
Tworzenie bezserwerowych aplikacji typu front-end za pomocą Google Cloud Platform
Opublikowany: 2022-03-10Ostatnio paradygmat tworzenia aplikacji zaczął się zmieniać z ręcznego wdrażania, skalowania i aktualizowania zasobów używanych w aplikacji do polegania na zewnętrznych dostawcach usług w chmurze, którzy zajmują się większością zarządzania tymi zasobami.
Jako programista lub organizacja, która chce zbudować aplikację dopasowaną do rynku w możliwie najkrótszym czasie, Twoim głównym celem może być dostarczanie użytkownikom podstawowych usług aplikacyjnych, podczas gdy Ty spędzasz mniej czasu na konfigurowaniu, wdrażaniu i testowaniu warunków skrajnych Twoje zgłoszenie. W takim przypadku najlepszym rozwiązaniem może być obsługa logiki biznesowej aplikacji w sposób bezserwerowy. Ale jak?
Ten artykuł jest przydatny dla inżynierów frontonu, którzy chcą zbudować określone funkcje w swojej aplikacji, lub inżynierów zaplecza, którzy chcą wyodrębnić i obsłużyć określoną funkcjonalność z istniejącej usługi zaplecza za pomocą aplikacji bezserwerowej wdrożonej na Google Cloud Platform.
Uwaga : Aby skorzystać z tego, co zostanie tutaj omówione, musisz mieć doświadczenie w pracy z React. Nie jest wymagane wcześniejsze doświadczenie w aplikacjach bezserwerowych.
Zanim zaczniemy, zrozummy, czym naprawdę są aplikacje bezserwerowe i jak można wykorzystać architekturę bezserwerową podczas budowania aplikacji w kontekście inżyniera front-endu.
Aplikacje bezserwerowe
Aplikacje bezserwerowe to aplikacje podzielone na małe, sterowane zdarzeniami funkcje wielokrotnego użytku, hostowane i zarządzane przez zewnętrznych dostawców usług w chmurze w chmurze publicznej w imieniu autora aplikacji. Są one wyzwalane przez określone zdarzenia i wykonywane na żądanie. Chociaż przyrostek „ less ” dołączony do słowa serverless wskazuje na brak serwera, nie jest to 100% sprawa. Aplikacje te nadal działają na serwerach i innych zasobach sprzętowych, ale w tym przypadku zasoby te nie są udostępniane przez programistę, ale przez zewnętrznego dostawcę usług w chmurze. Są więc bezserwerowe dla autora aplikacji, ale nadal działają na serwerach i są dostępne przez publiczny Internet.
Przykładowym przypadkiem użycia aplikacji bezserwerowej byłoby wysyłanie wiadomości e-mail do potencjalnych użytkowników, którzy odwiedzają Twoją stronę docelową i subskrybują otrzymywanie wiadomości e-mail z wprowadzeniem produktu. Na tym etapie prawdopodobnie nie masz uruchomionej usługi zaplecza i nie chcesz poświęcać czasu ani zasobów potrzebnych do tworzenia, wdrażania i zarządzania nią, a wszystko to dlatego, że musisz wysyłać wiadomości e-mail. Tutaj możesz napisać pojedynczy plik, który korzysta z klienta poczty e-mail i wdrożyć go u dowolnego dostawcy chmury, który obsługuje aplikację bezserwerową, i pozwolić mu zarządzać tą aplikacją w Twoim imieniu podczas łączenia tej aplikacji bezserwerowej ze stroną docelową.
Chociaż istnieje wiele powodów, dla których warto rozważyć wykorzystanie aplikacji bezserwerowych lub funkcji Functions As A Service (FAAS) w przypadku aplikacji typu front-end, oto kilka ważnych powodów, które należy wziąć pod uwagę:
- Automatyczne skalowanie aplikacji
Aplikacje bezserwerowe są skalowane w poziomie, a to „ skalowanie w górę ” jest wykonywane automatycznie przez dostawcę chmury na podstawie liczby wywołań, więc programista nie musi ręcznie dodawać ani usuwać zasobów, gdy aplikacja jest mocno obciążona. - Opłacalność
Będąc sterowanym zdarzeniami, aplikacje bezserwerowe działają tylko wtedy, gdy są potrzebne, co odzwierciedla opłaty, ponieważ są one rozliczane na podstawie czasu wywołania. - Elastyczność
Aplikacje bezserwerowe są zbudowane tak, aby były w wysokim stopniu wielokrotnego użytku, co oznacza, że nie są powiązane z pojedynczym projektem lub aplikacją. Konkretną funkcjonalność można wyodrębnić do aplikacji bezserwerowej, wdrożyć i używać w wielu projektach lub aplikacjach. Aplikacje bezserwerowe można również napisać w preferowanym języku autora aplikacji, chociaż niektórzy dostawcy usług w chmurze obsługują tylko mniejszą liczbę języków.
Korzystając z aplikacji bezserwerowych, każdy programista ma do dyspozycji szeroką gamę dostawców chmury w chmurze publicznej. W kontekście tego artykułu skupimy się na aplikacjach bezserwerowych w Google Cloud Platform — jak są one tworzone, zarządzane, wdrażane oraz jak integrują się z innymi produktami w Google Cloud. W tym celu dodamy nowe funkcjonalności do istniejącej aplikacji React podczas pracy nad procesem:
- Przechowywanie i pobieranie danych użytkownika w chmurze;
- Tworzenie i zarządzanie zadaniami cron w Google Cloud;
- Wdrażanie funkcji chmury w Google Cloud.
