
Tworzenie wewnętrznej usługi Pub/Sub przy użyciu Node.js i Redis
Opublikowany: 2022-03-10Dzisiejszy świat działa w czasie rzeczywistym. Niezależnie od tego, czy chodzi o handel zapasami, czy zamawianie żywności, konsumenci oczekują dziś natychmiastowych rezultatów. Podobnie wszyscy oczekujemy, że będziemy wiedzieć wszystko od razu — czy to w wiadomościach, czy w sporcie. Innymi słowy, Zero to nowy bohater.
Dotyczy to również twórców oprogramowania — prawdopodobnie niektórych z najbardziej niecierpliwych ludzi! Zanim zagłębię się w historię BrowserStack, byłoby zaniedbaniem z mojej strony, gdybym nie przedstawił informacji na temat Pub/Sub. Dla tych z Was, którzy znają podstawy, możecie pominąć kolejne dwa akapity.
Obecnie wiele aplikacji opiera się na przesyłaniu danych w czasie rzeczywistym. Przyjrzyjmy się bliżej przykładowi: sieci społecznościowe. Podobni do Facebooka i Twittera generują odpowiednie kanały , a Ty (za pośrednictwem ich aplikacji) konsumujesz je i szpiegujesz swoich znajomych. Osiągają to dzięki funkcji przesyłania wiadomości, w której jeśli użytkownik wygeneruje dane, zostaną one opublikowane, aby inni mogli je wykorzystać w mgnieniu oka. Wszelkie znaczące opóźnienia i użytkownicy będą narzekać, użycie spadnie, a jeśli będzie się powtarzać, zniknie. Stawka jest wysoka, podobnie jak oczekiwania użytkowników. Jak więc usługi takie jak WhatsApp, Facebook, TD Ameritrade, Wall Street Journal i GrubHub obsługują duże ilości transferów danych w czasie rzeczywistym?
Wszystkie używają podobnej architektury oprogramowania na wysokim poziomie, zwanej modelem „publikuj-subskrybuj”, powszechnie określanym jako Pub/Sub.
„W architekturze oprogramowania publikuj-subskrybuj jest wzorcem wiadomości, w którym nadawcy wiadomości, zwani wydawcami, nie programują wiadomości, które mają być wysyłane bezpośrednio do określonych odbiorców, zwanych subskrybentami, ale zamiast tego kategoryzują opublikowane wiadomości w klasy bez wiedzy o tym, którzy subskrybenci, jeśli każdy, może być. Podobnie subskrybenci wyrażają zainteresowanie co najmniej jedną klasą i otrzymują tylko te wiadomości, które są interesujące, bez wiedzy o tym, jacy są wydawcy”.
— Wikipedia
Znudzony definicją? Wróćmy do naszej historii.
W BrowserStack wszystkie nasze produkty obsługują (w taki czy inny sposób) oprogramowanie ze znacznym komponentem zależności w czasie rzeczywistym — niezależnie od tego, czy są to dzienniki testów automatycznych, świeżo upieczone zrzuty ekranu przeglądarki, czy strumieniowe przesyłanie strumieniowe z prędkością 15 klatek na sekundę.
W takich przypadkach, jeśli pojedyncza wiadomość zostanie odrzucona, klient może stracić informacje niezbędne do uniknięcia błędu . Dlatego musieliśmy dostosować skalę do różnych wymagań dotyczących rozmiaru danych. Na przykład w przypadku usług rejestratora urządzeń w danym momencie w ramach jednej wiadomości może zostać wygenerowanych 50 MB danych. Takie rozmiary mogą spowodować awarię przeglądarki. Nie wspominając o tym, że system BrowserStack będzie musiał być w przyszłości skalowany pod kątem dodatkowych produktów.
Ponieważ rozmiar danych dla każdej wiadomości różni się od kilku bajtów do nawet 100 MB, potrzebowaliśmy skalowalnego rozwiązania, które mogłoby obsługiwać wiele scenariuszy. Innymi słowy, szukaliśmy miecza, który mógłby pokroić wszystkie ciasta. W tym artykule omówię, dlaczego, w jaki sposób i jakie wyniki ma budowa naszej usługi Pub/Sub we własnym zakresie.
Przez pryzmat rzeczywistego problemu BrowserStack uzyskasz głębsze zrozumienie wymagań i procesu tworzenia własnego Pub/Sub .
Nasza potrzeba usługi Pub/Sub
BrowserStack zawiera około 100 milionów wiadomości, z których każda ma wielkość od około 2 bajtów do ponad 100 MB. Są one przekazywane na całym świecie w dowolnym momencie, wszystkie z różnymi prędkościami Internetu.
