
Strategie dla projektów bez głowy z ustrukturyzowanymi systemami zarządzania treścią
Opublikowany: 2022-03-10To jest przewodnik, który chciałbym mieć przez ostatnie kilka lat, kiedy prowadziłem projekty z bezgłowymi systemami zarządzania treścią (CMS). Byłem programistą, konsultantem ds. doświadczeń użytkowników i technologii, kierownikiem projektu, architektem informacji i autorem. Różne czapki uświadomiły mi, że nawet jeśli od jakiegoś czasu mamy tak zwane „bezgłowe” systemy CMS, wciąż jest sposób na zastanowienie się, jak najlepiej z nich korzystać.
Jesteśmy teraz w miejscu, w którym wielu z nas polega na frameworkach JavaScript do pracy frontendowej, używając systemów projektowych złożonych z komponentów i kompozycji, a nie tylko implementując płaskie układy stron. Stosy JAM i aplikacje izomorficzne/uniwersalne, które działają zarówno na serwerze, jak i na kliencie, są bardzo popularne. Ostatnim elementem układanki jest to, jak zarządzamy całą zawartością.
Tradycyjne systemy CMS dodają interfejsy API do obsługi treści za pośrednictwem żądań sieciowych i formatu JSON. Ponadto pojawiły się „bezgłowe” systemy CMS, które służą wyłącznie do obsługi treści za pośrednictwem interfejsów API. Mój argument w tym artykule jest taki, że powinniśmy spędzać mniej czasu na rozmowach o „bezgłowym”, a więcej o „treści strukturalnej” . Bo to jest podstawowa jakość tych systemów. Te systemy niosą ze sobą wiele implikacji dla naszego rzemiosła, a my wciąż pozostajemy do zrobienia, jeśli chodzi o znalezienie dobrych wzorców postępowania z tymi technologiami.
Przechodząc do doradztwa technologicznego z wykształcenia humanistycznego, nauczyłem się wiele o tym, jak organizować i pracować z projektami internetowymi, które przyjmują podejście skoncentrowane na treści — zarówno z nowszymi, opartymi na API, jak i tradycyjnymi CMS-ami. Doceniłem, jak wcześnie zacząłem korzystać z rzeczywistych treści na żywo z CMS; robienie tego w interdyscyplinarnym otoczeniu nie tylko umożliwiło odkrycie złożoności na wcześniejszym etapie, ale także użyczyło zaangażowania wszystkim zaangażowanym i daje możliwość zastanowienia się nad wyzwaniami i możliwościami technologii i projektowania w najszerszym tego słowa znaczeniu.
Bezgłowy WordPress
Wszyscy wiedzą, że jeśli witryna działa wolno, użytkownicy ją porzucają. Przyjrzyjmy się bliżej podstawom tworzenia oddzielonego WordPressa. Przeczytaj powiązany artykuł →
W tym artykule zasugeruję kilka nadrzędnych strategii wraz z konkretnymi przykładami z życia wziętymi, jak myśleć o pracy z treścią ustrukturyzowaną. W chwili pisania tego tekstu właśnie zacząłem pracować dla firmy SaaS, która dostarcza taką usługę zarządzania treścią, do hostingu treści dostarczanych przez API. Będę się do niego nawiązywał, zarówno ze względu na moje dotychczasowe doświadczenia z nim w projektach, w które byłem zaangażowany jako konsultant, ale także dlatego, że uważam, że trafnie ilustruje to, co chcę poruszyć. Potraktuj to więc jako swego rodzaju zastrzeżenie.
Biorąc to pod uwagę, myślałem o napisaniu tego artykułu od kilku lat i starałem się, aby można go było zastosować na dowolnej platformie, z którą się zdecydujesz. Więc bez zbędnych ceregieli cofnijmy się o dwadzieścia lat w czasie, aby lepiej zrozumieć, gdzie jesteśmy dzisiaj.
Pierwsze kroki ze standardami sieciowymi
Na początku XXI wieku ruch Web Standards zainspirował pole do zmiany sposobu pracy. Zgodnie z podejściem „najpierw układ” skierowali naszą uwagę na to, jak treść na stronie powinna być semantycznie oznaczana za pomocą kodu HTML: Menu witryny to nie <table> , to <nav> ; Nagłówek to nie <b> , to <h1> . Był to znaczący krok w kierunku myślenia o różnych rolach, jakie odgrywa sieć, aby pomóc użytkownikom ją znaleźć, zidentyfikować i przyjąć.
Ruch Web Standards przedstawił argument, że znaczniki semantyczne poprawiają dostępność, co również poprawia jego pozycję w wynikach wyszukiwania Google. Oznaczało to również zmianę w sposobie myślenia o treściach internetowych . Twoja witryna nie była już jedynym miejscem, w którym były reprezentowane Twoje treści. Musiałeś także pomyśleć o tym, jak Twoje strony internetowe były prezentowane w innych kontekstach wizualnych, takich jak wyniki wyszukiwania lub czytniki ekranu. Było to później napędzane przez media społecznościowe i wbudowane podglądy udostępnionych linków. Sposób myślenia zmienił się z tego, jak treść powinna wyglądać , na to, co powinna oznaczać . Jest to również klucz do pracy z ustrukturyzowanymi treściami.
Wraz z pojawieniem się kieszonkowych urządzeń podłączonych do Internetu, internet nagle stał się poważnym rywalem w aplikacjach. Konkurencja dotyczyła jednak głównie gałek ocznych użytkownika końcowego. Wiele organizacji nadal musiało rozpowszechniać informacje o swoich produktach i usługach zarówno w swoich aplikacjach, jak i w różnych witrynach internetowych. Jednocześnie sieć dojrzała, a JavaScript i AJAX ułatwiły łączenie różnych źródeł treści za pomocą interfejsów API. Dziś mamy GraphQL i narzędzia, które ułatwiają pobieranie treści i zarządzanie stanem. I tak zaczynają układać się fragmenty technologicznej układanki.