Uwaga : aplikacje bezserwerowe nie są powiązane tylko z Reactem, o ile preferowana platforma lub biblioteka frontonu może wysyłać żądanie HTTP , może korzystać z aplikacji bezserwerowej.
Funkcje chmury Google
Google Cloud umożliwia programistom tworzenie aplikacji bezserwerowych przy użyciu Cloud Functions i uruchamianie ich przy użyciu Functions Framework. Jak się je nazywa, funkcje Cloud są funkcjami sterowanymi zdarzeniami wielokrotnego użytku, wdrażanymi w Google Cloud w celu nasłuchiwania określonego wyzwalacza spośród sześciu dostępnych wyzwalaczy zdarzeń, a następnie wykonania operacji, do której zostały napisane.
Funkcje w chmurze, które są krótkotrwałe ( z domyślnym czasem wykonania 60 sekund i maksymalnie 9 minut ) mogą być pisane przy użyciu JavaScript, Python, Golang i Java i wykonywane przy użyciu ich środowiska uruchomieniowego. W JavaScript można je wykonywać tylko przy użyciu niektórych dostępnych wersji środowiska uruchomieniowego Node i są napisane w postaci modułów CommonJS przy użyciu zwykłego JavaScript, ponieważ są eksportowane jako podstawowa funkcja do uruchomienia w Google Cloud.
Przykładem funkcji w chmurze jest ta poniżej, która jest pustym szablonem dla funkcji do obsługi danych użytkownika.
// index.js exports.firestoreFunction = function (req, res) { return res.status(200).send({ data: `Hello ${req.query.name}` }); } Powyżej mamy moduł, który eksportuje funkcję. Po wykonaniu odbiera argumenty żądania i odpowiedzi podobne do trasy HTTP .
Uwaga : funkcja chmury dopasowuje każdy protokół HTTP po wysłaniu żądania. Warto to zauważyć, oczekując danych w argumencie żądania, ponieważ dane dołączone podczas żądania wykonania funkcji w chmurze byłyby obecne w treści żądania dla żądań POST , natomiast w treści zapytania dla żądań GET .
Funkcje w chmurze można wykonywać lokalnie podczas programowania, instalując pakiet @google-cloud/functions-framework w tym samym folderze, w którym znajduje się napisana funkcja, lub wykonując instalację globalną, aby używać jej dla wielu funkcji, uruchamiając npm i -g @google-cloud/functions-framework z wiersza poleceń. Po zainstalowaniu należy go dodać do skryptu package.json z nazwą wyeksportowanego modułu podobną do poniższej:
"scripts": { "start": "functions-framework --target=firestoreFunction --port=8000", } Powyżej mamy pojedyncze polecenie w naszych skryptach w pliku package.json , które uruchamia framework functions, a także określa funkcję firestoreFunction jako funkcję docelową, która ma być uruchomiona lokalnie na porcie 8000 .
Możemy przetestować punkt końcowy tej funkcji, wysyłając żądanie GET do portu 8000 na hoście lokalnym za pomocą curl. Wklejenie poniższego polecenia w terminalu zrobi to i zwróci odpowiedź.
curl https://localhost:8000?name="Smashing Magazine Author" Powyższe polecenie wykonuje żądanie metodą GET HTTP i odpowiada kodem statusu 200 oraz danymi obiektowymi zawierającymi nazwę dodaną w zapytaniu.
Wdrażanie funkcji chmury
Spośród dostępnych metod wdrażania jednym z szybkich sposobów wdrożenia funkcji chmury z komputera lokalnego jest użycie pakietu SDK chmury po jego zainstalowaniu. Uruchomienie poniższego polecenia z terminala po uwierzytelnieniu pakietu gcloud sdk w projekcie w Google Cloud spowoduje wdrożenie lokalnie utworzonej funkcji w usłudze Cloud Function.
gcloud functions deploy "demo-function" --runtime nodejs10 --trigger-http --entry-point=demo --timeout=60 --set-env-vars=[name="Developer"] --allow-unauthenticatedKorzystając z wyjaśnionych poniżej flag, powyższe polecenie wdraża funkcję wyzwalaną przez HTTP w chmurze Google o nazwie „ funkcja demo ”.
- IMIĘ
Jest to nazwa nadana funkcji chmury podczas jej wdrażania i jest wymagana. -
region
Jest to region, w którym ma zostać wdrożona funkcja chmury. Domyślnie jest wdrażany wus-central1. -
trigger-http
Powoduje to wybranie HTTP jako typu wyzwalacza funkcji. -
allow-unauthenticated
Dzięki temu funkcja może być wywoływana poza Google Cloud przez Internet przy użyciu wygenerowanego punktu końcowego bez sprawdzania, czy osoba wywołująca jest uwierzytelniona. -
source
Ścieżka lokalna z terminala do pliku zawierającego funkcję do wdrożenia. -
entry-point
Jest to konkretny wyeksportowany moduł do wdrożenia z pliku, w którym napisano funkcje. -
runtime
Jest to środowisko uruchomieniowe języka, które ma być używane dla funkcji z tej listy akceptowanych środowisk wykonawczych. -
timeout
Jest to maksymalny czas działania funkcji przed przekroczeniem limitu czasu. Domyślnie wynosi 60 sekund i można go ustawić na maksymalnie 9 minut.
