
Powstanie maszyn państwowych
Opublikowany: 2022-03-10Jest już rok 2018, a niezliczeni programiści front-end wciąż prowadzą walkę ze złożonością i bezruchem. Miesiąc po miesiącu szukali świętego Graala: wolnej od błędów architektury aplikacji, która pomoże im szybko dostarczać produkty w wysokiej jakości. Jestem jednym z tych programistów i znalazłem coś interesującego, co może pomóc.
Zrobiliśmy dobry krok naprzód dzięki narzędziom takim jak React i Redux. Jednak same w sobie nie wystarczą w zastosowaniach na dużą skalę. W tym artykule przedstawimy pojęcie maszyn stanowych w kontekście programowania front-end. Prawdopodobnie zbudowałeś już kilka z nich, nie zdając sobie z tego sprawy.
Wprowadzenie do maszyn stanowych
Maszyna stanów to matematyczny model obliczeń. To abstrakcyjna koncepcja, zgodnie z którą maszyna może mieć różne stany, ale w danym momencie spełnia tylko jeden z nich. Istnieją różne typy automatów stanowych. Najbardziej znanym, jak sądzę, jest maszyna Turinga. Jest nieskończoną maszyną stanów, co oznacza, że może mieć nieskończoną liczbę stanów. Maszyna Turinga nie pasuje do dzisiejszego rozwoju interfejsu użytkownika, ponieważ w większości przypadków mamy skończoną liczbę stanów. Dlatego maszyny skończone, takie jak Mealy i Moore, mają więcej sensu.
Różnica między nimi polega na tym, że maszyna Moore'a zmienia swój stan tylko na podstawie poprzedniego stanu. Niestety, mamy do czynienia z wieloma czynnikami zewnętrznymi, takimi jak interakcje użytkowników i procesy sieciowe, co oznacza, że maszyna Moore też nie jest dla nas wystarczająco dobra. To, czego szukamy, to maszyna Mealy. Ma stan początkowy, a następnie przechodzi do nowych stanów na podstawie danych wejściowych i stanu bieżącego.
Jednym z najłatwiejszych sposobów zilustrowania działania automatu stanowego jest spojrzenie na kołowrót. Ma skończoną liczbę stanów: zablokowany i odblokowany. Oto prosta grafika, która pokazuje nam te stany, wraz z ich możliwymi danymi wejściowymi i przejściami.
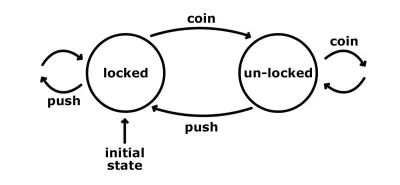
Początkowy stan kołowrotu jest zablokowany. Bez względu na to, ile razy możemy go popchnąć, pozostaje on w tym stanie zablokowanym. Jeśli jednak przekażemy do niego monetę, to przechodzi ona w stan odblokowany. Kolejna moneta w tym momencie nic by nie zrobiła; nadal będzie w stanie odblokowanym. Pchnięcie z drugiej strony zadziałałoby i moglibyśmy spasować. Ta akcja również przenosi komputer do początkowego stanu zablokowanego.
Gdybyśmy chcieli zaimplementować pojedynczą funkcję kontrolującą kołowrót, prawdopodobnie otrzymalibyśmy dwa argumenty: aktualny stan i akcję. A jeśli używasz Redux, prawdopodobnie brzmi to znajomo. Jest to podobne do znanej funkcji reduktora, gdzie otrzymujemy aktualny stan i na podstawie ładunku akcji decydujemy, jaki będzie następny stan. Reduktor to przejście w kontekście automatów stanowych. W rzeczywistości każdą aplikację, która ma stan, który możemy w jakiś sposób zmienić, można nazwać maszyną stanów. Tyle, że wciąż i od nowa wdrażamy wszystko ręcznie.
W jaki sposób maszyna stanowa jest lepsza?
W pracy używamy Reduxa i jestem z niego całkiem zadowolony. Jednak zacząłem widzieć wzory, które mi się nie podobają. Przez „nie lubię” nie mam na myśli, że nie działają. Chodzi raczej o to, że dodają złożoności i zmuszają do pisania większej ilości kodu. Musiałem podjąć się projektu pobocznego, w którym miałem miejsce na eksperymenty, i postanowiłem przemyśleć nasze praktyki programistyczne React i Redux. Zacząłem robić notatki o rzeczach, które mnie dotyczyły, i zdałem sobie sprawę, że abstrakcja maszyny stanów naprawdę rozwiąże niektóre z tych problemów. Wskoczmy i zobaczmy, jak zaimplementować maszynę stanów w JavaScript.
