy nieco przesunąć nasze skupienie: poniższy cytat podsumowuje to całkiem dobrze:
„Napisz testy. Nie zbyt dużo. Przede wszystkim integracja.”
— Guillermo Rauch
Rozłóżmy ten cytat, aby się o tym dowiedzieć:
- Napisz testy
Całkiem oczywiste — zawsze powinieneś pisać testy. Testy mają kluczowe znaczenie dla wzbudzenia zaufania w Twojej aplikacji — zarówno dla użytkowników, jak i programistów. Nawet dla siebie! - Nie zbyt dużo
Pisanie testów losowo nigdzie Cię nie zaprowadzi; piramida testowa jest nadal ważna w swoim oświadczeniu, aby zachować priorytety testów. - Głównie integracja
Atutem bardziej „kosztownych” testów, które piramida ignoruje, jest to, że zaufanie do testów wzrasta wraz ze wzrostem piramidy. Ten wzrost oznacza, że zarówno użytkownik, jak i Ty jako programista, najprawdopodobniej zaufa tym testom.
Oznacza to, że powinniśmy iść na testy, które są z założenia bliższe użytkownikowi. W rezultacie możesz zapłacić więcej, ale zyskujesz z powrotem dużą wartość. Możesz się zastanawiać, dlaczego nie wybrać testu E2E? Skoro naśladują użytkowników, czyż nie są najbliżej użytkownika? To prawda, ale nadal działają one znacznie wolniej i wymagają pełnego stosu aplikacji. Tak więc ten zwrot z inwestycji osiąga się później niż w przypadku testów integracyjnych: w konsekwencji testy integracyjne zapewniają odpowiednią równowagę między zaufaniem z jednej strony a szybkością i wysiłkiem z drugiej.
Jeśli śledzisz Kent C.Dodds, te argumenty mogą brzmieć znajomo, zwłaszcza jeśli czytasz ten artykuł w szczególności. Te argumenty nie są przypadkiem: w swojej pracy wymyślił nową strategię. Zdecydowanie zgadzam się z jego punktami i łączę najważniejszą tutaj i inne w sekcji zasobów. Jego sugerowane podejście wywodzi się z piramidy testowej, ale podnosi ją na inny poziom, zmieniając jej kształt, aby odzwierciedlić wyższy priorytet testów integracyjnych. Nazywa się „Trofeum testowe”.
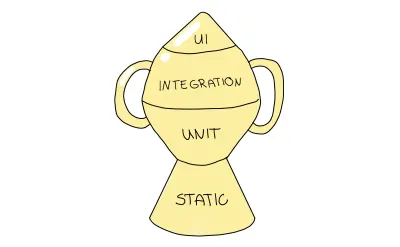
Trofeum testowe to metafora przedstawiająca szczegółowość testów w nieco inny sposób; powinieneś podzielić swoje testy na następujące typy testów:
- Analiza statyczna odgrywa w tej metaforze istotną rolę. W ten sposób złapiesz literówki, błędy typograficzne i inne błędy, wykonując jedynie wspomniane kroki debugowania.
- Testy jednostkowe powinny zapewnić, że najmniejsza jednostka jest odpowiednio przetestowana, ale trofeum testowe nie podkreśli ich w takim samym stopniu, jak piramida testowa.
- Integracja jest głównym celem, ponieważ w najlepszy sposób równoważy koszty i większą pewność.
- Testy interfejsu użytkownika , w tym testy E2E i wizualne, znajdują się na szczycie trofeum testowego, podobnie jak ich rola w piramidzie testowej.
Wybrałem tę strategię trofeum testowego w większości moich projektów i będę to kontynuował w tym przewodniku. Muszę jednak tutaj trochę zabronić: Oczywiście mój wybór opiera się na projektach, nad którymi pracuję na co dzień. Zatem korzyści i wybór dopasowanej strategii testowania są zawsze zależne od projektu, nad którym pracujesz. Więc nie czuj się źle, jeśli nie pasuje to do twoich potrzeb, dodam zasoby do innych strategii w odpowiednim akapicie.
