
Używanie SSE zamiast WebSocket do jednokierunkowego przepływu danych przez HTTP/2
Opublikowany: 2022-03-10Budując aplikację internetową, należy zastanowić się, z jakiego mechanizmu dostarczania będą korzystać. Załóżmy, że mamy aplikację wieloplatformową, która działa z danymi w czasie rzeczywistym; aplikacja giełdowa umożliwiająca kupowanie lub sprzedawanie akcji w czasie rzeczywistym. Ta aplikacja składa się z widżetów, które przynoszą różne wartości różnym użytkownikom.
Jeśli chodzi o dostarczanie danych z serwera do klienta, ograniczamy się do dwóch ogólnych podejść: client pull lub server push . Jako prosty przykład z dowolną aplikacją internetową, klientem jest przeglądarka internetowa. Gdy witryna w Twojej przeglądarce prosi serwer o dane, nazywa się to ściąganiem klienta . Odwrotnie, gdy serwer aktywnie wysyła aktualizacje do Twojej witryny, nazywa się to serwerem push .
Obecnie istnieje kilka sposobów na ich wdrożenie:
- Odpytywanie długie/krótkie (klient pull)
- WebSockets (serwer push)
- Zdarzenia wysłane przez serwer (push serwera).
Po ustaleniu wymagań dla naszego uzasadnienia biznesowego przyjrzymy się dogłębnie trzem alternatywom.
Przypadek biznesowy
Aby móc szybko dostarczać nowe widżety do naszej aplikacji giełdowej i używać ich w trybie plug'n'play bez ponownego wdrażania całej platformy, potrzebujemy, aby były one samowystarczalne i zarządzały własnymi danymi we/wy. Widgety nie są ze sobą w żaden sposób połączone. W idealnym przypadku wszyscy zasubskrybują jakiś punkt końcowy API i zaczną pobierać z niego dane. Oprócz szybszego czasu wprowadzania nowych funkcji na rynek, takie podejście daje nam możliwość eksportowania treści na strony internetowe osób trzecich, podczas gdy nasze widżety same dostarczają wszystko, czego potrzebują.
Główną pułapką jest to, że liczba połączeń będzie rosła liniowo wraz z liczbą posiadanych widżetów i przekroczymy limit przeglądarek pod względem liczby żądań HTTP obsługiwanych jednocześnie.
Dane, które otrzymają nasze widżety, składają się głównie z liczb i aktualizacji ich liczb: Pierwsza odpowiedź zawiera dziesięć akcji z pewnymi wartościami rynkowymi. Obejmuje to aktualizacje dodawania/usuwania zapasów oraz aktualizacje wartości rynkowych aktualnie prezentowanych. Przesyłamy małe ilości ciągów JSON dla każdej aktualizacji tak szybko, jak to możliwe.
HTTP/2 zapewnia multipleksowanie żądań pochodzących z tej samej domeny, co oznacza, że możemy uzyskać tylko jedno połączenie dla wielu odpowiedzi. Brzmi to tak, jakby to mogło rozwiązać nasz problem. Zaczynamy od zbadania różnych opcji, aby uzyskać dane i zobaczyć, co możemy z nich uzyskać.
- Będziemy używać NGINX do równoważenia obciążenia i proxy, aby ukryć wszystkie nasze punkty końcowe za tą samą domeną. Umożliwi nam to korzystanie z multipleksowania HTTP/2 po wyjęciu z pudełka.
- Chcemy efektywnie wykorzystywać sieć i baterię urządzeń mobilnych.
Alternatywy
Długie odpytywanie

Client pull jest odpowiednikiem implementacji oprogramowania irytującego dziecka siedzącego na tylnym siedzeniu twojego samochodu, ciągle pytającego: „Czy już tam jesteśmy?” Krótko mówiąc, klient prosi serwer o dane. Serwer nie ma danych i czeka przez pewien czas przed wysłaniem odpowiedzi:
- Jeśli coś wyskoczy podczas oczekiwania, serwer wysyła to i zamyka żądanie;
- Jeśli nie ma nic do wysłania i zostanie osiągnięty maksymalny czas oczekiwania, serwer wysyła odpowiedź, że nie ma danych;
- W obu przypadkach klient otwiera kolejne żądanie danych;
- Namyj, spłucz, powtórz.