„Twórz raz, publikuj wszędzie”
Chociaż jest to najczęściej opisywane jako „zmiana technologiczna”, osadzanie treści w ładunkach JSON (przemieszczanie się wzdłuż rurek HTTP) ma ogromny wpływ na to, jak myślimy o treściach cyfrowych i otaczających je przepływach pracy. W pewnym sensie już to zrobiło. Prawie dziesięć lat temu gość z National Public Radio (NPR) Daniel Jacobson pisał na blogu programmableweb.com o swoim podejściu, podsumowanym w akronimie COPE, co oznacza „Create Once, Publish Everywhere”. W artykule przedstawia system zarządzania treścią dostarczający treści do wielu interfejsów cyfrowych za pośrednictwem interfejsu API — a nie za pomocą maszyny do renderowania HTML — jak robiła większość systemów CMS w tamtym czasie (i prawdopodobnie teraz).
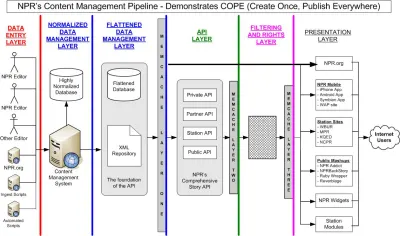
„Warstwa zarządzania danymi” NPR COPE jest tym, co stałoby się pojęciem „bezgłowego CMS”. Na początku COPE udało się to osiągnąć poprzez strukturyzację treści w XML. Obecnie JSON stał się dominującym formatem danych do przesyłania danych przez interfejsy API, w tym urządzenia Internetu rzeczy i inne systemy poza siecią. Jeśli chcesz wymieniać treści z chatbotami, interfejsami głosowymi, a nawet oprogramowaniem do wizualnego prototypowania, bardzo często mówisz HTTP z akcentem JSON.
„Rozbijanie” Termin „bezgłowy CMS”
Według Google Trends wyszukiwania hasła „headless CMS” zyskały na popularności dopiero w 2015 roku, czyli sześć lat po artykule COPE w NPR. Termin „bezgłowy” (przynajmniej w odniesieniu do technologii cyfrowej, a nie francuskiej arystokracji z końca XVIII wieku) jest używany przez dłuższy czas w odniesieniu do systemów, które działają bez graficznego interfejsu użytkownika.
Uwaga : można argumentować, że interfejs wiersza poleceń jest rzeczywiście „graficzny”, tak jak oprogramowanie na serwerach lub środowiskach testowych (ale zostawmy to na inny artykuł).
Mam dwa umysły, nazywając te nowe CMS-y „bezgłowymi”. Równie dobrze moglibyśmy nazwać je „policefalicznymi” – tym, który ma wiele głów. Są to Hydry i Cerbeusy z CMS. „Headless” to także definiowanie tych systemów przez ich brak (tj. silnik szablonów do renderowania stron internetowych), zamiast definiowania ich przez ich prawdziwą siłę: umożliwiając strukturyzację treści bez ograniczeń sieci. Mając to na uwadze, na dzień dzisiejszy wiele rozwiązań w tej kategorii można by również nazwać „Prawie bezgłowym Nick”. Ponieważ interfejs edycji jest nadal ściśle powiązany z systemem. Ich „bezgłowość” wynika z braku silnika szablonów, czyli maszynerii produkującej znaczniki z treści.
Uwaga : prawie na pewno skorzystałbym z systemu CMS o nazwie „Mimsy-Porpington” (znanego z uniwersum Harry'ego Pottera).
Zamiast tego udostępniają zawartość za pośrednictwem interfejsu API, co zapewnia większą elastyczność w zakresie tego, jak, co i gdzie chcesz wyświetlać i używać tej zawartości. To sprawia, że są idealnymi towarzyszami popularnych frontendowych frameworków JavaScript, takich jak React, Angular i Vue. I pomimo twierdzeń o możliwości dostarczania treści do „witryn, aplikacji i urządzeń”, większość z nich jest nadal ograniczona przez sposób działania treści internetowych. Jest to najbardziej widoczne w sposobie, w jaki większość obsługuje tekst sformatowany — przechowując go jako HTML lub Markdown.
Tradycyjne systemy CMS również zaczęły dodawać nieco ogólne interfejsy API oprócz swoich systemów renderowania szablonów i nazywają to „oddzielonym” jako sposób na odróżnienie się od nowych konkurentów. „To wszystko, a także interfejsy API!”* to twierdzenie. Niektóre z tych systemów CMS są również dość agnostyczne, jeśli chodzi o modelowanie treści. Na przykład Craft CMS nie przyjmuje prawie żadnych założeń dotyczących modelu zawartości podczas pierwszej instalacji. Wordpress zmierza również w kierunku używania interfejsów API do dostarczania treści. Podejrzewam, że przepaść między starymi graczami w dziedzinie CMS a nowymi będzie się zmniejszać w miarę postępów.
Niemniej jednak umieszczenie zarządzania treścią za interfejsami API (zamiast renderera HTML) jest ważnym krokiem w kierunku bardziej wyrafinowanych sposobów pracy w epoce, w której tekst, obrazy, filmy i multimedia organizacji są digitalizowane i udostępniane użytkownikom wewnętrznym i zewnętrznym oraz klientom. Nadszedł jednak czas, aby odejść od definiowania ich brakujących możliwości renderowania frontendu do tego, co naprawdę mogą dla nas zrobić: dać nam sposób na pracę z ustrukturyzowaną zawartością . Czy powinniśmy więc nazywać je „strukturyzowanymi systemami zarządzania treścią”? Na przykład „Nie Bob, to nie jest Twój zwykły CMS. To jest SCMS, zaufaj mi, to będzie coś.”
