
Pieczenie uporządkowanych danych w procesie projektowania
Opublikowany: 2022-03-10Optymalizacja wyszukiwarek (SEO) jest niezbędna dla prawie każdego rodzaju strony internetowej, ale jej niuanse pozostają czymś wyjątkowym. Nawet dzisiaj SEO jest często traktowane jako coś, do czego można się przyczepić po fakcie. Może do pewnego stopnia, ale tak naprawdę nie powinno. Wyszukiwarki stają się coraz mądrzejsze każdego dnia i istnieją sposoby na to, aby strony internetowe również były mądrzejsze.
Podstawy SEO są takie same, jak zawsze: świetne treści wyraźnie oznaczone prędzej czy później zwyciężą — niezależnie od tego, ile osób spróbuje oszukać system. Chodzi o to, że te etykiety są znacznie bardziej wyrafinowane niż kiedyś. Tytuły meta, tekst alternatywny obrazu i linki zwrotne są ważne, ale w 2020 roku są również dość prymitywne. Istnieje jeszcze inny poziom metadanych, z którego obecnie korzysta tylko niewielka część witryn: dane strukturalne.
Wszystkie wyszukiwarki mają ten sam cel: organizowanie zawartości sieci i dostarczanie najbardziej odpowiednich, użytecznych wyników wyszukiwania zapytań. Sposób, w jaki to osiągają, zmienił się ogromnie od czasów Lycos i Ask Jeeves. Sam Google wykorzystuje ponad 200 czynników rankingowych, a to tylko te, o których wiemy.
SEO to obecnie ogromna dziedzina i mówię wam, że uporządkowane dane są naprawdę ważnym czynnikiem do zrozumienia i wdrożenia w nadchodzących latach. To nie tylko zwiększa Twoje szanse na wysoką pozycję w rankingu dla odpowiednich zapytań. Co ważniejsze, pomaga ulepszyć Twoje witryny — otwierając je na wszelkiego rodzaju przydatne doświadczenia internetowe.
Zalecana lektura : Do czego należy SEO w procesie projektowania stron internetowych?
Co to są dane strukturalne?
Dane strukturalne to sposób oznaczania treści na stronach internetowych. Używając słownictwa ze Schema.org, usuwa wiele niejednoznaczności z SEO. Zamiast ufać firmom takim jak Google, Bing, Baidu i DuckDuckGo, aby dowiedzieć się, o czym są Twoje treści, mówisz im. Jest to różnica między wyszukiwarką, która zgaduje , o czym jest strona, a wiedzą na pewno.
Jak ujmuje to Schema.org:
Dodając dodatkowe tagi do kodu HTML swoich stron internetowych — tagi mówiące „Hej, wyszukiwarka, te informacje opisują ten konkretny film, miejsce, osobę lub wideo” — możesz pomóc wyszukiwarkom i innym aplikacjom w lepszym zrozumieniu zawartości i wyświetlaj go w użyteczny, odpowiedni sposób.
Schema.org wystartował w 2011 roku, projekt współdzielony przez Google, Microsoft, Yahoo i Yandex. Innymi słowy, jest to wysiłek „dwupartyjny” — jeśli chcesz. Znaczniki wykraczają poza jedną wyszukiwarkę. Własnymi słowami Schema.org:
„Wspólne słownictwo ułatwia webmasterom i programistom podjęcie decyzji o schemacie i uzyskanie maksymalnych korzyści z ich wysiłków”.
Pod wieloma względami jest bardziej ekspansywnym kuzynem mikroformatów (wprowadzonych około 2005 r.), które osadzają semantykę i dane strukturalne w HTML, głównie z korzyścią dla wyszukiwarek i agregatorów. Chociaż mikroformaty są obecnie nadal obsługiwane, „oficjalny” charakter biblioteki Schema.org sprawia, że jest to bezpieczniejszy zakład na długowieczność.
JSON for Linked Data (JSON-LD) stał się dominującym podstawowym standardem danych strukturalnych, chociaż Microdata i RDFa są również obsługiwane i służą temu samemu celowi. Schema.org zawiera przykłady dla każdego typu w zależności od tego, z czym czujesz się najlepiej.
Jako przykład powiedzmy, że Joe Bloggs pisze recenzję powieści Josepha Hellera z 1961 roku Catch-22 i publikuje ją na swoim blogu. Niestety, Bloggs ma kiepski gust i daje mu dwie z pięciu gwiazdek. Dla osoby przeglądającej stronę ta informacja byłaby zrozumiana bezmyślnie, ale programy komputerowe musiałyby połączyć kilka kropek, aby dojść do tego samego wniosku.