Wywołania AJAX działają na protokole HTTP, co oznacza, że żądania do tej samej domeny powinny być domyślnie multipleksowane. Jednak napotkaliśmy wiele problemów, próbując sprawić, by działały zgodnie z wymaganiami. Niektóre z pułapek, które zidentyfikowaliśmy dzięki naszemu podejściu do widżetów:
Nagłówki narzutu
Każde żądanie i odpowiedź odpytywania jest kompletnym komunikatem HTTP i zawiera pełny zestaw nagłówków HTTP w ramce komunikatu. W naszym przypadku, gdy mamy małe częste wiadomości, nagłówki faktycznie reprezentują większy procent przesyłanych danych. Rzeczywisty użyteczny ładunek jest znacznie mniejszy niż łączna liczba przesłanych bajtów (np. 15 KB nagłówków na 5 KB danych).Maksymalny czas oczekiwania
Gdy serwer odpowie, nie może już wysyłać danych do klienta, dopóki klient nie wyśle następnego żądania. Podczas gdy średnie opóźnienie dla długiego odpytywania jest zbliżone do jednego tranzytu sieciowego, maksymalne opóźnienie wynosi ponad trzy tranzyty sieciowe: odpowiedź, żądanie, odpowiedź. Jednak ze względu na utratę pakietów i retransmisję maksymalne opóźnienie dla dowolnego protokołu TCP/IP będzie większe niż trzy tranzyty sieciowe (można tego uniknąć dzięki potoku HTTP). Podczas gdy w bezpośrednim połączeniu LAN nie jest to duży problem, staje się jednym, gdy ktoś jest w ruchu i przełącza komórki sieciowe. Do pewnego stopnia jest to obserwowane w przypadku SSE i WebSockets, ale efekt jest największy w przypadku odpytywania.Nawiązywanie połączenia
Chociaż można tego uniknąć, używając trwałego połączenia HTTP wielokrotnego użytku dla wielu żądań odpytywania, trudno jest odpowiednio zaplanować odpytywanie wszystkich komponentów w krótkich okresach czasu, aby utrzymać połączenie przy życiu. W końcu, w zależności od odpowiedzi serwera, twoje ankiety zostaną rozsynchronizowane.Obniżenie wydajności
Obciążony klient (lub serwer) z długim odpytywaniem ma naturalną tendencję do spadku wydajności kosztem opóźnienia wiadomości. Kiedy tak się stanie, zdarzenia, które zostaną wysłane do klienta, zostaną umieszczone w kolejce. To naprawdę zależy od wdrożenia; w naszym przypadku musimy agregować wszystkie dane, ponieważ wysyłamy zdarzenia dodawania/usuwania/aktualizacji do naszych widżetów.Limity czasu
Długie żądania odpytywania muszą pozostać w stanie oczekiwania, dopóki serwer nie będzie miał czegoś do wysłania do klienta. Może to prowadzić do zamknięcia połączenia przez serwer proxy, jeśli pozostaje on bezczynny przez zbyt długi czas.Multipleksowanie
Może się to zdarzyć, jeśli odpowiedzi pojawią się w tym samym czasie za pośrednictwem trwałego połączenia HTTP/2. Może to być trudne, ponieważ odpowiedzi na ankiety nie mogą być zsynchronizowane.
Więcej o rzeczywistych problemach, których można doświadczyć podczas długich ankiet, można znaleźć tutaj .
Gniazda sieciowe

Jako pierwszy przykład metody server push przyjrzymy się WebSockets.
Przez MDN:
WebSockets to zaawansowana technologia umożliwiająca otwarcie interaktywnej sesji komunikacyjnej między przeglądarką użytkownika a serwerem. Za pomocą tego interfejsu API możesz wysyłać wiadomości do serwera i odbierać odpowiedzi sterowane zdarzeniami bez konieczności odpytywania serwera o odpowiedź.