Nie chodzi o głowy, chodzi o uporządkowane treści
Najbardziej radykalną zmianą narzucaną przez systemy zarządzania treścią strukturalną (SCMS) jest odejście od porządkowania treści zgodnie z hierarchią stron do miejsca, w którym możesz dowolnie kształtować treść w dowolnym celu, który uznasz za słuszny. Unikanie powielania treści jest wyraźną zaletą, ponieważ zwiększa niezawodność i zmniejsza obciążenie administracyjne (nie musisz radzić sobie z powielonymi treściami w wielu kanałach). Innymi słowy: twórz raz, publikuj wszędzie . Jeśli musisz zaktualizować opis produktu tylko raz — w jednym systemie — i aktualizuje się on wszędzie tam, gdzie Twój produkt jest widoczny dla użytkownika, jest to wyraźna zaleta.
Podczas gdy dostawcy SCMS często używają „Twojej witryny i aplikacji”, aby uzasadnić inne myślenie o strukturze strony, nie musisz przeprawiać się przez rzekę, aby czerpać korzyści z ustrukturyzowanej struktury treści. Wraz z popularnością frameworków JavaScript coraz częściej buduje się strony internetowe jako kompozycję pojedynczych komponentów, które można „wypełnić” różną treścią w zależności od stanu i kontekstu. Możesz mieć kartę produktu, która pojawia się w wielu różnych kontekstach w Twojej aplikacji internetowej. Widzimy, że współczesne tworzenie stron internetowych odchodzi od ustawiania dokumentów i stron do komponowania komponentów zgodnie z mieszanką danych wejściowych użytkownika, algorytmów i dostosowywania.
Te trendy dotyczące sposobu tworzenia systemów projektowania i zachęcania nas do pracy w zespołach poprzez procesy testowania, uczenia się i iteracji sprawiają, że dziedzina zarządzania treścią dojrzała do nowych sposobów myślenia. Pojawiły się pewne wzorce, ale wciąż mamy wiele do zrobienia. Dlatego opierając się na moim doświadczeniu z pracy w zespołach i projektach, które stawiają na treści na pierwszym miejscu i jako teraz część zespołu, który buduje dla niej usługę (i zachęcam, abyście byli świadomi wszelkich uprzedzeń tutaj), chcę przedstawić kilka strategii, które moim zdaniem mogą być pomocne i stworzyć punkty do dalszej dyskusji.
1. Podejdź do treści w zespołach multidyscyplinarnych
Uważam, że to już przeszłość, kiedy grafik może przekazywać przestarzałe, perfekcyjne co do piksela strony front-end developerowi, którego obowiązkiem było „zaimplementowanie” projektu. Teraz tworzymy systemy projektowe składające się z mniejszych komponentów, ułożonych w kompozycje, które mają wiele możliwych stanów po wyjęciu z pudełka. Częściej niż nie, te komponenty muszą być odporne na dane wejściowe generowane przez użytkowników, co oznacza, że im szybciej wprowadzisz treści na żywo do procesu, tym lepiej. Zadaniem programisty frontendu nie jest odwzorowanie wizji projektanta graficznego ; ma na celu manewrowanie złożonym obszarem, w jaki przeglądarki renderują HTML, CSS i JavaScript, upewniając się, że interfejsy użytkownika są responsywne, dostępne i wydajne.
Pracując jako konsultant technologiczny w Netlife (firmie konsultingowej specjalizującej się w doświadczeniach użytkowników), widziałem wielkie kroki w kierunku współpracy między programistami, projektantami i badaczami użytkowników. Mimo że nasi redaktorzy byli zawsze zaangażowani w projekt od samego początku, ich wkład nie trafił do obiegu projektowego, głównie z powodu problemów technicznych.
Wąskim gardłem był często przestarzały CMS, którego nie mogliśmy dotknąć, lub że zbudowanie struktury treści zajęło trochę czasu, ponieważ było to zależne od układu projektu. Często skutkowało to podwojeniem pracy: stworzyliśmy prototyp HTML, często oparty na treści przeanalizowanej z plików Markdown, które musiały zostać ponownie zaimplementowane w stosie CMS po zakończeniu testowania przez użytkowników, i wszyscy byli szczęśliwi co do piksela . Był to często kosztowny proces, ponieważ ograniczenia w CMS zostały odkryte na późniejszym etapie procesu. Wywiera również nacisk na wszystkie części, aby „zrobić to dobrze za pierwszym razem” i pozostawić mniej miejsca na eksperymenty, których potrzebujesz w projekcie projektowym.
Praca multidyscyplinarna wymaga zwinnych systemów
Przejście na system SCMS, w którym zakodowanie modelu treści zajęło kilka minut (gdzie pola i interfejs API były gotowe natychmiast), wywróciło nasz proces do góry nogami — i na lepsze. Pamiętam, jak w pierwszych dniach projektu siedziałem z edytorem treści nowego u4.no. Omówienie tego, jak pracowali i chcieliby pracować z ich treścią. Dość szybko przetłumaczyliśmy nasze wnioski na proste obiekty JavaScript, które natychmiast przekształciliśmy w środowisko edycyjne w przeglądarce. Znajdowanie przydatnych tytułów i opisów tytułów. Rozmawialiśmy o tym, jak chcieli fragmentów tekstu, które mogliby ponownie wykorzystać na różnych stronach i kontekstach, które wewnętrznie nazwali „samorodkami”, które następnie stworzyliśmy od czasu do czasu.
