
Udostępnianie danych między wieloma serwerami za pośrednictwem AWS S3
Opublikowany: 2022-03-10W przypadku udostępniania niektórych funkcji przetwarzania pliku przesłanego przez użytkownika, plik musi być dostępny dla procesu przez cały czas wykonywania. Prosta operacja przesyłania i zapisywania nie stwarza żadnych problemów. Jeśli jednak dodatkowo plik musi zostać zmanipulowany przed zapisaniem, a aplikacja działa na kilku serwerach za load balancerem, to musimy upewnić się, że plik jest dostępny dla każdego serwera, na którym w danym momencie jest uruchomiony proces.
Na przykład wieloetapowa funkcja „Prześlij swój awatar użytkownika” może wymagać od użytkownika przesłania awatara w kroku 1, przycięcia go w kroku 2 i zapisania go w kroku 3. Po przesłaniu pliku na serwer w kroku 1, plik musi być dostępny dla dowolnego serwera obsługującego żądanie dla kroków 2 i 3, które mogą być takie same lub nie dla kroku 1.
Naiwnym podejściem byłoby skopiowanie przesłanego pliku w kroku 1 na wszystkie inne serwery, aby plik był dostępny na wszystkich. Jednak takie podejście jest nie tylko niezwykle złożone, ale także niewykonalne: na przykład, jeśli witryna działa na setkach serwerów z kilku regionów, nie można tego zrealizować.
Możliwym rozwiązaniem jest włączenie „sticky session” na load balancerze, który zawsze przypisze ten sam serwer dla danej sesji. Następnie kroki 1, 2 i 3 będą obsługiwane przez ten sam serwer, a plik przesłany na ten serwer w kroku 1 nadal będzie dostępny w krokach 2 i 3. Jednak sesje trwałe nie są w pełni niezawodne: Jeśli pomiędzy krokami 1 i 2, że serwer uległ awarii, system równoważenia obciążenia będzie musiał przypisać inny serwer, zakłócając funkcjonalność i wrażenia użytkownika. Podobnie, zawsze przypisywanie tego samego serwera do sesji może, w szczególnych okolicznościach, prowadzić do wolniejszego czasu odpowiedzi z przeciążonego serwera.
Bardziej odpowiednim rozwiązaniem jest przechowywanie kopii pliku w repozytorium dostępnym dla wszystkich serwerów. Następnie, po przesłaniu pliku na serwer w kroku 1, ten serwer prześle go do repozytorium (lub alternatywnie plik może zostać przesłany do repozytorium bezpośrednio z klienta, z pominięciem serwera); krok 2 obsługi serwera pobierze plik z repozytorium, manipuluje nim i ponownie go tam załaduje; a na koniec krok 3 obsługujący serwer pobierze go z repozytorium i zapisze.
W tym artykule opiszę to drugie rozwiązanie, oparte na aplikacji WordPress przechowującej pliki na Amazon Web Services (AWS) Simple Storage Service (S3) (rozwiązanie do przechowywania obiektów w chmurze do przechowywania i pobierania danych), działającej poprzez AWS SDK.
Uwaga 1: W przypadku prostej funkcjonalności, takiej jak przycinanie awatarów, innym rozwiązaniem byłoby całkowite ominięcie serwera i zaimplementowanie go bezpośrednio w chmurze za pomocą funkcji Lambda. Ale ponieważ ten artykuł dotyczy łączenia aplikacji działającej na serwerze z AWS S3, nie rozważamy tego rozwiązania.
Uwaga 2: Aby korzystać z AWS S3 (lub dowolnej innej usługi AWS), musimy mieć konto użytkownika. Amazon oferuje tutaj bezpłatny poziom przez 1 rok, co jest wystarczające do eksperymentowania z ich usługami.
Uwaga 3: Istnieją wtyczki innych firm do przesyłania plików z WordPress do S3. Jedną z takich wtyczek jest WP Media Offload (wersja Lite jest dostępna tutaj), która zapewnia świetną funkcję: bezproblemowo przenosi pliki przesłane do Biblioteki multimediów do wiadra S3, co pozwala oddzielić zawartość witryny (tak jak wszystko pod /wp-content/uploads) z kodu aplikacji. Oddzielając zawartość i kod, jesteśmy w stanie wdrożyć naszą aplikację WordPress za pomocą Git (w przeciwnym razie nie możemy, ponieważ treści przesłane przez użytkowników nie są hostowane w repozytorium Git) i hostować aplikację na wielu serwerach (w przeciwnym razie każdy serwer musiałby zachować kopię wszystkich treści przesłanych przez użytkowników).