Jest to protokół komunikacyjny zapewniający pełnodupleksowe kanały komunikacyjne za pośrednictwem pojedynczego połączenia TCP.
Zarówno HTTP, jak i WebSockets znajdują się w warstwie aplikacji z modelu OSI i jako takie zależą od protokołu TCP w warstwie 4.
- Wniosek
- Prezentacja
- Sesja
- Transport
- Sieć
- Łącza danych
- Fizyczny
RFC 6455 stwierdza, że WebSocket „jest przeznaczony do pracy na portach HTTP 80 i 443, a także do obsługi serwerów proxy i pośredników HTTP”, dzięki czemu jest kompatybilny z protokołem HTTP. Aby osiągnąć zgodność, uzgadnianie WebSocket używa nagłówka HTTP Upgrade do zmiany z protokołu HTTP na protokół WebSocket.
Istnieje również bardzo dobry artykuł, który wyjaśnia wszystko, co musisz wiedzieć o WebSockets na Wikipedii. Zachęcam do lektury.
Po ustaleniu, że gniazdka mogą faktycznie dla nas działać, zaczęliśmy badać ich możliwości w naszym przypadku biznesowym i uderzać ściana za ścianą.
Serwery proxy : ogólnie istnieje kilka różnych problemów z WebSocketami i serwerami proxy:
- Pierwszy dotyczy dostawców usług internetowych i sposobu, w jaki obsługują oni swoje sieci. Problemy z zablokowanymi portami proxy promienia i tak dalej.
- Drugi rodzaj problemów jest związany ze sposobem, w jaki serwer proxy jest skonfigurowany do obsługi niezabezpieczonego ruchu HTTP i długotrwałych połączeń (wpływ jest zmniejszony dzięki HTTPS).
- Trzeci problem „w przypadku WebSockets jesteś zmuszony do uruchamiania serwerów proxy TCP w przeciwieństwie do serwerów proxy HTTP. Serwery proxy TCP nie mogą wstrzykiwać nagłówków, przepisywać adresów URL ani pełnić wielu ról, którymi tradycyjnie pozwalamy zająć się naszym proxy HTTP”.
Liczba połączeń : słynny limit połączeń dla żądań HTTP, który obraca się wokół liczby 6, nie dotyczy WebSocketów. 50 gniazd = 50 połączeń. Dziesięć kart przeglądarki na 50 gniazd = 500 połączeń i tak dalej. Ponieważ WebSocket jest innym protokołem do dostarczania danych, nie jest on automatycznie multipleksowany przez połączenia HTTP/2 (tak naprawdę w ogóle nie działa na HTTP). Implementacja niestandardowego multipleksowania zarówno na serwerze, jak i na kliencie jest zbyt skomplikowana, aby gniazda były przydatne w określonym przypadku biznesowym. Co więcej, łączy to nasze widżety z naszą platformą, ponieważ będą potrzebować pewnego rodzaju API na kliencie, aby się zasubskrybować, a bez niego nie jesteśmy w stanie ich rozpowszechniać.
Równoważenie obciążenia (bez multipleksowania) : Jeśli każdy użytkownik otwiera
nliczby gniazd, właściwe równoważenie obciążenia jest bardzo skomplikowane. Kiedy twoje serwery są przeciążone i musisz tworzyć nowe instancje i zamykać stare w zależności od implementacji twojego oprogramowania, działania podejmowane podczas „ponownego połączenia” mogą wywołać ogromny łańcuch odświeżeń i nowych żądań danych, które przeciążą twój system . WebSockety muszą być utrzymywane zarówno na serwerze, jak i na kliencie. Nie można przenieść połączeń z gniazdem na inny serwer, jeśli obecny jest mocno obciążony. Muszą zostać zamknięte i ponownie otwarte.DoS : Jest to zwykle obsługiwane przez serwery proxy HTTP frontonu, które nie mogą być obsługiwane przez serwery proxy TCP, które są wymagane przez WebSockets. Można podłączyć się do gniazda i zacząć zalewać serwery danymi. WebSockets narażają Cię na tego rodzaju ataki.
