
Regresja wielomianowa: znaczenie, implementacja krok po kroku
Opublikowany: 2021-01-29Spis treści
Wstęp
W tej rozległej dziedzinie uczenia maszynowego, jaki byłby pierwszy algorytm, który większość z nas studiowała? Tak, to regresja liniowa. Będąc głównie pierwszym programem i algorytmem, którego można się nauczyć w początkowych dniach programowania w uczeniu maszynowym, regresja liniowa ma swoje znaczenie i moc w przypadku danych liniowych.
Co się stanie, jeśli zbiór danych, z którym się spotykamy, nie jest liniowo rozdzielny? A co, jeśli model regresji liniowej nie jest w stanie wyprowadzić żadnego związku między zmiennymi niezależnymi i zależnymi?
Istnieje inny rodzaj regresji, znany jako regresja wielomianowa. Zgodnie ze swoją nazwą, Regresja wielomianowa to algorytm regresji, który modeluje związek między zmienną zależną (y) a zmienną niezależną (x) jako wielomian n-tego stopnia. W tym artykule zrozumiemy algorytm i matematykę stojącą za regresją wielomianową wraz z jej implementacją w Pythonie.
Co to jest regresja wielomianowa?
Jak zdefiniowano wcześniej, regresja wielomianowa jest szczególnym przypadkiem regresji liniowej, w której równanie wielomianowe o określonym (n) stopniu jest dopasowane do danych nieliniowych, które tworzą krzywoliniową zależność między zmienną zależną i niezależną.
y= b 0 +b 1 x 1 + b 2 x 1 2 + b 3 x 1 3 +…… b n x 1 n
Tutaj,

y jest zmienną zależną (zmienną wyjściową)
x1 to zmienna niezależna (predyktory)
b 0 to odchylenie
b 1 , b 2 , ….b n to wagi w równaniu regresji.
W miarę jak stopień równania wielomianowego ( n ) staje się wyższy, równanie wielomianowe staje się bardziej skomplikowane i istnieje możliwość nadmiernego dopasowania modelu, co zostanie omówione w dalszej części.
Porównanie równań regresji
Prosta regresja liniowa ===> y= b0+b1x
Wielokrotna regresja liniowa ===> y= b0+b1x1+ b2x2+ b3x3+…… bnxn
Regresja wielomianowa ===> y= b0+b1x1+ b2x12+ b3x13+…… bnx1n
Z powyższych trzech równań widzimy, że istnieje w nich kilka subtelnych różnic. Prosta i wielokrotna regresja liniowa różnią się od równania regresji wielomianowej tym, że ma stopień tylko 1. Wielokrotna regresja liniowa składa się z kilku zmiennych x1, x2 i tak dalej. Chociaż równanie regresji wielomianowej ma tylko jedną zmienną x1, ma stopień n, który odróżnia je od pozostałych dwóch.
Potrzeba regresji wielomianowej
Z poniższych diagramów widać, że na pierwszym diagramie próba dopasowania linii liniowej do danego zestawu nieliniowych punktów danych. Zrozumiałe jest, że linia prosta staje się bardzo trudna do utworzenia relacji z tymi nieliniowymi danymi. Z tego powodu, gdy trenujemy model, funkcja straty wzrasta, powodując duży błąd.
Z drugiej strony, gdy zastosujemy regresję wielomianową, wyraźnie widać, że linia dobrze pasuje do punktów danych. Oznacza to, że równanie wielomianowe, które pasuje do punktów danych, wyprowadza pewien rodzaj relacji między zmiennymi w zbiorze danych. Dlatego w takich przypadkach, w których punkty danych są ułożone w sposób nieliniowy, wymagany jest model regresji wielomianowej.
Implementacja regresji wielomianowej w Pythonie
Stąd zbudujemy model uczenia maszynowego w Pythonie implementujący regresję wielomianową. Porównamy uzyskane wyniki za pomocą regresji liniowej i regresji wielomianowej. Najpierw zrozummy problem, który rozwiążemy za pomocą regresji wielomianowej.
opis problemu
W tym przypadku rozważmy przypadek start-upu, który chce zatrudnić kilku kandydatów z firmy. W firmie są różne możliwości pracy na różnych stanowiskach. Start-up ma szczegółowe informacje o wynagrodzeniu dla każdej roli w poprzedniej firmie. Kiedy więc kandydat wspomina o swojej dotychczasowej pensji, HR start-upu musi to zweryfikować z istniejącymi danymi. Mamy więc dwie niezależne zmienne, którymi są Pozycja i Poziom. Zmienną zależną (wyjście) jest wynagrodzenie , które należy przewidzieć za pomocą regresji wielomianowej.
Wizualizując powyższą tabelę na wykresie, widzimy, że dane mają charakter nieliniowy. Innymi słowy, wraz ze wzrostem poziomu pensja rośnie w szybszym tempie, co daje nam krzywą pokazaną poniżej.