Drobny spoiler: W pewnym sensie będę musiał odejść od tej koncepcji, jak wkrótce zobaczysz. Myślę jednak, że to w porządku, ale za chwilę do tego dojdziemy. Chodzi mi o zastanowienie się nad priorytetyzacją i dystrybucją typów testów przed planowaniem i wdrażaniem potoków.
Jak zbudować te rurociągi online (szybko)
Bohater trzeciego sezonu serialu telewizyjnego Netflix „Jak sprzedawać narkotyki online (szybko)” jest pokazany przy użyciu Cypressa do testów E2E tuż przed terminem, jednak tak naprawdę były to tylko testy lokalne. Nie było widać żadnego CI/CD, co powodowało u niego niepotrzebny stres. Powinniśmy unikać presji danego protagonisty w odpowiednich odcinkach z wyuczoną teorią. Jak jednak możemy zastosować te wnioski do rzeczywistości?
Przede wszystkim potrzebujemy na początek bazy kodu jako podstawy testów. Najlepiej byłoby, gdyby był to projekt, z którym spotka się wielu z nas, programistów front-end. Jego przypadek użycia powinien być częsty, ponieważ dobrze nadaje się do praktycznego podejścia i umożliwia nam wdrożenie potoku testowego od zera. Czym mógłby być taki projekt?
Moja sugestia dotycząca pierwotnego rurociągu
Pierwsza rzecz, jaka przyszła mi do głowy, była oczywista: moja witryna internetowa, tj. strona z moim portfolio, dobrze nadaje się do uznania za przykładową bazę kodu do przetestowania przez nasz aspirujący potok. Jest opublikowany jako open source na Github, więc możesz go swobodnie przeglądać i używać. Kilka słów o stosie technologicznym witryny: Zasadniczo zbudowałem tę witrynę na Vue.js (niestety nadal w wersji 2, kiedy pisałem ten artykuł) jako framework JavaScript z Nuxt.js jako dodatkowym frameworkiem internetowym. Kompletny przykład implementacji można znaleźć w jego repozytorium GitHub.
Po wybraniu naszej przykładowej bazy kodu powinniśmy zacząć stosować nasze wnioski. Biorąc pod uwagę fakt, że chcemy wykorzystać trofeum testowe jako punkt wyjścia dla naszej strategii testowej, wpadłem na następującą koncepcję:
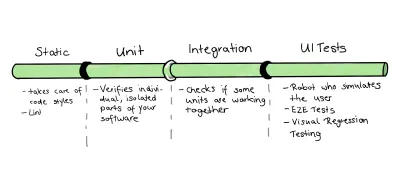
Ponieważ mamy do czynienia ze stosunkowo niewielką bazą kodu, połączę części testów jednostkowych i integracyjnych. Jednak to tylko jeden mały powód, aby to zrobić. Inne i ważniejsze powody to:
- Definicja jednostki jest często „do omówienia”: jeśli poprosisz grupę programistów o zdefiniowanie jednostki, w większości otrzymasz różne, różniące się odpowiedzi. Ponieważ niektórzy odnoszą się do funkcji, klasy lub usługi — pomniejszych jednostek — inny programista będzie liczył się w kompletnym komponencie.
- Oprócz tych problemów z definicją, wytyczenie granicy między jednostką a integracją może być trudne, ponieważ jest bardzo rozmyte. Ta walka jest prawdziwa, szczególnie w przypadku Frontendu, ponieważ często potrzebujemy DOM, aby pomyślnie zweryfikować podstawę testów.
- Zazwyczaj do pisania obu testów integracyjnych można użyć tych samych narzędzi i bibliotek. Więc możemy być w stanie zaoszczędzić zasoby, łącząc je.
Wybrane narzędzie: akcje GitHub
Ponieważ wiemy, co chcemy przedstawić w potoku, następnym krokiem jest wybór platformy ciągłej integracji i dostarczania (CI/CD). Wybierając taką platformę do naszego projektu, myślę o tych, z którymi już zdobyłem doświadczenie:
- GitLab, przez codzienną rutynę w moim miejscu pracy,
- GitHub Actions w większości moich projektów pobocznych.