Ponowne odkrywanie koła : Korzystając z WebSockets, trzeba samodzielnie poradzić sobie z wieloma problemami, które są rozwiązywane w HTTP.
Więcej o rzeczywistych problemach z WebSockets można przeczytać tutaj.
Dobrymi przykładami użycia WebSocketów są czaty i gry wieloosobowe, w których korzyści przeważają nad problemami z implementacją. Ponieważ ich główną zaletą jest komunikacja dwustronna, a my tak naprawdę jej nie potrzebujemy, musimy iść dalej.
Uderzenie
Otrzymujemy zwiększone koszty operacyjne w zakresie opracowywania, testowania i skalowania; oprogramowanie i jego infrastruktura informatyczna wraz z odpytywaniem i WebSocketami.
Ten sam problem pojawia się na urządzeniach mobilnych i w sieciach z obydwoma. Konstrukcja sprzętowa tych urządzeń utrzymuje otwarte połączenie, utrzymując antenę i połączenie z siecią komórkową przy życiu. Prowadzi to do skrócenia żywotności baterii, ciepła, a w niektórych przypadkach do dodatkowych opłat za dane.
Ale dlaczego wciąż mamy problemy z urządzeniami mobilnymi?
Zastanówmy się, jak domyślne urządzenie mobilne łączy się z Internetem:
Proste wyjaśnienie działania sieci komórkowej: Zazwyczaj urządzenia mobilne mają antenę o małej mocy, która może odbierać dane z komórki. W ten sposób, gdy urządzenie odbierze dane z połączenia przychodzącego, uruchamia antenę pełnodupleksową w celu nawiązania połączenia. Ta sama antena jest używana za każdym razem , gdy chcesz nawiązać połączenie lub uzyskać dostęp do Internetu (jeśli WiFi nie jest dostępne). Antena pełnodupleksowa musi nawiązać połączenie z siecią komórkową i przeprowadzić pewne uwierzytelnienie. Po ustanowieniu połączenia istnieje pewna komunikacja między Twoim urządzeniem a komórką w celu wykonania naszego żądania sieciowego. Zostajemy przekierowani do wewnętrznego proxy operatora telefonii komórkowej, który obsługuje zapytania internetowe. Od tego momentu procedura jest już znana: pyta DNS, gdzie faktycznie znajduje się www.domainname.ext , otrzymuje identyfikator URI do zasobu i ostatecznie zostaje do niego przekierowany.
Ten proces, jak można sobie wyobrazić, pobiera dość dużo energii z baterii. To jest powód, dla którego producenci telefonów komórkowych zapewniają kilkudniowy czas czuwania, a czas rozmów zaledwie kilka godzin.
Bez Wi-Fi zarówno WebSockets, jak i odpytywanie wymagają anteny działającej w trybie pełnego dupleksu do niemal ciągłej pracy. W związku z tym mamy do czynienia ze zwiększonym zużyciem danych i zwiększonym poborem mocy — a w zależności od urządzenia — także z ciepłem.
Zanim wszystko zacznie wydawać się ponure, wygląda na to, że będziemy musieli ponownie rozważyć wymagania biznesowe dla naszej aplikacji. Czy czegoś nam brakuje?

SSE
Przez MDN:
„Interfejs EventSource służy do odbierania zdarzeń wysyłanych przez serwer. Łączy się z serwerem przez HTTP i odbiera zdarzenia w formacie tekstu/strumienia zdarzeń bez zamykania połączenia.”
Główną różnicą w stosunku do odpytywania jest to, że otrzymujemy tylko jedno połączenie i utrzymujemy przez nie strumień zdarzeń. Długie odpytywanie tworzy nowe połączenie dla każdego wyciągnięcia — ergo z nagłówkami i innymi problemami, z którymi się tam spotkaliśmy.
Za pośrednictwem html5doctor.com:
Zdarzenia wysyłane przez serwer to zdarzenia w czasie rzeczywistym emitowane przez serwer i odbierane przez przeglądarkę. Są podobne do WebSocketów, ponieważ działają w czasie rzeczywistym, ale są bardzo jednokierunkową metodą komunikacji z serwerem.