Krok 1: Wstępne przetwarzanie danychPierwszym krokiem w tworzeniu dowolnego modelu uczenia maszynowego jest zaimportowanie bibliotek. Tutaj mamy do zaimportowania tylko trzy podstawowe biblioteki. Następnie zestaw danych jest importowany z mojego repozytorium GitHub i przypisywane są zmienne zależne i zmienne niezależne. Zmienne niezależne są przechowywane w zmiennej X, a zmienna zależna jest przechowywana w zmiennej y.
importuj numer jako np
importuj matplotlib.pyplot jako plt
importuj pandy jako PD
dataset = pd.read_csv('https://raw.githubusercontent.com/mk-gurucharan/Regression/master/PositionSalaries_Data.csv')
X = zbiór danych.iloc[:, 1:-1].wartości
y = zbiór danych.iloc[:, -1].wartości
Tutaj, w wyrażeniu [:, 1:-1], pierwszy dwukropek oznacza, że wszystkie wiersze muszą być wzięte, a termin 1:-1 oznacza, że kolumny, które mają być uwzględnione, są od pierwszej kolumny do przedostatniej kolumny, która jest podana przez -1.
Krok 2: Model regresji liniowejW następnym kroku zbudujemy model wielokrotnej regresji liniowej i użyjemy go do przewidywania danych płacowych na podstawie zmiennych niezależnych. W tym celu klasa LinearRegression jest importowana z biblioteki sklearn. Następnie jest dopasowywany do zmiennych X i y w celach szkoleniowych.

from sklearn.linear_model import LinearRegression
regresor = regresja liniowa()
regresor.fit(X, y)
Po zbudowaniu modelu, po wizualizacji wyników, otrzymujemy następujący wykres.
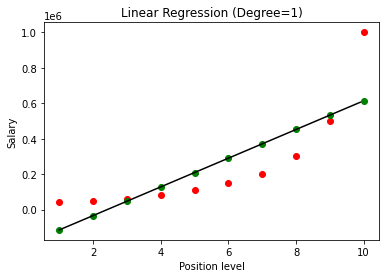
Jak wyraźnie widać, próbując dopasować linię prostą do nieliniowego zestawu danych, nie ma związku, który wynika z modelu uczenia maszynowego. Dlatego musimy skorzystać z regresji wielomianowej, aby uzyskać związek między zmiennymi.
Krok 3: Model regresji wielomianowejW następnym kroku dopasujemy model regresji wielomianowej do tego zbioru danych i zwizualizujemy wyniki. W tym celu importujemy inną klasę z modułu sklearn o nazwie jako PolynomialFeatures, w której podajemy stopień zbudowania równania wielomianowego. Następnie klasa LinearRegression jest używana do dopasowania równania wielomianowego do zestawu danych.
ze sklearn.preprocessing importuj funkcje wielomianowe
from sklearn.linear_model import LinearRegression
poly_reg = Wielomianowe cechy (stopień = 2)
X_poly = poly_reg.fit_transform(X)
lin_reg = Regresja Liniowa()
lin_reg.fit(X_poly, y)
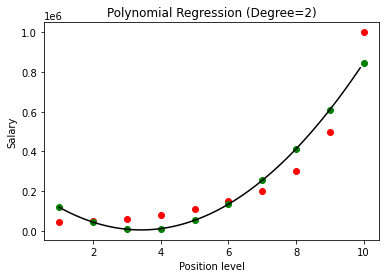
W powyższym przypadku podaliśmy, że stopień równania wielomianowego jest równy 2. Narysując wykres widzimy, że istnieje jakaś krzywa, która jest wyprowadzona, ale nadal istnieje duże odchylenie od rzeczywistych danych (na czerwono ) i przewidywane punkty krzywej (na zielono). Zatem w następnym kroku zwiększymy stopień wielomianu do wyższych liczb, takich jak 3 i 4, a następnie porównamy go ze sobą.
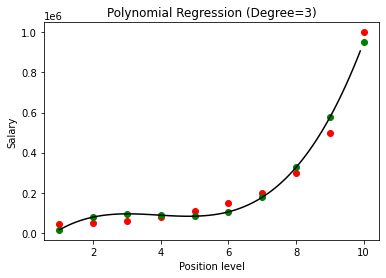
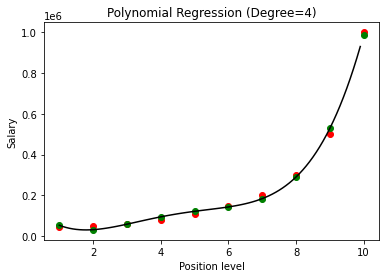
Porównując wyniki regresji wielomianowej ze stopniami 3 i 4, widzimy, że wraz ze wzrostem stopnia model dobrze trenuje z danymi. W ten sposób możemy wywnioskować, że wyższy stopień umożliwia dokładniejsze dopasowanie równania wielomianowego do danych uczących. Jest to jednak idealny przypadek overfittingu. Dlatego ważne staje się, aby dokładnie wybrać wartość n, aby zapobiec nadmiernemu dopasowaniu.