Istnieje jednak wiele innych platform do wyboru. Sugerowałbym, aby zawsze opierać swój wybór na swoich projektach i ich specyficznych wymaganiach, biorąc pod uwagę zastosowane technologie i frameworki — tak, aby nie wystąpiły problemy z kompatybilnością. Pamiętaj, używamy projektu Vue 2, który został już wydany na GitHub, przypadkowo pasujący do mojego wcześniejszego doświadczenia. Ponadto wspomniane akcje GitHub wymagają jedynie repozytorium GitHub twojego projektu jako punktu wyjścia; aby utworzyć i uruchomić przepływ pracy GitHub Actions specjalnie dla niego. W związku z tym w tym przewodniku przejdę do akcji GitHub.
Tak więc te akcje GitHub zapewniają platformę do uruchamiania specjalnie zdefiniowanych przepływów pracy, jeśli mają miejsce określone zdarzenia. Zdarzenia te to konkretne działania w naszym repozytorium, które uruchamiają przepływ pracy, np. wypychanie zmian do gałęzi. W tym przewodniku te zdarzenia są powiązane z CI/CD, ale takie przepływy pracy mogą również zautomatyzować inne przepływy pracy, takie jak dodawanie etykiet do żądań ściągnięcia. GitHub może je uruchamiać na maszynach wirtualnych Windows, Linux i macOS.
Aby zwizualizować taki przepływ pracy, wyglądałoby to tak:
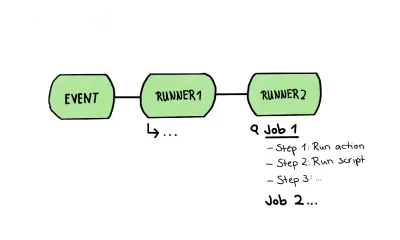
W tym artykule użyję jednego przepływu pracy, aby zobrazować jeden potok; oznacza to, że jeden przepływ pracy będzie zawierał wszystkie nasze etapy testowania, od analizy statycznej po wszelkiego rodzaju testy interfejsu użytkownika. Ten potok, nazywany w następnych akapitach „przepływem pracy”, będzie składał się z jednego lub nawet większej liczby zadań, które są zbiorem kroków wykonywanych na tym samym module uruchamiającym.

Ten przepływ pracy jest dokładnie taką strukturą, jaką chciałem naszkicować na powyższym rysunku. W nim przyjrzymy się bliżej takiemu biegaczowi zawierającemu wiele zadań; Same kroki pracy składają się z różnych kroków. Te kroki mogą być jednego z dwóch typów:
- Krok może uruchomić prosty skrypt.
- Krok może być w stanie uruchomić akcję. Takie działanie jest rozszerzeniem wielokrotnego użytku i często jest kompletną, niestandardową aplikacją.
Mając to na uwadze, rzeczywisty przepływ pracy akcji GitHub wygląda tak:
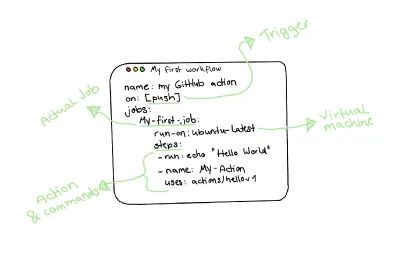
Pisanie naszej pierwszej akcji na GitHubie
Wreszcie możemy napisać naszą pierwszą własną akcję na Github i napisać trochę kodu! Zaczniemy od naszego podstawowego przepływu pracy i naszego pierwszego zarysu prac, które chcemy przedstawić. Pamiętając o naszym trofeum testowym, każda praca będzie przypominała jedną warstwę w trofeum testowym. Kroki będą tym, co musimy zrobić, aby zautomatyzować te warstwy.