Tworzenie Wiadra
Podczas tworzenia wiaderka musimy zwrócić uwagę na nazwę wiaderka: Każda nazwa wiaderka musi być globalnie unikalna w sieci AWS, więc nawet jeśli chcielibyśmy nazwać nasz wiaderko czymś prostym, jak „awatary”, ta nazwa może już być zajęta , wtedy możemy wybrać coś bardziej charakterystycznego, jak „awatary-nazwa-mojej-firmy”.
Musimy również wybrać region, w którym znajduje się zasobnik (region to fizyczna lokalizacja, w której znajduje się centrum danych, z lokalizacjami na całym świecie).
Region musi być tym samym, w którym jest wdrożona nasza aplikacja, aby dostęp do S3 podczas wykonywania procesu był szybki. W przeciwnym razie użytkownik może poczekać dodatkowe sekundy przed przesłaniem/pobraniem obrazu do/z odległej lokalizacji.
Uwaga: korzystanie z S3 jako rozwiązania do przechowywania obiektów w chmurze ma sens tylko wtedy, gdy do uruchamiania aplikacji korzystamy również z usługi Amazon dla serwerów wirtualnych w chmurze, EC2. Jeśli zamiast tego będziemy polegać na innej firmie do hostingu aplikacji, takiej jak Microsoft Azure lub DigitalOcean, powinniśmy również skorzystać z ich usług przechowywania obiektów w chmurze. W przeciwnym razie nasza witryna ucierpi na skutek przesyłania danych między sieciami różnych firm.
Na poniższych zrzutach ekranu zobaczymy, jak utworzyć zasobnik, w którym można przesłać awatary użytkowników do przycięcia. Najpierw przechodzimy do pulpitu nawigacyjnego S3 i klikamy „Utwórz wiadro”:
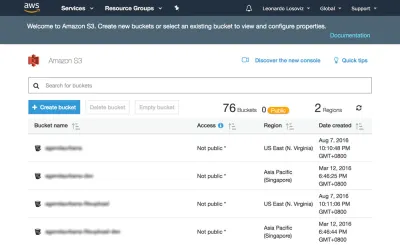
Następnie wpisujemy nazwę wiadra (w tym przypadku „avatary-smashing”) i wybieramy region („EU (Frankfurt)”):
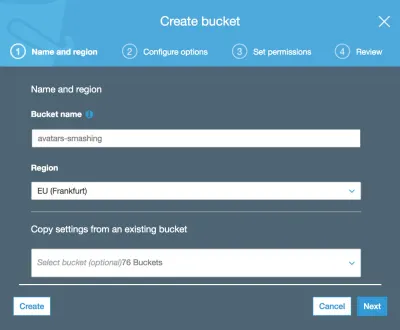
Tylko nazwa zasobnika i region są obowiązkowe. W kolejnych krokach możemy zachować domyślne opcje, więc klikamy „Dalej”, aż w końcu klikniemy „Utwórz zasobnik”, a dzięki temu utworzymy zasobnik.
Konfigurowanie uprawnień użytkownika
Podczas łączenia się z AWS za pośrednictwem SDK będziemy musieli wprowadzić nasze dane uwierzytelniające użytkownika (parę identyfikatorów klucza dostępu i tajnego klucza dostępu), aby potwierdzić, że mamy dostęp do żądanych usług i obiektów. Uprawnienia użytkownika mogą być bardzo ogólne (rola „administratora” może zrobić wszystko) lub bardzo szczegółowe, nadając uprawnienia tylko do określonych potrzebnych operacji i nic więcej.