Wygląda to trochę dziwnie, ale po rozważeniu — nasz główny przepływ danych odbywa się z serwera do klienta i w znacznie mniejszej liczbie przypadków od klienta do serwera.
Wygląda na to, że możemy to wykorzystać w naszym głównym biznesowym przypadku dostarczania danych. Możemy rozwiązać zakupy klienta, wysyłając nowe żądanie, ponieważ protokół jest jednokierunkowy i klient nie może za jego pośrednictwem wysyłać wiadomości do serwera. To w końcu będzie miało opóźnienie czasowe anteny pełnodupleksowej, aby uruchomić się na urządzeniach mobilnych. Możemy jednak żyć z tym, że zdarza się to od czasu do czasu — w końcu to opóźnienie mierzone jest w milisekundach.
Unikalne funkcje
- Strumień połączenia pochodzi z serwera i jest tylko do odczytu.
- Używają zwykłych żądań HTTP do trwałego połączenia, a nie specjalnego protokołu. Pierwsze multipleksowanie przez HTTP/2 po wyjęciu z pudełka.
- Jeśli połączenie zostanie przerwane, EventSource wyzwoli zdarzenie błędu i automatycznie spróbuje ponownie nawiązać połączenie. Serwer może również kontrolować limit czasu, zanim klient spróbuje ponownie się połączyć (więcej szczegółów wyjaśniono później).
- Klienci mogą wysyłać wraz z wiadomościami unikalny identyfikator. Gdy klient próbuje ponownie połączyć się po zerwaniu połączenia, wysyła ostatni znany identyfikator. Następnie serwer widzi, że klient pominął
nwiadomości i wysyła zaległości nieodebranych wiadomości przy ponownym połączeniu.
Przykładowa implementacja klienta
Zdarzenia te są podobne do zwykłych zdarzeń JavaScript, które występują w przeglądarce — na przykład zdarzeń kliknięć — z tą różnicą, że możemy kontrolować nazwę zdarzenia i powiązane z nim dane.
Zobaczmy prosty podgląd kodu po stronie klienta:
// subscribe for messages var source = new EventSource('URL'); // handle messages source.onmessage = function(event) { // Do something with the data: event.data; };Na przykładzie widzimy, że strona klienta jest dość prosta. Łączy się z naszym źródłem i czeka na odebranie wiadomości.
Aby umożliwić serwerom przesyłanie danych do stron internetowych przez HTTP lub przy użyciu dedykowanych protokołów wypychania serwera, specyfikacja wprowadza interfejs `EventSource` na kliencie. Korzystanie z tego interfejsu API polega na utworzeniu obiektu `EventSource` i zarejestrowaniu detektora zdarzeń.
Implementacja klienta dla WebSockets wygląda bardzo podobnie. Złożoność z gniazdami tkwi w infrastrukturze IT i wdrożeniu serwerów.
Źródło zdarzenia
Każdy obiekt EventSource ma następujących członków:
- URL: ustawiany podczas budowy.
- Żądanie: początkowo ma wartość null.
- Czas ponownego połączenia: wartość w ms (wartość zdefiniowana przez klienta użytkownika).
- Identyfikator ostatniego zdarzenia: początkowo pusty ciąg.
- Stan gotowości: stan połączenia.
- ŁĄCZENIE (0)
- OTWARTE (1)
- ZAMKNIĘTE (2)
Oprócz adresu URL wszystkie są traktowane jako prywatne i nie można uzyskać do nich dostępu z zewnątrz.
Wydarzenia wbudowane:
- otwarty
- Wiadomość
- Błąd
Obsługa zrzutów połączenia
W przypadku zerwania połączenie jest automatycznie ponownie nawiązywane przez przeglądarkę. Serwer może wysłać limit czasu, aby ponowić próbę lub trwale zamknąć połączenie. W takim przypadku przeglądarka zastosuje się do próby ponownego połączenia po przekroczeniu limitu czasu lub do braku próby połączenia, jeśli połączenie otrzyma komunikat o zakończeniu. Wydaje się dość proste — i tak właśnie jest.