Największymi generatorami tych wiadomości, pod względem rozmiaru wiadomości, są nasze produkty BrowserStack Automate. Oba mają pulpity nawigacyjne w czasie rzeczywistym wyświetlające wszystkie żądania i odpowiedzi dla każdego polecenia testu użytkownika. Tak więc, jeśli ktoś przeprowadzi test ze 100 żądaniami, w których średni rozmiar żądania-odpowiedzi wynosi 10 bajtów, to przesyła 1×100×10 = 1000 bajtów.
Rozważmy teraz szerszy obraz, ponieważ — oczywiście — nie przeprowadzamy tylko jednego testu dziennie. Ponad 850 000 testów BrowserStack Automate i App Automate jest przeprowadzanych każdego dnia za pomocą BrowserStack. I tak, średnio około 235 odpowiedzi na żądanie na test. Ponieważ użytkownicy mogą robić zrzuty ekranu lub prosić o źródła stron w Selenium, nasz średni rozmiar żądania-odpowiedzi wynosi około 220 bajtów.
Wracając więc do naszego kalkulatora:
850 000 × 235 × 220 = 43 945 000 000 bajtów (w przybliżeniu) lub tylko 43,945 GB dziennie
Porozmawiajmy teraz o BrowserStack Live i App Live. Z pewnością mamy Automate jako naszego zwycięzcę w postaci wielkości danych. Jednak jeśli chodzi o liczbę przesłanych wiadomości, prym wiodą produkty Live. W przypadku każdego testu na żywo przesyłanych jest około 20 wiadomości w każdej minucie obrotu. Przeprowadzamy około 100 000 testów na żywo, z których każdy test trwa średnio około 12 minut, co oznacza:
100 000 × 12 × 20 = 24 000 000 wiadomości dziennie
Teraz niesamowita i niezwykła część: budujemy, uruchamiamy i utrzymujemy aplikację dla tego zwanego pusher z 6 instancjami t1.micro ec2. Koszt prowadzenia usługi? Około 70 dolarów miesięcznie .
Wybór budowania a kupowanie
Po pierwsze: jako startup, jak większość innych, zawsze byliśmy podekscytowani możliwością tworzenia rzeczy we własnym zakresie. Ale nadal ocenialiśmy kilka usług. Podstawowe wymagania jakie mieliśmy to:
- Niezawodność i stabilność,
- Wysoka wydajność i
- Opłacalność.
Zostawmy kryteria opłacalności, ponieważ nie przychodzi mi do głowy żadna zewnętrzna usługa, która kosztuje mniej niż 70 USD miesięcznie (tweetuj mnie, jeśli znasz taką, która kosztuje!). Więc nasza odpowiedź jest oczywista.
Jeśli chodzi o niezawodność i stabilność, znaleźliśmy firmy, które dostarczały Pub/Sub jako usługę z ponad 99,9-procentową umową SLA, ale było tam wiele T&C. Problem nie jest tak prosty, jak myślisz, zwłaszcza gdy weźmie się pod uwagę rozległe obszary otwartego Internetu, które leżą między systemem a klientem. Każdy, kto zna się na infrastrukturze internetowej, wie, że stabilna łączność to największe wyzwanie. Dodatkowo ilość przesyłanych danych zależy od ruchu. Na przykład potok danych, który przez jedną minutę ma zero, może pęknąć w następnej. Usługi zapewniające odpowiednią niezawodność w takich momentach wybuchowych są rzadkie (Google i Amazon).
Wydajność dla naszego projektu oznacza pozyskiwanie i wysyłanie danych do wszystkich węzłów nasłuchowych z niemal zerową latencją . W BrowserStack korzystamy z usług w chmurze (AWS) wraz z hostingiem kolokacji. Jednak nasi wydawcy i/lub subskrybenci mogą być umieszczani w dowolnym miejscu. Na przykład może to obejmować serwer aplikacji AWS generujący bardzo potrzebne dane dziennika lub terminale (maszyny, na których użytkownicy mogą bezpiecznie łączyć się w celu testowania). Wracając ponownie do kwestii otwartego Internetu, gdybyśmy mieli zmniejszyć nasze ryzyko, musielibyśmy zapewnić, że nasz Pub/Sub korzysta z najlepszych usług hosta i AWS.
Kolejnym istotnym wymaganiem była możliwość przesyłania wszystkich typów danych (bajty, tekst, dziwne dane medialne itp.). Biorąc to wszystko pod uwagę, nie ma sensu polegać na rozwiązaniu innej firmy w celu obsługi naszych produktów. Z kolei postanowiliśmy wskrzesić ducha startupowego, zakasując rękawy, aby zakodować własne rozwiązanie.