Zaatakujemy prosty problem. Chcemy pobrać dane z interfejsu API zaplecza i wyświetlić je użytkownikowi. Pierwszym krokiem jest nauczenie się myślenia w stanach, a nie w przejściach. Zanim przejdziemy do maszyn stanów, mój przepływ pracy przy tworzeniu takiej funkcji wyglądał mniej więcej tak:
- Wyświetlamy przycisk pobierania danych.
- Użytkownik klika przycisk pobierania danych.
- Uruchom żądanie na zapleczu.
- Pobierz dane i przeanalizuj je.
- Pokaż to użytkownikowi.
- Lub, jeśli wystąpi błąd, wyświetl komunikat o błędzie i pokaż przycisk pobierania danych, abyśmy mogli ponownie uruchomić proces.
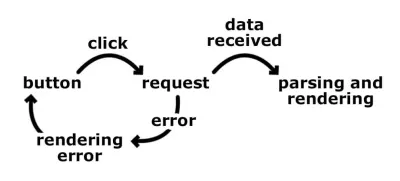
Myślimy liniowo i zasadniczo staramy się objąć wszystkie możliwe kierunki do końcowego wyniku. Jeden krok prowadzi do drugiego i szybko zaczęlibyśmy rozgałęziać nasz kod. A co z problemami, takimi jak dwukrotne kliknięcie przycisku przez użytkownika lub kliknięcie przycisku przez użytkownika podczas oczekiwania na odpowiedź z zaplecza, lub pomyślne zakończenie żądania, ale dane są uszkodzone. W takich przypadkach prawdopodobnie mielibyśmy różne flagi, które pokazują nam, co się stało. Posiadanie flag oznacza więcej klauzul if i, w bardziej złożonych aplikacjach, więcej konfliktów.
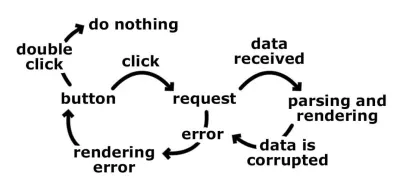
Dzieje się tak, ponieważ myślimy w przejściach. Skupiamy się na tym, jak te przejścia następują iw jakiej kolejności. Skupienie się na różnych stanach aplikacji byłoby znacznie prostsze. Ile mamy stanów i jakie są ich możliwe dane wejściowe? Na tym samym przykładzie:
- bezczynny
W tym stanie wyświetlamy przycisk pobierania danych, siadamy i czekamy. Możliwe działanie to:- Kliknij
Gdy użytkownik kliknie przycisk, uruchamiamy żądanie na zapleczu, a następnie przenosimy komputer do stanu „pobierania”.
- Kliknij
- ujmujący
Prośba jest w locie, a my siedzimy i czekamy. Działania to:- sukces
Dane docierają pomyślnie i nie są uszkodzone. W jakiś sposób wykorzystujemy dane i wracamy do stanu „bezczynności”. - niepowodzenie
Jeśli wystąpi błąd podczas wysyłania żądania lub parsowania danych, przechodzimy w stan „błąd”.
- sukces
- błąd
Pokazujemy komunikat o błędzie i wyświetlamy przycisk pobierania danych. Ten stan akceptuje jedną akcję:- spróbować ponownie
Gdy użytkownik kliknie przycisk ponawiania, ponownie uruchamiamy żądanie i przenosimy komputer do stanu „pobieranie”.
- spróbować ponownie
Opisaliśmy mniej więcej te same procesy, ale ze stanami i danymi wejściowymi.