Pozwolenie na tego rodzaju eksplorację na wczesnym etapie rozwoju projektu — edytor treści i programista rozmawiający ze sobą, gdy interfejs był tworzony przed nami — wydawał się potężny. Wiedząc, że możemy kontynuować projektowanie frontendu w React, podczas gdy ona i jej współpracownicy rozpoczęli pracę z treścią. I nie martwiąc się o malowanie się w kącie, jak to często robiliśmy w przypadku systemów CMS, w których struktura była ściśle powiązana z tym, jak trzeba było zakodować część frontendową.
System treści powinien umożliwiać eksperymenty i iteracje
Poza kreatywnymi projektami przeprojektowania, system ustrukturyzowanych treści powinien również umożliwiać dalsze ulepszanie, testowanie i iterację treści w ramach całego systemu projektowania. Projektanci UX powinni być w stanie szybko tworzyć prototypy z prawdziwą treścią za pomocą narzędzi takich jak Sketch lub Framer X. Powinieneś być w stanie ulepszyć zarządzanie treścią o pomiary ilościowe, niezależnie od tego, czy chodzi o skale czytelności, czy o to, jak treść zachowuje się tam, gdzie jest używana.
Uwaga : powyżej użyłem terminu „projektanci UX”, mimo że uważam, że wszyscy powinniśmy – w jakiś sposób – odnieść się do procesu tworzenia dobrych doświadczeń użytkownika. Wszyscy jesteśmy projektantami UX w naszych różnych nurtach projektowania.
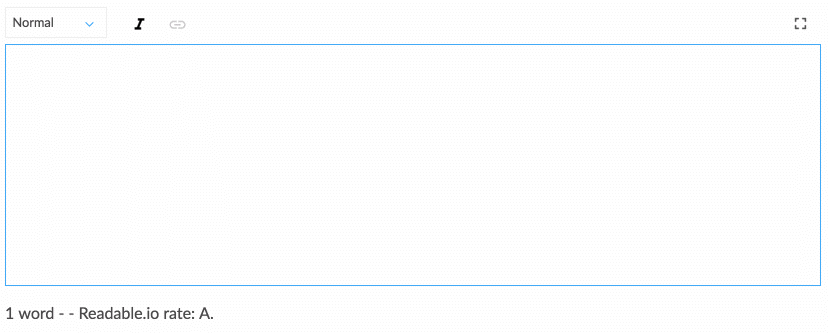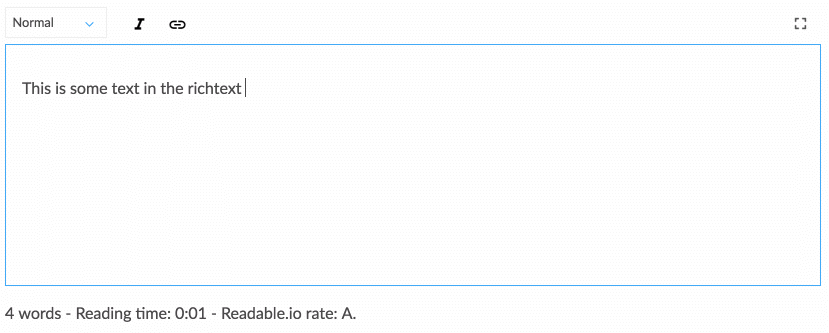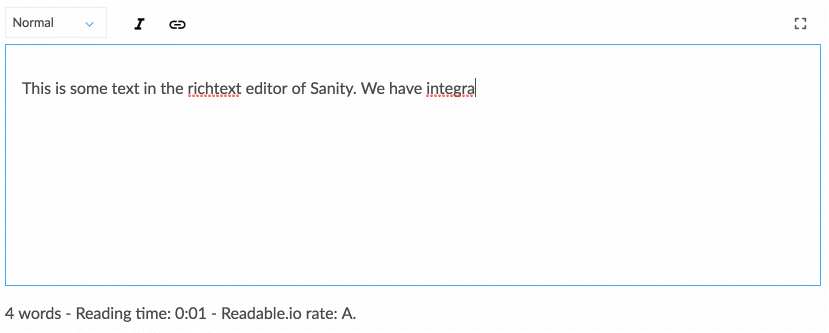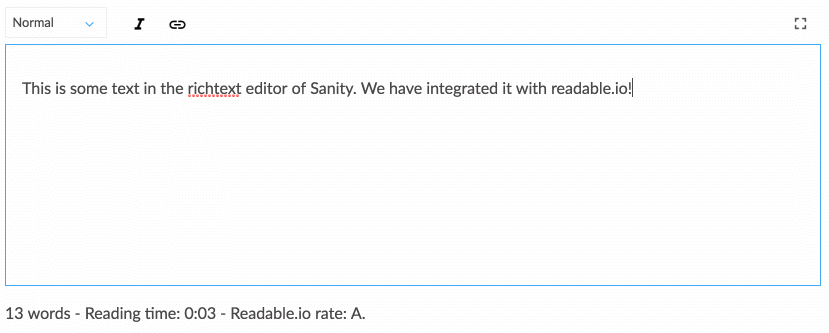
Praca z ustrukturyzowaną zawartością wymaga trochę przyzwyczajenia się, jeśli jesteś przyzwyczajony do WYSIWYG-owania zawartości bezpośrednio w układzie strony internetowej. Jednak nadaje się do rozmowy, która jest bardziej zgodna z tym, jak porusza się dziedzina projektowania cyfrowego. Ustrukturyzowana treść pozwala zespołowi projektantów, programistów, redaktorów treści, badaczy użytkowników i kierowników projektów wspólnie myśleć o tym, jak system powinien działać, aby wspierać potrzeby użytkowników i cele strategiczne. Wymaga to również innego myślenia o strukturze treści, co prowadzi nas do następnej strategii.
