
Prognozy giełdowe za pomocą uczenia maszynowego [Wdrażanie krok po kroku]
Opublikowany: 2021-02-26Spis treści
Wstęp
Przewidywanie i analiza rynku akcji to jedne z najbardziej skomplikowanych zadań do wykonania. Istnieje kilka przyczyn takiego stanu rzeczy, takich jak zmienność rynku i wiele innych zależnych i niezależnych czynników decydujących o wartości danej akcji na rynku. Czynniki te sprawiają, że każdemu analitykowi giełdowemu bardzo trudno jest przewidzieć wzrost i spadek z dużą dokładnością.
Jednak wraz z pojawieniem się uczenia maszynowego i jego niezawodnych algorytmów, najnowsze analizy rynku i prognozy giełdowe zaczęły uwzględniać takie techniki w zrozumieniu danych giełdowych.
Krótko mówiąc, algorytmy uczenia maszynowego są szeroko stosowane przez wiele organizacji do analizowania i przewidywania wartości zapasów. W tym artykule omówimy prostą implementację analizowania i przewidywania wartości akcji popularnego na całym świecie internetowego sklepu detalicznego przy użyciu kilku algorytmów uczenia maszynowego w Pythonie.
Stwierdzenie problemu
Zanim przejdziemy do wdrożenia programu do przewidywania wartości giełdowych, zwizualizujmy dane, na których będziemy pracować. Tutaj będziemy analizować wartość akcji Microsoft Corporation (MSFT) od National Association of Securities Dealers Automated Quotations (NASDAQ). Dane dotyczące wartości giełdowych zostaną przedstawione w postaci pliku rozdzielanego przecinkami (.csv), który można otworzyć i przeglądać za pomocą programu Excel lub arkusza kalkulacyjnego.
MSFT ma swoje akcje zarejestrowane na NASDAQ i aktualizuje ich wartości w każdy dzień roboczy giełdy. Zauważ, że rynek nie pozwala na handel w soboty i niedziele; stąd istnieje luka między tymi dwiema datami. Dla każdego dnia odnotowywana jest Wartość Otwarcia akcji, Najwyższa i Najniższa wartość tej akcji w tych samych dniach, wraz z Wartością Zamknięcia na koniec dnia.
Skorygowana wartość zamknięcia pokazuje wartość akcji po zaksięgowaniu dywidendy (zbyt techniczne!). Dodatkowo podana jest również całkowita wielkość akcji na rynku. W przypadku tych danych badanie danych i wdrożenie kilku algorytmów, które mogą wyodrębnić wzorce z historycznych danych akcji firmy Microsoft Corporation, zależy od pracy naukowca zajmującego się uczeniem maszynowym / danymi. dane.

Pamięć długotrwała
Aby opracować model uczenia maszynowego do przewidywania cen akcji Microsoft Corporation, użyjemy techniki pamięci długo-krótkotrwałej (LSTM). Służą do wprowadzania drobnych modyfikacji informacji poprzez mnożenia i dodawania. Z definicji pamięć długotrwała (LSTM) to architektura sztucznej sieci neuronowej (RNN) wykorzystywana w głębokim uczeniu.
W przeciwieństwie do standardowych sieci neuronowych ze sprzężeniem do przodu, LSTM ma połączenia zwrotne. Może przetwarzać pojedyncze punkty danych (takie jak obrazy) i całe sekwencje danych (takie jak mowa lub wideo). Aby zrozumieć koncepcję stojącą za LSTM, weźmy prosty przykład recenzji telefonu komórkowego online przez klienta.
Załóżmy, że chcemy kupić telefon komórkowy, zwykle odwołujemy się do recenzji sieci certyfikowanych użytkowników. W zależności od ich myślenia i wkładu decydujemy, czy telefon jest dobry, czy zły, a następnie go kupujemy. Czytając recenzje, szukamy słów kluczowych, takich jak „niesamowity”, „dobry aparat”, „najlepsza bateria podtrzymująca” i wielu innych terminów związanych z telefonem komórkowym.
