
Narzędzia danych ilościowych dla projektantów UX
Opublikowany: 2022-03-10Wielu projektantów UX trochę boi się danych, uważając, że wymaga to głębokiej znajomości statystyki i matematyki. Chociaż może to być prawdą w przypadku zaawansowanej nauki o danych, nie jest to prawdą w przypadku podstawowej analizy danych badawczych wymaganej przez większość projektantów UX. Ponieważ żyjemy w świecie coraz bardziej opartym na danych, podstawowa znajomość danych jest przydatna prawie każdemu profesjonaliście — nie tylko projektantom UX.
Aaron Gitlin, projektant interakcji w Google, twierdzi, że wielu projektantów nie jest jeszcze opartych na danych:
„Podczas gdy wiele firm promuje się jako oparte na danych, większość projektantów kieruje się instynktem, współpracą i jakościowymi metodami badawczymi”.
— Aaron Gitlin, „Zostawanie projektantem świadomym danych”
W tym artykule chciałbym dać projektantom UX wiedzę i narzędzia do włączania danych do ich codziennych zajęć.
Ale najpierw niektóre koncepcje dotyczące danych
W tym artykule omówię dane strukturalne, czyli dane, które mogą być reprezentowane w tabeli za pomocą wierszy i kolumn. Dane nieustrukturyzowane, będące przedmiotem samym w sobie, są trudniejsze do analizy, jak zauważył Devin Pickell (specjalista ds. marketingu treści w G2 Crowd, piszący o danych i analizach) w swoim artykule „Dane ustrukturyzowane a nieustrukturyzowane – na czym polega różnica?”. Jeśli uporządkowane dane można przedstawić w formie tabeli, główne pojęcia to:
Zbiór danych
Cały zestaw danych, które zamierzamy przeanalizować. Może to być na przykład tabela Excela. Innym popularnym formatem przechowywania zestawów danych jest plik z wartościami rozdzielanymi przecinkami (CSV). Pliki CSV to proste pliki tekstowe używane do przechowywania informacji podobnych do tabeli. Każdy wiersz CSV odpowiada wierszowi w tabeli, a każdy wiersz CSV ma wartości oddzielone (oczywiście) przecinkami, które odpowiadają komórkom tabeli.
Punkt danych
Pojedynczy wiersz z tabeli zestawu danych to punkt danych. W ten sposób zbiór danych jest zbiorem punktów danych.
Zmienna danych
Pojedyncza wartość z wiersza punktu danych reprezentuje zmienną danych — po prostu komórkę tabeli. Możemy mieć dwa rodzaje zmiennych danych: zmienne jakościowe i zmienne ilościowe. Zmienne jakościowe (nazywane również zmiennymi kategorialnymi) mają dyskretny zestaw wartości, taki jak color = red/green/blue . Zmienne ilościowe mają wartości liczbowe, np. height = 167 . Zmienna ilościowa, w przeciwieństwie do jakościowej, może przyjąć dowolną wartość.
Tworzenie naszego projektu danych
Teraz znamy podstawy, czas pobrudzić sobie ręce i stworzyć nasz pierwszy projekt danych. Zakres projektu obejmuje analizę zbioru danych poprzez przejście przez cały przepływ danych importu, przetwarzania i wykreślania danych. Najpierw wybierzemy nasz zbiór danych, następnie pobierzemy i zainstalujemy narzędzia do analizy danych.
Zestaw danych samochodów
Na potrzeby tego artykułu wybrałem zestaw danych samochodów, ponieważ jest prosty i intuicyjny. Analiza danych po prostu potwierdzi to, co już wiemy o samochodach — co jest w porządku, ponieważ koncentrujemy się na przepływie danych i narzędziach.
Zestaw danych samochodów używanych możemy pobrać z Kaggle, jednego z największych źródeł bezpłatnych zestawów danych. Musisz się najpierw zarejestrować.
Po pobraniu pliku otwórz go i spójrz. To naprawdę duży plik CSV, ale powinieneś zrozumieć. Linia w tym pliku będzie wyglądać tak:
19500,2015,2965,Miami,FL,WBA3B1G54FNT02351,BMW,3Jak widać, ten punkt danych ma kilka zmiennych oddzielonych przecinkami. Ponieważ mamy teraz zbiór danych, porozmawiajmy trochę o narzędziach.