Budowanie naszego rozwiązania
Pub/Sub z założenia oznacza, że będzie wydawca, który będzie generował i wysyłał dane, a Abonent je zaakceptuje i przetworzy. Jest to podobne do radia: kanał radiowy nadaje (publikuje) treści wszędzie w zasięgu. Jako subskrybent możesz zdecydować, czy chcesz dostroić się do tego kanału i słuchać (lub całkowicie wyłączyć radio).
W przeciwieństwie do analogii radiowej, w której dane są bezpłatne dla wszystkich i każdy może zdecydować się na dostrojenie, w naszym cyfrowym scenariuszu potrzebujemy uwierzytelnienia, co oznacza, że dane generowane przez wydawcę mogą dotyczyć tylko jednego konkretnego klienta lub abonenta.
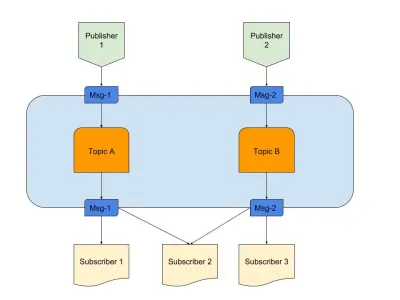
Powyżej znajduje się diagram przedstawiający przykład dobrego Pub/Sub z:
- Wydawcy
Tutaj mamy dwóch wydawców generujących komunikaty w oparciu o predefiniowaną logikę. W naszej radiowej analogii są to nasi radiodżokeje tworzący treść. - Tematy
Są tu dwa, co oznacza, że istnieją dwa rodzaje danych. Można powiedzieć, że są to nasze kanały radiowe 1 i 2. - Subskrybenci
Mamy trzy, z których każdy odczytuje dane na określony temat. Należy zauważyć, że subskrybent 2 czyta z wielu tematów. W naszej analogii radiowej są to ludzie dostrojeni do kanału radiowego.
Zacznijmy rozumieć niezbędne wymagania dotyczące usługi.
- Wydarzenie komponent
To włącza się tylko wtedy, gdy jest coś, w co można się włączyć. - Przechowywanie przejściowe
Dzięki temu dane są utrzymywane przez krótki czas, więc jeśli subskrybent jest powolny, nadal ma okno, aby je wykorzystać. - Zmniejszenie opóźnienia
Łączenie dwóch podmiotów przez sieć z minimalnymi przeskokami i odległością.
Wybraliśmy stos technologiczny spełniający powyższe wymagania:
- Node.js
Bo czemu nie? W każdym razie nie potrzebowalibyśmy intensywnego przetwarzania danych, a ponadto jest łatwy do wdrożenia. - Redis
Obsługuje idealnie krótkotrwałe dane. Posiada wszystkie możliwości inicjowania, aktualizowania i automatycznego wygasania. Zmniejsza również obciążenie aplikacji.
Node.js dla biznesowej łączności logicznej
Node.js to prawie idealny język, jeśli chodzi o pisanie kodu zawierającego IO i zdarzenia. Nasz konkretny problem miał oba, czyniąc tę opcję najbardziej praktyczną dla naszych potrzeb.
Z pewnością inne języki, takie jak Java, mogłyby być bardziej zoptymalizowane, a język taki jak Python oferuje skalowalność. Jednak koszt rozpoczęcia z tymi językami jest tak wysoki, że programista może dokończyć pisanie kodu w Node w tym samym czasie.
Szczerze mówiąc, gdyby serwis miał szansę na dodanie bardziej skomplikowanych funkcji, moglibyśmy przyjrzeć się innym językom lub kompletnemu stosowi. Ale tutaj jest małżeństwo zawarte w niebie. Oto nasz pakiet.json :
{ "name": "Pusher", "version": "1.0.0", "dependencies": { "bstack-analytics": "*****", // Hidden for BrowserStack reasons. :) "ioredis": "^2.5.0", "socket.io": "^1.4.4" }, "devDependencies": {}, "scripts": { "start": "node server.js" } }Mówiąc najprościej, wierzymy w minimalizm, zwłaszcza jeśli chodzi o pisanie kodu. Z drugiej strony moglibyśmy użyć bibliotek takich jak Express do napisania rozszerzalnego kodu dla tego projektu. Jednak nasze startupowe instynkty postanowiły to przekazać i zachować na kolejny projekt. Dodatkowe narzędzia, których użyliśmy:
- ioredis
Jest to jedna z najbardziej obsługiwanych bibliotek do łączności Redis z Node.js, używana przez firmy, w tym Alibaba. - gniazdo.io
Najlepsza biblioteka zapewniająca płynną łączność i awaryjne dzięki WebSocket i HTTP.