Mamy tendencję do ignorowania popularnych angielskich słów, takich jak „it”, „gave”, „this” itp. Dlatego decydując, czy kupić telefon komórkowy, czy nie, pamiętamy tylko te słowa kluczowe zdefiniowane powyżej. Najprawdopodobniej zapominamy o pozostałych słowach.
Jest to ten sam sposób, w jaki działa Algorytm Pamięci Długotrwałej. Zapamiętuje tylko istotne informacje i wykorzystuje je do przewidywania, ignorując nieistotne dane. W ten sposób musimy zbudować model LSTM, który zasadniczo rozpoznaje tylko podstawowe dane dotyczące tego towaru i pomija jego wartości odstające.
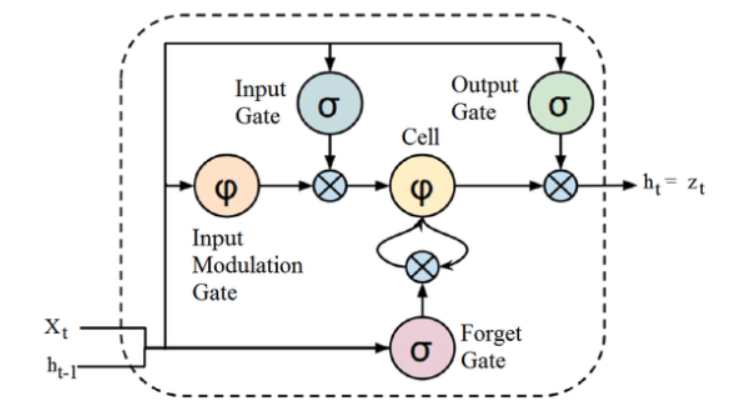
Źródło
Chociaż powyższa struktura architektury LSTM może początkowo wydawać się intrygująca, wystarczy pamiętać, że LSTM jest zaawansowaną wersją Recurrent Neural Networks, która zachowuje pamięć do przetwarzania sekwencji danych. Może usuwać lub dodawać informacje do stanu komórki, dokładnie regulowane przez struktury zwane bramkami.
Jednostka LSTM zawiera komórkę, bramkę wejściową, bramkę wyjściową i bramkę zapominania. Komórka zapamiętuje wartości w dowolnych odstępach czasu, a trzy bramki regulują przepływ informacji do iz komórki.
Wdrażanie Programu
Przejdziemy do części, w której wykorzystamy LSTM do przewidywania wartości zapasów za pomocą uczenia maszynowego w Pythonie.
Krok 1 – Importowanie bibliotek
Jak wszyscy wiemy, pierwszym krokiem jest zaimportowanie bibliotek, które są niezbędne do wstępnego przetworzenia danych giełdowych firmy Microsoft Corporation i innych wymaganych bibliotek do budowania i wizualizacji wyników modelu LSTM. W tym celu wykorzystamy bibliotekę Keras pod frameworkiem TensorFlow. Wymagane moduły są importowane z biblioteki Keras pojedynczo.
#Importowanie bibliotek
importuj pandy jako PD
importuj NumPy jako np
%matplotlib wbudowany
importuj bibliotekę matplotlib. pyplot jako plt
importuj bibliotekę matplotlib
od sklearn. Wstępne przetwarzanie importu MinMaxScaler
od Kerasa. import warstw LSTM, Gęsty, Dropout
ze sklearn.model_selection importuj TimeSeriesSplit
ze sklearn.metrics import mean_squared_error, r2_score
importuj bibliotekę matplotlib. daty jako mandaty
od sklearn. Wstępne przetwarzanie importu MinMaxScaler
from sklearn import linear_model
od Kerasa. Modele importują sekwencyjnie
od Kerasa. Warstwy importują Gęste
importuj Keras. Backend jako K
od Kerasa. Import wywołań zwrotnych EarlyStopping
od Kerasa. Optymalizatory importują Adam
od Kerasa. Modele importują load_model
od Kerasa. Importowanie warstw LSTM
od Kerasa. utils.vis_utils importuj model plotu
Krok 2 – Uzyskanie wizualizacji danych
Korzystając z biblioteki czytników Pandas Data, prześlemy dane giełdowe lokalnego systemu jako plik wartości oddzielonych przecinkami (.csv) i przechowamy je w pandas DataFrame. Na koniec przejrzymy również dane.