Z reguły im bardziej szczegółowe przyznane nam uprawnienia, tym lepiej, aby uniknąć problemów z bezpieczeństwem . Tworząc nowego użytkownika, będziemy musieli utworzyć politykę, która jest prostym dokumentem JSON zawierającym listę uprawnień, które należy nadać użytkownikowi. W naszym przypadku nasze uprawnienia użytkownika przyznają dostęp do S3, do wiadra „rozbijanie awatara”, do operacji „Put” (do wgrania obiektu), „Get” (do pobrania obiektu) i „Lista” ( do wylistowania wszystkich obiektów w zasobniku), co skutkuje następującą zasadą:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:Put*", "s3:Get*", "s3:List*" ], "Resource": [ "arn:aws:s3:::avatars-smashing", "arn:aws:s3:::avatars-smashing/*" ] } ] }Na poniższych zrzutach ekranu możemy zobaczyć, jak dodać uprawnienia użytkownika. Musimy przejść do pulpitu nawigacyjnego zarządzania tożsamością i dostępem (IAM):
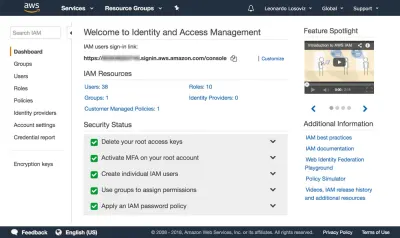
W desce rozdzielczej klikamy „Użytkownicy”, a zaraz potem „Dodaj użytkownika”. Na stronie Dodaj użytkownika wybieramy nazwę użytkownika („crop-avatars”) i zaznaczamy „Dostęp programowy” jako typ dostępu, który zapewni identyfikator klucza dostępu i tajny klucz dostępu do połączenia przez SDK:
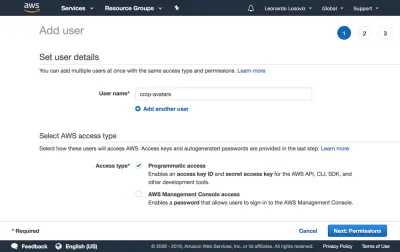
Następnie klikamy przycisk „Dalej: Uprawnienia”, klikamy „Dołącz istniejące polityki bezpośrednio” i klikamy „Utwórz politykę”. Spowoduje to otwarcie nowej karty w przeglądarce ze stroną Utwórz politykę. Klikamy na zakładkę JSON i wpisujemy kod JSON dla polityki zdefiniowanej powyżej:
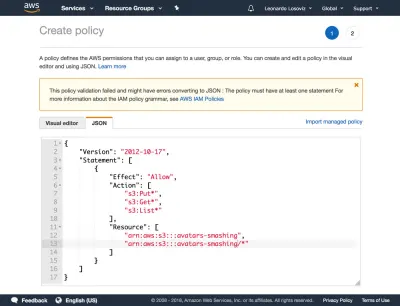
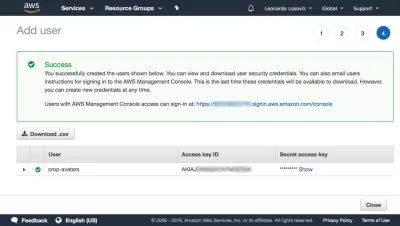
Następnie klikamy Zasady przeglądu, nadajemy im nazwę („CropAvatars”), a na koniec klikamy Utwórz zasady. Po utworzeniu polityki wracamy do poprzedniej zakładki, wybieramy politykę CropAvatars (może być konieczne odświeżenie listy polityk, aby ją zobaczyć), klikamy Dalej: Przejrzyj, a na koniec na Utwórz użytkownika. Po wykonaniu tej czynności możemy w końcu pobrać identyfikator klucza dostępu i tajny klucz dostępu (proszę zauważyć, że te dane uwierzytelniające są dostępne w tym wyjątkowym momencie; jeśli nie skopiujemy ich ani nie pobierzemy teraz, będziemy musieli utworzyć nową parę ):

Łączenie się z AWS przez SDK
SDK jest dostępny w wielu językach. W przypadku aplikacji WordPress potrzebujemy SDK dla PHP, które można pobrać stąd, a instrukcje dotyczące jego instalacji znajdują się tutaj.
Po utworzeniu zasobnika, przygotowaniu poświadczeń użytkownika i zainstalowaniu pakietu SDK możemy rozpocząć przesyłanie plików do S3.
Przesyłanie i pobieranie plików
Dla wygody definiujemy poświadczenia użytkownika i region jako stałe w pliku wp-config.php:
define ('AWS_ACCESS_KEY_ID', '...'); // Your access key id define ('AWS_SECRET_ACCESS_KEY', '...'); // Your secret access key define ('AWS_REGION', 'eu-central-1'); // Region where the bucket is located. This is the region id for "EU (Frankfurt)" W naszym przypadku wdrażamy funkcję przycinania awatarów, dla której awatary będą przechowywane w kubełku „awatary-smashing”. Jednak w naszej aplikacji możemy mieć kilka innych wiader dla innych funkcjonalności, wymagających wykonania tych samych operacji przesyłania, pobierania i wyświetlania plików. Dlatego implementujemy wspólne metody w abstrakcyjnej klasie AWS_S3 i uzyskujemy dane wejściowe, takie jak nazwa wiadra zdefiniowana za pomocą funkcji get_bucket , w implementujących klasach potomnych.