Dlatego tworzę .github/workflows/ , aby najpierw przechowywać nasze przepływy pracy. Stworzymy nowy plik o nazwie tests.yml , który będzie zawierał nasz przepływ pracy testowej w tym katalogu. Oprócz standardowej składni przepływu pracy widocznej na powyższym rysunku, postąpię w następujący sposób:
- Nazwę nasz przepływ pracy
Tests CI. - Ponieważ chcę wykonać mój przepływ pracy przy każdym wypchnięciu do moich zdalnych gałęzi i zapewnić ręczną opcję uruchomienia mojego potoku, skonfiguruję przepływ pracy tak, aby działał na
pushiworkflow_dispatch. - Wreszcie, jak stwierdzono w akapicie „Moja sugestia dotycząca podstawowego potoku”, mój przepływ pracy będzie zawierał trzy zadania:
-
static-eslintdo analizy statycznej; -
unit-integration-jestdla testów jednostkowych i integracyjnych połączonych w jednym zadaniu; -
ui-cypressjako etap UI, w tym podstawowy test E2E i wizualne testy regresji.
-
- Maszyna wirtualna oparta na Linuksie powinna wykonywać wszystkie zadania, więc przejdę do
ubuntu-latest.
Wstaw poprawną składnię pliku YAML , pierwszy zarys naszego przepływu pracy może wyglądać tak:
name: Tests CI on: [push, workflow_dispatch] # On push and manual jobs: static-eslint: runs-on: ubuntu-latest steps: # 1 steps unit-integration-jest: runs-on: ubuntu-latest steps: # 1 step ui-cypress: runs-on: ubuntu-latest steps: # 2 steps: e2e and visualJeśli chcesz zagłębić się w szczegóły dotyczące przepływów pracy w akcji GitHub, możesz w dowolnym momencie przejść do jego dokumentacji. Tak czy inaczej, bez wątpienia zdajesz sobie sprawę, że wciąż brakuje kroków. Nie martw się — też jestem tego świadomy. Aby więc ożywić ten zarys przepływu pracy, musimy zdefiniować te kroki i zdecydować, których narzędzi testowych i frameworków użyć w naszym małym projekcie portfelowym. Wszystkie nadchodzące akapity opisują odpowiednie zadania i zawierają kilka kroków, aby umożliwić automatyzację wspomnianych testów.
Analiza statyczna
Jak sugeruje trofeum testowe, zaczniemy od linterów i innych naprawiaczy kodu w naszym przepływie pracy. W tym kontekście możesz wybierać spośród wielu narzędzi, a niektóre przykłady obejmują te:
- Eslint jako naprawiacz stylu kodu JavaScript.
- Stylelint do naprawy kodu CSS.
- Możemy rozważyć pójście jeszcze dalej, np. do analizy złożoności kodu można przyjrzeć się narzędziom takim jak scrutinizer.
Te narzędzia łączy to, że wskazują błędy we wzorcach i konwencjach. Należy jednak pamiętać, że niektóre z tych zasad to kwestia gustu. Od Ciebie zależy, jak surowo chcesz je egzekwować. Aby wymienić przykład, jeśli zamierzasz tolerować wcięcie dwóch lub czterech tabulatorów. O wiele ważniejsze jest skupienie się na wymaganiu spójnego stylu kodu i wykrywaniu bardziej krytycznych przyczyn błędów, takich jak używanie „==” vs. „===”.