#Pobierz zbiór danych
df = pd.read_csv(“MicrosoftStockData.csv”,na_values=['null'],index_col='Data',parse_dates=True,infer_datetime_format=True)
df.głowa()
Uzyskaj certyfikat AI online z najlepszych uniwersytetów na świecie — Masters, Executive Post Graduate Programs oraz Advanced Certificate Program w ML i AI, aby przyspieszyć swoją karierę.
Krok 3 – Wydrukuj kształt DataFrame i sprawdź, czy nie ma wartości Null.
W tym kolejnym ważnym kroku najpierw drukujemy kształt zbioru danych. Aby upewnić się, że w ramce danych nie ma wartości null, sprawdzamy je. Obecność wartości null w zestawie danych zwykle powoduje problemy podczas uczenia, ponieważ działają one jako wartości odstające, powodując dużą zmienność w procesie uczenia.
#Drukuj kształt ramki danych i sprawdź wartości zerowe
print("Kształt ramki danych: ", df. kształt)
print("Obecna wartość pusta: ", df.IsNull().values.any())
>> Kształt ramki danych: (7334, 6)
>>Wartość zerowa Obecna: Fałsz
| Data | otwarty | Wysoka | Niski | Blisko | Przym Zamknij | Tom |
| 1990-01-02 | 0,605903 | 0,616319 | 0,598090 | 0,616319 | 0,447268 | 53033600 |
| 1990-01-03 | 0,621528 | 0,626736 | 0,614583 | 0,619792 | 0,449788 | 113772800 |
| 1990-01-04 | 0,619792 | 0,638889 | 0,616319 | 0,638021 | 0,463017 | 125740800 |
| 1990-01-05 | 0,635417 | 0,638889 | 0,621528 | 0,622396 | 0,451678 | 69564800 |
| 1990-01-08 | 0,621528 | 0,631944 | 0,614583 | 0,631944 | 0,458607 | 58982400 |
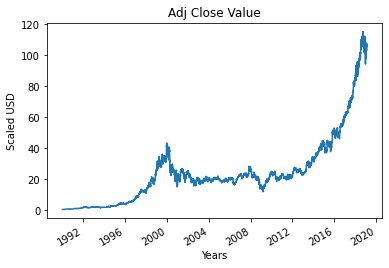
Krok 4 – Wykreślanie rzeczywistej skorygowanej wartości zamknięcia
Ostateczna wartość wyjściowa, która ma być przewidziana przy użyciu modelu uczenia maszynowego, to skorygowana wartość zamknięcia. Wartość ta reprezentuje wartość zamknięcia akcji w danym dniu obrotu giełdowego.
#Wykreśl prawdziwą wartość zbliżoną korekty
df['Adj Zamknij'].plot()
Krok 5 – Ustawienie zmiennej docelowej i wybór funkcji
W kolejnym kroku przypisujemy kolumnę wyjściową do zmiennej docelowej. W tym przypadku jest to skorygowana względna wartość akcji Microsoft. Dodatkowo dobieramy również cechy, które działają jako zmienna niezależna do zmiennej docelowej (zmiennej zależnej). Aby uwzględnić cel szkolenia, wybieramy cztery cechy, którymi są:

- otwarty
- Wysoka
- Niski
- Tom
#Ustaw zmienną docelową
output_var = PD.DataFrame(df['Adj Zamknij'])
#Wybieranie funkcji
funkcje = ['Otwarty', 'Wysoki', 'Niski', 'Głośność']
Krok 6 – Skalowanie
Aby zmniejszyć koszt obliczeniowy danych w tabeli, przeskalujemy wartości giełdowe do wartości od 0 do 1. W ten sposób wszystkie dane w dużych liczbach zostaną zredukowane, zmniejszając w ten sposób zużycie pamięci. Ponadto możemy uzyskać większą dokładność, skalując w dół, ponieważ dane nie są rozłożone w ogromnych wartościach. Jest to wykonywane przez klasę MinMaxScaler biblioteki sci-kit-learn.