W przypadku danych strukturalnych do kodu <head> strony można dodać następujący znacznik. (Jest to podejście JSON-LD. Mikrodane i RDFa można wykorzystać do wplecenia tych samych informacji w treść <body> ):
<script type="application/ld+json"> { "@context" : "https://schema.org", "@type" : "Book", "name" : "Catch-22", "author" : { "@type" : "Person", "name" : "Joseph Heller" }, "datePublished" : "1961-11-10", "review" : { "@type" : "Review", "author" : { "@type" : "Person", "name" : "Joe Bloggs" }, "reviewRating" : { "@type" : "Rating", "ratingValue" : "2", "worstRating" : "0", "bestRating" : "5" }, "reviewBody" : "A disaster. The worst book I've ever read, and I've read The Da Vinci Code." } } </script>To potwierdza, że strona dotyczy paragrafu 22 , powieści Josepha Hellera opublikowanej 10 listopada 1961 roku. Recenzent został zidentyfikowany, podobnie jak parametry systemu punktacji. Różne schematy można łączyć (lub warstwować), aby opisywać różne rzeczy. Na przykład, dzięki tego typu tagom można jasno określić, że strona jest listą wydarzeń na pokaz filmu na świeżym powietrzu, a film, o którym mowa, to Podwodne życie ze Stevem Zissou Wesa Andersona.
Zalecana literatura : Lepsze badania, lepszy projekt, lepsze wyniki
Dlaczego to ma znaczenie?
Ok, cudownie. Mogę oznaczyć swoją witrynę aż do jej gałek ocznych i będzie wyglądać dokładnie tak samo, ale jakie są korzyści? Moim zdaniem są dwie główne korzyści z umieszczania uporządkowanych danych na stronach internetowych:
- To znacznie ułatwia pracę w wyszukiwarkach.
Potrafią dokładniej indeksować treść, co z kolei oznacza, że mogą ją bardziej bogato prezentować. - Pomaga treściom internetowym być bardziej dokładnym i użytecznym.
Uporządkowane dane zapewniają treść z „komputerowej perspektywy”. Jakość treści jest fantastyczna. Wysokiej jakości treści, które zostały dokładnie otagowane, to marzenie.
Wiesz, kiedy widzisz odlotowe wyniki wyszukiwania zawierające oceny w postaci gwiazdek? To uporządkowane dane. Bogate fragmenty recenzji filmów? Dane strukturalne. Kiedy pojawi się wybór przepisów, składników, czasu przygotowania i tak dalej? Zgadłeś. Zakop się w kodzie dowolnej z tych stron, a gdzieś znajdziesz znacznik. Wyszukiwarki nagradzają witryny za pomocą danych strukturalnych, ponieważ informują je dokładnie, z czym mają do czynienia.
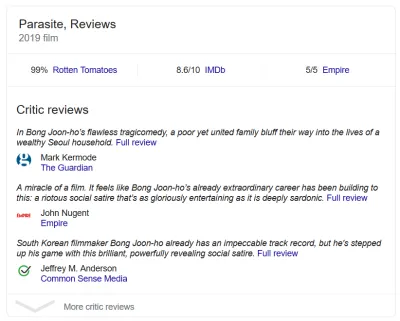
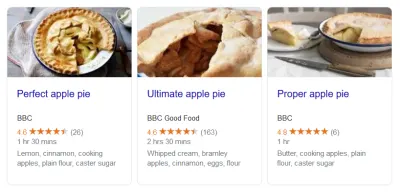
Żeby było jasne, nie chodzi tylko o wyszukiwanie. To duża część, ale to nie wszystko. Uporządkowane dane dotyczą przede wszystkim tagowania i porządkowania treści. Bogate wyniki wyszukiwania to tylko jeden ze sposobów wykorzystania wspomnianych treści. Wyszukiwarka zbiorów danych Google używa na przykład znaczników Schema.org/Dataset.
Poniżej znajduje się garść przykładów przydatnych danych strukturalnych:
- Przepisy
- Opinie
- Często zadawane pytania
- Zapytania głosowe
- Listy wydarzeń
- Akcje zawartości.
Są tysiące innych. Dosłownie. Schema.org przyspieszyło nawet ostatnio wydanie znaczników dla Covid-19. To wciąż rosnąca biblioteka.
Pod wieloma względami dane strukturalne są gałęzią sieci semantycznej, która dąży do w pełni odczytywanego maszynowo Internetu. Zapewnia czytelną dla komputera perspektywę treści internetowych, która (po prawidłowym zaimplementowaniu) prowadzi z powrotem do bogatszych funkcji dla ludzi.