Uwaga : Nadanie funkcji zezwalania na nieuwierzytelnione żądania oznacza, że każdy, kto ma punkt końcowy Twojej funkcji, może również wysyłać żądania bez Twojej zgody. Aby to złagodzić, możemy upewnić się, że punkt końcowy pozostaje prywatny, używając go za pośrednictwem zmiennych środowiskowych lub żądając nagłówków autoryzacji przy każdym żądaniu.
Teraz, gdy nasza funkcja demonstracyjna została wdrożona i mamy punkt końcowy, możemy przetestować tę funkcję tak, jakby była używana w rzeczywistej aplikacji, korzystając z globalnej instalacji działka automatycznego. Uruchomienie autocannon -d=5 -c=300 CLOUD_FUNCTION_URL z otwartego terminala wygeneruje 300 jednoczesnych żądań do funkcji chmury w ciągu 5 sekund. To więcej niż wystarczy, aby uruchomić funkcję w chmurze, a także wygenerować pewne metryki, które możemy eksplorować na pulpicie nawigacyjnym funkcji.
Uwaga : Punkt końcowy funkcji zostanie wydrukowany w terminalu po wdrożeniu. Jeśli tak nie jest, uruchom gcloud function describe FUNCTION_NAME z terminala, aby uzyskać szczegółowe informacje o wdrożonej funkcji, w tym o punkcie końcowym.
Korzystając z zakładki metryk na pulpicie nawigacyjnym, możemy zobaczyć wizualną reprezentację ostatniego żądania, składającą się z liczby wykonanych wywołań, czasu ich trwania, śladu pamięci funkcji i liczby wystąpień uruchomionych w celu obsługi wykonanych żądań.
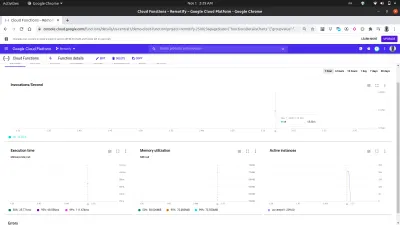
Bliższe spojrzenie na wykres aktywnych instancji na powyższym obrazku pokazuje możliwości skalowania w poziomie funkcji Cloud Functions, ponieważ widzimy, że 209 instancji zostało rozkręconych w ciągu kilku sekund, aby obsłużyć żądania wysłane za pomocą działka automatycznego.
Dzienniki funkcji chmury
Każda funkcja wdrożona w chmurze Google ma dziennik i za każdym razem, gdy ta funkcja jest wykonywana, tworzony jest nowy wpis do tego dziennika. Z zakładki Log na pulpicie funkcji możemy zobaczyć listę wszystkich wpisów logów z funkcji w chmurze.
Poniżej znajdują się wpisy dziennika z naszej wdrożonej demo-function utworzonej w wyniku próśb, które wysłaliśmy za pomocą autocannon .
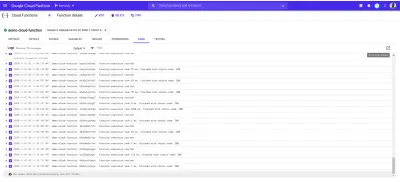
Każdy z powyższych wpisów dziennika pokazuje dokładnie, kiedy funkcja została wykonana, jak długo trwało wykonanie i jakim kodem statusu się zakończyła. W przypadku wystąpienia błędów wynikających z funkcji, szczegóły błędu, w tym linia, w której wystąpił, zostaną wyświetlone w logach w tym miejscu.
Eksplorator logów w Google Cloud może być używany do wyświetlania bardziej szczegółowych informacji o logach z funkcji chmury.
Funkcje chmury z aplikacjami front-end
Funkcje chmury są bardzo przydatne i potężne dla inżynierów front-end. Inżynier frontonu bez wiedzy na temat zarządzania aplikacjami zaplecza może wyodrębnić funkcjonalność do funkcji w chmurze, wdrożyć w Google Cloud i użyć w aplikacji frontonu, wysyłając żądania HTTP do funkcji w chmurze za pośrednictwem jej punktu końcowego.
Aby pokazać, jak można wykorzystać funkcje chmury w aplikacji front-endowej, dodamy więcej funkcji do tej aplikacji React. Aplikacja ma już podstawowy routing między uwierzytelnianiem a konfiguracją strony głównej. Rozbudujemy go o wykorzystanie React Context API do zarządzania stanem naszej aplikacji, ponieważ wykorzystanie stworzonych funkcji chmurowych odbywałoby się w ramach reduktorów aplikacji.
Na początek tworzymy kontekst naszej aplikacji za pomocą API createContext , a także tworzymy reduktor do obsługi akcji w naszej aplikacji.