2. Możesz nie potrzebować zamówienia na dziobanie
Jedną z najbardziej zauważalnych zmian dla wielu jest to, że systemy treści strukturalnych są nastawione na kolekcje i listy dokumentów, a nie na hierarchie przypominające foldery, które odzwierciedlają struktury nawigacji w witrynie. Struktury te przestają mieć sens, gdy tylko część treści ma zostać wykorzystana w innych kontekstach — czy to w chatbotach, mediach drukowanych czy innych witrynach internetowych. Tradycyjne systemy CMS próbowały to złagodzić, zezwalając na bloki treści wielokrotnego użytku, ale nadal muszą być umieszczane w układach stron i niewygodne w rozumowaniu za pomocą interfejsów API.
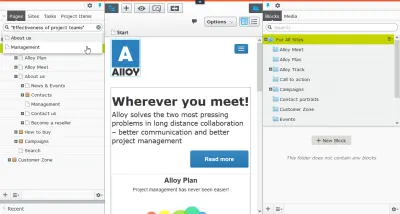
Każda strona na własną rękę
Jak określono w modelu podstawowym, gdy jednym z głównych stron odsyłających jest Google lub udostępnianie w mediach społecznościowych, każdą stronę należy traktować jako stronę docelową. A jeśli spojrzysz na rozkład odsłon, zauważysz, że niektóre z Twoich stron są znacznie bardziej popularne niż inne. O ile nie jesteś witryną z wiadomościami, nie są to zwykle wiadomości, ale takie, które pozwalają użytkownikowi osiągnąć to, co miał nadzieję osiągnąć w Twojej witrynie. To tam naprawdę dzieje się biznes.
Twoje treści cyfrowe powinny służyć przecięciu Twoich własnych celów strategicznych i indywidualnych celów Twoich użytkowników. Kiedy agencja cyfrowa Bengler (poprzednik sanity.io) stworzyła nową stronę internetową dla oma.eu, nie ustrukturyzowała treści według skomplikowanej hierarchii stron. Stworzyli typy treści, które odzwierciedlają organizacyjną codzienność, tj. po projektach , osobach , publikacjach . W rzeczywistości witryna OMA jest prawie całkowicie płaska pod względem hierarchii treści, a strona tytułowa jest generowana z połączenia reguł algorytmicznych i redakcyjnych.

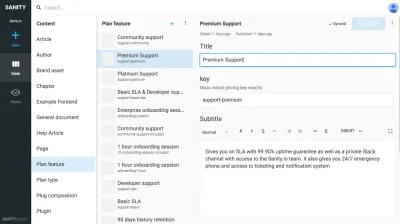
Więc jak się do tego zabrać? Uważam, że jest to połączenie myślenia o treściach jako odzwierciedlenie tego, w jaki sposób model mentalny Twojej organizacji i jaki musi być, aby był przydatny do tego, do czego potrzebują go Twoi użytkownicy.
Oto podstawowy przykład: Tworząc stronę z pracownikami, prawdopodobnie powinieneś zacząć od typu treści o nazwie osoba . Osoba może mieć imię i nazwisko, dane kontaktowe, obraz, różne role organizacyjne i krótką biografię. Dokument osoby może być ponownie wykorzystany na listach kontaktów, wpisach autorów artykułów, interfejsach wsparcia czatu i odznakach dostępu do budynków. Być może masz już własny system, który wie, kim są ci ludzie i który jest wyposażony w API? Świetnie, a następnie zsynchronizuj się z tym.
Nie zgub się w ontologicznej króliczej nory
Warto wrócić do sposobu indeksowania stron internetowych przez Google i sposobu, w jaki starają się indeksować informacje z całego świata. Dlatego poświęcają czas i wysiłek na połączone dane (RDFa, mikroformat, JSON-LD). Jeśli dodasz adnotacje do swoich stron internetowych za pomocą elementów JSON-LD, będziesz bardziej widoczny w wynikach wyszukiwania. Jest to również istotne, gdy Twoje informacje powinny być wypowiadane przez asystentów głosowych i wyświetlane w interfejsie asystenta. Jeśli Twoja treść jest już ustrukturyzowana i łatwo dostępna w interfejsie API, wdrożenie jej w tych mikroformatach będzie stosunkowo łatwe.
Nie jestem jednak pewien, czy poleciłbym zagłębianie się w ontologie schema.org i różne powiązane zasoby danych, przynajmniej nie dla celów edytora. Możesz szybko zgubić się w króliczej norce, próbując stworzyć idealne struktury platoniczne, w których wszystko pasuje.
Newsflash : Nigdy nie będzie, ponieważ świat jest bałaganem, a ludzie myślą o rzeczach inaczej.
Ważniejsze jest zorganizowanie treści w systemie, który ma intuicyjny sens i daje się dostosowywać do zmieniających się potrzeb. Dlatego ważne jest, aby zacząć od modelowania treści na wczesnym etapie procesu projektowania i tworzenia — musisz dowiedzieć się, jak należy z niego korzystać.
Abstrakt z rzeczywistości, a nie z konwencji CMS
Może być kuszące, aby po prostu podążać za konwencjami, które zawiera Twój CMS. Pamiętasz, jak Wordpress poda Ci „Posty” i „Strony” i nagle wszystko trzeba zmieścić w tych pudełkach? Pole tekstu sformatowanego WYSIWYG jest elastyczne, ponieważ pozwala wstawić cokolwiek, ale treść nie będzie ustrukturyzowana i łatwa do dostosowania — jest elastyczna tylko raz. Potrzebujesz jednak miejsca, aby rozpocząć mapowanie modelu treści. Proponuję zacząć od rozmowy z ludźmi, czyli autorami i czytelnikami.