W związku z tym prawie każdy, kto ma witrynę, skorzystałby na wiedzy, czym są dane strukturalne i jak one działają. Według W3Techs tylko 29,6% witryn korzysta z JSON-LD, a 43,2% nie używa w ogóle żadnych formatów danych strukturalnych. Oczywiście nie ma żadnych zobowiązań. Nie wszyscy dbają o SEO lub czytelność maszynową. Z drugiej strony, dla tych, którzy to robią, jest obecnie duża szansa na zjednoczenie konkurencyjnych witryn.
W ten sam sposób, w jaki HTML zmusza Cię do myślenia o tym, jak zorganizowana jest treść, ustrukturyzowane dane skłaniają Cię do myślenia o treści. To sprawia, że jesteś bardziej dokładny. Niezależnie od tego, o czym jest Twoja witryna, jeśli przejrzysz odpowiednią dokumentację schematu, prawie na pewno zauważysz szczegóły, o których wcześniej nie myślałeś.
Jako ludzie, łatwo jest przyjąć za pewnik powiązania między informacjami. Wyszukiwarki i programy komputerowe są sprytne, ale nie są aż tak inteligentne. Jeszcze nie. Uporządkowane dane przekładają treść na terminy, które mogą zrozumieć. To z kolei pozwala im dostarczać bogatsze doświadczenia.
Zasoby i dalsze czytanie
- „Przewodnik dla początkujących po uporządkowanych danych dla SEO: seria dwuczęściowa”, Bridget Randolph, Moz
- „Co to jest znacznik schematu i dlaczego jest ważny dla SEO”, Chuck Price, czasopismo wyszukiwarki
- „Co to jest schemat? Przewodnik dla początkujących po uporządkowanych danych”, Luke Harsel, SEMrush
- „JSON-LD: Budowanie znaczących interfejsów API danych”, Benjamin Young, blog dotyczący wdrażania
- „Zrozumieć, jak działają dane strukturalne”, Wyszukiwarka Google dla programistów
- „Oznaczanie witryny za pomocą uporządkowanych danych”, Bing
Włączanie danych strukturalnych do projektu strony internetowej
Wplatanie uporządkowanych danych do witryny internetowej nie jest tak proste, jak np. zmiana metatytułu. To DNA danych Twojej zawartości internetowej. Jeśli chcesz go właściwie wdrożyć, musisz być gotów zapuścić się w chwasty — przynajmniej trochę. Poniżej znajduje się kilka prostych kroków, które programiści mogą wykonać, aby wpleść uporządkowane dane w proces projektowania.

Uwaga : Osobiście popieram holistyczne podejście do projektowania, w którym design i treść idą w parze. Żonglowanie wieloma dyscyplinami nie jest niczym nowym w projektowaniu stron internetowych, to jest po prostu kolejna, a jeśli jest dobrze wkomponowana, może wzmocnić inne elementy wokół niej. Pomyśl o tym jako o ulepszeniu silnika Twojej witryny. Samochód może nie wygląda aż tak inaczej, ale prowadzi się o wiele lepiej.
Zacznij od koncepcji
Użyję siebie jako przykładu. Od pięciu lat, dwoje przyjaciół i ja, co tydzień recenzujemy album jako hobby (z innymi wkraczającymi od czasu do czasu). Nasza szydercza, nieznośna proza znajduje się obecnie na stronie WordPressa, która — pod moją dobrą, ale całkowicie ignorancką opieką — wyrosła na potwora wtyczek Frankensteina.
Jesteśmy w trakcie przeprojektowywania strony, co (między innymi) wiązało się z wprowadzeniem uporządkowanych danych do głównego projektu. Tutaj, podobnie jak w przypadku każdego innego projektu, pierwszą rzeczą do zrobienia jest ustalenie, o czym jest twoja treść. Im lepiej odpowiesz na to pytanie, tym łatwiejsze będzie wszystko, co nastąpi.
W naszym przypadku najważniejsze są:
- Recenzujemy albumy muzyczne;
- Każda recenzja ma trzech recenzentów, z których każdy pisze podsumowanie, wybierając maksymalnie trzy ulubione utwory i przypisując osobistą ocenę spośród dziesięciu;
- Te trzy wyniki są połączone w końcowy wynik z 30;
- Z tych trzech podsumowań wybierany jest fragment, który służy jako podsumowanie wszystkich naszych myśli.
Niektóre z nich mogą brzmieć nieco konkretnie lub nawet nieco arbitralnie (ponieważ tak jest), ale zdziwiłbyś się, jak wiele z nich można splecić ze sobą za pomocą danych strukturalnych.