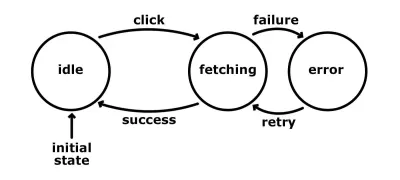
Upraszcza to logikę i czyni ją bardziej przewidywalną. Rozwiązuje również niektóre z wyżej wymienionych problemów. Zauważ, że gdy jesteśmy w stanie „pobierania”, nie akceptujemy żadnych kliknięć. Tak więc, nawet jeśli użytkownik kliknie przycisk, nic się nie stanie, ponieważ komputer nie jest skonfigurowany do reagowania na tę akcję w tym stanie. Takie podejście automatycznie eliminuje nieprzewidywalne rozgałęzienia naszej logiki kodu. Oznacza to, że podczas testowania będziemy mieli mniej kodu do pokrycia . Ponadto niektóre rodzaje testów, takie jak testowanie integracyjne, można zautomatyzować. Pomyśl, jak moglibyśmy mieć naprawdę jasny obraz tego, co robi nasza aplikacja, i moglibyśmy stworzyć skrypt, który sprawdza zdefiniowane stany i przejścia i generuje asercje. Te twierdzenia mogą udowodnić, że osiągnęliśmy każdy możliwy stan lub przebyliśmy konkretną podróż.
W rzeczywistości zapisanie wszystkich możliwych stanów jest łatwiejsze niż zapisanie wszystkich możliwych przejść, ponieważ wiemy, jakich stanów potrzebujemy lub mamy. Nawiasem mówiąc, w większości przypadków stany opisują logikę biznesową naszej aplikacji, podczas gdy przejścia są na początku bardzo często nieznane. Błędy w naszym oprogramowaniu są wynikiem działań wykonanych w złym stanie i/lub w złym czasie. Pozostawiają naszą aplikację w stanie, o którym nie wiemy, a to psuje nasz program lub sprawia, że zachowuje się on niepoprawnie. Oczywiście nie chcemy być w takiej sytuacji. Automaty stanowe to dobre zapory ogniowe . Chronią nas przed osiągnięciem nieznanych stanów, ponieważ wyznaczamy granice tego, co może się wydarzyć i kiedy, nie mówiąc wprost jak. Koncepcja maszyny stanów bardzo dobrze łączy się z jednokierunkowym przepływem danych. Razem zmniejszają złożoność kodu i wyjaśniają, gdzie powstał stan.
Tworzenie maszyny stanowej w JavaScript
Dość gadania — zobaczmy trochę kodu. Użyjemy tego samego przykładu. Na podstawie powyższej listy zaczniemy od:
const machine = { 'idle': { click: function () { ... } }, 'fetching': { success: function () { ... }, failure: function () { ... } }, 'error': { 'retry': function () { ... } } }Mamy stany jako obiekty, a ich możliwe dane wejściowe jako funkcje. Brakuje jednak stanu początkowego. Zmieńmy powyższy kod na ten:
const machine = { state: 'idle', transitions: { 'idle': { click: function() { ... } }, 'fetching': { success: function() { ... }, failure: function() { ... } }, 'error': { 'retry': function() { ... } } } }Po zdefiniowaniu wszystkich stanów, które mają dla nas sens, jesteśmy gotowi do wysłania wejścia i zmiany stanu. Zrobimy to za pomocą dwóch poniższych metod pomocniczych:
const machine = { dispatch(actionName, ...payload) { const actions = this.transitions[this.state]; const action = this.transitions[this.state][actionName]; if (action) { action.apply(machine, ...payload); } }, changeStateTo(newState) { this.state = newState; }, ... } Funkcja dispatch sprawdza, czy w przejściach bieżącego stanu znajduje się akcja o podanej nazwie. Jeśli tak, odpala go z podanym ładunkiem. Wywołujemy również procedurę obsługi action z machine jako kontekstem, dzięki czemu możemy wywołać inne akcje za pomocą this.dispatch(<action>) lub zmienić stan za pomocą this.changeStateTo(<new state>) .
Podążając za podróżą użytkownika z naszego przykładu, pierwszą akcją, którą musimy wysłać, jest click . Oto jak wygląda procedura obsługi tej akcji:
transitions: { 'idle': { click: function () { this.changeStateTo('fetching'); service.getData().then( data => { try { this.dispatch('success', JSON.parse(data)); } catch (error) { this.dispatch('failure', error) } }, error => this.dispatch('failure', error) ); } }, ... } machine.dispatch('click'); Najpierw zmieniamy stan maszyny na fetching . Następnie uruchamiamy żądanie na zapleczu. Załóżmy, że mamy usługę z metodą getData , która zwraca obietnicę. Po rozwiązaniu problemu i pomyślnym przeanalizowaniu danych wysyłamy success , jeśli nie failure .