Przykładowa implementacja serwera
Skoro klient jest taki prosty, to może implementacja serwera jest skomplikowana?
Cóż, program obsługi serwera dla SSE może wyglądać tak:
function handler(response) { // setup headers for the response in order to get the persistent HTTP connection response.writeHead(200, { 'Content-Type': 'text/event-stream', 'Cache-Control': 'no-cache', 'Connection': 'keep-alive' }); // compose the message response.write('id: UniqueID\n'); response.write("data: " + data + '\n\n'); // whenever you send two new line characters the message is sent automatically }Definiujemy funkcję, która będzie obsługiwać odpowiedź:
- Konfiguracja nagłówków
- Stwórz wiadomość
- Wysłać
Zauważ, że nie widzisz wywołania metody send() ani push() . Dzieje się tak, ponieważ standard określa, że wiadomość zostanie wysłana, gdy tylko otrzyma dwa \n\n znaki, jak w przykładzie: response.write("data: " + data + '\n\n'); . Spowoduje to natychmiastowe przekazanie wiadomości do klienta. Zwróć uwagę, że data muszą być łańcuchem ze znakami ucieczki i nie mają na końcu znaków nowej linii.
Budowa wiadomości
Jak wspomniano wcześniej, wiadomość może zawierać kilka właściwości:
- ID
Jeśli wartość pola nie zawiera U+0000 NULL, ustaw ostatni bufor identyfikatora zdarzenia na wartość pola. W przeciwnym razie zignoruj to pole. - Dane
Dodaj wartość pola do bufora danych, a następnie dołącz pojedynczy znak U+000A LINE FEED (LF) do bufora danych. - Wydarzenie
Ustaw bufor typu zdarzenia na wartość pola. Prowadzi to do tego, żeevent.typeTwoją niestandardową nazwę zdarzenia. - Spróbować ponownie
Jeśli wartość pola składa się tylko z cyfr ASCII, zinterpretuj wartość pola jako liczbę całkowitą o podstawie dziesiątej i ustaw czas ponownego połączenia strumienia zdarzeń na tę liczbę całkowitą. W przeciwnym razie zignoruj to pole.
Wszystko inne zostanie zignorowane. Nie możemy wprowadzić własnych pól.
Przykład z dodanym event :
response.write('id: UniqueID\n'); response.write('event: add\n'); response.write('retry: 10000\n'); response.write("data: " + data + '\n\n'); Następnie na kliencie jest to obsługiwane za pomocą addEventListener jako takiego:
source.addEventListener("add", function(event) { // do stuff with data event.data; });Możesz wysłać wiele wiadomości oddzielonych nowym wierszem, o ile podasz różne identyfikatory.
... id: 54 event: add data: "[{SOME JSON DATA}]" id: 55 event: remove data: JSON.stringify(some_data) id: 56 event: remove data: { data: "msg" : "JSON data"\n data: "field": "value"\n data: "field2": "value2"\n data: }\n\n ...To znacznie upraszcza to, co możemy zrobić z naszymi danymi.
Specyficzne wymagania dotyczące serwera
Podczas naszego POC dla zaplecza stwierdziliśmy, że ma on pewne szczegóły, którymi należy się zająć, aby mieć działającą implementację SSE. W najlepszym przypadku będziesz używać serwera opartego na pętli zdarzeń, takiego jak NodeJS, Kestrel lub Twisted. Pomysł polega na tym, że w przypadku rozwiązania opartego na wątkach będziesz mieć wątek na połączenie → 1000 połączeń = 1000 wątków. Dzięki rozwiązaniu pętli zdarzeń będziesz mieć jeden wątek na 1000 połączeń.