Jak ludzie rozmawiają o treści wewnętrznie? Jak ludzie nazywają różne rzeczy? Mógłbyś przeprowadzić ćwiczenie swobodnego umieszczania na liście, metodę stosowaną przez etnografów do mapowania taksonomii ludowej. Na przykład możesz zapytać:
„Wymień różne rodzaje treści w naszej organizacji”.
Lub na bardziej szczegółowym poziomie:
„Czy możesz wymienić różne rodzaje raportów, które mamy w tej organizacji?”
Celem tego badania jest wydobycie zinternalizowanych taksonomii, które ludzie noszą, a nie ich opinii lub odczuć na temat rzeczy (coś, co często ma tendencję do wykolejania procesów projektowania). Nie musisz pytać szczególnie wielu, zanim masz dość wyczerpującą listę, z której możesz pracować. Prawdopodobnie zauważysz, że części Twojej listy pochodzą z konwencji w Twoim obecnym systemie CMS (warto wiedzieć, jeśli zamierzasz dokonać pewnych przeróbek). Teraz powinieneś porozmawiać ze swoim redaktorem i spróbować określić, do czego potrzebuje zawartość.
Niektóre pytania, które możesz zadać, mogą być następujące:
- Czy musisz korzystać z tej zawartości w więcej niż jednym miejscu? Gdzie?
- Jakie są różne relacje między typami treści?
- Gdzie potrzebujemy treści do wyświetlania dziś i jutro?
- W jaki sposób potrzebujemy sortowania treści? Czy zamówienie może być zrobione algorytmicznie, przez użytkownika, czy musi być ręcznie?
- Czy istnieją systemy lub bazy danych w innych systemach, z którymi możemy synchronizować, aby zapobiec duplikacji?
- Gdzie chcemy, aby treści kanoniczne żyć? Czy SCMS powinien być jej źródłem, czy tylko uzupełniać istniejące treści, np. tekst marketingowy dla produktów żyjących w systemie zarządzania produktami?
Nie oznacza to, że musisz wyrzucić tradycyjną architekturę informacyjną z letnią już kąpielą. Nadal ma sens posiadanie artykułów jako typu treści, jeśli artykuły są częścią rzeczywistości treści Twojej organizacji. Ale być może tak naprawdę nie potrzebujesz abstrakcyjnej konwencji kategorii , ponieważ te artykuły mają odniesienia do rodzaju usług lub produktów w nich zawartych. A ta relacja pozwala na odpytywanie tych artykułów w okolicznościach, w których ma to sens, bez konieczności posiadania przez kogoś „zarządzania kategorią artykułów” w ramach opisu stanowiska.
Artykuł jest również tym, co utrudnia całkowite oddzielenie treści od warstwy prezentacji. Jesteśmy przyzwyczajeni do myślenia o układzie i stylu artykułu, ale w epoce, w której oczekuje się, że będziesz hostować własne treści we własnej domenie, a następnie dystrybuować je na platformach takich jak medium.com, już zrezygnowałeś kontrola nad prezentacją wizualną. To prowadzi nas do następnej strategii.
3. Konteksty prezentacji są również typami treści
Bądź gotowy do przeprojektowania
Chcesz mieć możliwość adaptacji i szybkiej zmiany struktury nawigacji w swojej witrynie bez konieczności przebudowywania całej architektury treści lub walki z rygorystycznym interfejsem przypominającym folder. Chcesz też mieć pewną hierarchię treści, ponieważ czasami ma to sens, a czasami sięga głębiej niż dwa poziomy, gdzie większość interfejsów w dziale API-first CMS nie zapewnia dużej pomocy.
Co ciekawe, systemy zarządzania treścią dla chatbotów mają tendencję do używania podobnych struktur hierarchicznych do aranżowania drzew intencji i przepływów dialogów. Oznacza to, że hierarchie treści odgrywają różne role w różnych kanałach, ale często zapewniają sposoby poruszania się po treści. Sposobem na podejście do tego jest stworzenie typów do nawigacji, w których można uporządkować zawartość według odwołań i albo zbudować trasy dla stron internetowych, menu lub ścieżki dla interfejsów konwersacyjnych.
Porady dotyczące związku
Odniesienia (lub relacje) umożliwiają stworzenie systemu ustrukturyzowanej zawartości i są tak naprawdę sednem wszystkiego, z czym mamy do czynienia, jeśli chodzi o zawartość w sieci (to jest powód, dla którego jest on metaforycznie nazywany siecią ). Możliwość tworzenia odniesień między bitami treści jest bardzo potężną rzeczą, ale może być również kosztowna, jeśli chodzi o to, jak backendy są w stanie zapisywać i pobierać takie dane. Być może będziesz musiał myśleć inaczej, jeśli masz mnóstwo dokumentów, ponieważ skala rzadko jest dostępna za darmo.
Warto również wziąć pod uwagę, że nie zawsze potrzebujesz wyraźnego odniesienia do łączenia danych; najczęściej można to zrobić według kryteriów związanych z treścią, np. „daj mi wszystkie osoby i wszystkie budynki w tej geolokalizacji”. Budynek i osoby nie muszą mieć wyraźnego odniesienia do siebie, o ile jest to sugerowane w polu lokalizacji w obu typach zawartości.