Poniżej znajduje się makieta tego, jak będą wyglądać odnowione strony z recenzjami, oraz informacje, które można przełożyć na znaczniki schematu:
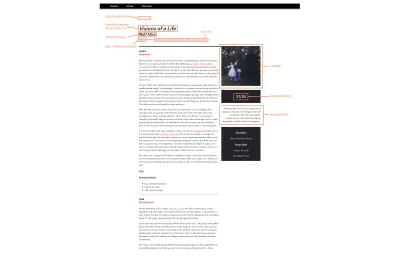
W tym procesie nie ma żadnej sztuczki. Wiem, o czym jest treść, więc wiem, gdzie szukać w dokumentacji. W tym przypadku wchodzę na stronę Schema.org/MusicAlbum i spotykam się z różnymi potencjalnymi właściwościami, w tym:
-
albumReleaseType -
byArtist -
genre -
producer -
datePublished -
recordedAt
Są dziesiątki; niektóre są dostępne wyłącznie w MusicAlbum, inne należą do większego parasola CreativeWork. Zagłębiając się w dokumentację, stwierdzam, że znaczniki mogą łączyć się z MusicBrainz, encyklopedią metadanych muzycznych. Ten sam proces przebiega, gdy przechodzę do dokumentacji recenzji.
Z tej jednej prostej strony można zebrać i uporządkować następujące informacje:
<script type="application/ld+json"> { "@context": "https://schema.org/", "@type": "Review", "reviewBody": "Whereas My Love is Cool was guilty of trying too hard no such thing can be said of Visions. The riffs roar and the melodies soar, with the band playing beautifully to Ellie Rowsell's strengths.", "datePublished": "October 4, 2017", "author": [{ "@type": "Person", "name": "Andre Dack" }, { "@type": "Person", "name": "Frederick O'Brien" }, { "@type": "Person", "name": "Marcus Lawrence" }], "itemReviewed": { "@type": "MusicAlbum", "@id": "https://musicbrainz.org/release-group/7f231c61-20b2-49d6-ac66-1cacc4cc775f", "byArtist": { "@type": "MusicGroup", "name": "Wolf Alice", "@id": "https://musicbrainz.org/artist/3547f34a-db02-4ab7-b4a0-380e1ef951a9" }, "image": "https://lesoreillescurieuses.files.wordpress.com/2017/10/a1320370042_10.jpg", "albumProductionType": "https://schema.org/StudioAlbum", "albumReleaseType": "https://schema.org/AlbumRelease", "name": "Visions of a Life", "numTracks": "12", "datePublished": "September 29, 2017" }, "reviewRating": { "@type": "Rating", "ratingValue": 27, "worstRating": 0, "bestRating": 30 } } </script>I szczerze, mogę jeszcze dodać dużo więcej. Początkowo znalazłem rzeczy, które są już częścią struktury strony z recenzjami (tj. wykonawca, nazwa albumu, ogólna ocena), ale potem zaczęły pojawiać się nowe pytania. Co może być jaśniejszego? Co mogę dodać?
Oczywiście należy to zrównoważyć pytaniami o to, co jest niepotrzebne . To, że możesz coś zrobić, nie oznacza, że powinieneś. Jest coś takiego jak „za dużo informacji”. Jednak czasami trochę więcej szczegółów może naprawdę podnieść stronę o krok.
Zapoznaj się ze schematem
Nie da się tego obejść; najlepszym sposobem na rozkręcenie się jest zagłębienie się w dokumentacji. Istnieją narzędzia, które zaimplementują to za Ciebie (więcej o tych poniżej), ale zyskasz więcej ze znaczników, jeśli będziesz mieć właściwe wyczucie, jak to działa.
Przeszukaj dokumentację Schema.org. Kimkolwiek jesteś i do czego służy Twoja witryna, istnieje duże prawdopodobieństwo, że istnieje wiele odpowiednich schematów. Strona jest bardzo dobra z przykładami, więc nie musi pozostać teoretyczna.
Krokiem dalej jest oczywiście znalezienie rozszerzonych wyników wyszukiwania, które chciałbyś emulować, odwiedzenie strony i użycie narzędzi programistycznych przeglądarki, aby sprawdzić, co robią. Często są doskonałymi przykładami stron internetowych, które znają swoją zawartość od podszewki. Możesz też przesyłać fragmenty kodu lub adresy URL do pomocnika Google do oznaczania danych strukturalnych, który następnie generuje odpowiedni schemat.