Redis do przechowywania przejściowego
Redis jako skala usługowa jest wysoce niezawodna i konfigurowalna. Ponadto istnieje wielu niezawodnych dostawców usług zarządzanych dla Redis, w tym AWS. Nawet jeśli nie chcesz korzystać z dostawcy, Redis jest łatwy do rozpoczęcia.
Podzielmy konfigurowalną część. Zaczęliśmy od zwykłej konfiguracji master-slave, ale Redis jest również wyposażony w tryby klastra lub wartownika. Każdy tryb ma swoje zalety.
Gdybyśmy mogli w jakiś sposób udostępnić dane, najlepszym wyborem byłby klaster Redis. Ale jeśli udostępnimy dane za pomocą dowolnej heurystyki, mamy mniejszą elastyczność, ponieważ heurystyka musi być śledzona w poprzek . Mniej zasad, większa kontrola jest dobra na całe życie!
Redis Sentinel działa dla nas najlepiej, ponieważ wyszukiwanie danych odbywa się tylko w jednym węźle, łączącym się w określonym momencie, podczas gdy dane nie są dzielone na fragmenty. Oznacza to również, że nawet w przypadku utraty wielu węzłów dane są nadal dystrybuowane i obecne w innych węzłach. Masz więc więcej HA i mniejsze szanse na stratę. Oczywiście usunęło to profesjonalistów z posiadania klastra, ale nasz przypadek użycia jest inny.
Architektura na 30000 stóp
Poniższy diagram przedstawia bardzo ogólny obraz tego, jak działają nasze pulpity nawigacyjne Automate i App Automate. Pamiętasz system czasu rzeczywistego, który mieliśmy z poprzedniej sekcji?
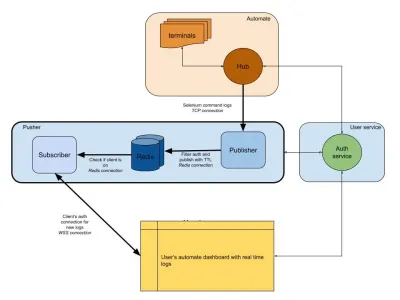
Na naszym diagramie nasz główny przepływ pracy jest wyróżniony grubszymi ramkami. Sekcja „automatyzacja” składa się z:
- Terminale
Składa się z nieskazitelnych wersji systemu Windows, OSX, Android lub iOS, które otrzymujesz podczas testowania na BrowserStack. - Centrum
Punkt kontaktowy dla wszystkich Twoich testów Selenium i Appium z BrowserStack.
Sekcja „obsługa użytkownika” to nasz strażnik, który zapewnia, że dane są przesyłane i zapisywane dla właściwej osoby. To także nasz strażnik. Sekcja „popychacz” zawiera sedno tego, co omówiliśmy w tym artykule. Składa się z typowych podejrzanych, w tym:
- Redis
Nasze tymczasowe przechowywanie wiadomości, gdzie w naszym przypadku automatyczne logi są tymczasowo przechowywane. - Wydawca
Jest to w zasadzie podmiot, który uzyskuje dane z centrum. Wszystkie odpowiedzi na żądania są przechwytywane przez ten komponent, który zapisuje dosession_idz identyfikatorem sesji jako kanałem. - Abonent
To odczytuje dane z Redis wygenerowane dlasession_id. Jest to również serwer WWW dla klientów, który łączy się za pośrednictwem protokołu WebSocket (lub HTTP) w celu uzyskania danych, a następnie wysyła je do uwierzytelnionych klientów.
Na koniec mamy sekcję przeglądarki użytkownika, reprezentującą uwierzytelnione połączenie WebSocket, aby zapewnić wysyłanie dzienników session_id . Dzięki temu front-endowy JS może analizować i upiększać go dla użytkowników.
Podobnie jak w przypadku usługi dzienników, mamy tutaj pusher, który jest używany do innych integracji produktów. Zamiast session_id używamy innej formy identyfikatora do reprezentowania tego kanału. To wszystko działa bez popychacza!
Wniosek (TLDR)
Odnieśliśmy spory sukces w tworzeniu Pub/Sub. Podsumowując dlaczego zbudowaliśmy go we własnym zakresie:
- Skaluje się lepiej dla naszych potrzeb;
- Tańsze niż usługi zlecane na zewnątrz;
- Pełna kontrola nad ogólną architekturą.
Nie wspominając o tym, że JS idealnie pasuje do tego rodzaju scenariusza. Pętla zdarzeń i ogromna ilość IO są tym, czego potrzebuje problem! JavaScript to magia pojedynczego pseudowątku.
Zdarzenia i Redis jako system upraszczają programistom, ponieważ możesz uzyskiwać dane z jednego źródła i przesyłać je do innego za pośrednictwem Redis. Więc to zbudowaliśmy.
Jeśli użycie pasuje do twojego systemu, polecam zrobić to samo!