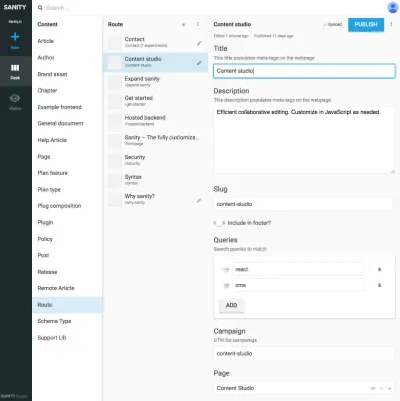
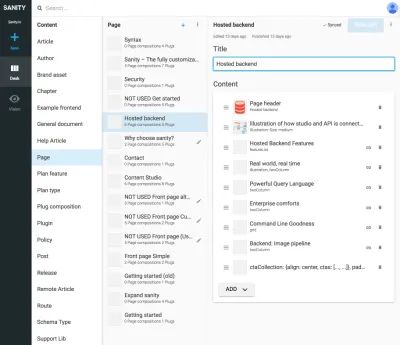
Odwołania między typami prezentacji i innymi typami zawartości są przydatne, gdy nie można pozostawić algorytmowi w warstwie prezentacji łączenia danych. Wyraźne narysowanie tego typu prezentacji i tworzenie kompozycji z treści, do których się odnosi, może wydawać się nieco kłopotliwe, ale jest to rozwiązanie problemu, który często można napotkać w systemach SCMS: trudno jest stwierdzić, gdzie jest używana treść. Uwzględniając typy nawigacji, wyraźnie powiążesz zawartość z prezentacją, ale nie tylko z jedną. Umożliwia to rozumowanie pracy ze strukturami nawigacyjnymi niezależnie od treści, do których prowadzą.
Na przykład na zrzutach ekranu powiązaliśmy Eksperymenty Google z typem route , co pozwala na dodawanie wielu stron skomponowanych z odwołań do treści, co oznacza, że możemy przeprowadzać testy A/B praktycznie bez duplikacji treści. Ponieważ otrzymujemy również ostrzeżenie, jeśli próbujemy usunąć zawartość, do której odwołują się inne dokumenty, ten sposób porządkowania uniemożliwi nam usunięcie czegoś, czego nie powinniśmy.
Relacje między typami treści to miecz obosieczny. Zwiększa trwałość i jest kluczem do uniknięcia powielania. Z drugiej strony możesz łatwo się skaleczyć, ponieważ tworzysz zależności między treściami, które (jeśli nie są przezroczyste) mogą prowadzić do niezamierzonych zmian w kanałach, w których wyświetlane są Twoje dane. Na przykład byłoby źle, gdybyśmy mogli usunąć „stronę” używaną przez „trasę” bez ostrzeżenia.
To prowadzi nas do następnej strategii, która (oczywiście!) jest na dzień dzisiejszy częściowo poza zasięgiem możliwości zwykłego użytkownika, ponieważ ma ona związek z architekturą różnych systemów. Mimo wszystko warto się nad tym zastanowić.
4. Nie umieszczaj tekstu sformatowanego w rogu
Sformatowany tekst to coś więcej niż HTML
Rozumiem, dlaczego HTML jest tak rozpowszechniony w treściach cyfrowych, ale wiem, że również z czegoś pochodzi; jest to podzbiór SGML, uogólnionego sposobu konstruowania dokumentów nadających się do odczytu maszynowego. Jak wskazuje Claire L. Evans w cudownej książce „Broad Band: The Untold Story of the Women who made the Internet” (2018), istniała już żywa społeczność ludzi myślących o powiązanych dokumentach, kiedy wprowadzono HTML. Propozycja Tima Bernersa-Lee była o wiele prostsza niż wiele innych systemów w tamtym czasie, ale prawdopodobnie dlatego się przyjęła i umożliwiła – od teraz – otwartą, darmową sieć.
Kiedy korzystasz z przeglądarki w sieci WWW, HTML jest świetny. Jeśli jesteś pisarzem, który chce opublikować coś, co kończy się w prostym HTML, Markdown jest świetny. Jeśli chcesz, aby zawartość tekstu sformatowanego można było łatwo zintegrować z czymś, co nie jest przeglądarką lub popularnym frameworkiem JavaScript, który pozwala rozszerzać HTML za pomocą JavaScript w złożonych komponentach (tak, mówimy o React i Vue.js) , posiadanie kodu HTML w odpowiedziach API zaczyna być trochę kłopotliwe — zwłaszcza jeśli musisz go przeanalizować.
Prawie wszyscy to robią, nawet nowe dzieciaki w bloku: przejrzałem wszystkich sprzedawców na headlesscms.org i przejrzałem dokumentację, a także zapisałem się na listę tych, którzy o tym nie wspomnieli. Z dwoma wyjątkami wszystkie one przechowują tekst sformatowany w formacie HTML lub Markdown. To dobrze, jeśli wszystko, co robisz, to używasz Jekyll do renderowania strony internetowej lub jeśli lubisz używać DangerlySetInnerHTML w React. Ale co, jeśli chcesz ponownie wykorzystać swoje treści w interfejsach, których nie ma w Internecie? A może chcesz mieć większą kontrolę i funkcjonalność w swoim edytorze tekstu sformatowanego? A może po prostu chcesz, aby renderowanie tekstu sformatowanego było łatwiejsze w jednym z popularnych frameworków frontendowych, a komponenty zajmowały się różnymi częściami treści tekstu sformatowanego? Cóż, albo będziesz musiał znaleźć sprytny sposób, aby przeanalizować tę przecenę lub kod HTML do tego, czego potrzebujesz, albo, wygodniej, po prostu przechowywać go w bardziej sensowny sposób.
Na przykład, co zrobić, jeśli chcesz wyprowadzić swój sformatowany tekst do interfejsu głosowego? Wiemy, że asystenci głosowi zyskują na popularności. Najpopularniejsze platformy dla tych asystentów mają możliwość pobierania tekstu do treści mówionych za pośrednictwem interfejsów API. Następnie chcesz skorzystać z czegoś takiego jak język znaczników syntezy mowy. System przenośnego tekstu przyjmuje bardziej agnostyczne podejście do tekstu sformatowanego, co pozwala dostosować tę samą treść do różnych rodzajów interfejsów.