#Skalowanie
skaler = MinMaxScaler()
feature_transform = scaler.fit_transform(df[features])
feature_transform= pd.DataFrame(kolumny=features, data=feature_transform, index=df.index)
feature_transform.head()
| Data | otwarty | Wysoka | Niski | Tom |
| 1990-01-02 | 0,000129 | 0,000105 | 0,000129 | 0,064837 |
| 1990-01-03 | 0,000265 | 0,000195 | 0,000273 | 0.144673 |
| 1990-01-04 | 0,000249 | 0,000300 | 0,000288 | 0.160404 |
| 1990-01-05 | 0,000386 | 0,000300 | 0,000334 | 0,086566 |
| 1990-01-08 | 0,000265 | 0,000240 | 0,000273 | 0,072656 |
Jak wspomniano powyżej, widzimy, że wartości zmiennych cech są przeskalowane do mniejszych wartości w porównaniu z wartościami rzeczywistymi podanymi powyżej.
Krok 7 – Podział na zestaw treningowy i zestaw testowy.
Przed wprowadzeniem danych do modelu uczącego musimy podzielić cały zestaw danych na zestaw uczący i testowy. Model uczenia maszynowego LSTM zostanie przeszkolony na danych obecnych w zestawie uczącym i przetestowany na zestawie testowym pod kątem dokładności i propagacji wstecznej.
W tym celu użyjemy klasy TimeSeriesSplit z biblioteki sci-kit-learn. Ustawiamy liczbę podziałów na 10, co oznacza, że 10% danych zostanie użytych jako zestaw testowy, a 90% danych zostanie wykorzystanych do uczenia modelu LSTM. Zaletą korzystania z tego podziału szeregów czasowych jest to, że próbki danych z podziału szeregów czasowych są obserwowane w stałych odstępach czasu.
#Podział na zestaw treningowy i zestaw testowy
timesplit=TimeSeriesSplit(n_split=10)
dla train_index, test_index w timesplit.split(feature_transform):
X_train, X_test = feature_transform[:len(train_index)], feature_transform[len(train_index): (len(train_index)+len(test_index))]
y_train, y_test = output_var[:len(train_index)].values.ravel(), output_var[len(train_index): (len(train_index)+len(test_index))].values.ravel()
Krok 8 – Przetwarzanie danych dla LSTM
Gdy zestawy uczące i testowe są gotowe, możemy wprowadzić dane do modelu LSTM po jego zbudowaniu. Wcześniej musimy przekonwertować dane zestawu uczącego i testowego na typ danych, który zaakceptuje model LSTM. Najpierw konwertujemy dane treningowe i dane testowe na tablice NumPy, a następnie przekształcamy je do formatu (Liczba próbek, 1, Liczba funkcji), ponieważ LSTM wymaga, aby dane były wprowadzane w formie 3D. Jak wiemy, liczba próbek w zbiorze uczącym wynosi 90% z 7334, czyli 6667, a liczba cech to 4, zbiór uczący jest przekształcony do (6667, 1, 4). Podobnie zmienia się również zestaw testowy.