W przypadku naszego projektu portfolio i tego przewodnika chcę rozpocząć instalację Eslint, ponieważ używamy dużo JavaScriptu. Zainstaluję go za pomocą następującego polecenia:
npm install eslint --save-dev Oczywiście mogę również użyć alternatywnego polecenia z menedżerem pakietów Yarn, jeśli wolę nie używać NPM. Po instalacji muszę utworzyć plik konfiguracyjny o nazwie .eslintrc.json . Użyjmy na razie podstawowej konfiguracji, ponieważ ten artykuł nie nauczy Cię przede wszystkim, jak skonfigurować Eslint:
{ "extends": [ "eslint:recommended", ] } Jeśli chcesz szczegółowo poznać konfigurację Eslint, przejdź do tego przewodnika. Następnie chcemy wykonać nasze pierwsze kroki, aby zautomatyzować wykonanie Eslint. Na początek chcę ustawić polecenie wykonywania Eslint jako skryptu NPM. Osiągam to za pomocą tego polecenia w naszym pliku package.json w sekcji script :
"scripts": { "lint": "eslint --ext .js .", }, Następnie mogę wykonać ten nowo utworzony skrypt w naszym przepływie pracy GitHub. Jednak zanim to zrobimy, musimy upewnić się, że nasz projekt jest dostępny. Dlatego używamy wstępnie skonfigurowanych akcji GitHub Action actions/checkout@v2 , które dokładnie to robią: Sprawdzamy nasz projekt, aby przepływ pracy Twojej akcji GitHub miał do niego dostęp. Następnym krokiem byłoby zainstalowanie wszystkich zależności NPM, których potrzebujemy do mojego projektu portfela. Po tym jesteśmy w końcu gotowi do uruchomienia naszego skryptu eslint! Nasza ostatnia praca polegająca na użyciu lintingu wygląda teraz tak:
static-eslint: runs-on: ubuntu-latest steps: # Action to check out my codebase - uses: actions/checkout@v2 # install NPM dependencies - run: npm install # Run lint script - run: npm run lint Możesz się teraz zastanawiać: czy ten potok automatycznie „nie powiedzie się”, gdy nasz npm run lint w nieudanym teście? Tak, to działa po wyjęciu z pudełka. Jak tylko skończymy pisać nasz przepływ pracy, przyjrzymy się zrzutom ekranu na Github.
Jednostka i integracja
Następnie chcę stworzyć naszą pracę zawierającą kroki jednostkowe i integracyjne. Jeśli chodzi o framework użyty w tym artykule, chciałbym przedstawić Wam framework Jest do testowania frontendu. Oczywiście nie musisz używać Jesta, jeśli nie chcesz — istnieje wiele alternatyw do wyboru:
- Cypress zapewnia również testowanie komponentów, które są dobrze dostosowane do testów integracyjnych.
- Jasmine to kolejny framework, któremu warto się przyjrzeć.
- A jest ich znacznie więcej; Chciałem tylko wymienić kilka.
Jest dostarczany jako open-source przez Facebook. Framework przypisuje nacisk na prostotę, a jednocześnie jest kompatybilny z wieloma frameworkami i projektami JavaScript, w tym Vue.js, React lub Angular. Jestem również w stanie używać żartów w parze z TypeScript. To sprawia, że framework jest bardzo interesujący, szczególnie dla mojego małego projektu portfolio, ponieważ jest kompatybilny i dobrze dopasowany.
Możemy rozpocząć instalację Jest bezpośrednio z tego folderu głównego mojego projektu portfolio, wpisując następujące polecenie:
npm install --save-dev jest Po instalacji mogę już zacząć pisać testy. Jednak ten artykuł koncentruje się na automatyzacji tych testów za pomocą akcji Github. Aby dowiedzieć się, jak napisać test jednostkowy lub test integracyjny, zapoznaj się z poniższym przewodnikiem. Konfigurując pracę w naszym przepływie pracy, możemy postępować podobnie do pracy static-eslint . Tak więc pierwszym krokiem jest ponowne utworzenie małego skryptu NPM do wykorzystania w naszej pracy później:
"scripts": { "test": "jest", }, Następnie zdefiniujemy zadanie nazwane unit-integration-jest podobnie do tego, co już wcześniej zrobiliśmy dla naszych linterów. Tak więc workflow sprawdzi nasz projekt. Oprócz tego użyjemy dwóch drobnych różnic w stosunku do naszej pierwszej pracy static-eslint :
- Użyjemy akcji jako kroku do zainstalowania Node.
- Następnie użyjemy naszego nowo utworzonego skryptu npm do uruchomienia naszego testu Jest.