Zalecana literatura : Eksperymentowanie z interfejsem SpeechSynthesis
Przenośny tekst jako agnostyczny model tekstu sformatowanego
Przenośny tekst jest również przydatny, gdy tworzysz głównie treści internetowe. Co zrobić, jeśli chcesz mieć możliwość zagnieżdżania i rozszerzania tekstu za pomocą struktur danych, takich jak przypis dolny z tekstem sformatowanym lub wbudowany komentarz redakcyjny? Albo alternatywne wyrażenie lub sformułowanie do przypadków testów A/B? Markdown i HTML szybko zawodzą i będziesz musiał polegać na dodaniu czegoś takiego jak specjalne tagi shortcode, tak jak Wordpress to rozwiązał. With portable text, you have an agnostic representation of content structures, without having to marry a certain implementation. Your content ends up being more sustainable and flexible for new redesigns and implementations.
There are also other advantages to portable text, especially if you want to be able to edit content collaboratively and in real time (as you do in Google Docs); you need to store rich text in another structure than HTML. If you do, you'll also be able to take advantage of microservices and bots, such as spaCy, in order to annotate and augment your content without locking the document.
As for now, portable text isn't widely adopted, but we're seeing movements towards it. The specification isn't very complex and can be explored at portabletext.org.
5. Make Sure Your SCMS Is In Service For Your Editors, And Not The Other Way Around
Digital content isn't just used for your organization's online web page leaflets anymore. For most of us, it encapsulates and defines how your organization is understood by the world, both from those within it and those outside: From product copy, micro texts to blog posts, chatbot responses, and strategy documents. We are millions of people that have to log into some CMS every day and navigate interfaces that were imagined twenty years ago with the assumptions of people who have never made much effort to user test or challenge their interfaces. Countless hours have been wasted away trying to fit a modern frontend experience into a page layout machine. Fortunately, this is soon a thing of the past.
As a technology consultant, I had to read through pages of technical specification whenever someone thought it was time to acquire a new CMS for themselves. There were demands from which server architecture it should run on (Windows servers, of course) to their ability to render “carousels” and “being able to edit web pages in place”, despite also requesting a “modular redesign”. When editors had been allowed to contribute to these specifications, they were also often dated to the what the editors had begotten used to. They seemed not aware that they could demand better user experiences, because enterprise software has to be big, lumpy and boring.
This is partly the fault of us making these systems. We tend to communicate technology features and specifications, and less what the everyday situation working with these systems look like. Sure, for a frontend designer, something supporting GraphQL is shorthand for how conveniently she is able to work against the backend, but on a higher level, it's about the systems ability to accommodate for emerging workflows, where a content model could survive visual redesigns and design systems should be resilient to changes of its content.
Questions To Ask Of Your (S)CMS
If we are to embrace design processes, we can't know prior to solving the problem whether the user tasks are best solved by making carousels ( newsflash: most probably not ), or whether A/B-testing makes sense for your case, even though it sounds cool.
Instead, ask questions like this:
- Is it possible, and how exactly will multi-disciplinary teams work with this system?
- How easy is it to change and migrate the content model?
- How does it deal with file and image assets?
- Has the editorial interface been user tested?
- To what extent can the system be configured and customized to special workflows and needs of the editorial team?
- How easy is it to export the content in a moveable format?
- How does the system accommodate for collaboration?
- Can content models be version controlled?
- How easy is it to integrate the system with a larger ecosystem of flowing information?
The goal of these questions is to explore to what degree a content management system allows for a cross-disciplinary team to work effortlessly together, without too many bottle-necks or long deployment cycles. They also push the focus to be more about the content should be doing, and less about how things should look in a given context. Leave that for the design processes, where user testing probably will challenge assumptions one may have when looking into getting a new content system.
There are, of course, many factors in addition to this that probably have to be taken into consideration. The easiest thing to assess is the fiscal cost of software licenses and API-related costs if you are on a hosted service. The invisible cost (in time and attention spent by the team working with the system), is harder to estimate. From my experience, many of the SCMSs in combination with one of the popular frontend frameworks can significantly cut development time and allow for an agile ( there's my coin for the swear jar ) design process. With the caveat that your team is prepared to solve some of the problems that come out of the box with traditional CMSs.
Towards Structured Content
The ways we work with digital content has changed dramatically since the World Wide Web made working with interconnected documents mainstream. Organizations, businesses, and corporations have amassed gigabytes of this content, which now is stuck in rigid page hierarchies, HTML markup, and clunky user interfaces.
Using a Structured Content Management System can be a great way to free your content from a paradigm that begins to feel its age. But it isn't a trivial exercise, and success comes from being able to work multi-disciplinary and put your content model to the test. You need to get rid of some conventions you have grown used to by dealing with CMSs designed to output hierarchical websites. That means that you need to think differently about ordering content, make presentations types in order to make it easier to orchestrate content across multiple channels and to consider how you structure rich text so that it can be used outside of HTML contexts.
This article deals with some of the high-level concerns working with SCMSs. There are, of course, loads of exciting challenges when you start working with this in your team. You have to rethink stuff we've taken for granted for many years, but that's probably a good thing. Because we are forced to evaluate our content, not only from its place on a digital page but from its role in a larger system that works for whatever goals your organization and your users may have.
I believe that we can achieve content models that are more meaningful and easier to sustain in the long run, and that means saving time and expenses. It means more flexibility in terms of inventing new outputs and services, and less tie in with software vendors. Because a well-made Structured Content Management System will make it easy for you to take your content and go elsewhere. And that makes for some interesting competition. Hopefully, all in favor of the users.