#Przetwarzaj dane dla LSTM
trainX =np.array(X_train)
testX =np.tablica(X_test)
X_train = trainX.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test = testX.reshape(X_test.shape[0], 1, X_test.shape[1])
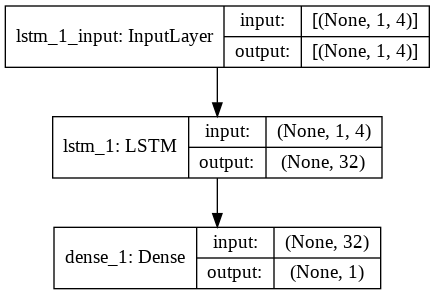
Krok 9 – Budowanie modelu LSTM
Wreszcie dochodzimy do etapu, w którym budujemy Model LSTM. Tutaj tworzymy model Sequential Keras z jedną warstwą LSTM. Warstwa LSTM ma 32 jednostki, a za nią znajduje się jedna warstwa gęsta z 1 neuronem.
Do kompilacji modelu używamy Adam Optimizer i Mean Squared Error jako funkcji straty. Te dwa są najbardziej preferowaną kombinacją dla modelu LSTM. Dodatkowo model jest również kreślony i wyświetlany poniżej.
#Budowanie modelu LSTM
lstm = sekwencyjny()
lstm.add(LSTM(32, input_shape=(1, trainX.shape[1]), aktywacja='relu', return_sequences=False))
lstm.add (gęsty (1))
lstm.compile(loss='mean_squared_error', Optimizer='adam')
plot_model(lstm, show_shapes=True, show_layer_names=True)
Krok 10 – Trening modelki
Na koniec trenujemy model LSTM zaprojektowany powyżej na danych uczących dla 100 epok z wielkością partii 8 za pomocą funkcji dopasowania.
#Szkolenie modelowe
historia = lstm.fit (X_train, y_train, epoki = 100, rozmiar_partii = 8, verbose = 1, shuffle = False)
Epoka 1/100
834/834 [==============================] – 3s 2ms/krok – utrata: 67,1211
Epoka 2/100
834/834 [==============================] – 1s 2ms/krok – utrata: 70.4911
Epoka 3/100
834/834 [==============================] – 1s 2ms/krok – utrata: 48.8155
Epoka 4/100
834/834 [==============================] – 1s 2ms/krok – utrata: 21.5447
Epoka 5/100
834/834 [==============================] – 1s 2ms/krok – utrata: 6.1709
Epoka 6/100
834/834 [==============================] – 1s 2ms/krok – utrata: 1.8726
Epoka 7/100
834/834 [==============================] – 1s 2ms/krok – strata: 0,9380
Epoka 8/100
834/834 [==============================] – 2s 2ms/krok – utrata: 0,6566
Epoka 9/100
834/834 [==============================] – 1s 2ms/krok – utrata: 0,5369
Epoka 10/100
834/834 [==============================] – 2s 2ms/krok – utrata: 0,4761
.
.
.
.
Epoka 95/100
834/834 [==============================] – 1s 2ms/krok – utrata: 0,4542
Epoka 96/100
834/834 [==============================] – 2s 2ms/krok – utrata: 0,4553
Epoka 97/100
834/834 [==============================] – 1s 2ms/krok – utrata: 0,4565
Epoka 98/100
834/834 [==============================] – 1s 2ms/krok – utrata: 0,4576
Epoka 99/100
834/834 [==============================] – 1s 2ms/krok – utrata: 0,4588
Epoka 100/100
834/834 [==============================] – 1s 2ms/krok – utrata: 0,4599
Na koniec widzimy, że wartość straty zmniejszyła się wykładniczo w czasie podczas procesu uczenia trwającego 100 epok i osiągnęła wartość 0,4599
Krok 11 – Przewidywanie LSTM
Gdy nasz model jest gotowy, nadszedł czas, aby użyć modelu wytrenowanego przy użyciu sieci LSTM na zestawie testowym i przewidzieć sąsiednią wartość zamknięcia akcji Microsoft. Odbywa się to za pomocą prostej funkcji przewidywania na zbudowanym modelu lstm.