Narzędzia handlu
Do analizy zestawu danych użyjemy języka R i RStudio. R to bardzo popularny i łatwy do nauczenia język, używany nie tylko przez naukowców zajmujących się danymi, ale także osoby z rynków finansowych, medycyny i wielu innych dziedzin. RStudio to środowisko, w którym rozwijane są projekty R, a dostępna jest darmowa wersja, która jest więcej niż wystarczająca dla naszych potrzeb jako projektantów UX.
Prawdopodobnie niektórzy projektanci UX używają programu Excel do przepływu danych. Jeśli to oznacza Ciebie, wypróbuj R — jest duża szansa, że Ci się spodoba, ponieważ jest łatwy do nauczenia, bardziej elastyczny i wydajny niż Excel. Dodanie R do zestawu narzędzi zrobi różnicę.
Instalowanie narzędzi
Najpierw musimy pobrać i zainstalować R i RStudio. Powinieneś najpierw zainstalować R, a następnie RStudio. Procesy instalacji zarówno R, jak i RStudio są proste i proste.
Konfiguracja projektu
Po zakończeniu instalacji utwórz folder projektu — nazwałem go used-cars-prj . W tym folderze utwórz podfolder o nazwie data , a następnie skopiuj plik zestawu danych (pobrany z Kaggle) do tego folderu i zmień jego nazwę na used-cars.csv . Teraz wróć do folderu naszego projektu ( used-cars-prj ) i utwórz zwykły plik tekstowy o nazwie used-cars.r . Powinieneś otrzymać taką samą strukturę, jak na poniższym zrzucie ekranu.
Teraz mamy już strukturę folderów, możemy otworzyć RStudio i utworzyć nowy projekt R. Wybierz New Project… z menu File i drugą opcję Existing Directory . Następnie wybierz katalog projektu ( used-cars-prj ). Na koniec naciśnij przycisk Utwórz projekt i gotowe. Po utworzeniu projektu otwórz used-cars.r w RStudio — jest to plik, w którym dodamy cały nasz kod R.
Importowanie danych
Dodamy nasz pierwszy wiersz w used-cars.r do odczytu danych z pliku used-cars.csv . Pamiętaj, że pliki CSV to zwykłe pliki tekstowe używane do przechowywania danych. Nasz pierwszy wiersz kodu R będzie wyglądał tak:
cars <- read.csv("./data/used-cars.csv", stringsAsFactors = FALSE, sep=",") Może to wyglądać trochę onieśmielająco, ale tak naprawdę nie jest — nawiasem mówiąc, jest to najbardziej złożona linijka w całym artykule. Mamy tutaj funkcję read.csv , która przyjmuje trzy parametry.
Pierwszym parametrem jest plik do odczytu, w naszym przypadku used-cars.csv , który znajduje się w folderze data . Drugi parametr, stringsAsFactors=FALSE , jest ustawiony, aby upewnić się, że ciągi takie jak „BMW” lub „Audi” nie są konwertowane na czynniki (żargon R dla danych kategorycznych) — jak pamiętasz, zmienne jakościowe lub kategorialne mogą mieć tylko wartości dyskretne, takie jak red/green/blue . Wreszcie trzeci parametr, sep="," określa rodzaj separatora używanego do oddzielania wartości w pliku CSV: przecinek.
Po odczytaniu pliku CSV dane są zapisywane w obiekcie ramki danych cars . Ramka danych to dwuwymiarowa struktura danych (jak tabela Excela), która jest bardzo przydatna w R do manipulowania danymi. Po wprowadzeniu linii i jej uruchomieniu zostanie dla Ciebie utworzona ramka danych cars . Jeśli spojrzysz na prawy górny kwadrant w RStudio, zauważysz ramkę danych cars w sekcji Dane na karcie Środowisko . Jeśli klikniesz dwukrotnie na samochody , w lewym górnym kwadrancie RStudio otworzy się nowa zakładka, która zaprezentuje ramkę danych cars . Jak można się spodziewać, wygląda jak tabela Excela.
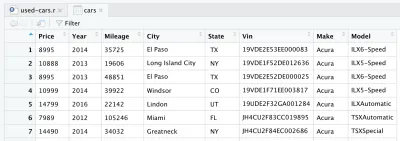
W rzeczywistości są to surowe dane, które pobraliśmy z Kaggle. Ale ponieważ chcemy przeprowadzić analizę danych, najpierw musimy przetworzyć nasz zbiór danych.