// state/index.js import { createContext } from “react”;export const UserReducer = (akcja, stan) => { switch (action.type) { case „CREATE-USER”: przerwa; przypadek „UPLOAD-USER-IMAGE”: przerwa; wielkość liter „FETCH-DATA” : przerwa wielkość liter „LOGOUT” : przerwa; domyślnie: console.log(
${action.type} is not recognized) } };export const userState = { user: null, isLoggedIn : false };
export const UserContext = createContext(userState);
Powyżej rozpoczęliśmy od stworzenia funkcji UserReducer , która zawiera instrukcję switch, pozwalającą na wykonanie operacji w oparciu o typ wysłanej do niej akcji. Instrukcja switch ma cztery przypadki i są to działania, które będziemy obsługiwać. Na razie nic nie robią, ale gdy zaczniemy integrować się z naszymi funkcjami w chmurze, będziemy stopniowo wdrażać akcje, które mają być w nich wykonywane.
Stworzyliśmy również i wyeksportowaliśmy kontekst naszej aplikacji za pomocą interfejsu API React createContext i nadaliśmy mu domyślną wartość obiektu userState , który zawiera obecnie wartość użytkownika, która po uwierzytelnieniu zostanie zaktualizowana z null do danych użytkownika, a także wartość logiczną isLoggedIn , aby wiedzieć, czy użytkownik jest zalogowany lub nie.
Teraz możemy przystąpić do korzystania z naszego kontekstu, ale zanim to zrobimy, musimy owinąć całe drzewo aplikacji dostawcą dołączonym do UserContext , aby komponenty potomne mogły subskrybować zmianę wartości naszego kontekstu.
// index.js import React from "react"; import ReactDOM from "react-dom"; import "./index.css"; import App from "./app"; import { UserContext, userState } from "./state/"; ReactDOM.render( <React.StrictMode> <UserContext.Provider value={userState}> <App /> </UserContext.Provider> </React.StrictMode>, document.getElementById("root") ); serviceWorker.unregister(); Opakowujemy naszą aplikację enter z dostawcą UserContext w komponencie głównym i przekazaliśmy naszą wcześniej utworzoną wartość domyślną userState we właściwości wartości.
Teraz, gdy mamy już w pełni skonfigurowany stan naszej aplikacji, możemy przejść do tworzenia modelu danych użytkownika za pomocą Google Cloud Firestore poprzez funkcję chmury.
Obsługa danych aplikacji
Dane użytkownika w tej aplikacji składają się z unikalnego identyfikatora, adresu e-mail, hasła i adresu URL obrazu. Korzystając z funkcji chmury, dane te będą przechowywane w chmurze za pomocą usługi Cloud Firestore, która jest oferowana na platformie Google Cloud.
Google Cloud Firestore , elastyczna baza danych NoSQL, została wydzielona z bazy danych czasu rzeczywistego Firebase z nowymi ulepszonymi funkcjami, które pozwalają na bogatsze i szybsze zapytania oraz obsługę danych offline. Dane w usłudze Firestore są zorganizowane w kolekcje i dokumenty podobne do innych baz danych NoSQL, takich jak MongoDB.
Firestore jest dostępny wizualnie za pośrednictwem Google Cloud Console. Aby go uruchomić, otwórz lewy panel nawigacyjny i przewiń w dół do sekcji Baza danych i kliknij Firestore. Spowoduje to wyświetlenie listy kolekcji dla użytkowników z istniejącymi danymi lub monitowanie użytkownika o utworzenie nowej kolekcji, gdy nie ma istniejącej kolekcji. Stworzylibyśmy kolekcję użytkowników do wykorzystania przez naszą aplikację.
Podobnie jak inne usługi w Google Cloud Platform, Cloud Firestore ma również bibliotekę klienta JavaScript zbudowaną do użytku w środowisku węzła ( w przypadku użycia w przeglądarce zostanie zgłoszony błąd ). Do improwizacji używamy Cloud Firestore w funkcji chmury przy użyciu pakietu @google-cloud/firestore .
Korzystanie z Cloud Firestore z funkcją chmury
Na początek zmienimy nazwę pierwszej utworzonej funkcji z demo-function firestoreFunction , a następnie rozszerzymy ją, aby połączyć się z Firestore i zapisać dane w kolekcji naszych użytkowników.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const { SecretManagerServiceClient } = require("@google-cloud/secret-manager"); const client = new SecretManagerServiceClient(); exports.firestoreFunction = function (req, res) { return { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); console.log(document) // prints details of the collection to the function logs if (!type) { res.status(422).send("An action type was not specified"); } switch (type) { case "CREATE-USER": break case "LOGIN-USER": break; default: res.status(422).send(`${type} is not a valid function action`) } }; Aby obsłużyć więcej operacji związanych z fire-store, dodaliśmy instrukcję switch z dwoma przypadkami, aby obsłużyć potrzeby uwierzytelniania naszej aplikacji. Nasza instrukcja switch ocenia wyrażenie type , które dodajemy do treści żądania podczas wysyłania żądania do tej funkcji z naszej aplikacji i za każdym razem, gdy dane tego type nie są obecne w naszej treści żądania, żądanie jest identyfikowane jako Bad Request i kod stanu 400 wraz z komunikatem wskazującym brakujący type jest wysyłany jako odpowiedź.