Na razie w porządku. Następnie musimy zaimplementować działania success i failure oraz dane wejściowe w stanie fetching :
transitions: { 'idle': { ... }, 'fetching': { success: function (data) { // render the data this.changeStateTo('idle'); }, failure: function (error) { this.changeStateTo('error'); } }, ... } Zwróć uwagę, jak uwolniliśmy nasz mózg od myślenia o poprzednim procesie. Nie dbamy o kliknięcia użytkownika ani o to, co dzieje się z żądaniem HTTP. Wiemy, że aplikacja jest w stanie fetching i oczekujemy właśnie tych dwóch działań. To trochę jak pisanie nowej logiki w izolacji.
Ostatni bit to stan error . Byłoby miło, gdybyśmy udostępnili logikę ponawiania prób, aby aplikacja mogła odzyskać sprawność po awarii.
transitions: { 'error': { retry: function () { this.changeStateTo('idle'); this.dispatch('click'); } } } Tutaj musimy powielić logikę, którą napisaliśmy w obsłudze click . Aby tego uniknąć, powinniśmy albo zdefiniować procedurę obsługi jako funkcję dostępną dla obu akcji, albo najpierw przejść do stanu idle , a następnie ręcznie wywołać akcję click .
Pełny przykład działającej maszyny stanów można znaleźć w moim Codepen.
Zarządzanie maszynami stanowymi za pomocą biblioteki
Wzorzec automatu skończonego działa niezależnie od tego, czy używamy Reacta, Vue czy Angulara. Jak widzieliśmy w poprzednim rozdziale, możemy bez większych problemów zaimplementować automat stanów. Czasami jednak biblioteka zapewnia większą elastyczność. Niektóre z tych dobrych to Machina.js i XState. Jednak w tym artykule porozmawiamy o Stent, mojej podobnej do Redux bibliotece, która wykorzystuje koncepcję maszyn skończonych.
Stent to implementacja kontenera maszyn stanowych. Podąża za niektórymi pomysłami z projektów Redux i Redux-Saga, ale moim zdaniem zapewnia prostsze i wolne od schematów procesy. Jest rozwijany przy użyciu programowania opartego na readme, a ja dosłownie spędziłem tygodnie tylko na projektowaniu API. Ponieważ pisałem bibliotekę, miałem szansę naprawić problemy, które napotkałem podczas korzystania z architektur Redux i Flux.

Tworzenie maszyn
W większości przypadków nasze aplikacje obejmują wiele domen. Nie możemy jechać tylko jedną maszyną. Stent pozwala więc na stworzenie wielu maszyn:
import { Machine } from 'stent'; const machineA = Machine.create('A', { state: ..., transitions: ... }); const machineB = Machine.create('B', { state: ..., transitions: ... }); Później możemy uzyskać dostęp do tych maszyn za pomocą metody Machine.get :
const machineA = Machine.get('A'); const machineB = Machine.get('B');Podłączanie maszyn do logiki renderowania
Renderowanie w moim przypadku odbywa się za pomocą Reacta, ale możemy skorzystać z dowolnej innej biblioteki. Sprowadza się to do uruchomienia wywołania zwrotnego, w którym uruchamiamy renderowanie. Jedną z pierwszych funkcji, nad którymi pracowałem, była funkcja connect :
import { connect } from 'stent/lib/helpers'; Machine.create('MachineA', ...); Machine.create('MachineB', ...); connect() .with('MachineA', 'MachineB') .map((MachineA, MachineB) => { ... rendering here }); Mówimy, które maszyny są dla nas ważne i podajemy ich nazwy. Callback, który przekazujemy do map , jest uruchamiany raz na początku, a później za każdym razem, gdy stan niektórych maszyn się zmienia. Tutaj uruchamiamy renderowanie. W tym momencie mamy bezpośredni dostęp do podłączonych maszyn, dzięki czemu możemy pobrać aktualny stan i metody. Istnieją również mapOnce , aby wywołać wywołanie zwrotne tylko raz, i mapSilent , aby pominąć początkowe wykonanie.