#Przewidywanie LSTM
y_pred= lstm.predict(X_test)
Krok 12 – Prawda a przewidywana wartość zamknięcia korekty – LSTM
Wreszcie, ponieważ przewidzieliśmy wartości zestawu testowego, możemy wykreślić wykres, aby porównać zarówno prawdziwe wartości funkcji Adj Close, jak i przewidywaną wartość funkcji Adj Close za pomocą modelu uczenia maszynowego LSTM.
#Prawda a przewidywana wartość zamknięcia korekty – LSTM
plt.plot(y_test, label='Prawdziwa wartość')
plt.plot(y_pred, label='Wartość LSTM')
plt.title("Przewidywanie przez LSTM")
plt.xlabel('Skala czasu')
plt.ylabel('Skalowane USD')
plt.legenda()
plt.pokaż()
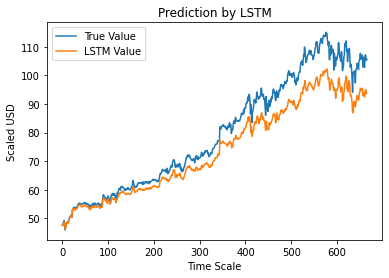
Powyższy wykres pokazuje, że pewien wzorzec jest wykrywany przez bardzo podstawowy pojedynczy model sieci LSTM zbudowany powyżej. Dostrajając kilka parametrów i dodając do modelu więcej warstw LSTM, możemy uzyskać dokładniejsze odwzorowanie wartości akcji dowolnej firmy.
Wniosek
Jeśli chcesz dowiedzieć się więcej o przykładach sztucznej inteligencji, uczeniu maszynowym, sprawdź program Executive PG IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji , który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznych szkoleń, ponad 30 studiów przypadków i zadania, status absolwentów IIIT-B, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Czy potrafisz przewidzieć rynek akcji za pomocą uczenia maszynowego?
Dziś dysponujemy szeregiem wskaźników, które pomagają przewidywać trendy rynkowe. Jednak nie musimy szukać dalej niż komputer o dużej mocy, aby znaleźć najdokładniejsze wskaźniki dla rynku akcji. Giełda jest systemem otwartym i może być postrzegana jako złożona sieć. Sieć składa się z relacji między akcjami, firmami, inwestorami i wielkością obrotu. Korzystając z algorytmu eksploracji danych, takiego jak maszyna wektorów nośnych, można zastosować wzór matematyczny, aby wyodrębnić relacje między tymi zmiennymi. Rynek akcji jest teraz poza ludzkimi przewidywaniami.
Który algorytm jest najlepszy do prognozowania na giełdzie?
Aby uzyskać najlepsze wyniki, należy użyć regresji liniowej. Regresja liniowa to podejście statystyczne, które służy do określenia związku między dwiema różnymi zmiennymi. W tym przykładzie zmiennymi są cena i czas. W prognozach giełdowych cena jest zmienną niezależną, a czas jest zmienną zależną. Jeśli można określić liniową zależność między tymi dwiema zmiennymi, możliwe jest dokładne przewidzenie wartości zapasów w dowolnym momencie w przyszłości.
Czy prognozy giełdowe są problemem klasyfikacji czy regresji?
Zanim odpowiemy, musimy zrozumieć, co oznaczają prognozy giełdowe. Czy jest to problem klasyfikacji binarnej, czy problem regresji? Załóżmy, że chcemy przewidzieć przyszłość akcji, gdzie przyszłość oznacza następny dzień, tydzień, miesiąc lub rok. Jeśli przeszłe wyniki akcji w pewnym momencie są danymi wejściowymi, a przyszłe są danymi wyjściowymi, to jest to problem regresji. Jeśli przeszłe wyniki akcji i przyszłość akcji są niezależne, to jest to problem klasyfikacji.