Przetwarzanie danych
Przez przetwarzanie rozumiemy usuwanie, przekształcanie lub dodawanie informacji do naszego zbioru danych w celu przygotowania się do rodzaju analizy, którą chcemy przeprowadzić. Mamy dane w obiekcie ramki danych, więc teraz musimy zainstalować bibliotekę dplyr , potężną bibliotekę do manipulowania danymi. Aby zainstalować bibliotekę w naszym środowisku R, musimy napisać następujący wiersz na górze naszego pliku R.
install.packages("dplyr")Następnie, aby dodać bibliotekę do naszego obecnego projektu, użyjemy następnej linii:
library(dplyr) Po dodaniu biblioteki dplyr do naszego projektu możemy rozpocząć przetwarzanie danych. Mamy naprawdę duży zbiór danych i potrzebujemy tylko danych reprezentujących tego samego producenta i model samochodu, aby skorelować to z ceną. Użyjemy następującego kodu R, aby zachować tylko dane dotyczące BMW serii 3, a resztę usuniemy. Oczywiście możesz wybrać dowolnego innego producenta i model z zestawu danych i oczekiwać, że dane będą takie same.
cars <- cars %>% filter(Make == "BMW", Model == "3")Teraz mamy łatwiejszy w zarządzaniu zbiór danych, choć wciąż zawierający ponad 11 000 punktów danych, który pasuje do naszego zamierzonego celu: analizy rozkładu cen, wieku i przebiegu samochodów, a także korelacji między nimi. W tym celu musimy zachować tylko kolumny „Cena”, „Rok” i „Przebieg” i usunąć resztę — odbywa się to za pomocą następującego wiersza.
cars <- cars %>% select(Price, Year, Mileage)Po usunięciu pozostałych kolumn nasza ramka danych będzie wyglądać tak:

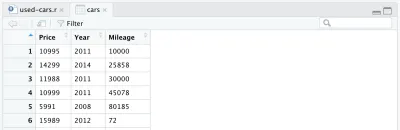
Jest jeszcze jedna zmiana, którą chcemy wprowadzić w naszym zbiorze danych: zastąpić rok produkcji wiekiem samochodu. Możemy dodać następujące dwa wiersze, pierwszy do obliczenia wieku, drugi do zmiany nazwy kolumny.
cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Na koniec nasza pełna przetworzona ramka danych wygląda tak:
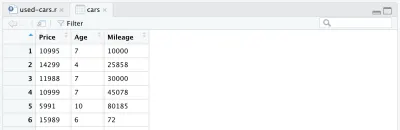
W tym momencie nasz kod R będzie wyglądał następująco i to wszystko dla przetwarzania danych. Możemy teraz zobaczyć, jak łatwy i potężny jest język R. Początkowy zestaw danych przetworzyliśmy dość radykalnie za pomocą zaledwie kilku linii kodu.
install.packages("dplyr") library(dplyr) cars = read.csv("./data/cars.csv", stringsAsFactors = FALSE, sep=",") cars <- cars %>% filter(Make == "BMW", Model == "3") cars <- cars %>% select(Price, Year, Mileage) cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Analiza danych
Nasze dane są teraz w odpowiednim stanie, więc możemy przejść do tworzenia wykresów. Jak już wspomniano, skupimy się na dwóch aspektach: rozkładzie poszczególnych zmiennych oraz korelacjach między nimi. Rozkład zmienny pomaga nam zrozumieć, co jest uważane za średnią lub wysoką cenę używanego samochodu — lub procent samochodów powyżej określonej ceny. To samo dotyczy wieku i przebiegu samochodów. Z drugiej strony korelacje są pomocne w zrozumieniu, w jaki sposób zmienne, takie jak wiek i przebieg, są ze sobą powiązane.
To powiedziawszy, użyjemy dwóch rodzajów wizualizacji danych: histogramów dla rozkładu zmiennych i wykresów punktowych dla korelacji.
Dystrybucja cen
Wykreślenie histogramu ceny samochodu w języku R jest tak proste, jak to:
hist(cars$Price)Mała wskazówka: jeśli jesteś w RStudio, możesz uruchamiać kod linia po linii; na przykład w naszym przypadku wystarczy uruchomić tylko powyższy wiersz, aby wyświetlić histogram. Nie ma potrzeby ponownego uruchamiania całego kodu, ponieważ uruchomiłeś go już raz. Histogram powinien wyglądać tak:
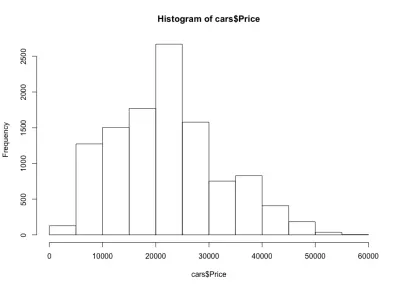
Jeśli spojrzymy na histogram, zauważymy dzwonkowy rozkład cen samochodów, czego oczekiwaliśmy. Większość samochodów mieści się w średnim zakresie, a my mamy ich coraz mniej, gdy poruszamy się w każdą stronę. Prawie 80% samochodów kosztuje od 10 000 do 30 000 USD, a maksymalnie ponad 2500 samochodów kosztuje od 20 000 do 25 000 USD. Po lewej stronie mamy prawdopodobnie około 150 samochodów poniżej 5000 USD, a po prawej jeszcze mniej. Możemy łatwo zobaczyć, jak przydatne są takie wykresy, aby uzyskać wgląd w dane.