Dla wygody helper jest eksportowany specjalnie do integracji z React. Jest bardzo podobny do connect(mapStateToProps) z Redux.
import React from 'react'; import { connect } from 'stent/lib/react'; class TodoList extends React.Component { render() { const { isIdle, todos } = this.props; ... } } // MachineA and MachineB are machines defined // using Machine.create function export default connect(TodoList) .with('MachineA', 'MachineB') .map((MachineA, MachineB) => { isIdle: MachineA.isIdle, todos: MachineB.state.todos }); Stent uruchamia nasze wywołanie zwrotne mapowania i oczekuje, że otrzyma obiekt — obiekt, który jest wysyłany jako props do naszego komponentu React.
Co to jest stan w kontekście stentu?
Do tej pory nasz stan był prostymi strunami. Niestety, w prawdziwym świecie musimy utrzymywać w stanie coś więcej niż tylko ciąg. To dlatego stan Stentu jest w rzeczywistości obiektem posiadającym wewnątrz właściwości. Jedyną zastrzeżoną właściwością jest name . Wszystko inne to dane specyficzne dla aplikacji. Na przykład:
{ name: 'idle' } { name: 'fetching', todos: [] } { name: 'forward', speed: 120, gear: 4 }Moje dotychczasowe doświadczenie ze Stentem pokazuje mi, że jeśli obiekt stanu powiększy się, prawdopodobnie będziemy potrzebować innej maszyny, która obsłuży te dodatkowe właściwości. Identyfikacja różnych stanów zajmuje trochę czasu, ale uważam, że jest to duży krok naprzód w pisaniu łatwiejszych w zarządzaniu aplikacji. To trochę jak przepowiadanie przyszłości i rysowanie ram możliwych działań.
Praca z maszyną stanową
Podobnie jak w przykładzie na początku, musimy zdefiniować możliwe (skończone) stany naszej maszyny i opisać możliwe dane wejściowe:
import { Machine } from 'stent'; const machine = Machine.create('sprinter', { state: { name: 'idle' }, // initial state transitions: { 'idle': { 'run please': function () { return { name: 'running' }; } }, 'running': { 'stop now': function () { return { name: 'idle' }; } } } }); Mamy stan początkowy idle , który akceptuje akcję run . Gdy maszyna jest w stanie running , jesteśmy w stanie wykonać akcję stop , która przywraca nas do stanu idle .
Zapewne pamiętasz wcześniej helpery dispatch i changeStateTo z naszej implementacji. Ta biblioteka zapewnia tę samą logikę, ale jest ukryta wewnętrznie i nie musimy o tym myśleć. Dla wygody, na podstawie właściwości transitions , Stent generuje:
- metody pomocnicze do sprawdzania, czy maszyna jest w określonym stanie — stan
idlegenerujeisIdle(), natomiast dorunningmamyisRunning(); - metody pomocnicze do wywoływania akcji:
runPlease()istopNow().
Tak więc w powyższym przykładzie możemy użyć tego:
machine.isIdle(); // boolean machine.isRunning(); // boolean machine.runPlease(); // fires action machine.stopNow(); // fires action Łącząc automatycznie generowane metody z funkcją narzędzia connect , jesteśmy w stanie zamknąć okrąg. Interakcja użytkownika wyzwala dane wejściowe i działanie maszyny, które aktualizują stan. W związku z tą aktualizacją funkcja mapowania przekazana do connect zostaje odpalona, a my jesteśmy informowani o zmianie stanu. Następnie renderujemy.
Programy obsługi wejścia i działania
Prawdopodobnie najważniejszą częścią są procedury obsługi akcji. To jest miejsce, w którym piszemy większość logiki aplikacji, ponieważ reagujemy na stany wejściowe i zmienione. To, co naprawdę lubię w Redux, jest tutaj również zintegrowane: niezmienność i prostota funkcji reduktora. Istota obsługi akcji Stent jest taka sama. Otrzymuje aktualny stan i ładunek akcji i musi zwrócić nowy stan. Jeśli program obsługi nic nie zwraca ( undefined ), stan maszyny pozostaje taki sam.
transitions: { 'fetching': { 'success': function (state, payload) { const todos = [ ...state.todos, payload ]; return { name: 'idle', todos }; } } } Załóżmy, że musimy pobrać dane ze zdalnego serwera. Uruchamiamy żądanie i przenosimy maszynę do stanu fetching . Gdy dane pochodzą z zaplecza, uruchamiamy akcję success , na przykład:
machine.success({ label: '...' }); Następnie wracamy do stanu idle i zachowujemy niektóre dane w postaci tablicy todos . Istnieje kilka innych możliwych wartości, które można ustawić jako procedury obsługi akcji. Pierwszym i najprostszym przypadkiem jest przekazanie tylko ciągu, który staje się nowym stanem.