Nawiązujemy połączenie z Firestore za pomocą biblioteki Application Default Credentials (ADC) w bibliotece klienta Cloud Firestore. W kolejnym wierszu wywołujemy metodę collection w innej zmiennej i przekazujemy nazwę naszej kolekcji. Wykorzystamy to do dalszych operacji na gromadzeniu zawartych dokumentów.
Uwaga : biblioteki klienta dla usług w Google Cloud łączą się z odpowiednią usługą za pomocą utworzonego klucza konta usługi przekazanego podczas inicjowania konstruktora. Gdy klucz konta usługi nie jest obecny, domyślnie używa się domyślnych poświadczeń aplikacji, które z kolei łączą się przy użyciu IAM uprawnień przypisanych do funkcji w chmurze.
Po edycji kodu źródłowego funkcji, która została wdrożona lokalnie przy użyciu Gcloud SDK, możemy ponownie uruchomić poprzednie polecenie z terminala, aby zaktualizować i ponownie wdrożyć funkcję w chmurze.
Teraz, gdy połączenie zostało nawiązane, możemy zaimplementować przypadek CREATE-USER , aby utworzyć nowego użytkownika przy użyciu danych z treści żądania.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const path = require("path"); const { v4 : uuid } = require("uuid") const cors = require("cors")({ origin: true }); const client = new SecretManagerServiceClient(); exports.firestoreFunction = function (req, res) { return cors(req, res, () => { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); if (!type) { res.status(422).send("An action type was not specified"); } switch (type) { case "CREATE-USER": if (!email || !password) { res.status(422).send("email and password fields missing"); } const id = uuid() return bcrypt.genSalt(10, (err, salt) => { bcrypt.hash(password, salt, (err, hash) => { document.doc(id) .set({ id : id email: email, password: hash, img_uri : null }) .then((response) => res.status(200).send(response)) .catch((e) => res.status(501).send({ error : e }) ); }); }); case "LOGIN": break; default: res.status(400).send(`${type} is not a valid function action`) } }); }; Wygenerowaliśmy UUID za pomocą pakietu uuid, który będzie używany jako identyfikator dokumentu, który ma zostać zapisany, przekazując go do metody set na dokumencie, a także identyfikatora użytkownika. Domyślnie na każdym wstawianym dokumencie generowany jest losowy identyfikator, ale w tym przypadku zaktualizujemy dokument podczas obsługi przesyłania obrazu, a UUID zostanie użyty do zaktualizowania konkretnego dokumentu. Zamiast przechowywać hasło użytkownika w postaci zwykłego tekstu, najpierw solimy je za pomocą bcryptjs, a następnie przechowujemy wynikowy skrót jako hasło użytkownika.

Integrując funkcję chmury firestoreFunction z aplikacją, używamy jej ze sprawy CREATE_USER w ramach reduktora użytkownika.
Po kliknięciu przycisku Utwórz konto wysyłana jest akcja do reduktorów typu CREATE_USER w celu wykonania POST zawierającego wpisany adres e-mail i hasło do punktu końcowego funkcji firestoreFunction .
import { createContext } from "react"; import { navigate } from "@reach/router"; import Axios from "axios"; export const userState = { user : null, isLoggedIn: false, }; export const UserReducer = (state, action) => { switch (action.type) { case "CREATE_USER": const FIRESTORE_FUNCTION = process.env.REACT_APP_FIRESTORE_FUNCTION; const { userEmail, userPassword } = action; const data = { type: "CREATE-USER", email: userEmail, password: userPassword, }; Axios.post(`${FIRESTORE_FUNCTION}`, data) .then((res) => { navigate("/home"); return { ...state, isLoggedIn: true }; }) .catch((e) => console.log(`couldnt create user. error : ${e}`)); break; case "LOGIN-USER": break; case "UPLOAD-USER-IMAGE": break; case "FETCH-DATA" : break case "LOGOUT": navigate("/login"); return { ...state, isLoggedIn: false }; default: break; } }; export const UserContext = createContext(userState); Powyżej wykorzystaliśmy Axios do wykonania żądania do funkcji firestoreFunction i po rozwiązaniu tego żądania ustawiamy stan początkowy użytkownika z null na dane zwrócone z żądania i na koniec kierujemy użytkownika do strony głównej jako uwierzytelniony użytkownik .
W tym momencie nowy użytkownik może pomyślnie utworzyć konto i zostać przekierowanym na stronę główną. Ten proces pokazuje, w jaki sposób używamy Firestore do wykonywania podstawowego tworzenia danych z funkcji chmury.
Obsługa przechowywania plików
Przechowywanie i pobieranie plików użytkownika w aplikacji jest najczęściej bardzo potrzebną funkcją w aplikacji. W aplikacji połączonej z backendem node.js Multer jest często używany jako oprogramowanie pośredniczące do obsługi danych wieloczęściowych/formularzy, w których pojawia się przesłany plik. Ale w przypadku braku backendu node.js, moglibyśmy użyć pliku online usługa przechowywania, taka jak Google Cloud Storage do przechowywania statycznych zasobów aplikacji.