// Load the SDK and import the AWS objects require 'vendor/autoload.php'; use Aws\S3\S3Client; use Aws\Exception\AwsException; // Definition of an abstract class abstract class AWS_S3 { protected function get_bucket() { // The bucket name will be implemented by the child class return ''; } } Klasa S3Client udostępnia interfejs API do interakcji z S3. Tworzymy go tylko wtedy, gdy jest to potrzebne (poprzez leniwą inicjalizację) i zapisujemy odwołanie do niego w $this->s3Client , aby nadal używać tej samej instancji:
abstract class AWS_S3 { // Continued from above... protected $s3Client; protected function get_s3_client() { // Lazy initialization if (!$this->s3Client) { // Create an S3Client. Provide the credentials and region as defined through constants in wp-config.php $this->s3Client = new S3Client([ 'version' => '2006-03-01', 'region' => AWS_REGION, 'credentials' => [ 'key' => AWS_ACCESS_KEY_ID, 'secret' => AWS_SECRET_ACCESS_KEY, ], ]); } return $this->s3Client; } } Kiedy mamy do czynienia z $file w naszej aplikacji, ta zmienna zawiera bezwzględną ścieżkę do pliku na dysku (np /var/app/current/wp-content/uploads/users/654/leo.jpg ), ale podczas przesyłania pliku do S3 nie powinniśmy przechowywać obiektu pod tą samą ścieżką. W szczególności musimy usunąć początkowy bit dotyczący informacji systemowych ( /var/app/current ) ze względów bezpieczeństwa i opcjonalnie możemy usunąć bit /wp-content (ponieważ wszystkie pliki są przechowywane w tym folderze, jest to zbędna informacja ), zachowując tylko względną ścieżkę do pliku ( /uploads/users/654/leo.jpg ). Dogodnie można to osiągnąć, usuwając wszystko po WP_CONTENT_DIR ze ścieżki bezwzględnej. Funkcje get_file i get_file_relative_path poniżej przełączają między bezwzględną i względną ścieżką plików:
abstract class AWS_S3 { // Continued from above... function get_file_relative_path($file) { return substr($file, strlen(WP_CONTENT_DIR)); } function get_file($file_relative_path) { return WP_CONTENT_DIR.$file_relative_path; } }Wgrywając obiekt do S3, możemy ustalić komu przyznawany jest dostęp do obiektu oraz rodzaj dostępu, realizowanego poprzez uprawnienia listy kontroli dostępu (ACL). Najczęstsze opcje to zachowanie prywatności pliku (ACL => „prywatny”) i udostępnienie go do odczytu w Internecie (ACL => „public-odczyt”). Ponieważ będziemy musieli zażądać pliku bezpośrednio z S3, aby pokazać go użytkownikowi, potrzebujemy ACL => „public-read”:
abstract class AWS_S3 { // Continued from above... protected function get_acl() { return 'public-read'; } }Na koniec wdrażamy metody przesyłania obiektu do i pobierania obiektu z zasobnika S3:
abstract class AWS_S3 { // Continued from above... function upload($file) { $s3Client = $this->get_s3_client(); // Upload a file object to S3 $s3Client->putObject([ 'ACL' => $this->get_acl(), 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SourceFile' => $file, ]); } function download($file) { $s3Client = $this->get_s3_client(); // Download a file object from S3 $s3Client->getObject([ 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SaveAs' => $file, ]); } }Następnie w implementującej klasie potomnej definiujemy nazwę wiadra:
class AvatarCropper_AWS_S3 extends AWS_S3 { protected function get_bucket() { return 'avatars-smashing'; } } Na koniec po prostu tworzymy instancję klasy, aby przesłać awatary do lub pobrać z S3. Ponadto, przechodząc z kroków 1 do 2 i 2 do 3, musimy przekazać wartość $file . Możemy to zrobić, przesyłając pole „file_relative_path” z wartością ścieżki względnej $file poprzez operację POST (nie przekazujemy ścieżki bezwzględnej ze względów bezpieczeństwa: nie ma potrzeby dołączania „/var/www/current ” informacje dla osób postronnych:
// Step 1: after the file was uploaded to the server, upload it to S3. Here, $file is known $avatarcropper = new AvatarCropper_AWS_S3(); $avatarcropper->upload($file); // Get the file path, and send it to the next step in the POST $file_relative_path = $avatarcropper->get_file_relative_path($file); // ... // -------------------------------------------------- // Step 2: get the $file from the request and download it, manipulate it, and upload it again $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_POST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Do manipulation of the file // ... // Upload the file again to S3 $avatarcropper->upload($file); // -------------------------------------------------- // Step 3: get the $file from the request and download it, and then save it $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_REQUEST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Save it, whatever that means // ...Wyświetlanie pliku bezpośrednio z S3
Jeśli chcemy wyświetlić stan pośredni pliku po manipulacji w kroku 2 (np. awatar użytkownika po przycięciu), musimy odwołać się do pliku bezpośrednio z S3; URL nie mógł wskazywać na plik na serwerze, ponieważ po raz kolejny nie wiemy, który serwer obsłuży to żądanie.