- Żądania EventSource można akceptować tylko wtedy, gdy żądanie HTTP mówi, że może akceptować typ MIME strumienia zdarzeń;
- Musisz utrzymywać listę wszystkich podłączonych użytkowników, aby emitować nowe zdarzenia;
- Powinieneś nasłuchiwać zerwanych połączeń i usunąć je z listy podłączonych użytkowników;
- Opcjonalnie należy prowadzić historię wiadomości, aby klienci ponownie nawiązujący połączenie mogli nadążyć za nieodebranymi wiadomościami.
Działa zgodnie z oczekiwaniami i na początku wygląda jak magia. Dostajemy wszystko, co chcemy, aby nasza aplikacja działała wydajnie. Podobnie jak w przypadku wszystkich rzeczy, które wyglądają zbyt dobrze, aby mogły być prawdziwe, czasami napotykamy pewne problemy, które należy rozwiązać. Jednak ich wdrożenie lub obejście nie są skomplikowane:
Wiadomo, że starsze serwery proxy w niektórych przypadkach zrywają połączenia HTTP po krótkim czasie oczekiwania. Aby chronić się przed takimi serwerami proxy, autorzy mogą umieszczać wiersz komentarza (rozpoczynający się od znaku „:”) co około 15 sekund.
Autorzy, którzy chcą powiązać połączenia źródła zdarzeń ze sobą lub z określonymi wcześniej obsługiwanymi dokumentami, mogą stwierdzić, że poleganie na adresach IP nie działa, ponieważ poszczególni klienci mogą mieć wiele adresów IP (ze względu na posiadanie wielu serwerów proxy), a indywidualne adresy IP mogą mieć wielu klientów (ze względu na współdzielenie serwera proxy). Lepiej jest umieścić unikalny identyfikator w dokumencie podczas jego obsługi, a następnie przekazać go jako część adresu URL podczas nawiązywania połączenia.
Autorzy są również ostrzegani, że chunking HTTP może mieć nieoczekiwany negatywny wpływ na niezawodność tego protokołu, w szczególności, jeśli chunking jest wykonywany przez inną warstwę nieświadomą wymagań dotyczących czasu. Jeśli jest to problem, fragmentowanie można wyłączyć w celu obsługi strumieni zdarzeń.
Klienci, którzy obsługują ograniczenie połączenia HTTP na serwer, mogą napotkać problemy podczas otwierania wielu stron z witryny, jeśli każda strona ma EventSource do tej samej domeny. Autorzy mogą tego uniknąć, korzystając ze stosunkowo złożonego mechanizmu używania unikatowych nazw domen na połączenie lub zezwalając użytkownikowi na włączanie lub wyłączanie funkcji EventSource na stronie lub udostępniając pojedynczy obiekt EventSource przy użyciu współużytkowanego procesu roboczego.
Obsługa przeglądarki i wypełnienia: Edge pozostaje w tyle za tą implementacją, ale dostępne jest wypełnienie, które może cię uratować. Jednak najważniejszy argument za SSE dotyczy urządzeń mobilnych, w których IE/Edge nie ma realnego udziału w rynku.
Niektóre z dostępnych wypełniaczy:
- Yaffle
- amvtek
- remy
Bezpołączeniowe Push i inne funkcje
Programy użytkownika działające w kontrolowanych środowiskach, np. przeglądarki w telefonach komórkowych powiązanych z określonymi operatorami, mogą odciążać zarządzanie połączeniem z serwerem proxy w sieci. W takiej sytuacji, agent użytkownika dla celów zgodności jest uważany za obejmujący zarówno oprogramowanie mikrotelefonu, jak i sieciowe proxy.
Na przykład przeglądarka na urządzeniu mobilnym po ustanowieniu połączenia może wykryć, że znajduje się w sieci wspierającej i zażądać, aby serwer proxy w sieci przejął zarządzanie połączeniem. Harmonogram takiej sytuacji może wyglądać następująco:
- Przeglądarka łączy się ze zdalnym serwerem HTTP i żąda zasobu określonego przez autora w konstruktorze EventSource.
- Serwer wysyła sporadyczne wiadomości.
- Pomiędzy dwoma komunikatami przeglądarka wykrywa, że jest bezczynna, z wyjątkiem aktywności sieciowej związanej z utrzymywaniem aktywnego połączenia TCP, i postanawia przełączyć się w tryb uśpienia, aby oszczędzać energię.