Google Cloud Storage to globalnie dostępna usługa przechowywania plików służąca do przechowywania dowolnej ilości danych jako obiektów dla aplikacji w zasobnikach. Jest wystarczająco elastyczny, aby obsłużyć przechowywanie aktywów statycznych zarówno dla małych, jak i dużych aplikacji.
Aby korzystać z usługi Cloud Storage w aplikacji, możemy skorzystać z dostępnych punktów końcowych Storage API lub skorzystać z oficjalnej biblioteki klienta węzła Storage. Jednak biblioteka klienta Node Storage nie działa w oknie przeglądarki, więc moglibyśmy skorzystać z funkcji chmury, w której będziemy korzystać z biblioteki.
Przykładem tego jest poniższa funkcja Cloud, która łączy i przesyła plik do utworzonego zasobnika Cloud.
const cors = require("cors")({ origin: true }); const { Storage } = require("@google-cloud/storage"); const StorageClient = new Storage(); exports.Uploader = (req, res) => { const { file } = req.body; StorageClient.bucket("TEST_BUCKET") .file(file.name) .then((response) => { console.log(response); res.status(200).send(response) }) .catch((e) => res.status(422).send({error : e})); }); };Z powyższej funkcji chmury wykonujemy dwie główne operacje:
Najpierw tworzymy połączenie z Cloud Storage w
Storage constructori korzystamy z funkcji Application Default Credentials (ADC) w Google Cloud do uwierzytelniania w Cloud Storage.Po drugie, przesyłamy plik zawarty w treści żądania do naszego
TEST_BUCKET, wywołując metodę.filei podając nazwę pliku. Ponieważ jest to operacja asynchroniczna, używamy obietnicy, aby wiedzieć, kiedy ta akcja została rozwiązana i wysyłamy odpowiedź200, kończąc w ten sposób cykl życia wywołania.
Teraz możemy rozszerzyć powyższą funkcję Uploader w chmurze, aby obsłużyć przesyłanie obrazu profilu użytkownika. Funkcja chmury otrzyma obraz profilu użytkownika, przechowa go w zasobniku chmury naszej aplikacji, a następnie zaktualizuje dane img_uri użytkownika w kolekcji naszych użytkowników w usłudze Firestore.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const cors = require("cors")({ origin: true }); const { Storage } = require("@google-cloud/storage"); const StorageClient = new Storage(); const BucketName = process.env.STORAGE_BUCKET exports.Uploader = (req, res) => { return Cors(req, res, () => { const { file , userId } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); StorageClient.bucket(BucketName) .file(file.name) .on("finish", () => { StorageClient.bucket(BucketName) .file(file.name) .makePublic() .then(() => { const img_uri = `https://storage.googleapis.com/${Bucket}/${file.path}`; document .doc(userId) .update({ img_uri, }) .then((updateResult) => res.status(200).send(updateResult)) .catch((e) => res.status(500).send(e)); }) .catch((e) => console.log(e)); }); }); };Teraz rozszerzyliśmy powyższą funkcję przesyłania, aby wykonać następujące dodatkowe operacje:
- Po pierwsze, tworzy nowe połączenie z usługą Firestore, aby pobrać naszą kolekcję
users, inicjując konstruktor Firestore i używa domyślnych poświadczeń aplikacji (ADC) do uwierzytelniania w Cloud Storage. - Po przesłaniu pliku dodanego w treści żądania upubliczniamy go, aby był dostępny za pośrednictwem publicznego adresu URL, wywołując metodę
makePublicna przesłanym pliku. Zgodnie z domyślną kontrolą dostępu Cloud Storage, bez upublicznienia pliku, nie można uzyskać dostępu do pliku przez Internet i móc to zrobić po załadowaniu aplikacji.
Uwaga : upublicznienie pliku oznacza, że każda osoba korzystająca z Twojej aplikacji może skopiować łącze do pliku i mieć nieograniczony dostęp do pliku. Jednym ze sposobów, aby temu zapobiec, jest użycie podpisanego adresu URL w celu przyznania tymczasowego dostępu do pliku w zasobniku zamiast upubliczniania go.
- Następnie aktualizujemy istniejące dane użytkownika, aby zawierały adres URL przesłanego pliku. Odnajdujemy dane konkretnego użytkownika za pomocą zapytania Firestore
WHEREi używamy identyfikatora użytkownika zawartego w treści żądania, a następnieimg_uriuserIdaby zawierało adres URL nowo zaktualizowanego obrazu.
Z powyższej funkcji Upload do chmury można korzystać w dowolnej aplikacji, która ma zarejestrowanych użytkowników w usłudze Firestore. Wszystko, co jest potrzebne, aby wysłać żądanie POST do punktu końcowego, umieszczając IS użytkownika i obraz w treści żądania.
Przykładem tego w aplikacji jest przypadek UPLOAD-FILE , który wykonuje żądanie POST do funkcji i umieszcza odsyłacz do obrazu zwrócony z żądania w stanie aplikacji.