Co to jest overfitting?
Jak sama nazwa wskazuje, Overfitting jest określany jako sytuacja w statystyce, w której funkcja (lub w tym przypadku model uczenia maszynowego) jest zbyt ściśle dopasowana do zestawu ograniczonych punktów danych. Powoduje to, że funkcja działa słabo z nowymi punktami danych.
W uczeniu maszynowym, jeśli mówi się, że model jest nadmiernie dopasowany do danego zestawu punktów danych treningowych, to gdy ten sam model zostanie wprowadzony do zupełnie nowego zestawu punktów (powiedzmy testowy zestaw danych), wtedy działa na nim bardzo źle, ponieważ przesadnie dopasowany model nie uogólnił się dobrze z danymi i jest przesadnie dopasowany tylko do treningowych punktów danych.
W regresji wielomianowej istnieje duża szansa, że model będzie przesadnie dopasowany do danych uczących, gdy stopień wielomianu zostanie zwiększony. W powyższym przykładzie widzimy typowy przypadek overfittingu w regresji wielomianowej, który można skorygować jedynie metodą prób i błędów przy wyborze optymalnej wartości stopnia.
Przeczytaj także: Pomysły na projekty uczenia maszynowego
Wniosek
Podsumowując, regresja wielomianowa jest wykorzystywana w wielu sytuacjach, w których istnieje nieliniowa zależność między zmienną zależną i niezależną. Chociaż ten algorytm ma wrażliwość na wartości odstające, można go skorygować, traktując je przed dopasowaniem linii regresji. Dlatego w tym artykule wprowadziliśmy się w koncepcję regresji wielomianowej wraz z przykładem jej implementacji w programowaniu w Pythonie na prostym zbiorze danych.
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, sprawdź dyplom IIIT-B i upGrad's PG Diploma in Machine Learning & AI, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadań, IIIT- Status absolwenta B, ponad 5 praktycznych, praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Ucz się kursu ML z najlepszych światowych uniwersytetów. Zdobywaj programy Masters, Executive PGP lub Advanced Certificate Programy, aby przyspieszyć swoją karierę.
Co rozumiesz przez regresję liniową?
Regresja liniowa to rodzaj predykcyjnej analizy numerycznej, dzięki której możemy znaleźć wartość nieznanej zmiennej za pomocą zmiennej zależnej. Wyjaśnia również związek między jedną zmienną zależną a jedną lub większą liczbą zmiennych niezależnych. Regresja liniowa to technika statystyczna służąca do wykazania powiązania między dwiema zmiennymi. Regresja liniowa wykreśla linię trendu z zestawu punktów danych. Regresji liniowej można użyć do wygenerowania modelu predykcyjnego na podstawie pozornie losowych danych, takich jak diagnozy raka lub ceny akcji. Istnieje kilka metod obliczania regresji liniowej. Zwykłe podejście najmniejszych kwadratów, które szacuje nieznane zmienne w danych i wizualnie przekształca je w sumę odległości pionowych między punktami danych a linią trendu, jest jednym z najbardziej rozpowszechnionych.
Jakie są wady regresji liniowej?
W większości przypadków analiza regresji jest wykorzystywana w badaniach w celu ustalenia, czy istnieje związek między zmiennymi. Jednak korelacja nie implikuje związku przyczynowego, ponieważ powiązanie między dwiema zmiennymi nie implikuje, że jedna powoduje drugą. Nawet linia w podstawowej regresji liniowej, która dobrze pasuje do punktów danych, może nie zapewniać związku między okolicznościami a wynikami logicznymi. Korzystając z modelu regresji liniowej, możesz określić, czy istnieje jakakolwiek korelacja między zmiennymi. Wymagane będą dodatkowe badania i analiza statystyczna w celu określenia dokładnego charakteru powiązania i tego, czy jedna zmienna powoduje drugą.
Jakie są podstawowe założenia regresji liniowej?
W regresji liniowej istnieją trzy kluczowe założenia. Zmienne zależne i niezależne muszą przede wszystkim mieć związek liniowy. Do sprawdzenia tej zależności używany jest wykres punktowy zmiennych zależnych i niezależnych. Po drugie, między zmiennymi niezależnymi w zbiorze danych powinna występować minimalna lub zerowa współliniowość. Oznacza to, że zmienne niezależne nie są ze sobą powiązane. Wartość musi być ograniczona, co jest określane przez wymagania domeny. Trzecim czynnikiem jest homoskedastyczność. Założenie o równomiernym rozłożeniu błędów jest jednym z najważniejszych założeń.