Podział wiekowy
Podobnie jak w przypadku cen samochodów, użyjemy podobnej linii do wykreślenia histogramu wieku samochodów.
hist(cars$Age)A oto histogram:
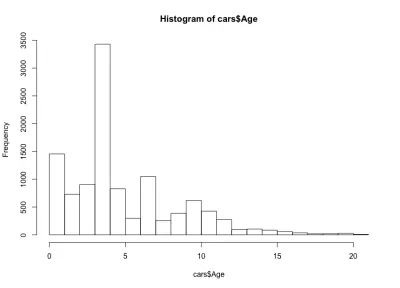
Tym razem histogram wygląda na sprzeczny z intuicją — zamiast prostego kształtu dzwonka mamy tutaj cztery dzwonki. Zasadniczo dystrybucja ma trzy lokalne i jedno globalne maksimum, co jest nieoczekiwane. Byłoby interesujące zobaczyć, czy ten dziwny rozkład wieku samochodów pozostaje prawdziwy w przypadku innego producenta i modelu samochodu. Na potrzeby tego artykułu pozostaniemy przy zestawie danych BMW serii 3, ale jeśli jesteś ciekawy, możesz zagłębić się w dane. Jeśli chodzi o rozkład wieku samochodów, zauważamy, że ponad 90% samochodów ma mniej niż 10 lat, a ponad 80% mniej niż 7 lat. Zauważamy również, że większość samochodów ma mniej niż 5 lat.
Rozkład przebiegu
Co możemy powiedzieć o przebiegu? Oczywiście spodziewamy się takiego samego kształtu dzwonka, jaki mieliśmy za cenę. Oto kod R i histogram:
hist(cars$Mileage) 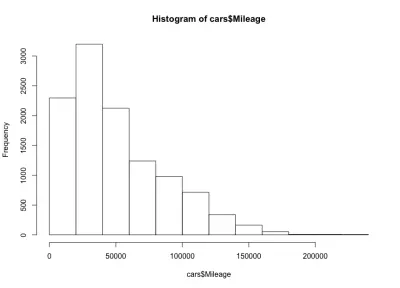
Tutaj mamy przekrzywiony w lewo kształt dzwonka, co oznacza, że na rynku jest więcej samochodów z mniejszym przebiegiem. Zauważamy również, że większość samochodów ma mniej niż 60 000 mil, a my mamy maksymalnie około 20 000 do 40 000 mil.
Korelacja między wiekiem a ceną
Jeśli chodzi o korelacje, przyjrzyjmy się bliżej korelacji wiek-cena samochodów. Można się spodziewać, że cena będzie ujemnie skorelowana z wiekiem — wraz ze wzrostem wieku samochodu jego cena będzie spadać. Użyjemy funkcji plot R, aby wyświetlić korelację cena-wiek w następujący sposób:
plot(cars$Age, cars$Price)A fabuła wygląda tak:
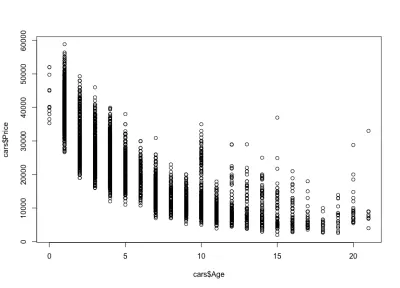
Obserwujemy, jak wraz z wiekiem spadają ceny samochodów: są drogie nowe auta i tańsze stare auta. Możemy również zobaczyć przedział zmienności ceny dla dowolnego konkretnego wieku, zmienność, która zmniejsza się wraz z wiekiem samochodu. Ta odmiana jest w dużej mierze uzależniona od przebiegu, konfiguracji i ogólnego stanu samochodu. Na przykład w przypadku 4-letniego samochodu cena waha się od 10 000 USD do 40 000 USD.