# index.js import Axios from 'axios' const UPLOAD_FUNCTION = process.env.REACT_APP_UPLOAD_FUNCTION export const UserReducer = (state, action) => { switch (action.type) { case "CREATE-USER" : # .....CREATE-USER-LOGIC .... case "UPLOAD-FILE": const { file, id } = action return Axios.post(UPLOAD_FUNCTION, { file, id }, { headers: { "Content-Type": "image/png", }, }) .then((response) => {}) .catch((e) => console.log(e)); default : return console.log(`${action.type} case not recognized`) } } Z powyższego przypadku przełącznika, wykonujemy żądanie POST za pomocą Axios do UPLOAD_FUNCTION przekazując w dodanym pliku, który ma być uwzględniony w treści żądania, a także dodaliśmy obraz Content-Type w nagłówku żądania.
Po pomyślnym przesłaniu odpowiedź zwrócona z funkcji chmury zawiera dokument z danymi użytkownika, który został zaktualizowany tak, aby zawierał prawidłowy adres URL obrazu przesłanego do pamięci w chmurze Google. Następnie możemy zaktualizować stan użytkownika, aby zawierał nowe dane, a to zaktualizuje również element src obrazu profilu użytkownika w komponencie profilu.
Obsługa zadań Cron
Powtarzające się automatyczne zadania, takie jak wysyłanie wiadomości e-mail do użytkowników lub wykonywanie działań wewnętrznych o określonej godzinie, są najczęściej dostępną funkcją aplikacji. W zwykłej aplikacji node.js takie zadania mogą być obsługiwane jako zadania cron przy użyciu node-cron lub node-schedule. Podczas tworzenia aplikacji bezserwerowych za pomocą Google Cloud Platform, Cloud Scheduler jest również zaprojektowany do wykonywania operacji cron.
Uwaga : Chociaż Cloud Scheduler działa podobnie do narzędzia cron uniksowego, jeśli chodzi o tworzenie zadań, które będą wykonywane w przyszłości, należy pamiętać, że Cloud Scheduler nie wykonuje polecenia tak, jak robi to narzędzie cron. Raczej wykonuje operację przy użyciu określonego celu.
Jak sama nazwa wskazuje, Cloud Scheduler umożliwia użytkownikom zaplanowanie operacji do wykonania w przyszłości. Każda operacja nazywana jest zadaniem , a zadania można wizualnie tworzyć, aktualizować, a nawet niszczyć w sekcji Scheduler w Cloud Console. Oprócz pola nazwy i opisu zadania w Cloud Scheduler składają się z następujących elementów:
- Częstotliwość
Służy do planowania wykonania zadania Crona. Harmonogramy są określane przy użyciu formatu unix-cron, który jest pierwotnie używany podczas tworzenia zadań w tle w tabeli cron w środowisku Linux. Format unix-cron składa się z ciągu znaków z pięcioma wartościami, z których każda reprezentuje punkt czasowy. Poniżej możemy zobaczyć każdy z pięciu ciągów i wartości, które reprezentują.
- - - - - - - - - - - - - - - - minute ( - 59 ) | - - - - - - - - - - - - - hour ( 0 - 23 ) | | - - - - - - - - - - - - day of month ( 1 - 31 ) | | | - - - - - - - - - month ( 1 - 12 ) | | | | - - - - - -- day of week ( 0 - 6 ) | | | | | | | | | | | | | | | | | | | | | | | | | * * * * *Narzędzie generatora Crontab przydaje się podczas próby wygenerowania wartości częstotliwość-czas dla zadania. Jeśli masz trudności ze złożeniem wartości czasu, generator Crontab ma wizualną listę rozwijaną, w której możesz wybrać wartości, które składają się na harmonogram, a następnie skopiować wygenerowaną wartość i użyć jako częstotliwości.
- Strefa czasowa
Strefa czasowa, z której wykonywane jest zadanie cron. Ze względu na różnicę czasu między strefami czasowymi, zadania cron wykonywane z różnymi określonymi strefami czasowymi będą miały różne czasy wykonania. - Cel
To jest używane w wykonaniu określonego zadania. Cel może być typemHTTP, w którym zadanie wysyła żądanie w określonym czasie do adresu URL lub tematu Pub/Sub, do którego zadanie może publikować lub pobierać komunikaty, a na koniec do aplikacji App Engine.
Cloud Scheduler doskonale łączy się z funkcjami chmury wyzwalanymi przez HTTP. Gdy zadanie w Cloud Scheduler jest tworzone z celem ustawionym na HTTP, to zadanie może zostać użyte do wykonania funkcji chmury. Wszystko, co należy zrobić, to określić punkt końcowy funkcji w chmurze, określić czasownik HTTP żądania, a następnie dodać wszelkie dane, które mają zostać przekazane do funkcji w wyświetlonym polu treści. Jak pokazano w poniższym przykładzie:
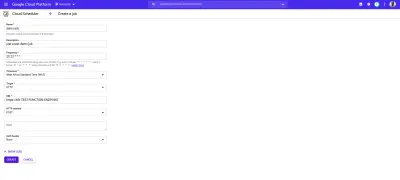
Zadanie cron na powyższym obrazku będzie uruchamiane codziennie o 9 rano, wysyłając żądanie POST do przykładowego punktu końcowego funkcji w chmurze.