- Przeglądarka rozłącza się z serwerem.
- Przeglądarka kontaktuje się z usługą w sieci i żąda, aby usługa „push proxy” utrzymywała połączenie.
- Usługa „push proxy” kontaktuje się ze zdalnym serwerem HTTP i żąda zasobu określonego przez autora w konstruktorze EventSource (prawdopodobnie zawierającego nagłówek HTTP
Last-Event-IDitp.). - Przeglądarka umożliwia uśpienie urządzenia mobilnego.
- Serwer wysyła kolejną wiadomość.
- Usługa „push proxy” wykorzystuje technologię, taką jak OMA push, aby przekazać zdarzenie do urządzenia mobilnego, które budzi się tylko na tyle, aby przetworzyć zdarzenie, a następnie wraca do stanu uśpienia.
Może to zmniejszyć całkowite zużycie danych, a tym samym spowodować znaczne oszczędności energii.
Oprócz implementacji istniejącego interfejsu API i formatu drutu tekstowego/strumienia zdarzeń zgodnie z definicją w specyfikacji oraz w bardziej rozproszony sposób (jak opisano powyżej), mogą być obsługiwane formaty ramek zdarzeń zdefiniowane w innych odpowiednich specyfikacjach.
Streszczenie
Po długich i wyczerpujących POC, w tym wdrożeniach serwerowych i klienckich, wygląda na to, że SSE jest odpowiedzią na nasze problemy z dostarczaniem danych. Jest z tym również kilka pułapek, ale okazały się one trywialne do naprawienia.
Tak wygląda w końcu nasza konfiguracja produkcyjna:
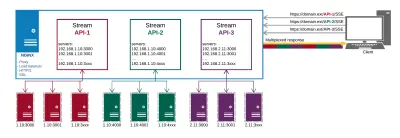
Od NGINX otrzymujemy:
- Proxy do punktów końcowych API w różnych miejscach;
- HTTP/2 i wszystkie jego zalety, takie jak multipleksowanie połączeń;
- Równoważenie obciążenia;
- SSL.
W ten sposób zarządzamy dostarczaniem danych i certyfikatami w jednym miejscu, zamiast robić to na każdym punkcie końcowym osobno.
Główne korzyści, jakie uzyskujemy dzięki takiemu podejściu to:
- Wydajne przetwarzanie danych;
- Prostsza implementacja;
- Jest automatycznie multipleksowany przez HTTP/2;
- Ogranicza liczbę połączeń dla danych na kliencie do jednego;
- Zapewnia mechanizm oszczędzania baterii poprzez odciążenie połączenia z serwerem proxy.
SSE to nie tylko realna alternatywa dla innych metod dostarczania szybkich aktualizacji; wygląda na to, że jest we własnej lidze, jeśli chodzi o optymalizacje dla urządzeń mobilnych. Jego wdrożenie nie wiąże się z żadnymi kosztami ogólnymi w porównaniu z alternatywami. Pod względem implementacji po stronie serwera nie różni się to zbytnio od odpytywania. Na kliencie jest to znacznie prostsze niż sondowanie, ponieważ wymaga wstępnej subskrypcji i przypisania obsługi zdarzeń — podobnie jak w przypadku zarządzania obiektami WebSockets.
Sprawdź demo kodu, jeśli chcesz uzyskać prostą implementację klient-serwer.
Zasoby
- „Znane problemy i najlepsze praktyki dotyczące korzystania z długiego odpytywania i przesyłania strumieniowego w dwukierunkowym HTTP”, IETF (PDF)
- Rekomendacja W3C, W3C
- „Czy WebSocket przetrwa HTTP/2?”, Allan Denis, InfoQ
- „Przesyłaj aktualizacje za pomocą zdarzeń wysyłanych przez serwer”, Eric Bidelman, HTML5 Rocks
- „Aplikacje do przesyłania danych z HTML5 SSE”, Darren Cook, O'Reilly Media