Poniżej dodajemy funkcję get_file_url($file) która pobiera adres URL tego pliku w S3. Jeśli korzystasz z tej funkcji, upewnij się, że lista ACL przesłanych plików jest „do odczytu publicznego”, w przeciwnym razie nie będzie dostępna dla użytkownika.
abstract class AWS_S3 { // Continue from above... protected function get_bucket_url() { $region = $this->get_region(); // North Virginia region is simply "s3", the others require the region explicitly $prefix = $region == 'us-east-1' ? 's3' : 's3-'.$region; // Use the same scheme as the current request $scheme = is_ssl() ? 'https' : 'http'; // Using the bucket name in path scheme return $scheme.'://'.$prefix.'.amazonaws.com/'.$this->get_bucket(); } function get_file_url($file) { return $this->get_bucket_url().$this->get_file_relative_path($file); } }Następnie możemy po prostu pobrać adres URL pliku na S3 i wydrukować obraz:
printf( "<img src='%s'>", $avatarcropper->get_file_url($file) );Lista plików
Jeśli w naszej aplikacji chcemy umożliwić użytkownikowi przeglądanie wszystkich wgranych wcześniej awatarów, możemy to zrobić. W tym celu wprowadzamy funkcję get_file_urls , która wyświetla adres URL wszystkich plików przechowywanych pod określoną ścieżką (w terminologii S3 nazywa się to prefiksem):
abstract class AWS_S3 { // Continue from above... function get_file_urls($prefix) { $s3Client = $this->get_s3_client(); $result = $s3Client->listObjects(array( 'Bucket' => $this->get_bucket(), 'Prefix' => $prefix )); $file_urls = array(); if(isset($result['Contents']) && count($result['Contents']) > 0 ) { foreach ($result['Contents'] as $obj) { // Check that Key is a full file path and not just a "directory" if ($obj['Key'] != $prefix) { $file_urls[] = $this->get_bucket_url().$obj['Key']; } } } return $file_urls; } }Następnie, jeśli przechowujemy każdy awatar pod ścieżką „/users/${user_id}/”, przekazując ten prefiks, otrzymamy listę wszystkich plików:
$user_id = get_current_user_id(); $prefix = "/users/${user_id}/"; foreach ($avatarcropper->get_file_urls($prefix) as $file_url) { printf( "<img src='%s'>", $file_url ); }Wniosek
W tym artykule zbadaliśmy, jak wykorzystać rozwiązanie do przechowywania obiektów w chmurze, aby działać jako wspólne repozytorium do przechowywania plików aplikacji wdrożonych na wielu serwerach. W przypadku rozwiązania skupiliśmy się na AWS S3 i przystąpiliśmy do pokazania kroków, które należy zintegrować z aplikacją: tworzenie zasobnika, konfigurowanie uprawnień użytkownika oraz pobieranie i instalowanie SDK. Na koniec wyjaśniliśmy, jak uniknąć pułapek bezpieczeństwa w aplikacji, i zobaczyliśmy przykłady kodu pokazujące, jak wykonać najbardziej podstawowe operacje na S3: przesyłanie, pobieranie i wyświetlanie plików, z których każdy ledwo wymagał kilku linijek kodu. Prostota rozwiązania pokazuje, że integracja usług chmurowych z aplikacją nie jest trudna, a mogą tego dokonać również programiści, którzy nie mają dużego doświadczenia z chmurą.