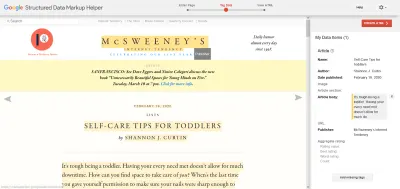
Podstawy są w rzeczywistości bardzo proste. Gdy już je opanujesz, jest to szeroki zakres opcji, które wymagają czasu na zbadanie i zabawę. Nie chcesz być tą osobą, która dobiega końca procesu projektowania, analizuje opcje schematu i zaczyna odgadywać wszystko, co zostało zrobione.
Zadawaj właściwe pytania
Teraz, gdy jesteś uzbrojony w swoją bogatą wiedzę na temat danych strukturalnych, masz lepszą pozycję do położenia fundamentów pod silną witrynę internetową. Ustrukturyzowane dane poruszają się po dość wyjątkowej linii. W sensie bezpośrednim istnieje „pod maską” i jest tam z korzyścią dla komputerów. Jednocześnie może zapewnić użytkownikowi bogatsze doświadczenia.
Dlatego opłaca się patrzeć na dane strukturalne zarówno z perspektywy technicznej, jak i użytkownika. W jaki sposób dane strukturalne mogą pomóc w lepszym zrozumieniu mojej witryny? Jakie inne zasoby, internetowe bazy danych lub sprzęt (np. inteligentne głośniki) mogą być zainteresowane tym, co robisz? Jakie opcje pojawiają się w dokumentacji, których nie uwzględniłem? Czy chcę je dodać?
Szczególnie ważne jest, aby zidentyfikować powtarzające się typy treści. Można śmiało powiedzieć, że blog może z czasem spodziewać się wielu postów na blogu, więc włączenie uporządkowanych danych do szablonów postów przyniesie najlepsze rezultaty. Przykład, który podałem powyżej, sam w sobie jest dobry i dobry, ale nie ma powodu, dla którego proces znaczników nie mógłby zostać zautomatyzowany. Taki jest plan dla nas.
Zastanów się także, w jaki sposób ludzie mogą znaleźć Twoje treści. Jeśli istnieje możliwość, powiedzmy, wyróżnienia fragmentu tekstu do wykorzystania w wyszukiwaniu głosowym, zrób to. To jest to, lub zostaw to wyszukiwarkom, aby same to rozpracowały. Nikt nie zna Twoich treści lepiej niż Ty, więc wykorzystaj to zrozumienie dzięki opisowym znacznikom.
Nie musisz zgadywać, jak treść będzie rozumiana za pomocą uporządkowanych danych. Dzięki narzędziom takim jak Rich Results Tester firmy Google możesz dokładnie zobaczyć, w jaki sposób nadaje treści formę i znaczenie, które w innym przypadku mogłyby zostać przeoczone.
Zasoby i dalsze czytanie
- „Pierwsze kroki ze Schema.org przy użyciu mikrodanych”, Schema.org
- „Repozytorium projektów Schema.org”, społeczność GitHub
- „Pomocnik do oznaczania danych strukturalnych”, Googe Webmasters
- „Dodaj uporządkowane dane do swoich stron internetowych”, Google Developers Codelabs
- „Test wyników z elementami rozszerzonymi”, Google
Wysokiej jakości treść zasługuje na oznaczenie jakości
Nie znajdziesz większego zwolennika świetnych treści niż ja. Branża SEO traci rozsądek za każdym razem, gdy Google wprowadza poważną aktualizację wyszukiwania. Reakcja na histerię jest zawsze taka sama: twórz wysokiej jakości treści. Do tego dodam: odpowiednio to zaznacz.
Zapoznaj się z dokumentacją i jasno określ, o czym jest Twoja witryna. Każda otagowana informacja znacznie ułatwia jej indeksowanie i udostępnianie właściwym osobom.
Niezależnie od tego, czy jesteś wielbicielem Google, czy konwertytą z DuckDuckGo, duch pozostaje taki sam. Nie chodzi o ranking, ale o to, aby strony internetowe były jak najlepsze. Uwzględnienie uporządkowanych danych poprawi inne aspekty Twojej witryny.
Nie musisz ufać technologii, aby zrozumieć, o czym są Twoje treści — możesz to powiedzieć. Od recenzji po przepisy kulinarne i wyszukiwanie audio, programiści mogą dodać zupełnie nowy poziom wyrafinowania do swoich treści.
Serce i dusza optymalizacji strony internetowej pod kątem wyszukiwania nigdy się nie zmieniło: twórz świetne treści i wyjaśniaj, co to jest i dlaczego jest przydatne. Dane strukturalne to kolejne narzędzie do tego celu, więc korzystaj z nich.