Korelacja przebiegu z wiekiem
Biorąc pod uwagę korelację przebiegu z wiekiem, spodziewalibyśmy się, że przebieg będzie wzrastał wraz z wiekiem, co oznacza korelację dodatnią. Oto kod:
plot(cars$Mileage, cars$Age)A oto fabuła:
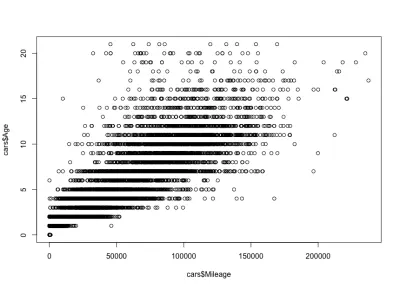
Jak widać, wiek i przebieg samochodu są skorelowane dodatnio, w przeciwieństwie do ceny i wieku samochodu, które są skorelowane ujemnie. Mamy również oczekiwaną zmianę przebiegu dla określonego wieku; czyli samochody w tym samym wieku mają różne przebiegi. Na przykład większość 4-letnich samochodów ma przebieg od 10 000 do 80 000 mil. Ale są też odstające, z większym przebiegiem.
Korelacja przebiegu z ceną
Zgodnie z oczekiwaniami, pomiędzy przebiegiem samochodu a ceną wystąpi ujemna korelacja, co oznacza, że zwiększenie przebiegu obniża cenę.
plot(cars$Mileage, cars$Price)A oto fabuła:
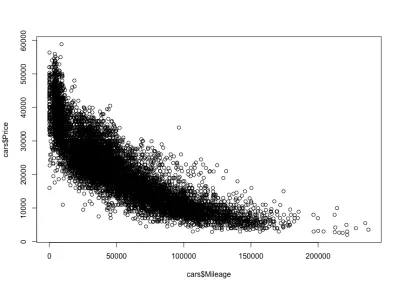
Tak jak się spodziewaliśmy, korelacja ujemna. Możemy również zauważyć przedział cenowy brutto między 3000 a 50 000 USD oraz przebieg od 0 do 150 000. Jeśli przyjrzymy się bliżej kształtowi dystrybucji, zobaczymy, że cena spada znacznie szybciej w przypadku samochodów z mniejszym przebiegiem niż w przypadku samochodów z większym przebiegiem. Są auta z prawie zerowym przebiegiem, których cena dramatycznie spada. Poza tym przy zasięgu powyżej 200 000 mil — ponieważ przebieg jest bardzo wysoki — cena pozostaje stała.
Od liczb do wizualizacji danych
W tym artykule wykorzystaliśmy dwa rodzaje wizualizacji: histogramy dla dystrybucji danych i wykresy punktowe dla korelacji danych. Histogramy to wizualne reprezentacje, które pobierają wartości zmiennej danych ( liczby rzeczywiste ) i pokazują, jak są one rozłożone w zakresie. Użyliśmy funkcji R hist() do wykreślenia histogramu.
Z drugiej strony wykresy punktowe biorą pary liczb i przedstawiają je na dwóch osiach. Wykresy punktowe wykorzystują funkcję plot() i zapewniają dwa parametry: pierwszą i drugą zmienną danych korelacji, którą chcemy zbadać. Tak więc dwie funkcje R, hist() i plot() , pomagają nam tłumaczyć zbiory liczb w sensowne reprezentacje wizualne.
Wniosek
Po ubrudzeniu sobie rąk podczas całego przepływu danych importowania, przetwarzania i kreślenia danych wszystko wygląda teraz znacznie jaśniej. Możesz zastosować ten sam przepływ danych do dowolnego nowego, błyszczącego zestawu danych, który napotkasz. Na przykład w badaniach użytkowników można wykreślić czas na rozkładzie zadań lub błędów, a także można wykreślić czas na korelację między zadaniem a błędem.
Aby dowiedzieć się więcej o języku R, dobrym miejscem do rozpoczęcia jest Quick-R, ale możesz również rozważyć R Bloggers. Aby uzyskać dokumentację pakietów R, takich jak dplyr , możesz odwiedzić RDocumentation. Zabawa z danymi może być fajna, ale jest również niezwykle pomocna dla każdego projektanta UX w świecie opartym na danych. W miarę gromadzenia i wykorzystywania większej ilości danych do podejmowania decyzji biznesowych, projektanci mają większą szansę na pracę nad wizualizacją danych lub produktami z danymi, w których zrozumienie natury danych jest niezbędne.