transitions: { 'idle': { 'run': 'running' } } Jest to przejście z { name: 'idle' } do { name: 'running' } za pomocą akcji run() . To podejście jest przydatne, gdy mamy synchroniczne przejścia stanów i nie mamy żadnych metadanych. Tak więc, jeśli zachowamy coś innego w stanie, ten rodzaj przejścia wypłucze to. Podobnie możemy przekazać bezpośrednio obiekt stanu:
transitions: { 'editing': { 'delete all todos': { name: 'idle', todos: [] } } } Przechodzimy z editing do idle za pomocą akcji deleteAllTodos .
Widzieliśmy już procedurę obsługi funkcji, a ostatnim wariantem obsługi akcji jest funkcja generatora. Jest inspirowany projektem Redux-Saga i wygląda tak:
import { call } from 'stent/lib/helpers'; Machine.create('app', { 'idle': { 'fetch data': function * (state, payload) { yield { name: 'fetching' } try { const data = yield call(requestToBackend, '/api/todos/', 'POST'); return { name: 'idle', data }; } catch (error) { return { name: 'error', error }; } } } });Jeśli nie masz doświadczenia z generatorami, może to wyglądać nieco tajemniczo. Ale generatory w JavaScript są potężnym narzędziem. Możemy wstrzymywać nasz program obsługi akcji, wielokrotnie zmieniać stan i obsługiwać logikę asynchroniczną.
Zabawa z generatorami
Kiedy po raz pierwszy zapoznałem się z Redux-Saga, pomyślałem, że jest to zbyt skomplikowany sposób obsługi operacji asynchronicznych. W rzeczywistości jest to całkiem sprytna implementacja wzorca projektowego poleceń. Główną zaletą tego wzorca jest to, że oddziela on wywołanie logiki od jego rzeczywistej implementacji.
Innymi słowy, mówimy, czego chcemy, ale nie mówimy, jak powinno się to wydarzyć. Seria blogów Matta Hinka pomogła mi zrozumieć, w jaki sposób sagi są wdrażane i gorąco polecam jej przeczytanie. Wprowadziłem te same pomysły do Stentu i na potrzeby tego artykułu powiemy, że udostępniając rzeczy, dajemy instrukcje dotyczące tego, czego chcemy, nie robiąc tego. Po wykonaniu akcji otrzymujemy z powrotem kontrolę.
W tej chwili kilka rzeczy może zostać wysłanych (uzyskanych):
- obiekt stanu (lub ciąg znaków) do zmiany stanu maszyny;
-
callhelpera wywołania (przyjmuje funkcję synchroniczną, czyli funkcję zwracającą obietnicę lub inną funkcję generatora) — mówimy w zasadzie: „Uruchom to dla mnie, a jeśli jest asynchroniczne, poczekaj. Gdy skończysz, daj mi wynik.”; - wywołanie pomocnika
wait(przyjmuje ciąg znaków reprezentujący inną akcję); jeśli użyjemy tej funkcji użytkowej, wstrzymujemy procedurę obsługi i czekamy na wykonanie innej akcji.
Oto funkcja ilustrująca warianty:
const fireHTTPRequest = function () { return new Promise((resolve, reject) => { // ... }); } ... transitions: { 'idle': { 'fetch data': function * () { yield 'fetching'; // sets the state to { name: 'fetching' } yield { name: 'fetching' }; // same as above // wait for getTheData and checkForErrors actions // to be dispatched const [ data, isError ] = yield wait('get the data', 'check for errors'); // wait for the promise returned by fireHTTPRequest // to be resolved const result = yield call(fireHTTPRequest, '/api/data/users'); return { name: 'finish', users: result }; } } }Jak widać, kod wygląda na synchroniczny, ale w rzeczywistości tak nie jest. To po prostu Stent, który wykonuje nudną część oczekiwania na rozwiązaną obietnicę lub iterację z innym generatorem.
Jak stent rozwiązuje moje problemy związane z redukcją?