W ten sposób nasza praca unit-integration-jest będzie wyglądać tak:
unit-integration-jest: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 # Set up node - name: Run jest uses: actions/setup-node@v1 with: node-version: '12' - run: npm install # Run jest script - run: npm testTesty interfejsu użytkownika: E2E i testy wizualne
Na koniec napiszemy naszą pracę ui-cypress , która będzie zawierała zarówno testy E2E, jak i testy wizualne. Sprytnie jest połączyć te dwie rzeczy w jednym zadaniu, ponieważ będę używał frameworka Cypress do obu. Oczywiście możesz rozważyć inne frameworki, takie jak te poniżej, NightwatchJS i CodeceptJS.
Ponownie omówimy tylko podstawy konfiguracji w naszym przepływie pracy GitHub. Jeśli chcesz dowiedzieć się, jak szczegółowo pisać testy Cypressa, przygotowałem dla Ciebie kolejny z moich poradników, który dokładnie to opisuje. Ten artykuł poprowadzi Cię przez wszystko, czego potrzebujemy, aby zdefiniować nasze etapy testowania E2E. W porządku, najpierw zainstalujemy Cypress, w ten sam sposób, w jaki zrobiliśmy to z innymi frameworkami, używając następującego polecenia w naszym folderze głównym:
npm install --save-dev cypress Tym razem nie musimy definiować skryptu NPM. Cypress już udostępnia nam własną akcję GitHub do użycia, cypress-io/github-action@v2 . W tym miejscu musimy tylko skonfigurować kilka rzeczy, aby uruchomić:
- Musimy upewnić się, że nasza aplikacja jest w pełni skonfigurowana i działa, ponieważ test E2E wymaga pełnego dostępnego stosu aplikacji.
- Musimy nazwać przeglądarkę, w której uruchamiamy nasz test E2E.
- Musimy poczekać, aż serwer WWW zacznie w pełni funkcjonować, aby komputer mógł zachowywać się jak prawdziwy użytkownik.
Na szczęście nasza akcja Cypress pomaga nam przechowywać wszystkie te konfiguracje z obszarem with . W ten sposób nasza obecna praca na GitHubie wygląda tak:
steps: - name: Checkout uses: actions/checkout@v2 # Install NPM dependencies, cache them correctly # and run all Cypress tests - name: Cypress Run uses: cypress-io/github-action@v2 with: browser: chrome headless: true # Setup: Nuxt-specific things build: npm run generate start: npm run start wait-on: 'http://localhost:3000'Testy wizualne: daj trochę oczu na swój test
Zapamiętaj naszą pierwszą intencję napisania tego przewodnika: mam swoją znaczącą refaktoryzację z dużą ilością zmian w plikach SCSS — chcę dodać testowanie jako część procedury budowania, aby upewnić się, że nie zepsuje to niczego innego. Mając analizę statyczną, testy jednostkowe, integracyjne i E2E, powinniśmy być całkiem pewni, prawda? To prawda, ale wciąż jest coś, co mogę zrobić, aby mój rurociąg był jeszcze bardziej kuloodporny i doskonały. Można powiedzieć, że staje się śmietanką. Zwłaszcza w przypadku refaktoryzacji CSS, test E2E może być tylko ograniczony, ponieważ robi tylko to, co powiedziałeś, zapisując to w swoim teście.
Na szczęście istnieje inny sposób na wyłapywanie błędów poza pisanymi poleceniami, a tym samym poza koncepcją. Nazywa się to testami wizualnymi: można sobie wyobrazić, że ten rodzaj testowania jest jak układanka typu „znajdź różnicę”. Technicznie rzecz biorąc, wizualne testy to porównanie zrzutów ekranu, które wykona zrzuty ekranu Twojej aplikacji i porówna je ze status quo, np. z głównej gałęzi Twojego projektu. W ten sposób żaden przypadkowy problem ze stylizacją nie pozostanie niezauważony — przynajmniej w obszarach, w których używasz testów wizualnych. To może zmienić testy wizualne w ratunek dla dużych refaktoryzacji CSS, przynajmniej z mojego doświadczenia.