Bardziej realistycznym przypadkiem użycia zadania cron jest wysyłanie zaplanowanych wiadomości e-mail do użytkowników w określonych odstępach czasu za pomocą zewnętrznej usługi pocztowej, takiej jak Mailgun. Aby zobaczyć to w akcji, utworzymy nową funkcję chmury, która wyśle wiadomość e-mail w formacie HTML na określony adres e-mail za pomocą pakietu nodemailer JavaScript, aby połączyć się z Mailgun:
# index.js require("dotenv").config(); const nodemailer = require("nodemailer"); exports.Emailer = (req, res) => { let sender = process.env.SENDER; const { reciever, type } = req.body var transport = nodemailer.createTransport({ host: process.env.HOST, port: process.env.PORT, secure: false, auth: { user: process.env.SMTP_USERNAME, pass: process.env.SMTP_PASSWORD, }, }); if (!reciever) { res.status(400).send({ error: `Empty email address` }); } transport.verify(function (error, success) { if (error) { res .status(401) .send({ error: `failed to connect with stmp. check credentials` }); } }); switch (type) { case "statistics": return transport.sendMail( { from: sender, to: reciever, subject: "Your usage satistics of demo app", html: { path: "./welcome.html" }, }, (error, info) => { if (error) { res.status(401).send({ error : error }); } transport.close(); res.status(200).send({data : info}); } ); default: res.status(500).send({ error: "An available email template type has not been matched.", }); } };Using the cloud function above we can send an email to any user's email address specified as the receiver value in the request body. It performs the sending of emails through the following steps:
- It creates an SMTP transport for sending messages by passing the
host,userandpasswhich stands for password, all displayed on the user's Mailgun dashboard when a new account is created. - Next, it verifies if the SMTP transport has the credentials needed in order to establish a connection. If there's an error in establishing the connection, it ends the function's invocation and sends back a
401 unauthenticatedstatus code. - Next, it calls the
sendMailmethod to send the email containing the HTML file as the email's body to the receiver's email address specified in thetofield.
Note : We use a switch statement in the cloud function above to make it more reusable for sending several emails for different recipients. This way we can send different emails based on the type field included in the request body when calling this cloud function.
Now that there is a function that can send an email to a user; we are left with creating the cron job to invoke this cloud function. This time, the cron jobs are created dynamically each time a new user is created using the official Google cloud client library for the Cloud Scheduler from the initial firestoreFunction .
We expand the CREATE-USER case to create the job which sends the email to the created user at a one-day interval.
require("dotenv").config();cloc const { Firestore } = require("@google-cloud/firestore"); const scheduler = require("@google-cloud/scheduler") const cors = require("cors")({ origin: true }); const EMAILER = proccess.env.EMAILER_ENDPOINT const parent = ScheduleClient.locationPath( process.env.PROJECT_ID, process.env.LOCATION_ID ); exports.firestoreFunction = function (req, res) { return cors(req, res, () => { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); const client = new Scheduler.CloudSchedulerClient() if (!type) { res.status(422).send({ error : "An action type was not specified"}); } switch (type) { case "CREATE-USER":const job = { httpTarget: { uri: process.env.EMAIL_FUNCTION_ENDPOINT, httpMethod: "POST", body: { email: email, }, }, schedule: "*/30 */6 */5 10 4", timezone: "Africa/Lagos", }if (!email || !password) { res.status(422).send("email and password fields missing"); } return bcrypt.genSalt(10, (err, salt) => { bcrypt.hash(password, salt, (err, hash) => { document .add({ email: email, password: hash, }) .then((response) => {client.createJob({ parent : parent, job : job }).then(() => res.status(200).send(response)) .catch(e => console.log(`unable to create job : ${e}`) )}) .catch((e) => res.status(501).send(`error inserting data : ${e}`) ); }); }); default: res.status(422).send(`${type} is not a valid function action`) } }); };
From the snippet above, we can see the following:
- A connection to the Cloud Scheduler from the Scheduler constructor using the Application Default Credentials (ADC) is made.
- We create an object consisting of the following details which make up the cron job to be created:
-
uri
The endpoint of our email cloud function in which a request would be made to. -
body
This is the data containing the email address of the user to be included when the request is made. -
schedule
The unix cron format representing the time when this cron job is to be performed.
-
- After the promise from inserting the user's data document is resolved, we create the cron job by calling the
createJobmethod and passing in the job object and the parent. - The function's execution is ended with a
200status code after the promise from thecreateJoboperation has been resolved.
After the job is created, we'll see it listed on the scheduler page.
From the image above we can see the time scheduled for this job to be executed. We can decide to manually run this job or wait for it to be executed at the scheduled time.
Wniosek
Within this article, we have had a good look into serverless applications and the benefits of using them. We also had an extensive look at how developers can manage their serverless applications on the Google Cloud using Cloud Functions so you now know how the Google Cloud is supporting the use of serverless applications.
Within the next years to come, we will certainly see a large number of developers adapt to the use of serverless applications when building applications. If you are using cloud functions in a production environment, it is recommended that you read this article from a Google Cloud advocate on “6 Strategies For Scaling Your Serverless Applications”.
The source code of the created cloud functions are available within this Github repository and also the used front-end application within this Github repository. The front-end application has been deployed using Netlify and can be tested live here.
Bibliografia
- Google Cloud
- Cloud Functions
- Cloud Source Repositories
- Cloud Scheduler overview
- Cloud Firestore
- “6 Strategies For Scaling Your Serverless Applications,” Preston Holmes