Za dużo kodu płyty kotłowej
Architektura Redux (i Flux) opiera się na działaniach krążących w naszym systemie. Gdy aplikacja się rozrasta, zwykle kończy się na tym, że mamy wielu stałych i twórców akcji. Te dwie rzeczy bardzo często znajdują się w różnych folderach, a śledzenie wykonania kodu czasami zajmuje trochę czasu. Ponadto, dodając nową funkcję, zawsze mamy do czynienia z całym zestawem akcji, co oznacza zdefiniowanie większej liczby nazw akcji i twórców akcji.
W Stent nie mamy nazw akcji, a biblioteka automatycznie tworzy dla nas kreatory akcji:
const machine = Machine.create('todo-app', { state: { name: 'idle', todos: [] }, transitions: { 'idle': { 'add todo': function (state, todo) { ... } } } }); machine.addTodo({ title: 'Fix that bug' }); Mamy kreatora akcji machine.addTodo zdefiniowanego bezpośrednio jako metodę maszyny. Takie podejście rozwiązało również inny problem, z którym się spotkałem: znalezienie reduktora, który reaguje na konkretną akcję. Zwykle w komponentach React widzimy nazwy twórców akcji, takie jak addTodo ; jednak w reduktorach pracujemy z rodzajem działania, które jest stałe. Czasami muszę przeskoczyć do kodu twórcy akcji, aby zobaczyć dokładny typ. Tutaj w ogóle nie mamy typów.
Nieprzewidywalne zmiany stanu
Ogólnie rzecz biorąc, Redux dobrze radzi sobie z zarządzaniem stanem w niezmienny sposób. Problem nie tkwi w samym Redux, ale w tym, że programista może wykonać dowolne działanie w dowolnym momencie. Jeśli powiemy, że mamy akcję, która włącza światła, czy można uruchomić tę akcję dwa razy z rzędu? Jeśli nie, to jak mamy rozwiązać ten problem za pomocą Redux? Cóż, prawdopodobnie umieścilibyśmy jakiś kod w reduktorze, który chroni logikę i sprawdza, czy światła są już włączone — może klauzula if , która sprawdza aktualny stan. Teraz pytanie brzmi, czy nie jest to poza zakresem reduktora? Czy reduktor powinien wiedzieć o takich skrajnych przypadkach?
To, czego mi brakuje w Redux, to sposób na zatrzymanie wysyłania akcji na podstawie bieżącego stanu aplikacji bez zanieczyszczania reduktora logiką warunkową. I nie chcę też podejmować tej decyzji do warstwy widoku, gdzie odpalany jest twórca akcji. W przypadku Stentu dzieje się to automatycznie, ponieważ maszyna nie reaguje na działania, które nie są zadeklarowane w bieżącym stanie. Na przykład:
const machine = Machine.create('app', { state: { name: 'idle' }, transitions: { 'idle': { 'run': 'running', 'jump': 'jumping' }, 'running': { 'stop': 'idle' } } }); // this is fine machine.run(); // This will do nothing because at this point // the machine is in a 'running' state and there is // only 'stop' action there. machine.jump();Fakt, że maszyna akceptuje tylko określone dane wejściowe w danym momencie, chroni nas przed dziwnymi błędami i sprawia, że nasze aplikacje są bardziej przewidywalne.
Stany, a nie przejścia
Redux, podobnie jak Flux, każe nam myśleć w kategoriach przejść. Mentalny model programowania w Redux jest w dużej mierze napędzany przez działania i sposób, w jaki te działania zmieniają stan naszych reduktorów. To nie jest złe, ale stwierdziłem, że bardziej sensowne jest myślenie w kategoriach stanów — w jakich stanach może znajdować się aplikacja i jak te stany reprezentują wymagania biznesowe.
Wniosek
Koncepcja maszyn stanowych w programowaniu, zwłaszcza w tworzeniu interfejsu użytkownika, otworzyła mi oczy. Zacząłem wszędzie widzieć maszyny stanowe i mam pewne pragnienie, aby zawsze przechodzić do tego paradygmatu. Zdecydowanie dostrzegam korzyści płynące z posiadania ściślej określonych stanów i przejść między nimi. Zawsze szukam sposobów, aby moje aplikacje były proste i czytelne. Uważam, że maszyny państwowe są krokiem w tym kierunku. Koncepcja jest prosta i jednocześnie potężna. Ma potencjał, aby wyeliminować wiele błędów.