Do wyboru jest wiele narzędzi do testowania wizualnego, na które warto zwrócić uwagę:
- Percy.io, narzędzie Browserstack, którego używam w tym przewodniku;
- Wizualne śledzenie regresji, jeśli wolisz nie korzystać z rozwiązania SaaS i jednocześnie korzystać z pełnego oprogramowania open source;
- Applitools z obsługą AI. W magazynie Smashing znajduje się ekscytujący przewodnik dotyczący tego narzędzia;
- Chromatyczna według Storybook.
W przypadku tego przewodnika, a przede wszystkim mojego projektu portfelowego, konieczne było ponowne wykorzystanie moich istniejących testów Cypress do testów wizualnych. Jak wspomniano wcześniej, w tym przykładzie użyję Percy'ego ze względu na jego prostotę integracji. Chociaż jest to rozwiązanie SaaS, nadal istnieje wiele części dostarczanych z otwartym kodem źródłowym i istnieje bezpłatny plan, który powinien wystarczyć dla wielu projektów open source lub innych projektów pobocznych. Jeśli jednak czujesz się bardziej komfortowo, korzystając z pełnego samodzielnego hostowania, korzystając również z narzędzia typu open source, możesz spróbować wizualnego śledzenia regresji.
Ten przewodnik da ci tylko krótki przegląd Percy'ego, który w przeciwnym razie dostarczyłby treści do zupełnie nowego artykułu. Jednak udzielę Ci informacji, które pomogą Ci zacząć. Jeśli chcesz teraz zagłębić się w szczegóły, polecam zajrzeć do dokumentacji Percy'ego. Jak więc możemy dać naszym testom oczy, że tak powiem? Załóżmy, że napisaliśmy już jeden lub dwa testy Cypressa. Wyobraź sobie, że wyglądają tak:
it('should load home page (visual)', () => { cy.get('[data-cy=Polaroid]').should('be.visible'); cy.get('[data-cy=FeaturedPosts]').should('be.visible'); });Jasne, jeśli chcemy zainstalować Percy'ego jako nasze rozwiązanie do testowania wizualnego, możemy to zrobić za pomocą wtyczki cypress. Tak jak zrobiliśmy to kilka razy dzisiaj, instalujemy go w naszym folderze głównym za pomocą NPM:
npm install --save-dev @percy/cli @percy/cypress Następnie wystarczy zaimportować pakiet percy/cypress do pliku indeksu cypress/support/index.js :
import '@percy/cypress';Ten import umożliwi Ci użycie polecenia migawki Percy'ego, które zrobi migawkę z Twojej aplikacji. W tym kontekście migawka oznacza zbiór zrzutów ekranu zrobionych z różnych rzutni lub przeglądarek, które możesz skonfigurować.
it('should load home page (visual)', () => { cy.get('[data-cy=Polaroid]').should('be.visible'); cy.get('[data-cy=FeaturedPosts]').should('be.visible'); // Take a snapshot cy.percySnapshot('Home page'); }); Wracając do naszego pliku przepływu pracy, chcę zdefiniować testowanie Percy'ego jako drugi etap pracy. Uruchomimy w nim skrypt npx percy exec -- cypress run , aby uruchomić nasz test razem z Percym. Aby połączyć nasze testy i wyniki z naszym projektem Percy, musimy przekazać nasz token Percy, ukryty za sekretem GitHub.
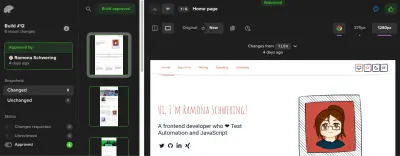
steps: # Before: Checkout, NPM, and E2E steps - name: Percy Test run: npx percy exec -- cypress run env: PERCY_TOKEN: ${{ secrets.PERCY_TOKEN }}Dlaczego potrzebuję tokena Percy? To dlatego, że Percy jest rozwiązaniem SaaS do utrzymywania naszych zrzutów ekranu. Zachowa zrzuty ekranu i status quo do porównania i zapewni nam przepływ pracy zatwierdzania zrzutów ekranu. Tam możesz zatwierdzić lub odrzucić każdą nadchodzącą zmianę:
Przeglądanie naszych prac: integracja z GitHub
Gratulacje! Udało nam się zbudować nasz pierwszy przepływ akcji GitHub. Rzućmy okiem na nasz kompletny plik przepływu pracy w repozytorium strony mojego portfolio. Nie zastanawiasz się, jak to wygląda w praktyce? Możesz znaleźć swoje działające akcje GitHub w zakładce "Akcje" swojego repozytorium:
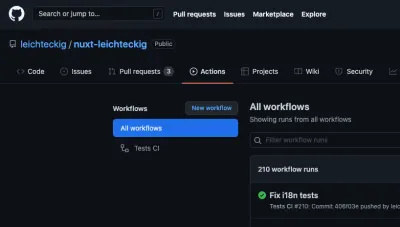
Znajdziesz tam wszystkie przepływy pracy, które są odpowiednikami Twoich plików przepływów pracy. Jeśli spojrzysz na jeden przepływ pracy, np. mój przepływ pracy „Testy CI”, możesz sprawdzić wszystkie jego zadania:
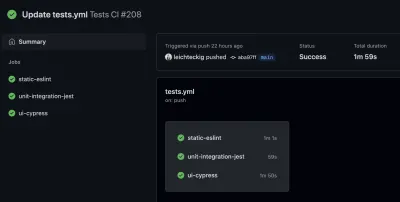
Jeśli chcesz rzucić okiem na jedną ze swoich prac, możesz ją również wybrać na pasku bocznym. Tam możesz sprawdzić dziennik swoich zadań:
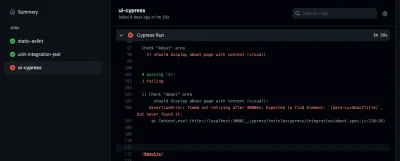
Widzisz, jesteś w stanie wykryć błędy, jeśli wystąpią w twoim potoku. Nawiasem mówiąc, zakładka „akcja” to nie jedyne miejsce, w którym możesz sprawdzić wyniki swoich działań na GitHubie. Możesz je również sprawdzić w swoich żądaniach ściągnięcia:
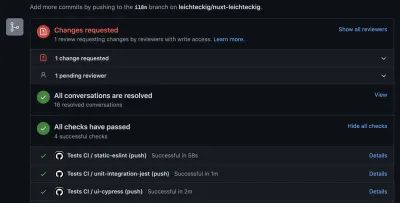
I like to configure those GitHub actions the way they need to be executed successfully: Otherwise, it's not possible to merge any pull requests into my repository.
Wniosek
CI/CD helps us perform even major refactorings — and dramatically minimizes the risk of running into nasty surprises. The testing part of CI/CD is taking care of our codebase being continuously tested and monitored. Consequently, we will notice errors very early, ideally before anyone merges them into your main branch. Plus, we will not get into the predicament of correcting our local tests on the way to work — or even worse — actual errors in our application. I think that's a great perspective, right?
To include this testing build routine, you don't need to be a full DevOps engineer: With the help of some testing frameworks and GitHub actions, you're able to implement these for your side projects as well. I hope I could give you a short kick-off and got you on the right track.
I'm looking forward to seeing more testing pipelines and GitHub action workflows out there! ️.
Zasoby
- An excellent guide on CI/CD by GitHub
- “The practical test pyramid”, Ham Vocke
- Articles on the testing trophy worth reading, by Kent C.Dodds:
- “Write tests. Not too many. Mostly integration”
- “The Testing Trophy and Testing Classifications”
- “Static vs Unit vs Integration vs E2E Testing for Frontend Apps”
- I referred to some examples of the Cypress real world app
- Documentation of used tools and frameworks:
- GitHub actions
- Eslint docs
- Jest dokumentacja
- Dokumentacja cyprysowa
- Percy documentation